港科大谭平团队新作SAIL-Recon:一种Transformer,数分钟搞定万帧图像3D重建
《SAIL-Recon:基于视觉定位增强的大规模场景回归方法》提出了一种高效处理大规模图像集的前馈式SfM方案。传统基于学习的SfM方法面临输入图像增多时计算量剧增的瓶颈,SAIL-Recon创新地通过整合视觉定位能力,先利用少量锚点图像构建紧凑的神经场景表示,再以此为基础快速回归所有图像的相机位姿和三维结构。实验表明,该方法在Tanks&Temples等数据集上仅需数分钟即可处理数千张图
一、导读
本研究旨在解决现有场景回归 (Scene Regression) 方法在处理大量输入图像时的可扩展性瓶颈。传统基于学习的 Structure-from-Motion (SfM) 方法,如 VGGT,虽然在处理极端视角变化时表现优异,但其计算和内存开销会随图像数量的增加而急剧增长。为应对这一挑战,本文提出了一种名为 SAIL-Recon 的新方法,通过将视觉定位 (Visual Localization) 能力整合到场景回归网络中,实现了对大规模场景的高效前馈式 SfM 重建。具体而言,SAIL-Recon 首先从一小组锚点图像 (Anchor Images) 中计算出一个紧凑的**神经场景表示 (Neural Scene Representation)**,该表示作为一个全局隐式地图。随后,网络利用此表示对包括所有剩余图像在内的整个图像集进行高效的相机位姿和三维结构回归。该方法的主要贡献在于,它无需对每个场景进行耗时的优化训练,便能快速(数分钟内)且精确地重建包含数千张图像的大规模场景,并在多个基准测试中取得了领先的性能。
二、论文基本信息
基本信息

-
论文标题:SAIL-Recon: Large SfM by Augmenting Scene Regression with Localization
-
作者:Junyuan Deng, Heng Li, Tao Xie, Weiqiang Ren, Qian Zhang, Ping Tan, Xiaoyang Guo
-
作者单位:The Hong Kong University of Science and Technology, Horizon Robotics, Zhejiang University
摘要精炼
本文旨在解决场景回归方法在处理大规模图像集时的扩展性问题。为实现此目标,论文提出了一种名为 SAIL-Recon 的前馈式 Transformer 模型,其核心技术贡献在于将视觉定位能力与场景回归网络相结合。该方法首先利用一小部分锚点图像生成一个全局神经场景表示,作为场景的隐式地图。然后,网络将此表示作为条件,对所有输入图像(包括锚点图像和查询图像)进行联合位姿和三维结构回归。通过这种方式,SAIL-Recon 能够在几分钟内高效处理数千张图像。实验结果表明,该方法在相机位姿估计和新视角合成方面取得了当前最优性能,例如,在 Tanks & Temples 数据集上,其前馈式版本(FFD)的 RRA@5 达到了 70.4%,RTA@5 达到了 74.7%,ATE 低至 0.008,显著优于其他前馈方法。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/rt4wPNKI4R4r7xxP5LTfjg
https://mp.weixin.qq.com/s/rt4wPNKI4R4r7xxP5LTfjg
三、研究背景与相关工作
研究背景
