AAAI 2025 | 狂甩传统方法几条街!PConv让红外小目标无所遁形,检测性能逆天升级
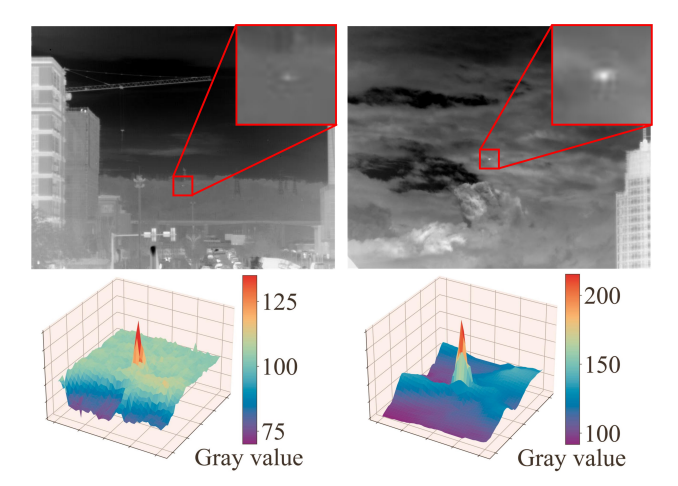
近年来,基于卷积神经网络(CNN)的红外小目标检测方法表现出色,但这些方法通常采用标准卷积,忽略了红外小目标像素分布的空间特性。为此,研究者提出了一种新颖的风车形卷积(PConv),以替代骨干网络低层的标准卷积,它更符合微弱小目标的像素高斯空间分布,能增强特征提取、显著增大感受野,且参数增加极少。此外,鉴于现有损失函数在结合尺度和位置损失时,未充分考虑不同目标尺度下这些损失的敏感性差异,限制了对微
1. 【前言】
近年来,基于卷积神经网络(CNN)的红外小目标检测方法表现出色,但这些方法通常采用标准卷积,忽略了红外小目标像素分布的空间特性。为此,研究者提出了一种新颖的风车形卷积(PConv),以替代骨干网络低层的标准卷积,它更符合微弱小目标的像素高斯空间分布,能增强特征提取、显著增大感受野,且参数增加极少。此外,鉴于现有损失函数在结合尺度和位置损失时,未充分考虑不同目标尺度下这些损失的敏感性差异,限制了对微弱小目标的检测性能,研究者提出了基于尺度的动态损失(SD Loss),可根据目标大小动态调整尺度和位置损失的影响,提升网络对不同尺度目标的检测能力。研究者还构建了新的基准数据集SIRST-UAVB,这是目前最大且最具挑战性的单帧红外小目标实拍摄影数据集。最后,将PConv和SD Loss整合到最新的小目标检测算法中,在IRSTD-1K和SIRST-UAVB数据集上均取得了显著的性能提升,验证了该方法的有效性和通用性。
另外,我整理了 AAAI 2025 论文+源码,感兴趣的可以dd,希望能帮到你!
