(论文速读)从语言模型到通用智能体
通用具身代理(GEA),通过多模态大语言模型实现跨领域任务统一处理。核心创新包括:1)设计多体验动作分词器,将异构动作统一编码为token序列;2)采用两阶段训练策略(监督学习+在线强化学习);3)实现跨领域知识迁移。实验表明,GEA在机器人操控(94.7% Meta-World)、游戏(44% Procgen专家水平)等任务中显著超越基线方法7-22%。关键发现:在线强化学习对错误恢复能力至关重
论文题目:From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons(从多模式大型语言模型到多面手具身代理:方法和教训)
会议:CVPR2025
摘要:我们研究了多模态大型语言模型(Multimodal Large Language Models, mllm)处理不同领域的能力,这些领域超出了这些模型通常训练的传统语言和视觉任务。具体来说,我们关注的是嵌入式AI、游戏、UI控制和计划等领域。为此,我们介绍了一个将mllm应用于通用具身代理(GEA)的过程。GEA是一个单一的统一模型,能够通过多体现动作标记器在这些不同的领域中扎根。GEA的训练方法是在大型具体化经验数据集上进行监督学习,并在交互式模拟器中进行在线强化学习。我们将探索开发这种模型所需的数据和算法选择。我们的研究结果揭示了使用跨领域数据和在线强化学习进行训练对于构建多面手智能体的重要性。与其他通用模型和特定于基准的方法相比,最终的GEA模型在不同基准上实现了对未见任务的强大泛化性能。
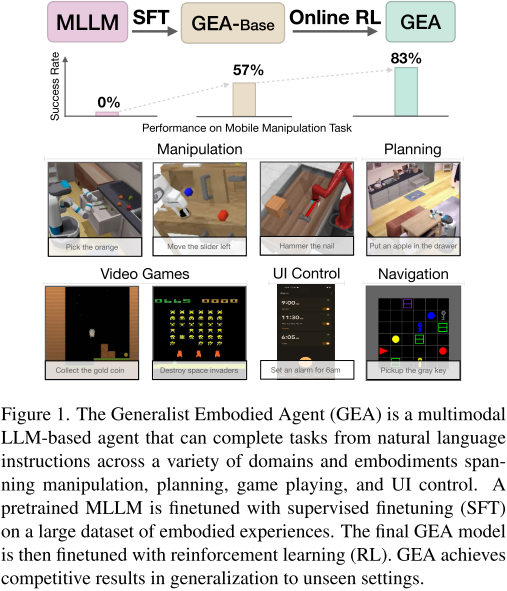
引言:AI智能体的新里程碑
想象一下,一个AI模型能够同时完成机器人抓取苹果、玩《太空入侵者》游戏、设置手机闹钟,以及规划复杂的家务任务。这听起来像科幻小说,但Apple和Georgia Tech的研究团队通过**Generalist Embodied Agent (GEA)**让这一愿景成为现实。
这项工作代表了embodied AI领域的重要突破,将多模态大语言模型的能力扩展到了前所未有的应用范围。
核心挑战:从语言理解到行动执行
现有方法的局限性
传统的embodied AI系统通常面临以下问题:
- 域特化严重:大多数系统只能在特定环境中工作,如只做机器人操控或只玩特定游戏
- 动作空间异构:不同任务需要完全不同的控制方式
- 机器人:连续的关节角度控制
- 游戏:离散的按键操作
- UI控制:坐标点击和文本输入
- 数据稀缺性:专家演示数据有限,且缺乏错误恢复示例
GEA的解决方案
研究团队提出了一个统一的智能体架构,能够通过单个模型处理多样化的embodied任务。关键创新在于:
- 设计了通用的动作表示方法
- 建立了有效的跨域训练策略
- 结合了监督学习和强化学习的优势
