LLaVA进化之路
LLaVA系列模型通过创新的视觉-语言对齐架构,推动了多模态AI的发展。关键技术包括:1)使用CLIP/SigLIP视觉编码器提取图像特征;2)采用MLP投影层将视觉特征映射到文本嵌入空间;3)逐步提升输入分辨率(224→672px)并支持动态切块处理;4)优化训练策略(两阶段训练、数据混合)。最新版本LLaVA-NeXT和OneVision进一步增强了OCR能力,支持多图像/视频输入,并通过Si
1 LLaVA
传统LLM模型只支持文本输入,对于图像则无从下手。
LLAVA旨在设计一个通用的视觉、语言助手,可以根据图像、文本指令进行对应任务。
1.1 LLaVA结构:
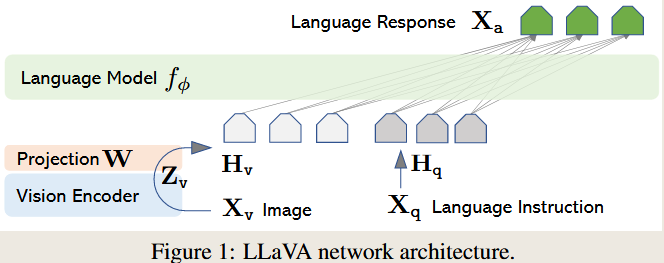
LLAVA主要目标是有效利用预训练的 LLM 和视觉模型的功能,以实现特定视觉、语言任务。
对于图像分支,使用预训练CLIP的视觉编码器ViT-L/14,为其提供视觉特征。
为了将视觉特征和文本词向量(text embedding tokens)进行对齐,使用一个MLP将图像特征投影到词嵌入空间。也就是下面的公式:
这里有个细节,视觉特征取的不一定是ViT-L的最后一层,可能是倒数第二层。
因为CLIP训练的ViT-L,在不同层捕获到的图像特征有所区别。
1. 深层更适合OCR任务
2.浅层、中间层更适合计数、定位等推理任务
3. LLAVA选择的是倒数第二层除了CLS token以外的图像特征
笔者认为:CLIP ViT的最后一层收到了info loss的监督(特征被聚合后,容易过拟合于某个特定任务),更倾向于做分类。而使用倒数第二层(不受到直接监督)的image token,其信息量更足,更好表征图像信息。
1.2 训练
在训练阶段,首先进行特征对齐预训练;
Step1: 构造图像-文本对;每个样本对视作单轮对话。对于图像X,随机采用问题Q,要求助手简要描述图像;在训练阶段,保持视觉编码器和LLM权重的冻结,更新投影层和LLM权重。这样,图像特征I可以更好的与预训练LLM的词嵌入T进行对齐。