2. 【论文基本信息】

- 论文标题:Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection
- 作者:Jiangnan Yang, Shuangli Liu, Jingjun Wu, Xinyu Su, Nan Hai, Xueli Huang
- 论文链接:https://arxiv.org/pdf/2412.16986v1(CVPR2025)
- 项目链接:https://github.com/JN-Yang/PConv-SDloss-Data
- 即插即用模块:pinwheel-shaped convolution (PConv)
3. 【算法创新点】
3.1 提出风车形卷积(PConv)
作为一种即插即用的卷积模块,其设计符合红外小目标的高斯空间分布特性,能增强底层特征提取,显著增大感受野,且参数增加极少,可替代骨干网络低层的标准卷积。
3.2 提出基于尺度的动态损失(SD Loss)
通过动态调整尺度损失和位置损失的影响系数,以适应不同目标尺度,改善神经网络在不同尺度目标上的回归能力和检测性能,适用于边界框和掩码两种标签格式。
3.3 构建SIRST-UAVB数据集
该数据集是目前最大且最具挑战性的单帧红外小目标实拍摄影数据集,包含无人机和鸟类目标,场景复杂,为相关算法提供了更贴近真实场景的评估基准。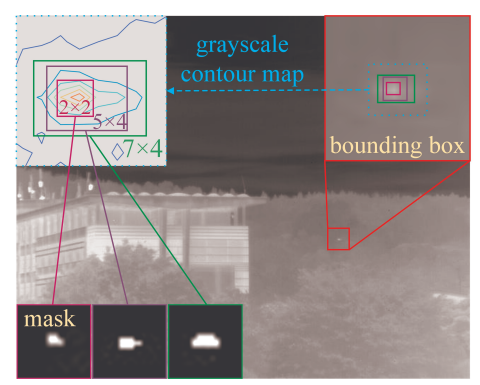
4. 【算法框架与核心模块】
4.1 算法框架
将提出的风车形卷积(PConv)替代骨干网络低层的标准卷积,同时将基于尺度的动态损失(SD Loss)应用于模型训练过程,通过整合这两个核心组件到现有红外小目标检测和分割算法中,提升模型对红外小目标的检测性能。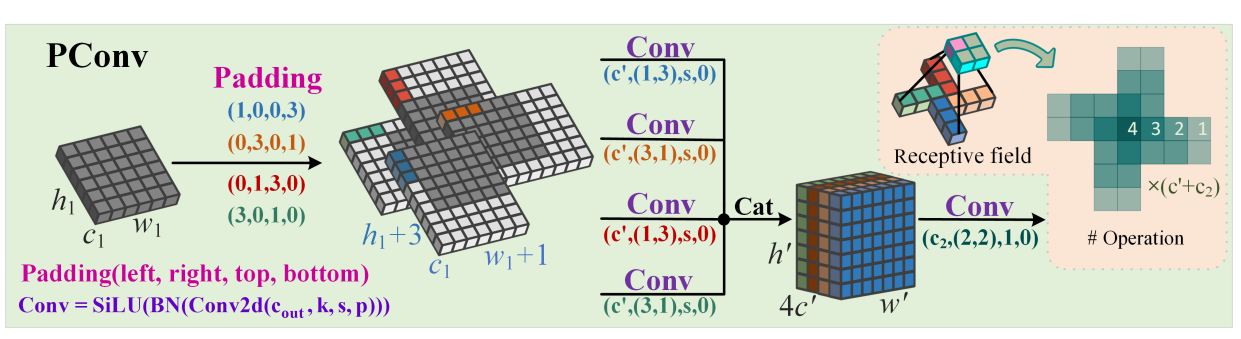
4.2 核心模块
4.2.1 风车形卷积(PConv)
- 结构:采用不对称填充,对图像不同区域使用水平和垂直卷积核,卷积核向外扩散;第一层进行并行卷积,经批归一化(BN)和SiLU激活函数处理后,将结果拼接,再通过特定卷积核归一化,输出特征图的高、宽调整为预设值,可与标准卷积层互换。
- 公式:
- 第一层并行卷积:
X 1 ( h ′ , w ′ , c ′ ) = S i L U ( B N ( X P ( 1 , 0 , 0 , 3 ) ( h 1 , w 1 , c 1 ) ⊗ W 1 ( 1 , 3 , c ′ ) ) ) X_{1}^{\left(h', w', c'\right)}=S i L U\left(B N\left(X_{P(1,0,0,3)}^{\left(h_{1}, w_{1}, c_{1}\right)} \otimes W_{1}^{\left(1,3, c'\right)}\right)\right) X1(h′,w′,c′)=SiLU(BN(XP(1,0,0,3)(h1,w1,c1)⊗W1(1,3,c′)))
X 2 ( h ′ , w ′ , c ′ ) = S i L U ( B N ( X P ( 0 , 3 , 0 , 1 ) ( h 1 , w 1 , c 1 ) ⊗ W 2 ( 3 , 1 , c ′ ) ) ) X_{2}^{\left(h', w', c'\right)}=S i L U\left(B N\left(X_{P(0,3,0,1)}^{\left(h_{1}, w_{1}, c_{1}\right)} \otimes W_{2}^{\left(3,1, c'\right)}\right)\right) X2(h′,w′,c′)=SiLU(BN(XP(0,3,0,1)(h1,w1,c1)⊗W2(3,1,c′)))
