Qwen-VL系列-国产大模型开眼看世界
阿里Qwen-VL系列多模态模型技术解析:Qwen-VL基于Qwen-7B架构,通过ViT-BigG/14视觉编码器和仅0.08B参数的Adapter实现图文跨模态理解,支持中英文及多图对话。Qwen2-VL创新引入动态分辨率处理机制和M-RoPE位置编码,突破传统ViT的固定分辨率限制。Qwen2.5-VL进一步强化文档解析、长视频理解能力,采用窗口注意力机制和MLP投影层优化计算效率。三代模型
阿里Qwen系列包含众多分支,这里主播主要详解Qwen-VL部分。
1. Qwen-VL
Qwen-VL(基于Qwen7B)具有理解视觉和语言指令的多功能能力。这些模型在各种评估基准中优于当前的开源视觉语言模型,并支持中文和英文的文本识别和视觉基础。此外,这些模型还可以实现多图像对话和讲故事。
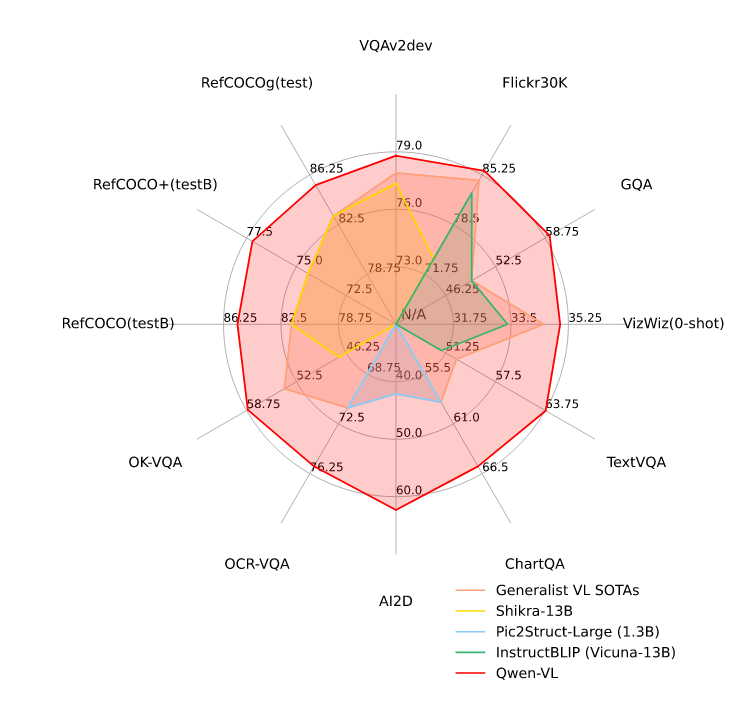
先上数据Qwen-VL在多个测试上都获得了SOTA的效果。主播在自己的微调数据上实测也获得了十分好的效果。并且支持各种图片问答。
1 模型选型
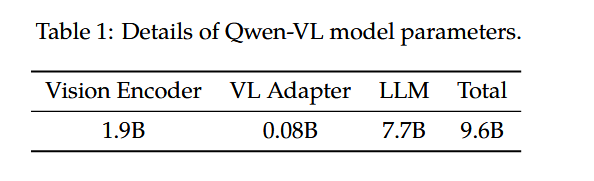
LLM:LLM选择了Qwen自家的Qwen-7B。
Visual Encoder:选择ViT-BigG/14。
Adapter: 引入了新的visual-text connector;使用一组learnable query embedding用于Query,将图像特征作为交叉注意力的Key,将视觉特征序列固定为256的长度。这个Adapter仅0.08B参数。
参数量见下表
2 输入输出细节
图像输入:视觉编码器的特征通过Adapter后,编码为固定长度256的序列,并用<img>进行标记开头和结尾,用于区分图像token和文本token
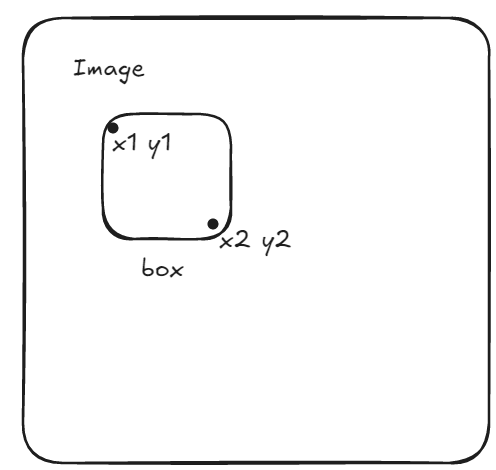
bounding box输入:涉及到Box的部分,指定字符串格式为[X左上角,Y左上角,X右下角,Y右下角],这是绝对位置框。直接给到左上角和右下角的坐标作为box输入。不过需要注意,坐标范围限定在[0, 1000]。边界框的字符串有<box>标记。注意与引用边界框的区别:因为存在引用文本描述,使用<ref>进行标记内容。
3 训练细节
预训练阶段:
利用大规模、若标记的、网络爬虫的图像-文本对。从50亿样本中,清洗了一部分数据,留下14亿样本,包括77.3%英文和22.7%的中文样本。
