基于chainlit的大模型聊天室创建
实现了基本聊天室功能,但是登录和历史聊天会话仍然没有实现,今天先实现到这里,后续功能我会在后续的博客当中给出,想要后续实现,请关注我。瑞斯拜!!!!!
一、项目展示
1.1登录页面展示
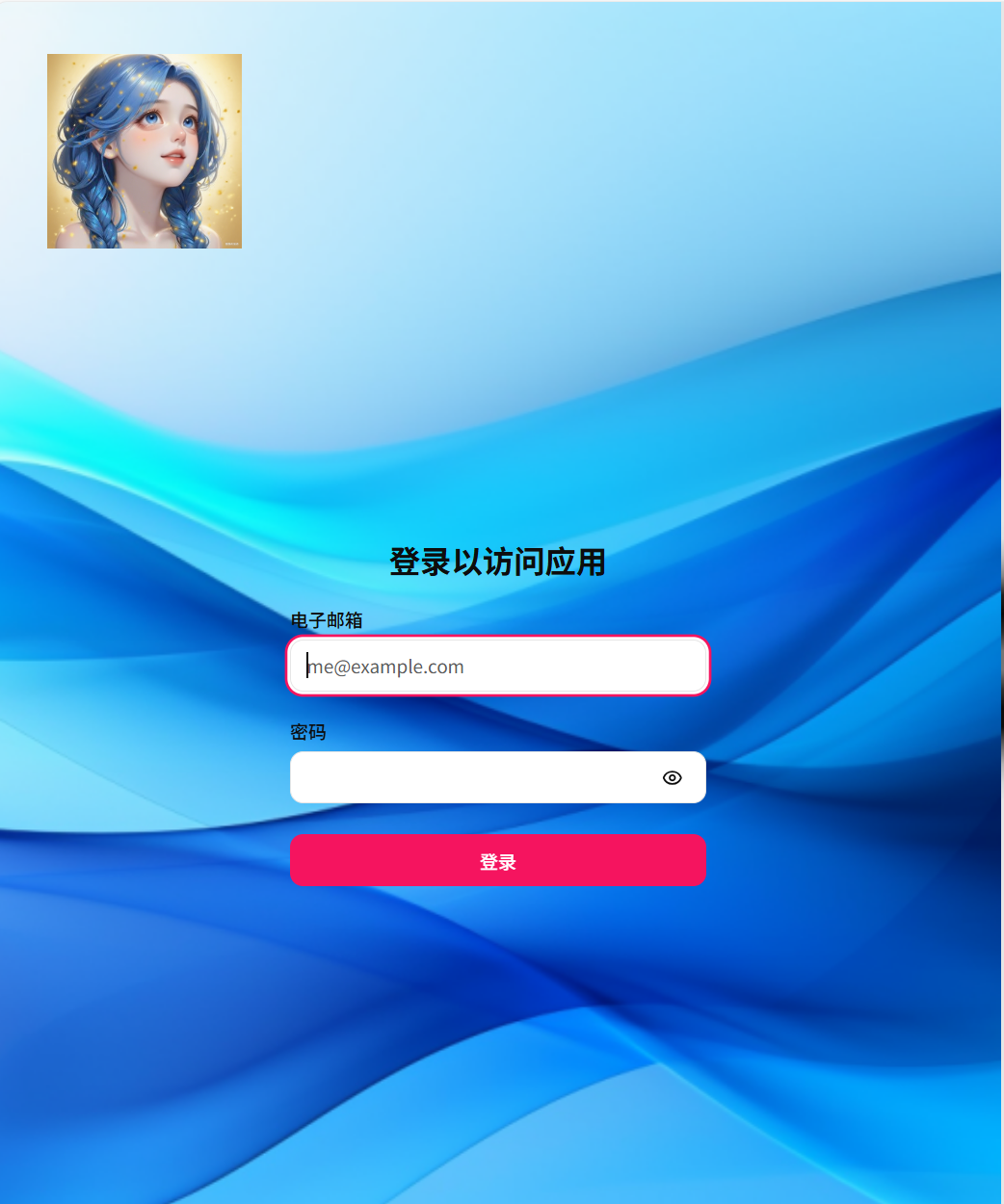
1.2浅色背景展示
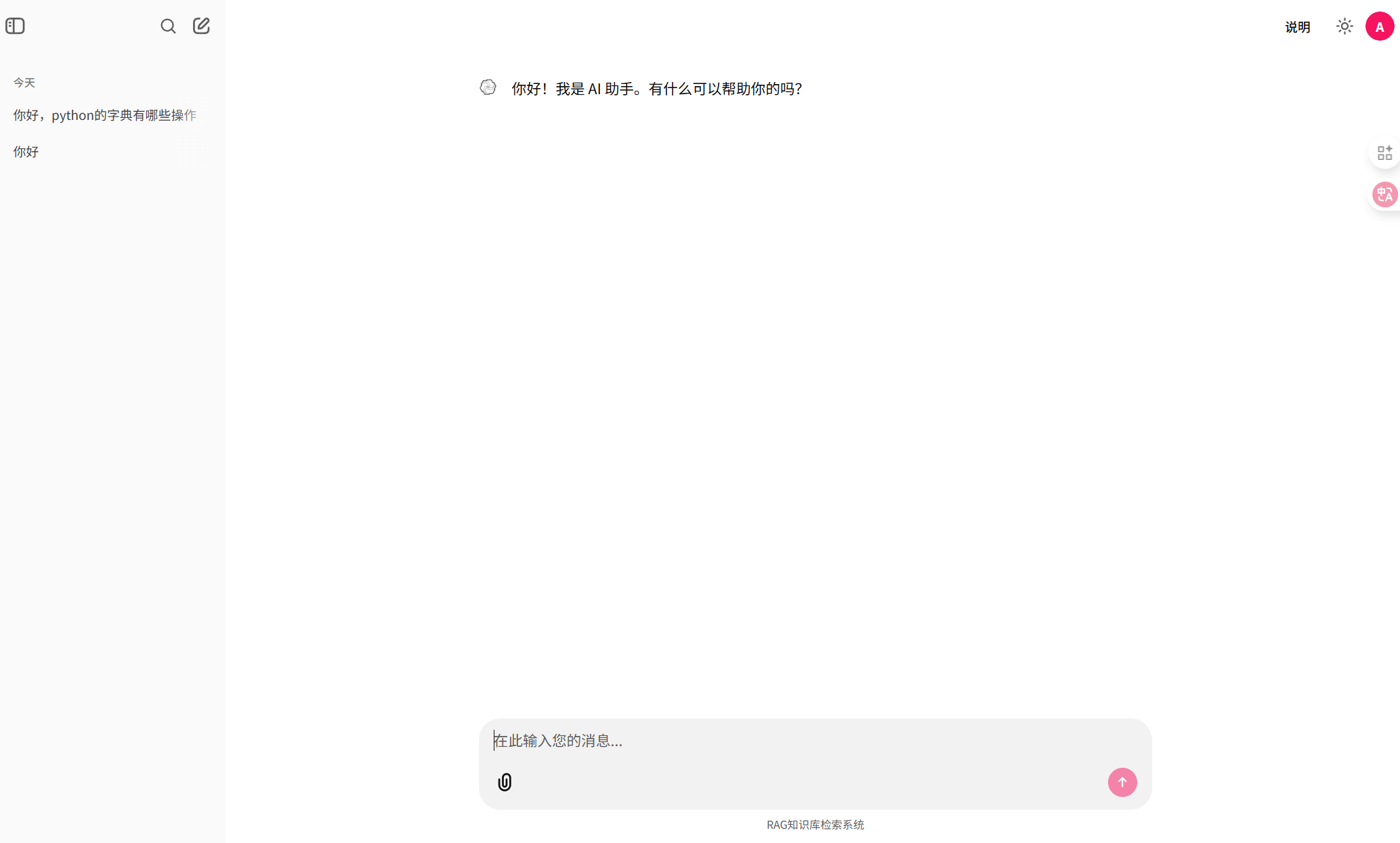
1.3深色背景展示
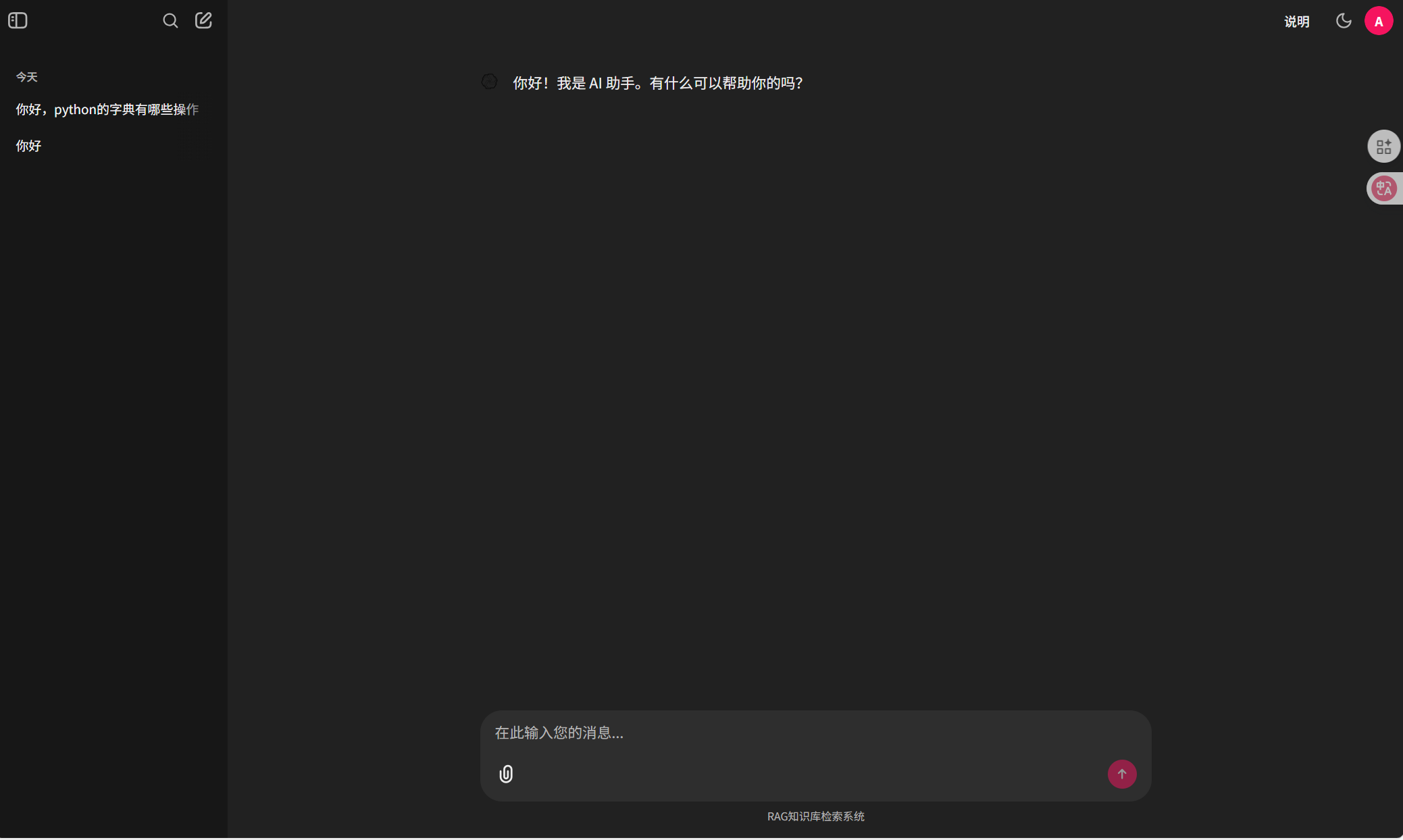
1.4历史侧边栏展示
1.5聊天展示(包含文件上传)

二、项目技术栈解析
我们聊天室的前端采用chainlit构建用户交互页面,后端使用python+Llama Index去进行大模型连接和支持大模型的数据处理。在数据库存储方面用户数据采用portgresql去实现数据库持久化存储,大模型的对象存储使用Minio向量数据库进行存储处理。
以下是一个技术栈解析表格,方便查看。
| 技术领域 | 技术名称 | 描述 |
|---|---|---|
| 前端 | Chainlit | 用于构建大模型的展示页面,提供用户交互界面。 |
| 后端 | Python | 编程语言,用于实现后端逻辑。 |
| Llama Index | 用于实现后端的索引和查询功能,支持大模型的数据处理。 | |
| 数据持久化存储 | PostgreSQL | 关系型数据库,用于存储结构化数据,如用户信息、会话信息等。 |
| Minio | 对象存储服务,用于存储非结构化数据,如文件、图片等。 |
三、项目开发
3.1项目准备阶段
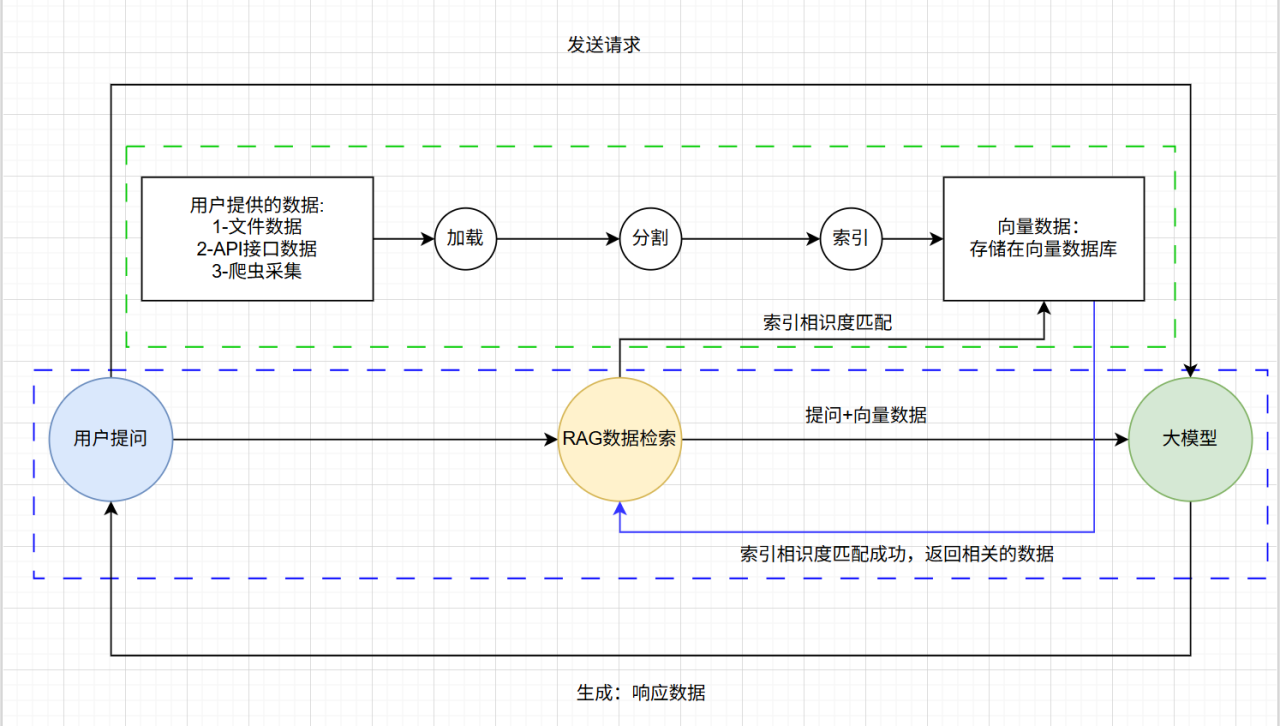
在项目准备阶段,我们首先需要清楚一些流程也就是大模型给我回答问题是一个什么样的过程。只有明白了这样一个原理过程我们才能够基于这个过程有一个清晰的开发路线。在开始流程之前我们需要提到一个名词RAG,RAG是什么,我们可以理解为是一个提高大模型输出效率与准确性的优化架构,我们的大模型要给用户输出的合理准确规范和高效的话,这个RAG是必不可少的。RAG总体上面分为两个过程一个是数据索引,另一个是数据存储,数据索引为将外部的数据进行处理简历索引变为向量数据,数据存储是将得到的向量数据存储在数据库当中,以供大模型检索回复时进行使用。