X 3 ( h ′ , w ′ , c ′ ) = S i L U ( B N ( X P ( 0 , 1 , 3 , 0 ) ( h 1 , w 1 , c 1 ) ⊗ W 3 ( 1 , 3 , c ′ ) ) ) X_{3}^{\left(h', w', c'\right)}=S i L U\left(B N\left(X_{P(0,1,3,0)}^{\left(h_{1}, w_{1}, c_{1}\right)} \otimes W_{3}^{\left(1,3, c'\right)}\right)\right) X3(h′,w′,c′)=SiLU(BN(XP(0,1,3,0)(h1,w1,c1)⊗W3(1,3,c′)))
X 4 ( h ′ , w ′ , c ′ ) = S i L U ( B N ( X P ( 3 , 0 , 1 , 0 ) ( h 1 , w 1 , c 1 ) ⊗ W 4 ( 3 , 1 , c ′ ) ) ) X_{4}^{\left(h', w', c'\right)}=S i L U\left(B N\left(X_{P(3,0,1,0)}^{\left(h_{1}, w_{1}, c_{1}\right)} \otimes W_{4}^{\left(3,1, c'\right)}\right)\right) X4(h′,w′,c′)=SiLU(BN(XP(3,0,1,0)(h1,w1,c1)⊗W4(3,1,c′))) - 输出特征图与输入特征图关系:
h ′ = h 1 s + 1 , w ′ = w 1 s + 1 , c ′ = c 2 4 h'=\frac{h_{1}}{s}+1, w'=\frac{w_{1}}{s}+1, c'=\frac{c_{2}}{4} h′=sh1+1,w′=sw1+1,c′=4c2 - 拼接结果:
X ′ ( h ′ , w ′ , 4 c ′ ) = C a t ( X 1 ( h ′ , w ′ , c ′ ) , . . . , X 4 ( h ′ , w ′ , c ′ ) ) X^{\prime\left(h', w', 4 c'\right)}=Cat\left(X_{1}^{\left(h', w', c'\right)}, ..., X_{4}^{\left(h', w', c'\right)}\right) X′(h′,w′,4c′)=Cat(X1(h′,w′,c′),...,X4(h′,w′,c′)) - 最终输出:
h 2 = h ′ − 1 = h 1 s , w 2 = w ′ − 1 = w 1 s h_{2}=h'-1=\frac{h_{1}}{s}, w_{2}=w'-1=\frac{w_{1}}{s} h2=h′−1=sh1,w2=w′−1=sw1
Y ( h 2 , w 2 , c 2 ) = S i L U ( B N ( X ′ ( h ′ , w ′ , 4 c ′ ) ⊗ W ( 2 , 2 , c 2 ) ) ) Y^{(h_{2}, w_{2}, c_{2})}=SiLU\left(B N\left(X^{\prime\left(h', w', 4 c'\right)} \otimes W^{\left(2,2, c_{2}\right)}\right) \right) Y(h2,w2,c2)=SiLU(BN(X′(h′,w′,4c′)⊗W(2,2,c2)))
- 第一层并行卷积:
- 特点:感受野呈高斯分布特性,利用分组卷积在增加感受野的同时减少参数,能增强目标与背景的对比度并抑制类杂波信号。