训练时冻结LLM模型,只优化Visual Encoder和VL adapter,输入图像调整为224,目标是最小化text token的交叉熵。batch=30720,使用了约15亿样本对。
多任务训练阶段:
引入了更大的输入分辨率的高质量、细粒度的VL标注数据和文本数据。此时视觉编码器的输入分辨率调整为448,以减少下采样损失(patch size调整为28)。
随之解锁LLM部分权重,一起参与训练。
监督微调
这一阶段进行指令微调,增强Qwen-VL跟随指令和对话能力。
2. Qwen2-VL
对Qwen-VL进行了升级,其中包括引入了不同分辨率输入的处理机制、集成了多模态旋转位置嵌入M-RoPE。
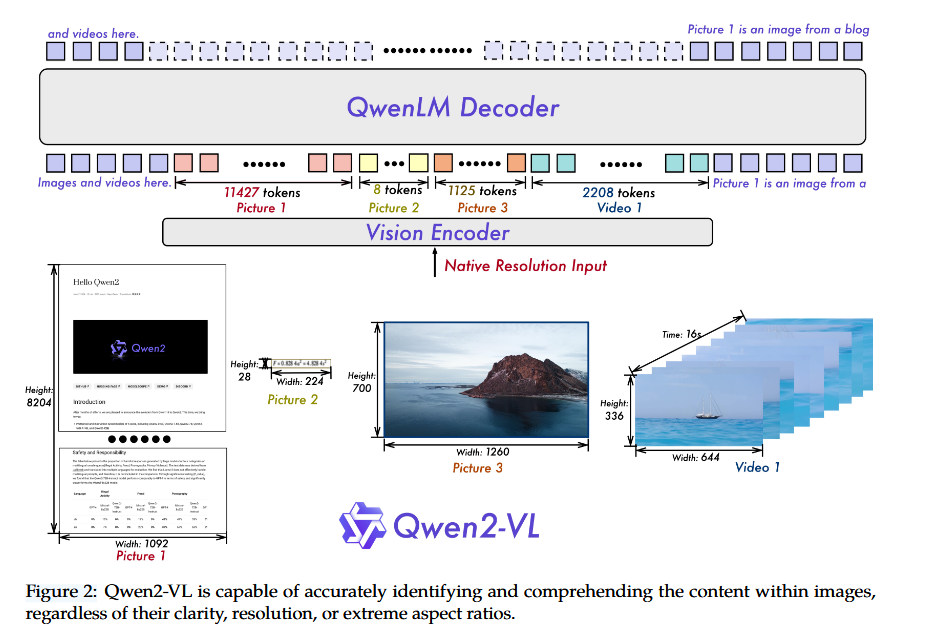
改进点
1 Visual Encoder多分辨率适应
传统做法比如LLaVa1.5通过对高分辨率图像进行切片,然后拼接到整图用于输入。
为了让Visual Encoder模块适应多分辨率的输入,Qwen2在训练中引入了动态分辨率训练。在ViT中采用了二维旋转嵌入RoPE,使得模型能够更好捕获不同空间尺度的信息。
Naive Dynamic Resolution
通过引入RoPE,Qwen2-VL支持任何分辨率的图像输入,并将其转化为不同长度的视觉token。
实现原理:将ViT原来的余弦位置编码改为旋转位置编码(2D-RoPE),用来捕获图像patch的二维位置。在推理阶段,不同分辨率的图像会被打包为一个序列。通过一个MLP将图像序列进行压缩:2*2 token -> 1 token,使用<vision_start>和<vision_end>作为压缩后视觉开始和结束的标记。
比如:输入224*224 image 、14patch size -> 16*16 patch token-> 8*8 token + start+end = 66 token
问题来了,为什么余弦位置嵌入不支持动态分辨率,你RoPE就可以?
我们先看余弦位置嵌入,这是一种绝对位置嵌入的方式;
传统的LLM模型,通常使用绝对位置编码(余弦位置嵌入or learnable embedding),这组编码是固定的、可学习的向量,每个向量对应图像的一个patch位置,是一一对应的。
那么问题是,对于224*224的图像,16patch_size下会生成14*14=196个patch。模型就会为这196个位置学习一个特定的位置编码。你完成训练后,你想输入一张448*448图像的时候傻眼了,模型报错说size不对啊,因为patch_size还是16,448的图像就生成28*28=784个patch,可是模型只学了前196个位置嵌入,后面的patch他完全不知道放哪里,他办不到。