现在我们来讲一讲从用户到大模型输出给我们答案是一个什么样的过程:
①用户输入不同种类的数据包括文件,文字等多模态的数据给大模型,大模型此时进入加载阶段,将不同模态(类型)的知识进行链接和读取。
②大模型为了更好的检索数据,先将大的知识内容进行分割,将他们分割成小块以便后续索引。
③大模型将分割号的知识块变为一个高维向量进行嵌入,进行向量存储的索引。
④大模型将嵌入的高位向量使用向量数据库进行存储或者索引,这里会用到一些向量检索的算法提高效率。
⑤在数据索引简短结束后,大模型要将处理好的数据输出给用户这是就是检索阶段,在检索之前,开发仍愿会对检索进行优化提高检索的精确度和生成的质量。
⑥在优化过后,大模型先借助数据索引从数据库检索,然后使用排序算法,对检索的数据进行排序,作为上下文参考,一边后续生成结果。
⑦排序算法是对检索后的数据进行过滤知识块,对即将要输出的数据进行必要的补充和处理,提高大模型的输出质量。
⑧在检索完毕以后大模型就开始生成给用户,将检索的知识块输出回答用户的原始查询问题,至此闭环。
至此你已经了解了大模型的输出流程,以及RAG是一个优化大模型输出的架构,我们现在就基于这么一个知识流程来完成我们的项目。
这里我提供一张图片来帮助大家更深入了解。
3.2项目起步阶段
在开始之间我们需要先去参考Chainlit官方的写法,在我们的Pycharm工具当中去下载他们的库使用。除此以外我们还需要去下载postgresql和Minio使用,这些是我们必须要用到的工具,需要提前去准备。
在搭建好项目环境以后我们需要在终端去下载我们需要要到的llama Index去使用,我们可以使用以下任意一条指令去下载使用。
pip install llama-index
或者
pip install llama-index-llms-openai然后我们可以去查看我们是否导入成功。
pip show llama-index在能看到版本号之后,我们就是以及导入成功了。
在安装好llama_index以后我们就需要去准备我们用到的大模型的api_key了,我们可以去到大模型的官方文档去获取到他们的api_key去调用他们的大模型,电脑硬件强大的也可以使用本地部署方式去部署自己的大模型。如何去获取api_key这里不多说,不会的可以去参考我之前基于通义千问的调取文章。都是一样的。我们这里需要用到deepseek和kimi2大模型的密钥,不想使用这两个大模型的我们也可以使用其他的,都是一样的,但是强烈建议要一个k2的密钥,因为这个大模型还是很强大的。