4.2.2 基于尺度的动态损失(SD Loss)
- 边界框的SD损失(SDB loss):
- 定义边界框尺度损失和位置损失:
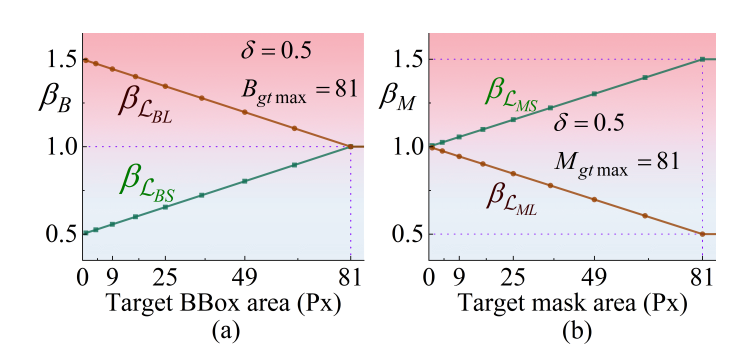
L B S = 1 − I o U + α v , L B L = ρ 2 ( b p , b g t ) c 2 \mathcal{L}_{B S}=1-I o U+\alpha v, \mathcal{L}_{B L}=\frac{\rho^{2}\left(b_{p}, b_{g t}\right)}{c^{2}} LBS=1−IoU+αv,LBL=c2ρ2(bp,bgt) - 计算影响系数:
β B = m i n ( B g t B g t m a x × R O C × δ , δ ) \beta_{B}=min \left(\frac{B_{g t}}{B_{g t max }} × R_{O C} × \delta, \delta\right) βB=min(BgtmaxBgt×ROC×δ,δ)
β L B S = 1 − δ + β B , β L B L = 1 + δ − β B \beta _{\mathcal {L}_{BS}}=1-\delta +\beta _{B}, \beta _{\mathcal {L}_{BL}}=1+\delta -\beta _{B} βLBS=1−δ+βB,βLBL=1+δ−βB - 最终损失:
L S D B = β L B S × L B S + β L B L × L B L \mathcal{L}_{S D B}=\beta_{\mathcal{L}_{B S}} × \mathcal{L}_{B S}+\beta_{\mathcal{L}_{B L}} × \mathcal{L}_{B L} LSDB=βLBS×LBS+βLBL×LBL
- 定义边界框尺度损失和位置损失:
- 掩码的SD损失(SDM loss):
- 定义掩码尺度损失和位置损失:
L M S = 1 − ω ∣ M p ⋂ M g t ∣ ∣ M p ⋃ M g t ∣ \mathcal{L}_{M S}=1-\omega \frac{\left|M_{p} \bigcap M_{g t}\right|}{\left|M_{p} \bigcup M_{g t}\right|} LMS=1−ω∣Mp⋃Mgt∣∣Mp⋂Mgt∣
L M L = 1 − m i n ( d p , d g t ) m a x ( d p , d g t ) + 4 π 2 ( θ p − θ g t ) 2 \mathcal{L}_{M L}=1-\frac{min \left(d_{p}, d_{g t}\right)}{max \left(d_{p}, d_{g t}\right)}+\frac{4}{\pi^{2}}\left(\theta_{p}-\theta_{g t}\right)^{2} LML=1−max(dp,dgt)min(dp,dgt)+π24(θp−θgt)2 - 计算影响系数:
β M = m i n ( M g t M g t m a x × R O C × δ , δ ) \beta_{M}=min \left(\frac{M_{g t}}{M_{g t max }} × R_{O C} × \delta, \delta\right) βM=min(MgtmaxMgt×ROC×δ,δ)