技术架构:构建通用智能体的三大支柱
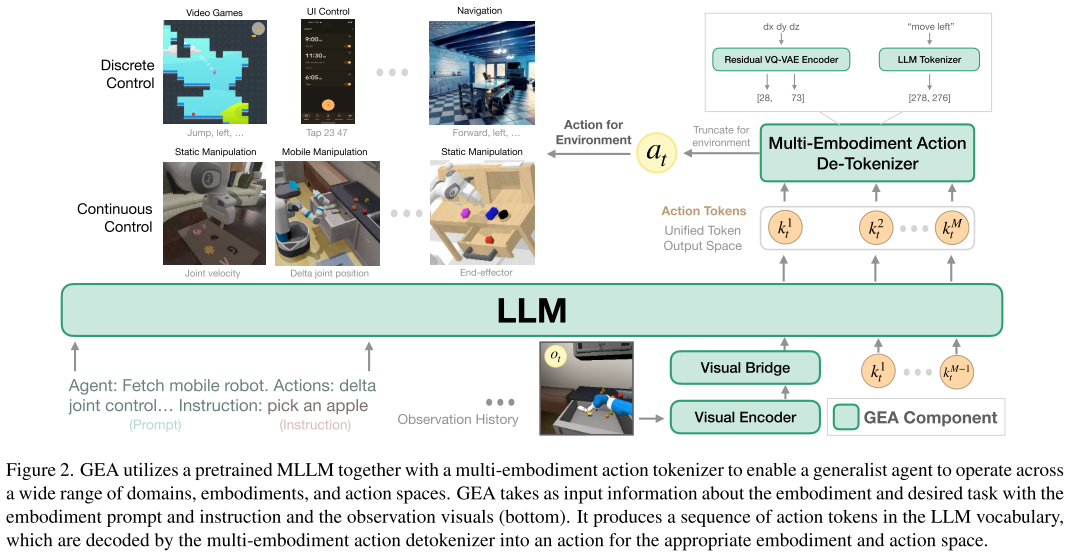
1. 多体验动作分词器
核心问题:如何让一个语言模型理解和输出各种不同类型的动作?
解决方案:使用Residual VQ-VAE技术将所有动作统一编码为token序列
连续动作(机器人关节控制) → RVQ编码 → [k₁, k₂, ..., kₘ] → 语言模型token
离散动作("向左移动") → 文本分词 → ["move", "left"] → 语言模型token
这种设计让模型能够:
- 统一处理机器人的7维关节控制和游戏的简单按键操作
- 在推理时根据具体环境截取相应维度的动作
- 保持动作表示的精度和效率
2. 两阶段训练策略
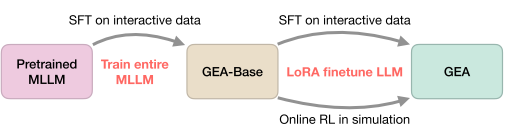
阶段一:监督微调(SFT)
- 数据规模:220万条成功轨迹
- 覆盖领域:机器人操控、导航、游戏、UI控制、规划
- 目标:让模型学会基本的感知-动作映射
阶段二:在线强化学习
- 算法:PPO + 持续SFT
- 环境:Habitat Pick、语言重排列、Procgen游戏
- 目标:提升鲁棒性和错误恢复能力
3. 跨域知识迁移
研究发现,不同域之间存在有益的知识迁移:
- 机器人操控的空间推理能力可以帮助游戏任务
- UI控制的精确定位技能可以提升机器人抓取性能
- 导航任务的路径规划思维对复杂操控任务有帮助
实验结果:全面超越现有方法
操控任务表现
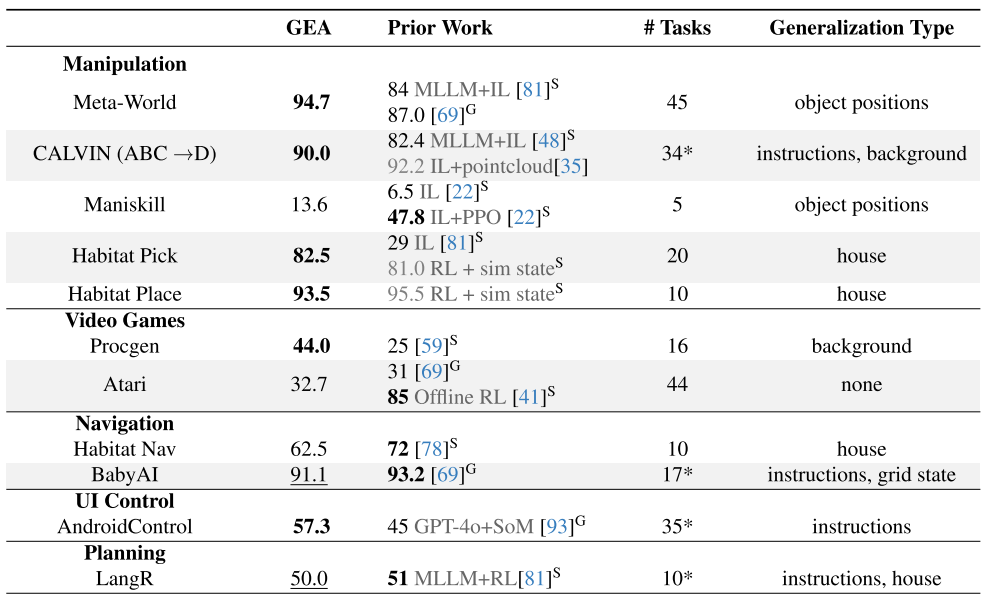
| 基准测试 | GEA性能 | 最佳基线 | 提升幅度 |
|---|---|---|---|
| Meta-World | 94.7% | 87.0% | +7.7% |
| CALVIN | 90.0% | 82.4% | +7.6% |
| Habitat Pick | 82.5% | 81.0% | +1.5% |
视频游戏表现
- Procgen: 44%专家水平(vs 25%基线)
- Atari: 32.7%专家水平,超越通用基线Gato
其他域表现
- UI控制: 57.3%成功率,超越GPT-4o+专用感知系统
- 导航: 在BabyAI达到91.1%成功率
- 规划: LangR任务达到50%成功率
关键发现:训练策略的重要启示
1. 在线RL的决定性作用
实验对比显示:
- 仅SFT的GEA-Base:60.5%(Habitat Pick)
- 加入在线RL的GEA:82.5%(+22%提升)
原因分析:
- SFT只学习成功案例,缺乏错误恢复能力
- 在线RL能够探索更多样的状态空间
- 交互式学习更符合embodied任务的特性
2. 跨域数据的协同效应
多域联合训练 vs 单域训练的对比:
- 所有测试域都从多域训练中受益
- 操控任务受益最大(丰富的操控数据相互增强)
- 即使是看似无关的域也存在知识迁移
3. 基础模型的影响
- 模型规模越大,embodied任务性能越好
- 视觉编码器的预训练比语言模型更关键
- 不同的基础MLLM(LLaVA-OneVision vs MM1.5)性能相近
技术细节:实现通用智能体的工程实践
训练效率优化
计算资源:
- 阶段一:8节点×8 H100 GPU,2天
- 阶段二:8节点×8 H100 GPU,1天
- 总计算量:约1亿步强化学习
内存优化:
- 使用LoRA微调减少内存占用
- 约束解码确保动作有效性
- PopArt归一化处理多环境奖励差异
数据处理管道
-
数据收集:多种来源的轨迹数据
- 人类演示:CALVIN、AndroidControl
- RL专家:Habitat、Procgen、Atari
- 运动规划:Maniskill导航任务
-
数据格式统一:
- 观察:RGB图像序列
- 指令:自然语言描述
- 动作:统一token序列
-
质量控制:仅使用成功轨迹进行SFT训练
局限性与未来方向
当前局限
- 性能天花板:某些域(如Maniskill、AndroidControl)仍有较大改进空间
- 零样本能力有限:无法直接控制完全新的体验类型
- 计算成本较高:大规模多域训练需要大量资源
改进方向
- 扩展RL训练:将在线学习应用到更多域
- 增强泛化能力:研究更好的跨体验迁移方法
- 提升效率:开发更高效的训练和推理算法
影响与意义:迈向通用人工智能的重要一步
学术贡献
- 方法论突破:证明了跨域训练在embodied AI中的有效性
- 技术创新:多体验动作分词器为统一控制提供了新思路
- 实证发现:在线RL对embodied任务的重要性
应用前景
- 家用机器人:一个模型处理清洁、整理、烹饪等多种任务
- 智能助手:同时控制多种设备和应用程序
- 自动化系统:跨平台的统一控制解决方案
产业影响
- 降低了开发多任务智能体的门槛
- 为robotics即服务(RaaS)提供了技术基础
- 推动了AI从理解到行动的paradigm shift
结语:通用智能体时代的序幕
GEA的成功表明,通过合适的架构设计和训练策略,我们可以构建真正的通用智能体。这不仅是技术上的突破,更代表了AI从"专才"向"通才"的重要转变。
虽然距离真正的通用人工智能还有距离,但GEA为我们展示了一个清晰的发展路径:
- 统一的表示学习
- 跨域的知识迁移
- 交互式的能力获取
随着计算资源的增长和数据的丰富,我们有理由期待更加强大和通用的embodied AI系统。未来的智能体将不再局限于特定任务,而是能够像人类一样灵活地适应和学习新的环境与挑战。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)