3.2项目实现阶段
3.2.1大模型部署
在调取了大模型的key以后我们需要在环境当中去配置大模型,我们先创建一个llms.py的文件去配置我们的大模型。下面我将给出我的代码示例并讲解代码的含义。
from llama_index.llms.openai import OpenAI
from typing import Dict
from llama_index.llms.openai.utils import ALL_AVAILABLE_MODELS, CHAT_MODELS
# 定义Moonshot模型及其上下文长度配置
MOONSHOT_MODELS: Dict[str, int] = {
"kimi-k2-0711-preview": 128000, # 大模型上下文长度
}
# 定义DeepSeek模型及其上下文长度配置
Deepseek_MODELS: Dict[str, int] = {
"deepseek-chat": 128000, # 大模型上下文长度
}
# 定义Qwen模型及其上下文长度配置
Qwen_MODELS: Dict[str, int] = {
"qwen-plus": 128000, # 大模型上下文长度
}
# 将自定义模型合并到可用模型和聊天模型集合中
ALL_AVAILABLE_MODELS.update(
Deepseek_MODELS | MOONSHOT_MODELS | Qwen_MODELS
)
CHAT_MODELS.update(
Deepseek_MODELS | MOONSHOT_MODELS | Qwen_MODELS
)
def moonshot_llm(**kwargs):
"""
创建并返回一个配置好的Moonshot大语言模型实例。
参数:
**kwargs: 其他传递给OpenAI类的参数,如temperature、max_tokens等。
返回:
OpenAI: 配置完成的Moonshot大语言模型实例。
"""
llm = OpenAI(
api_key="你的kimi的key值", # 大模型的key值