β L M S = 1 + β M , β L M L = 1 − β M \beta _{\mathcal {L}_{MS}}=1+\beta _{M}, \beta _{\mathcal {L}_{ML}}=1-\beta _{M} βLMS=1+βM,βLML=1−βM - 最终损失:
L S D M = β L M S × L M S + β L M L × L M L \mathcal{L}_{S D M}=\beta_{\mathcal{L}_{M S}} × \mathcal{L}_{M S}+\beta_{\mathcal{L}_{M L}} × \mathcal{L}_{M L} LSDM=βLMS×LMS+βLML×LML
- 定义掩码尺度损失和位置损失:
- 特点:根据目标大小动态调整尺度和位置损失的影响,减少标签不准确对损失函数稳定性的影响,提升不同尺度目标的检测性能。
4.3 模块配置
- PConv:用于骨干网络的前两层,替代标准卷积,可选择不同的卷积核配置(如(3,3)、(4,3)、(4,4)),其中(4,3)配置在多数情况下性能更优。
- SD Loss:在检测模型中,δ值根据目标大小选择;在分割模型中,δ=0.5通常能提供最佳平衡。
5.【实验结果】
5.1 实验设置
- 数据集:使用IRSTD-1K和SIRST-UAVB两个数据集,前者包含1000张真实红外图像,目标尺度较大,分辨率为512×512像素;后者目标更小。两个数据集均按4:1的比例分为训练集和测试集。
- 评估指标:
- 边界框标签:采用精确率(P)、召回率(R)和平均精度均值50(mAP50),其中精确率公式为 P = T P T P + F P P=\frac{TP}{TP + FP} P=TP+FPTP,召回率公式为 R = T P T P + F N R=\frac{TP}{TP + FN} R=TP+FNTP,mAP50为不同类别的AP50的平均值。
- 掩码标签:使用交并比(IoU)、虚警率( F a F_a Fa)和检测概率( P d P_d Pd),公式分别为 I o U = ∣ A p ⋂ A g t ∣ ∣ A p ⋃ A g t ∣ IoU=\frac{|A_p \bigcap A_{gt}|}{|A_p \bigcup A_{gt}|} IoU=∣Ap⋃Agt∣∣Ap⋂Agt∣、 F a = P f a l s e P a l l F_a=\frac{P_{false}}{P_{all}} Fa=PallPfalse、 P d = T p r e d T a l l P_d=\frac{T_{pred}}{T_{all}} Pd=TallTpred。
- 实现细节:在RTX3090 GPU上使用PyTorch框架进行消融实验。检测模型输入图像大小设为640,批量大小为64,训练轮次为700,耐心值为70,学习率为0.01;分割模型输入图像大小设为256,批量大小为4,训练轮次为400,学习率为0.05。
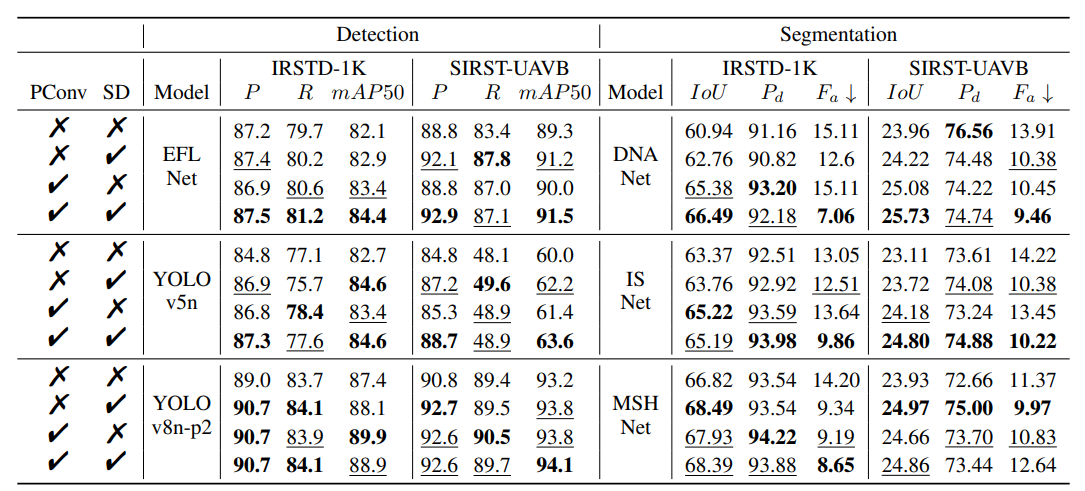
5.2 与其他方法的比较
-
卷积模块比较:在YOLOv8n-p2检测模型和MSHNet分割模型中,将PConv与多种卷积模块对比,结果显示PConv在多数指标上表现更优。如在SIRST-UAVB数据集的YOLOv8n-p2检测中,PConv(4,3)的mAP50达到93.8%,优于其他模块;在MSHNet分割中,PConv能提升IoU、 P d P_d Pd并降低 F a F_a Fa。
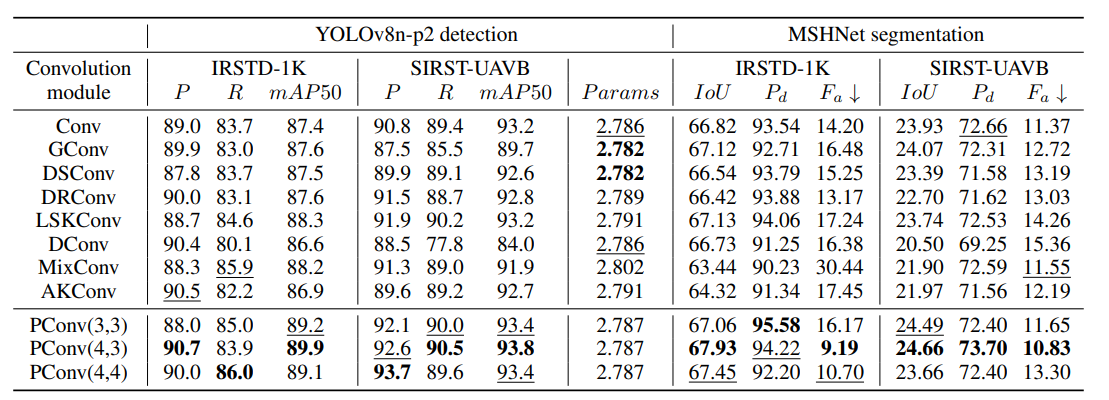
-
损失函数比较:
-