当然,有人会想到,我对patch_size进行修改,或者我对embedding进行插值不就能输入448了。这当然能行,但是训练模型的时候用的224,推理时候会损失性能。
从ViT代码和Attention角度来理解,图像嵌入后,绝对位置编码是加在特征中的,在计算attention时,取到的是两个patch的绝对位置。输入大小变了,绝对位置也就变了。
输入向量
Query\Key:

Attention score =
绝对位置Pi已经深深刻在attention中了。等回头再去改变已然来不及。
我们再看RoPE为什么可以支持动态分辨率。
RoPE是相对位置编码,不依赖于固定的位置索引表,而是通过数学公式将patch信息进行嵌入。
1 想象一下在直角坐标系中,每一个图像patch都有一个坐标(x,y),比如第一个是(0,0),最后一个是(13,13).
2 我们将这些坐标转化为旋转角度:使用RoPE公式对坐标进行旋转,旋转角为(θx, θy)。
3 在计算patch两两之间的attention时,你会发现你计算的依据是两个patch的相对距离。
我们依然从Attention角度来理解:
输入向量
Query、Key:经过RoPE旋转,变为

Attention score =
因为Q、K是通过旋转角计算的,那么相对距离只和j-i的相对旋转角度有关。
Attention score =
这样计算注意力就不依赖i和j的绝对位置了,反而变成了i和j的相对位置
回到Qwen2-VL
Multimodal Rotary Position Embedding (M-RoPE)
因为文本和图像、Video都需要进行嵌入,这里使用了M-RoPE的旋转嵌入手段。增加了Time维度。

其实M-RoPE可以解构为长、宽、Time,
文本输入:等同于 1D-RoPE。每个token给了固定的ID ( x,x,x)。
图像输入:每个视觉标记的time ID 保持不变,而不同的图像patch会被分配不同的ID (x,y,0)。
视频帧序列:每帧的时间Time ID会递增,单张帧可以认作是固定ID的图像输入(x,y,T)。
统一图像、视频理解
在训练时,混合了图像和视频,保证大模型能够掌握图像理解和视频理解。
视频每秒采样2帧。集成3D卷积对更多的视频帧进行处理。长视频处理时,动态调整视频帧分辨率,视频token数限制为16384。
训练策略-3阶段
1. 利用文本-图像对进行训练,只训练视觉模块。 600 b tokens;视觉编码器使用DFN's ViT(RoPE).