model="kimi-k2-0711-preview", # 大模型的名称
api_base="https://api.moonshot.cn/v1", # 大模型的API地址
temperature=0.6,
**kwargs,
)
return llm
def deepseek_llm(**kwargs):
"""
创建并返回一个配置好的DeepSeek大语言模型实例。
参数:
**kwargs: 其他传递给OpenAI类的参数,如temperature、max_tokens等。
返回:
OpenAI: 配置完成的DeepSeek大语言模型实例。
"""
llm = OpenAI(
api_key="deepseek的key值", # 大模型的key值
model="deepseek-chat", # 大模型名称
api_base="https://api.deepseek.com", # 大模型的API地址
temperature=0.6,
**kwargs,
)
return llm
def qwen_llm(**kwargs):
"""
创建并返回一个配置好的Qwen大语言模型实例。
参数:
**kwargs: 其他传递给OpenAI类的参数,如temperature、max_tokens等。
返回:
OpenAI: 配置完成的Qwen大语言模型实例。
"""
llm = OpenAI(
api_key="通义千问的key值",
model="qwen-plus",
api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=0.6,
**kwargs,
)
return llm
代码的大部分解释说明我已经在代码当中打好注释,现在着重解释一些代码的功能。
在最上方我配置了两个个参数,一个是设置了大模型的最大上下文长度,另一个是基于llama_index去调用大模型,这样写的原因是在llama_index当中没有我们国内这些大模型的配置,所以我们需要手动去配置一些我们国内大模型的参数,所以需要加入这两个参数。其中在下面写的大模型参数当中key值,大模型类型(model),api_base都是官方文档下方提供的,最主要的是我们的temperature这个值的含义。现在解释以下temperature这个值的含义。
①温度参数(Temperature)的作用:
控制模型生成文本的随机性和多样性
影响模型在每个token选择时的概率分布
②取值范围和效果:
低温度(接近0):输出更加确定性和保守,倾向于选择概率最高的词
高温度(接近1或更高):输出更加随机和创造性,增加词汇多样性
中等温度(如0.6):在创造性和一致性之间取得平衡
③设置为0.6的意义:
提供适度的创造性,避免过于机械化的回复
保持一定的稳定性,防止输出过于随机或不相关
适合大多数通用对话和文本生成任务
在保证质量的同时增加回复的自然性和多样性
这个参数值的选择通常基于实际应用场景和用户体验的优化考虑。
总而言之这一个参数不同的取值代码大模型的性能。
至此我们大模型的部署已完成,接下来是调用。
3.2.2大模型调用
在调用之前我们需要测试一下我们的模型是否打通,这里我们需要创建一个main.py文件去运行我们的项目。以下是实现的代码。
from llama_index.core import Settings
from llama_index.core.chat_engine import SimpleChatEngine
# 导入大模型相关配置
from llms import moonshot_llm
from llms import deepseek_llm
from llms import qwen_llm
# Settings.llm=moonshot_llm()
# Settings.llm=deepseek_llm()
# Settings.llm=qwen_llm()
model=input(str("请输入你需要的大模型名称(kimi,deepseek,qwen):"))
if model=="kimi":
Settings.llm=moonshot_llm()
elif model=="deepseek":
Settings.llm=deepseek_llm()
elif model=="qwen":
Settings.llm=qwen_llm()
chat_engine=SimpleChatEngine.from_defaults()