边界框损失:在YOLOv8n-p2上,SDB损失在两个数据集上均有稳定且均衡的提升,如SDB(0.7)在IRSTD-1K的mAP50为88.8%,SDB(0.3)在SIRST-UAVB的mAP50为93.9%,优于CIoU、DIoU等损失。
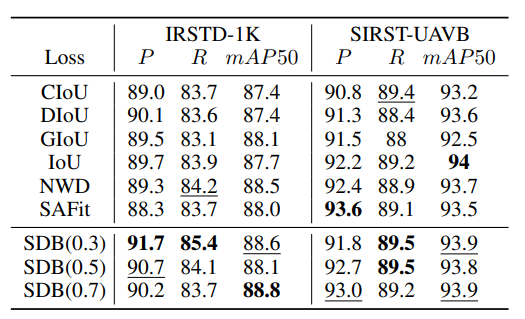
-
掩码损失:在MSHNet上,SDM损失表现更佳,如SDM(0.5)在IRSTD-1K的IoU为68.49%,在SIRST-UAVB的IoU为24.97%,优于SLS、Dice等损失。
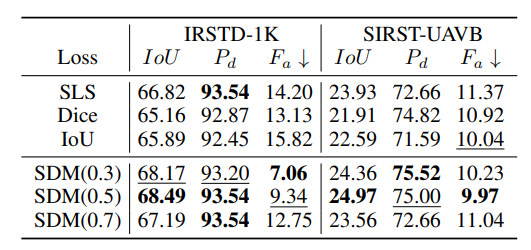
-
5.3 多模型消融实验
在EFLNet、YOLOv5n、YOLOv8n-p2等检测模型和DNANet、ISNet、MSHNet等分割模型上进行实验,结果显示PConv和SD损失的结合能持续提升性能。如YOLOv8n-p2在结合两者后,IRSTD-1K的mAP50达到88.9%,SIRST-UAVB的mAP50达到94.1%;分割模型中,两者结合也能提升IoU、 P d P_d Pd并降低 F a F_a Fa。
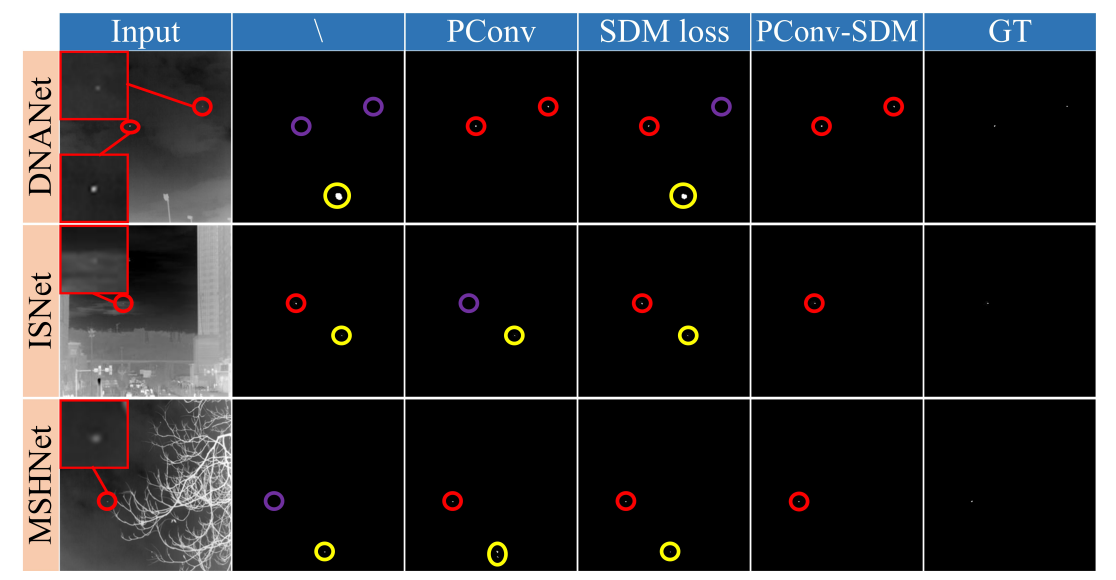
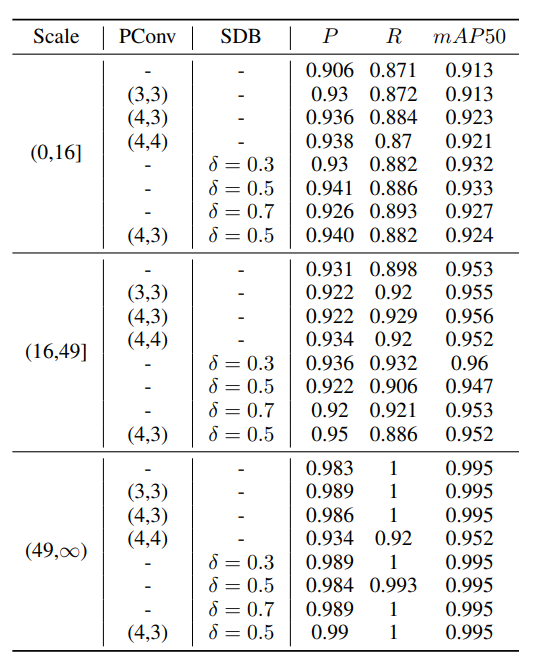
5.4 不同目标尺度的消融实验
在YOLOv8n-p2框架下对SIRST-UAVB数据集按目标尺度划分后实验,发现PConv和SDB损失在各尺度目标上均能提升检测能力,尤其对框面积小于16的小目标效果显著。如PConv(4,3)结合SDB(0.5)时,小目标的mAP50等指标有明显改善。
6.【适用任务】
6.1 医学图像分割的多源域泛化
- 适用场景:基于多个不同来源的医学图像数据集训练模型,需泛化到未见过的目标域。
- 核心作用:整合多源形态学先验,保证循环一致性,减轻域偏移,提升分割性能。
6.2 医学图像分割的单源域泛化
- 适用场景:仅用单一来源数据集训练,需向多个未知目标域泛化。
- 核心作用:借助先验知识聚焦域不变特征,缓解单源域迁移中的性能下降。
6.3 医学图像分割的测试时自适应
- 适用场景:模型部署后,需利用未标记测试数据自适应调整以应对域偏移。
- 核心作用:冻结先验指导匹配,通过无监督微调快速适应新目标域,提升分割精度。
7.【即插即用模块代码】
7.1 PConv模块
功能:实现风车形状卷积(Pinwheel-shaped Convolution),通过不对称填充(Asymmetric Padding)方法提取不同方向的特征,增强特征提取的多样性。
核心代码段(即插即用关键):
class PConv(nn.Module):
''' Pinwheel-shaped Convolution using the Asymmetric Padding method. '''
def __init__(self, c1, c2, k, s):
super().__init__()
p = [(k, 0, 1, 0), (0, k, 0, 1), (0, 1, k, 0), (1, 0, 0, k)]
self.pad = [nn.ZeroPad2d(padding=(p[g])) for g in range(4)]
self.cw = Conv(c1, c2 // 4, (1, k), s=s, p=0)
self.ch = Conv(c1, c2 // 4, (k, 1), s=s, p=0)
self.cat = Conv(c2, c2, 2, s=1, p=0)
def forward(self, x):
yw0 = self.cw(self.pad[0](x))