Step2:进行端到端训练;同样保持视觉编码器,但更新LLM权重,以及同样更新投影层和LLM权重。
2 LLaVA1.5
2.1 LLAVA1.5改进
LLAVA1.5的一个改进是增大了输入图像的尺寸。并用更少的数据(13B模型,1.2M数据,8-A100,1天的训练量)实现更好的结果。
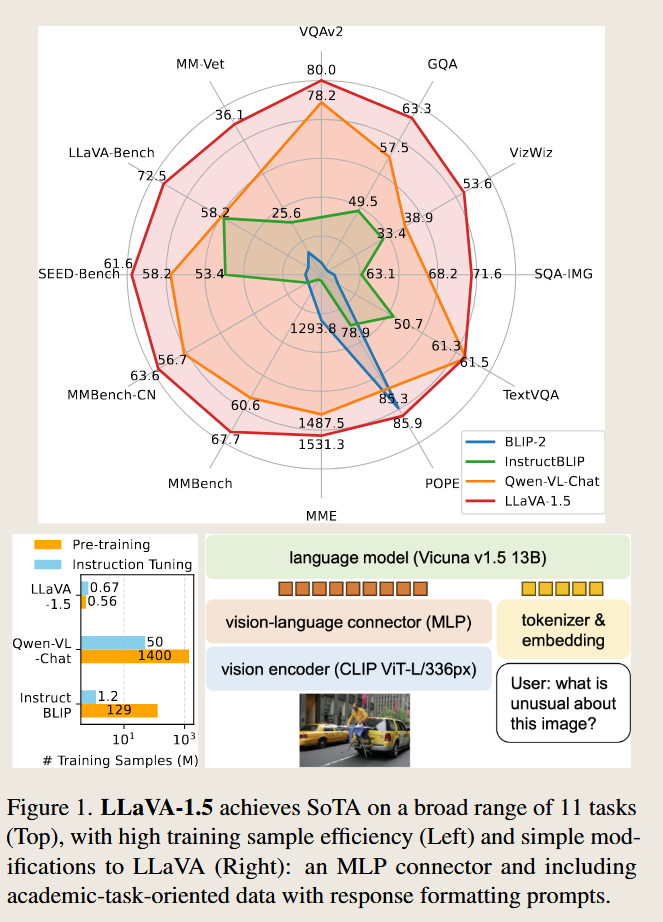
对比LLaVA的ViT-L/14(224),LLAVA1.5使用了CLIP-ViT-L-336px的输入,添加了学术任务的问答对数据。
改进1 任意大小的图像输入
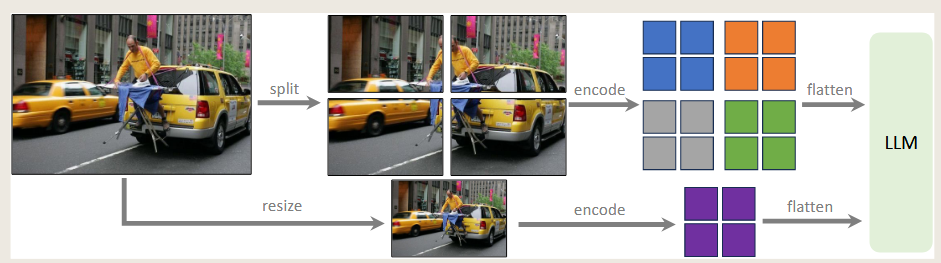
传统上对图像输入的做法是resize到224,这可能会引入伪影,可能导致大模型幻觉。LLAVA1.5这里选择将图像进行切块输入,允许模型扩展到任何分辨率。同时选择336px输入的ViT-L,增大了单块图像输入分辨率,使得LLM能够看清图像细节。
改进2 对投影层MLP做了扩展
实验发现使用两层MLP能获得更好的效果
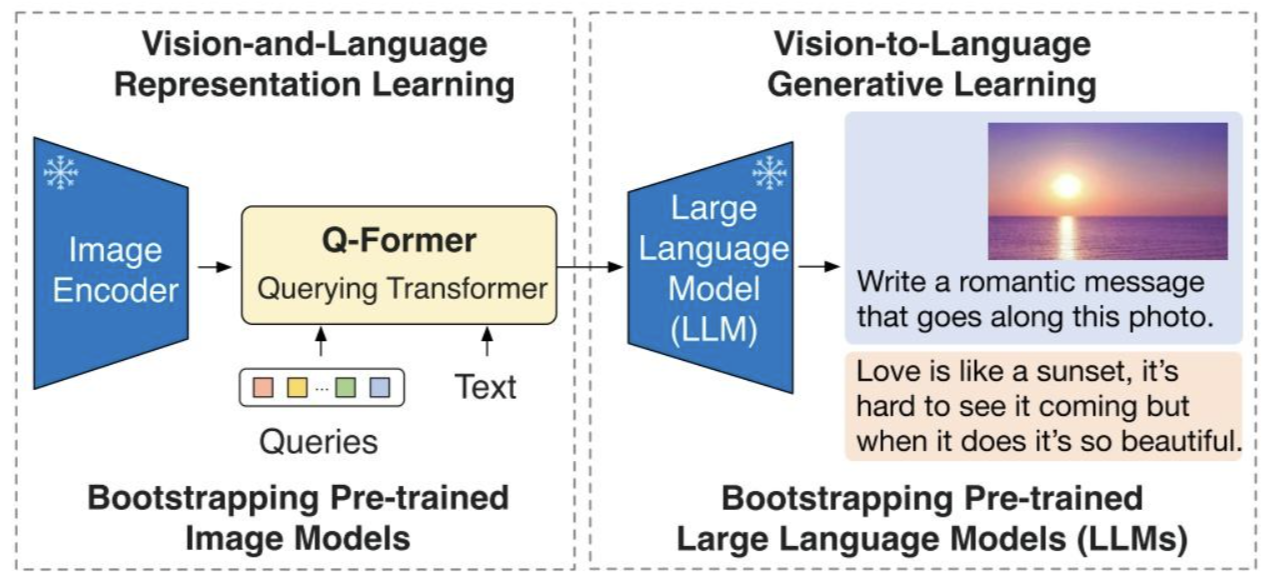
这里可能涉及到MLP和QFormer之争
作为视觉模型和LLM模型的适配器,MLP和QFormer都能够将图像特征投影到词向量嵌入空间,以便LLM进行理解。
QFormer:特点是Token数量少,会损失一些视觉信息;训练更慢;
通常做法是用一个cross-attention将visual token压缩到与Qformer中learnable queries数量的少量token(32\64),然后接入self-attention层。
MLP:结构简单,训练高效,无信息损失。但缺点是visual token会比较长,在推理时LLM计算量会更大。
3 LLaVA-NeXT
四个改进:(基本是LLaVA1.5同款,定位不同,更适合用于OCR)
1. 将输入图像分辨率提高到 4 倍像素。这使它能够捕捉更多视觉细节。它支持三种长宽比,最高可达 672x672、336x1344、1344x336 分辨率。
2. 通过改进的视觉指令调优数据混合,提高视觉推理和 OCR 能力。