chat_engine.streaming_chat_repl()右键点击运行即可随便切换一个大模型使用,这里我们将前面部署的大模型进行了实例化调用,其中Settings 是 llama_index 框架中的全局配置管理器,作用是管理组件的默认配置,llm参数为我们默认配置的大模型类型,我们通过Settings.llm=大模型配置的形式去调用大模型,下面的chat_engine是我们创建的聊天引擎参数,其中SimpleChatEngine的使用可以让我们去进行一些简单的多轮对话,他的缺点是不能对过大的知识块进行分割,我们这里使用这个知识进行一个简单的聊天实现,后面的streaming是进行流式输出。
下面是演示:
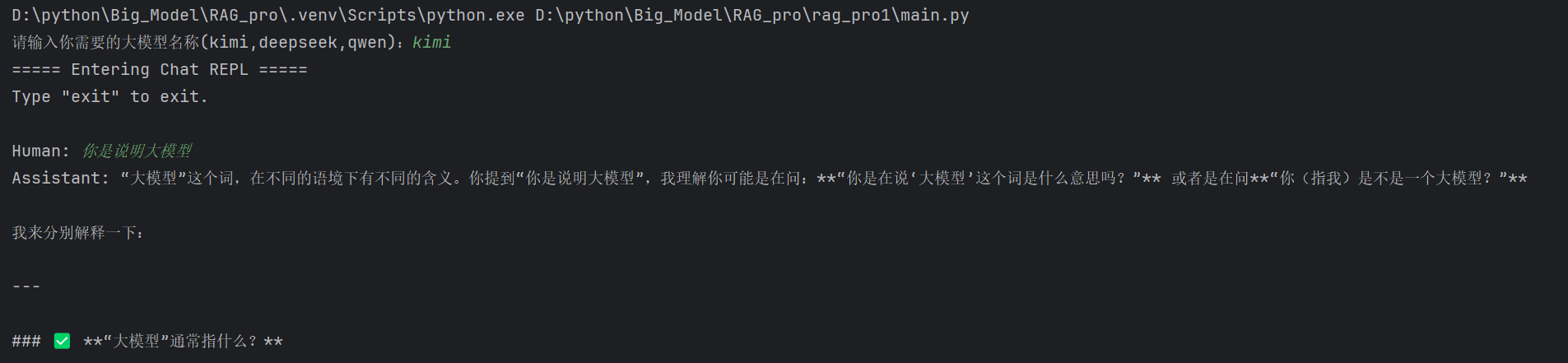
已经连接成功了。
至此我们已经连通,可以使用chainlit,对我们的聊天室进行一个可视化实现。
3.2.3基于Chainlit去实现可视化聊天室
在使用chainlit之前我们需要访问官方文档去实现我们的前端效果,需要注意的是这个需要挂梯子才可以访问,不挂梯子可能会访问失败。
这个是chainlit的官方文档页面:
后续我们完成一些功能都需要参考官方文档去使用。
现在我将流程展示以下:
①先在bash当中下载chainlit库,下载指令如下。
pip install chainlit检查是否安装成功。
chainlit hello②打开我上面那个官方文档页面去复制官方文档当中提供的代码,但是我们需要删减一些代码,我现在给出我的代码并进行解释
import chainlit as cl
from llama_index.core import Settings
from llama_index.core.chat_engine import SimpleChatEngine
from llms import moonshot_llm
@cl.on_chat_start
async def start():
# 初始化语言模型配置
Settings.llm = moonshot_llm()
# 创建默认的简单聊天引擎实例
chat_engine = SimpleChatEngine.from_defaults()
# 将聊天引擎存储到当前用户的会话状态中,供后续对话使用
cl.user_session.set("chat_engine", chat_engine)
# 发送欢迎消息给用户
await cl.Message(
author="Assistant", content="你好,我是AI智能助手,请开始提问?"