yw1 = self.cw(self.pad[1](x))
yh0 = self.ch(self.pad[2](x))
yh1 = self.ch(self.pad[3](x))
return self.cat(torch.cat([yw0, yw1, yh0, yh1], dim=1))
即插即用优势:无需修改网络整体架构,可直接替换传统卷积层(如在YOLOv8的backbone中使用),通过不同的不对称填充和卷积组合,有效捕捉多方向特征,提升特征提取能力,且参数和计算量控制合理。
7.2 APC2f模块
功能:基于不对称填充卷积的快速CSP瓶颈层实现(Faster Implementation of APCSP Bottleneck),用于特征融合与增强,可选择使用APBottleneck或普通Bottleneck。
核心代码段(即插即用关键):
class APC2f(nn.Module):
"""Faster Implementation of APCSP Bottleneck with Asymmetric Padding convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, P=True, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
if P:
self.m = nn.ModuleList(APBottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
else:
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
即插即用优势:兼容传统C2f模块的接口和使用方式,可直接替换网络中的C2f模块,通过引入APBottleneck增强特征提取的多样性,同时提供灵活的参数选择(是否使用APBottleneck),适应不同场景需求。
7.3 APBottleneck模块
功能:不对称填充瓶颈层(Asymmetric Padding bottleneck),通过多组不对称填充和卷积操作提取特征,增强特征表达能力,可作为基础组件用于构建更复杂的网络模块。
核心代码段(即插即用关键):
class APBottleneck(nn.Module):
"""Asymmetric Padding bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e) # hidden channels
p = [(2,0,2,0),(0,2,0,2),(0,2,2,0),(2,0,0,2)]
self.pad = [nn.ZeroPad2d(padding=(p[g])) for g in range(4)]
self.cv1 = Conv(c1, c_ // 4, k[0], 1, p=0)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2((torch.cat([self.cv1(self.pad[g](x)) for g in range(4)], 1))) if self.add else self.cv2((torch.cat([self.cv1(self.pad[g](x)) for g in range(4)], 1)))
即插即用优势:可直接替换网络中的普通Bottleneck模块,通过多组不同的不对称填充方式,增加特征提取的角度和多样性,且保持与原Bottleneck相似的计算复杂度,易于集成到现有网络架构中。