Structure-from-Motion (SfM) 是从无序图像集合中同时估计相机位姿和三维场景结构的关键技术,对新视角合成、三维重建和视觉定位等应用至关重要。传统的 SfM 方法(如增量式或全局式)依赖于特征匹配、三角化和束调整 (Bundle Adjustment) 等多个独立组件,这些组件在处理低纹理、模糊或重复模式的图像时容易出错,可能导致整个重建过程失败。近年来,基于场景回归的端到端学习方法展现了强大的鲁棒性,但它们普遍面临一个核心痛点:随着输入图像数量的增加,GPU 显存消耗和计算时间会急剧上升,使其难以扩展到视频或大规模场景,这是驱动本研究寻找高效、可扩展 SfM 方案的主要动机。
相关工作
该领域已有的解决方案主要分为两类。第一类是传统的几何 SfM 方法,包括增量式(如 COLMAP)和全局式(如 GLOMAP),它们虽然精度较高,但对特征匹配的依赖性强且流程脆弱。第二类是基于场景回归的学习方法,如 DUSt3R 及其后续工作,它们通过 Transformer 直接从图像回归场景坐标图 (Scene Coordinate Maps, SCM) 和相机位姿。这类方法的局限性在于可扩展性差,难以直接处理上百张图像。一些针对视频序列的方法(如 SLAM3R)采用增量更新方式,但这容易导致位姿漂移,并依赖全局对齐来修正误差。与此同时,现有的视觉定位方法大多需要针对每个场景进行耗时的网络优化和精确的相机位姿标注。本文提出的 SAIL-Recon 创新地统一了重建与定位,避免了这些局限性。
四、主要贡献与创新
-
统一重建与定位框架:提出了一种名为 SAIL-Recon 的新型前馈式 SfM 方法,通过将视觉定位能力推广并整合到神经场景回归中,实现了对数千张输入图像的精确、鲁棒且高效的重建(仅需数分钟)。
-
神经场景表示:从场景回归网络中提取出一种新颖的神经场景表示,它作为一种全局隐式地图,有效地编码了场景的几何与外观信息,用于后续的快速定位,且无需显式的三维点云或网格。
-
卓越的性能:通过大量实验证明,SAIL-Recon 在多个权威的 SfM 和视觉定位基准测试(包括 TUM-RGBD、CO3Dv2 和 Tanks & Temples)上,性能超越了现有的传统方法和基于学习的方法,达到了业界领先水平。
五、研究方法与原理
总体框架与核心思想
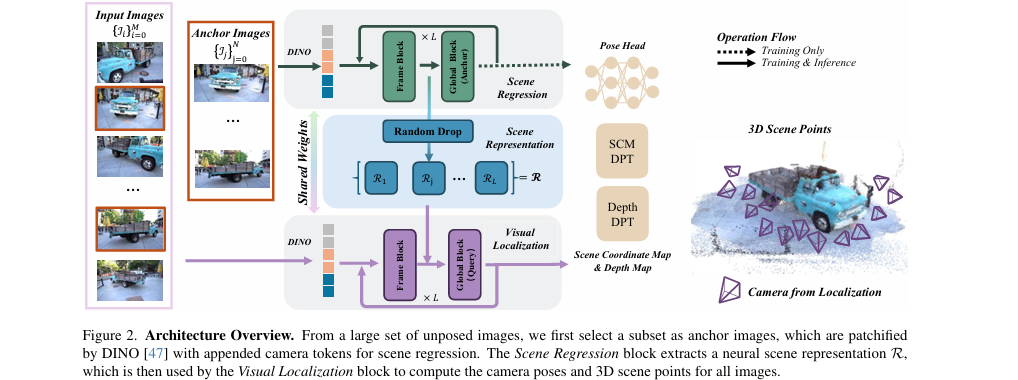
SAIL-Recon 的核心设计哲学是“构建全局地图,然后定位所有视图”,从而将计算复杂度与图像总数解耦。如论文图2所示,其总体框架分为两个阶段:
-
神经场景表示构建:从大规模图像集中选取一小部分(如50-100张)作为锚点图像。这些图像通过一个基于 Transformer 的场景回归网络,生成一个全局的神经场景表示
R。这个R是从网络不同深度的中间层特征中提取并下采样得到的,它同时包含了从二维外观特征到三维几何描述的渐进信息,充当了场景的隐式“地图”。 -
定位与重建:将该神经场景表示
R作为固定的上下文信息,网络以一种高效的前馈方式处理包括锚点和非锚点在内的所有图像。通过在全局注意力模块中引入掩码机制,实现每个查询图像与场景表示R之间的交叉注意力,从而回归出该图像的相机位姿、深度图和场景坐标图。
这种“先建图,后定位”的策略,极大地提升了处理大规模图像集时的效率和可扩展性。
关键实现与评估原理
关键实现细节
-
神经场景表示的构建:神经场景表示
R并非仅来自网络的最后一层,而是由各 Transformer 层中间特征t'_{I,j}经过下采样Θ后聚合而成。这种多层次的表示能够更好地连接二维图像特征和三维空间结构。其构建公式为: -
基于交叉注意力的定位:在定位阶段,查询图像的特征
t_{q,j}与场景表示R_j通过全局注意力层进行交互。通过注意力掩码,查询图像的 token 只能关注自身以及场景表示的 token,而不能关注其他查询图像的 token,这本质上是一种交叉注意力机制。 -
训练策略:训练时,通过一个多任务损失函数
L同时优化相机参数、深度图和场景坐标图。采用随机采样r比例的 token 构建场景表示,这起到了类似 Dropout 的正则化作用,提升了模型的泛化能力。 -