2. 解冻所有参数,进行全面训练。
3. 冻结ViT参数,对LLM进行指令微调。
整个训练阶段使用了1.4万亿的tokens。
数据格式:
同Qwen-VL相同,使用<vision_start> <vision_end>进行隔离视觉token。
对话时,指令微调数据集,每个交互语句都有<|im_start|> <|im_end|>作为标记,方便对话开始和终止。
box框:和Qwen-VL一样,使用绝对位置"(x1,y1),(x2,y2)",取值为[0,1000)。数值为左上角和右下角的绝对位置。
用<|box_start|>和<|box_end|>划分。
3. Qwen2.5-VL
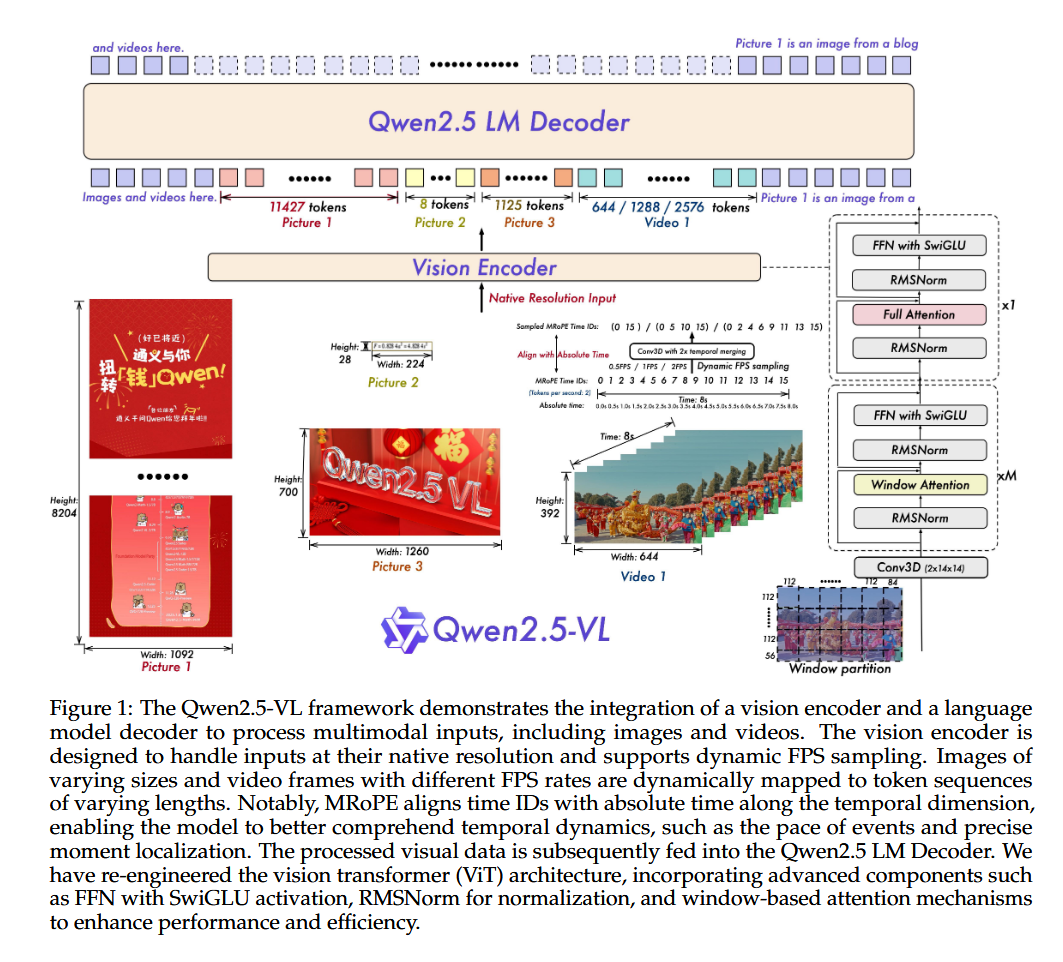
Qwen2.5-VL在Qwen2-VL的基础上做了一些细节变动和业务扩展。
1. 增强了文档解析能力。
2.适应绝对坐标和json格式的输出,实现了空间推理能力。(作者也是通过Qwen2.5-VL实现了对特定物体的目标框输出,效果非常不错)
3.超长视频理解,能够理解数个小时的长视频。
4. 在端侧部署推理上提供助力。
模型结构
1. LLM
选择了最新的Qwen2.5。将RoPE修改为绝对时间对齐的多模态旋转位置嵌入。
2 Vision Encoder
重新设计了视觉ViT网络,结合2D-RoPE和窗口注意力来支持原生分辨率。训练和推理时,图像patch为14.
这里团队做了类似Swin Transformer的改动,只有4层用了全局的多头注意力(比如7,15,23,31),其余层全部使用窗口注意力,最大窗口为112*112(对应了8*8个 patches)。
处理视频时,将patch扩展到3D形状(14*14个patches)。将两个连续帧组合在一起,变相提高了处理效率。