3. 更好的视觉对话,适用于更多场景,涵盖不同的应用。更好的世界知识和逻辑推理。
4. 使用 SGLang 进行高效部署和推理。
4 LLaVA-OneVision
重点:可以支持单图像、多图像、视频的输入。
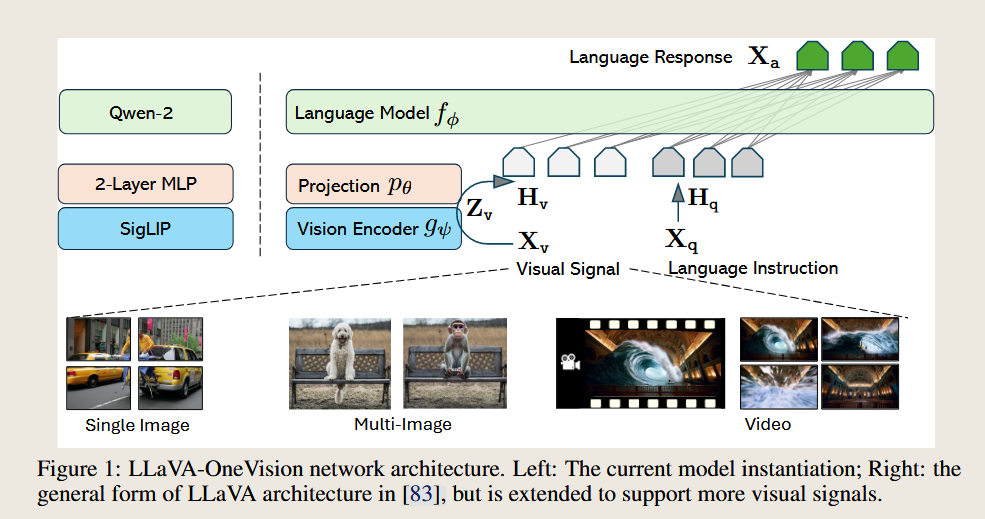
1.结构变化
架构上继承了LLaVa的设计,模型选型上有一些区别。
LLM选择了QWen-2
VIsion Encoder选择SigLIP
Projector:选择2层MLP
这里涉及到CLIP和SigLIP的区别。
重要区别:CLIP计算infoLoss时选择的Softmax,而SigLIP则选择了Sigmoid。
CLIP计算损失时,为 (查询图像寻找最佳匹配文本的loss+查询文本寻找最佳匹配图像的loss)/2, 并通过温度t进行缩放。 既然如此,CLIP在训练时就对batch的大小有所要求,batch越大,负样本越多,模型学到的区分性越强,但计算成本也越高。
而SigLIP将多分类转化为二分类任务,只对比每个样本对 image-text是否匹配。避免了批次内两两比较,这样对batch多少就不敏感了。训练更快也更灵活。
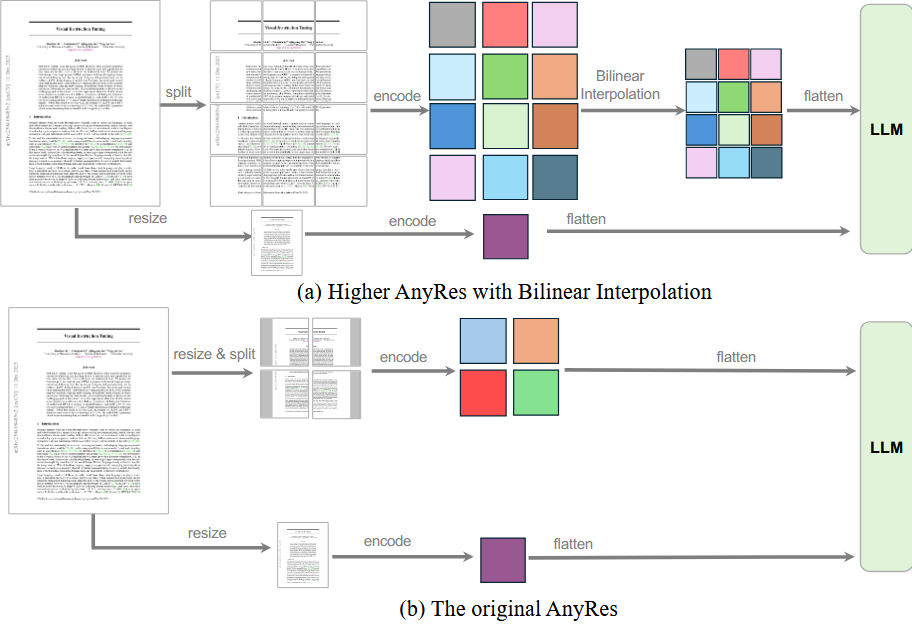
2. 输入切片变化
相比LLaVA1.5的图像切片输入(下图b),这里选择将输入的切片进行插值缩放,用于平衡性能和计算成本。
3. 图像、堆栈、视频输入
这里三种类型输入共用了一个视觉编码器。所以对不同的输入做了平衡适配。
1. 图像:图像会切为N块+原始图像输入,那就是 (1+N)*729Tokens
2. 图像堆栈:图像堆栈中,每张图像都resize到基础输入大小(不进行剪裁),然后作为输入N*729 tokens。
3. 视频:视频中每一帧都调整为基础输入大小,并进行插值减少输入的tokens。

总结
LLaVA是多模态学习路线上重要一环。视觉编码器赋予了LLM感知世界的能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)