后期优化:虽然模型直接输出的结果已经很强,但论文还提供了一个可选的后期优化步骤。该步骤采用类似 BARF 的方法,通过最小化渲染损失来微调相机位姿,进一步提升精度。
核心评估原理与指标
- 相机位姿精度:
-
相对位姿误差:RRA@5 (相对旋转误差小于5度的相机对比例) 和 RTA@5 (相对平移误差小于5度的相机对比例)。
-
绝对轨迹误差 (ATE):衡量估计轨迹与真实轨迹之间的均方根误差(RMSE),常用于 SLAM 评测。
-
- 重建质量 (通过新视角合成评估):
-
峰值信噪比 (PSNR):在估计出的相机位姿上训练一个 NeRF 模型 (Nerfacto),并渲染测试视图。渲染图像与真实图像的 PSNR 值越高,表明估计的位姿越准确。
-
六、实验结果与分析
实验设置
- 数据集:
-
大规模场景:Tanks & Temples
-
SLAM 视频序列:TUM-RGBD
-
视觉定位场景:7-Scenes
-
其他:CO3Dv2, Mip-NeRF 360 等。
-
- 评估指标:
-
RRA@5, RTA@5, ATE, PSNR。
-
- 对比基线:
-
**优化方法 (OPT)**:COLMAP, GLOMAP, ACE0 等。
-
**前馈方法 (FFD)**:Light3R-SfM, VGGT-SLAM, SLAM3R 等。
-
- 关键超参:
-
锚点图像数量:通常为 50-100 张。
-
每个锚点图像贡献的 token 数量:约 300 个 (下采样率
r≈ 0.2)。
-
核心实验与结论
核心实验:在 Tanks & Temples 数据集上的位姿估计性能
-
实验目的:验证 SAIL-Recon 在包含数百张图像的大规模场景下的位姿估计精度和效率,并与目前主流的优化方法和前馈方法进行对比。
-
关键结果:如表1所示,SAIL-Recon(FFD版本)在所有前馈方法中取得了最佳性能。其 RRA@5 和 RTA@5 分别达到了 70.4% 和 **74.7%**,显著高于次优的 VGGT-SLAM(57.3% 和 67.9%)。其 ATE 仅为 0.008,与顶级的优化方法相媲美。同时,其运行时间(81秒)远快于优化方法(如GLOMAP的1977秒),且比大多数前馈方法更快。
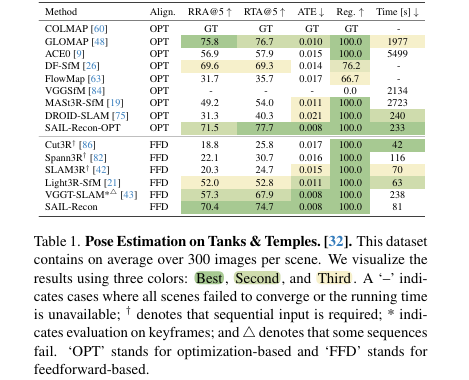
-
作者结论:该实验结果有力地证明,SAIL-Recon 成功地解决了前馈式场景回归方法的可扩展性问题。通过引入视觉定位机制,它不仅实现了对大规模场景的高效处理,而且在精度上达到了与耗时更长的优化方法相当甚至更好的水平,稳固了其作为一种先进大规模 SfM 方案的地位。
七、论文结论与启示
总结
本文成功提出了一种名为 SAIL-Recon 的创新性 SfM 框架,通过将场景回归与视觉定位相结合,有效解决了现有学习方法在处理大规模图像集时的可扩展性难题。该方法的核心在于先从一小部分锚点图像中构建一个紧凑且信息丰富的神经场景表示,然后利用此表示以前馈方式高效地定位和重建场景中的所有图像。实验证明,SAIL-Recon 在精度和效率上均超越了现有的主流方法,为大规模三维视觉任务提供了一个强大而实用的解决方案。
展望
论文指出了当前模型的两个局限性及未来的改进方向:
-
参考坐标系选择:当前方法在预先固定的参考坐标系中进行全局位姿估计,这可能在某些序列上导致性能下降。未来可以研究更优的视角选择标准来提升鲁棒性。
-
锚点采样策略:均匀采样锚点图像可能无法有效覆盖大范围或多样化的场景区域。未来可以探索覆盖感知 (coverage-aware) 的采样策略,以最大化场景的可见性,从而提高重建的完整性和准确性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)