7.4 SLSIoULoss模块
功能:结合尺度动态调整的IoU损失函数(包括SLSIoULoss和SDM Loss),用于优化目标检测或分割任务中的预测精度,考虑了目标尺度、距离等因素。
核心代码段(即插即用关键):
class SLSIoULoss(nn.Module): # https://github.com/Lliu666/MSHNet
''' SLSIoULoss and our SDM Loss '''
def __init__(self):
super(SLSIoULoss, self).__init__()
def forward(self, pred_log, target, warm_epoch, epoch, with_distance=True, dynamic=True, delta=0.5):
pred = torch.sigmoid(pred_log)
h = pred.shape[2]
w = pred.shape[3]
smooth = 0.0
R_oc = 512 * 512 / ( w * h )
intersection = pred * target
intersection_sum = torch.sum(intersection, dim=(1, 2, 3))
pred_sum = torch.sum(pred, dim=(1, 2, 3))
target_sum = torch.sum(target, dim=(1, 2, 3))
dis = torch.pow((pred_sum - target_sum) / 2, 2)
alpha = (torch.min(pred_sum, target_sum) + dis + smooth) / (torch.max(pred_sum, target_sum) + dis + smooth)
loss = (intersection_sum + smooth) / \
(pred_sum + target_sum - intersection_sum + smooth)
if epoch > warm_epoch:
siou_loss = alpha * loss
if dynamic:
lloss = LLoss(pred, target)
beta = (target_sum * delta * R_oc) / 81
beta = torch.where(beta > delta, torch.tensor(delta), beta)
beta = beta.mean()
if with_distance:
loss = (1 + beta) * (1 - siou_loss.mean()) + (1 - beta) * lloss # SDM loss
else:
loss = 1 - siou_loss.mean()
else:
if with_distance:
lloss = LLoss(pred, target)
loss = 1 - siou_loss.mean() + lloss
else:
loss = 1 - siou_loss.mean()
else:
loss = 1 - loss.mean()
return loss
即插即用优势:可作为损失函数直接替换目标检测或分割任务中的传统IoU损失、Dice损失等,通过动态调整参数(如beta)适应不同尺度目标,提升对小目标和不同距离目标的检测/分割精度,且支持热身训练(warm_epoch)设置,便于模型收敛。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)