).send()
@cl.on_message
async def main(message: cl.Message):
# 从用户会话中获取聊天引擎实例
query_engine = cl.user_session.get("chat_engine") # type: RetrieverQueryEngine
# 创建一个空的助手消息对象,用于流式输出
msg = cl.Message(content="", author="Assistant")
# 异步调用查询引擎的流式聊天方法处理用户消息
res = await cl.make_async(query_engine.stream_chat)(message.content)
# 遍历响应生成器,将每个token流式发送给用户
for token in res.response_gen:
await msg.stream_token(token)
# 发送完整的消息
await msg.send()
我们复制了官方文档的两个装饰器@cl.on_chat_start和@cl.on_message,前者其实就是我们上面提到的大模型连通,我们只需要把上面提到的两行代码复制到这里即可,这里我们选择调用K2模型,后面的代码作用主要用于历史会话生成,注释已经给出,其中发送欢迎消息给用户的代码我们可以根据自己的需求添加。
后面的代码解释注释当中已经给出,需要注意的是,我们需要你先创建一个app.py的文件去装这些代码使用,后续我们启动我们需要进行配置。以下是配置流程。
③配置启动文件
第一种启动方式:
在终端运行
chainlit run app.py -w第二种启动方式:
我们需要点击鼠标右键,按照我下面的流程点击即可。
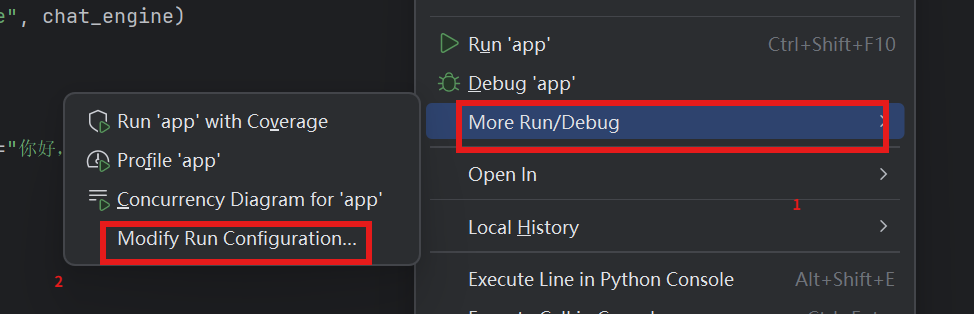
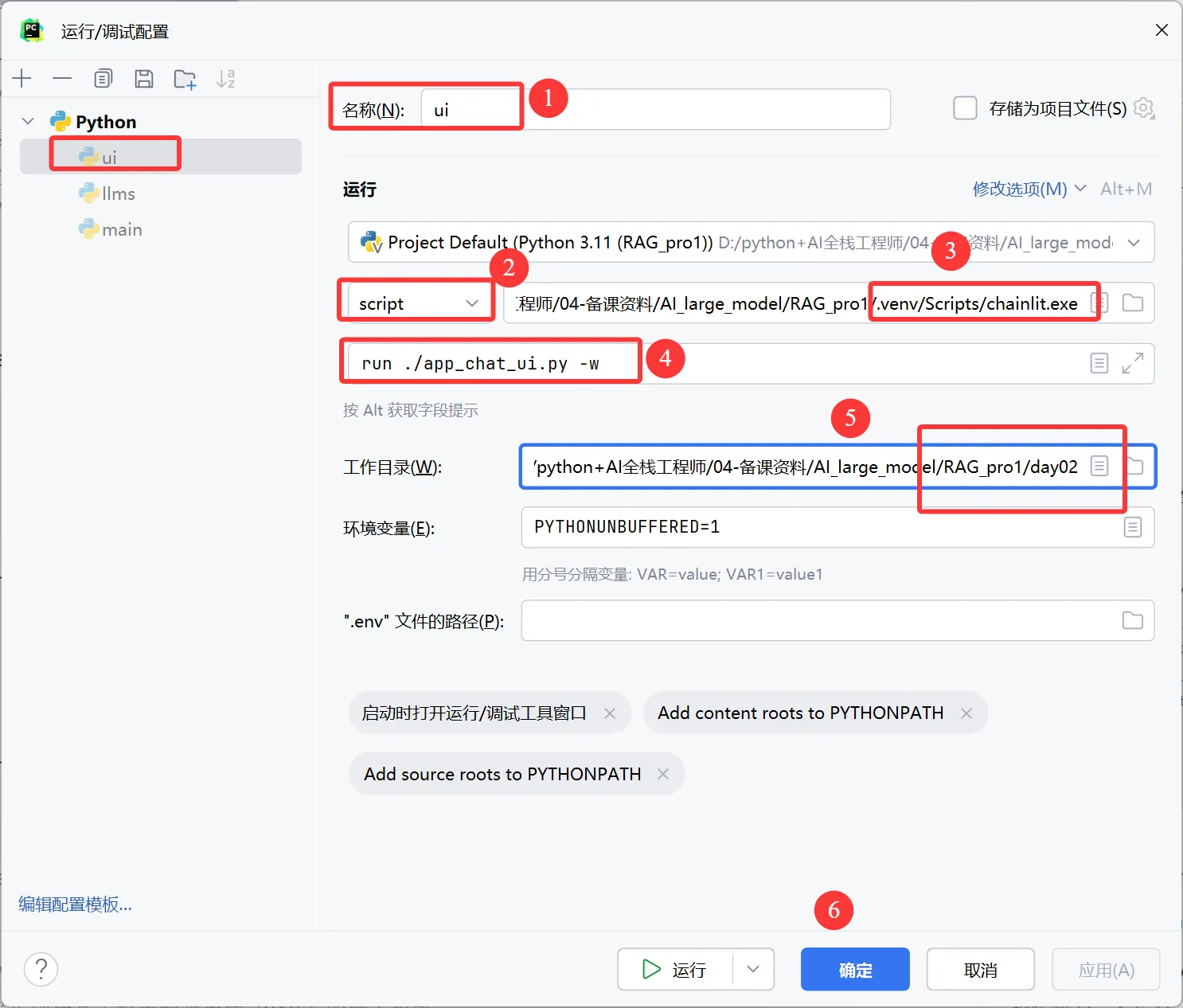
这样配置以后我们直接点击上面的启动按钮即可启动。
启动后的页面出现那就是成功了。
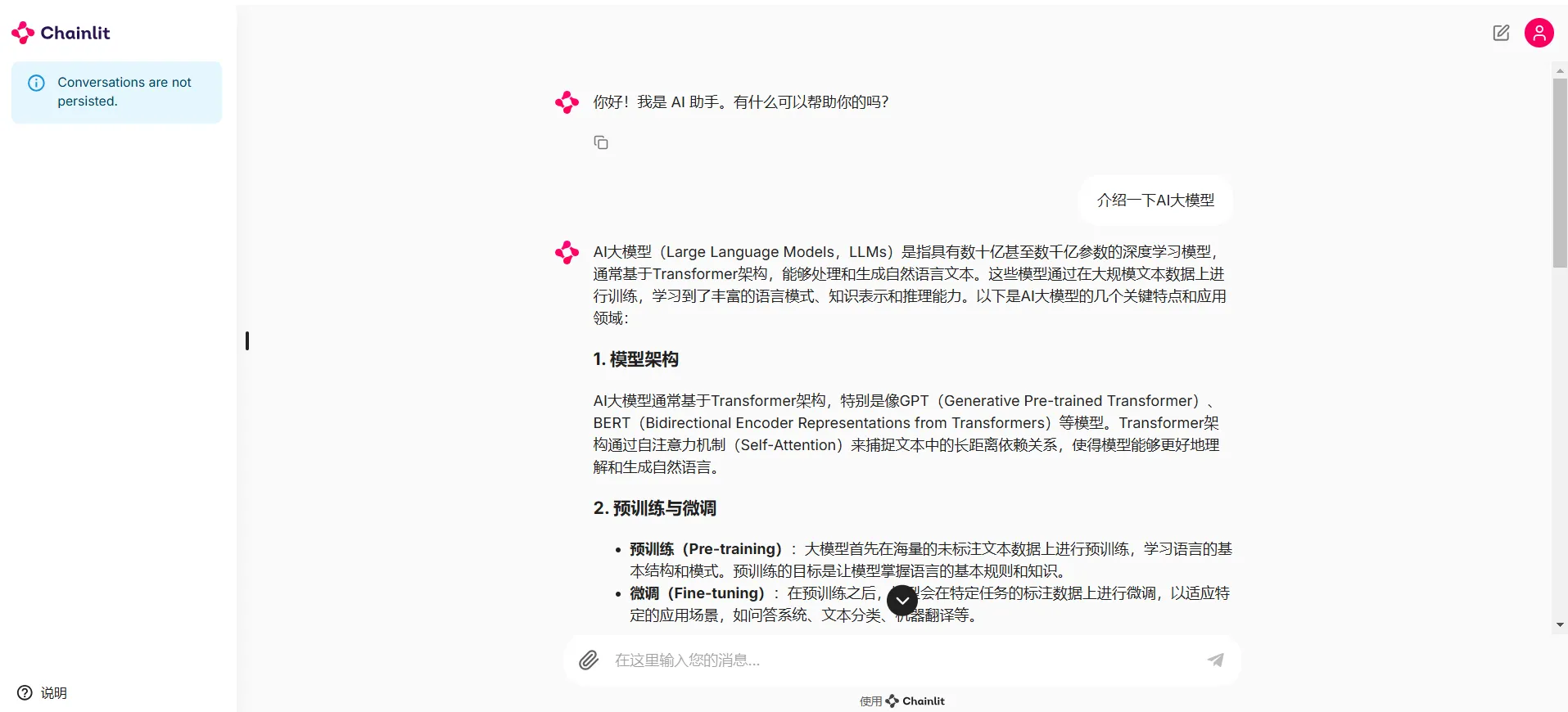
启动的样式会和我给出的图有差异,左边的历史侧边栏不会有,因为根据官方文档我们需要使用身份认证和连接数据库以后才可使用。
四、项目总结
实现了基本聊天室功能,但是登录和历史聊天会话仍然没有实现,今天先实现到这里,后续功能我会在后续的博客当中给出,想要后续实现,请关注我。瑞斯拜!!!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)