ViT结构细节上,选择RMSNorm进行归一化,采用SwiGLU作为激活函数。
这里可以思考下,为什么不用LayerNorm、BatchNorm
有什么区别?
为什么CNN中可以用BatchNorm,而Transformer中都用LayerNorm和BatchNorm?
视觉模块训练时,采用了CLIP预训练、视觉语言对齐和端到端微调。
3 MLP投影层
相比之前的Qwen用transformer进行投影,这里使用简单的MLP来进行投影。因为输入的图像序列更长了,使用transformer太慢。
细节在于,事先将图像特征进行压缩,将空间相邻的4个token进行分组,然后输入到两层MLP中,嵌入到文本token中。这样还可以动态压缩不同长度的图像特征序列。
4 动态分辨率输入和帧采样策略
Qwen2。5-VL在空间和时间维度上做了改进。
空间中,不同大小的图像都动态转化为具有相应长度的标记序列。
与规范化坐标的传统方法不同,我们的模型直接使用输入图像的实际尺寸来表示边界框、点和其他空间特征。这使得模型能够本质上学习比例信息,从而提高其处理不同分辨率图像的能力。
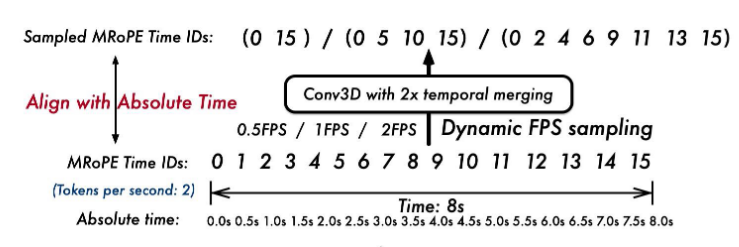
对于视频输入,结合动态帧率训练和绝对时间编码。
通过适应可变帧率,模型可以更好地捕捉视频内容的时间动态。
引入了一种新颖且有效的策略,将 M-RoPE ID直接与时间戳对齐。这种方法允许模型通过时间维度 ID 之间的间隔来理解时间节奏,而无需任何额外的计算开销。
将 MRoPE 的时间分量与绝对时间对齐。通过利用时间 ID 之间的间隔,该模型能够学习不同 FPS 采样率的视频之间的一致时间对齐。
帧采样时制定了 h-m-s-f的时间戳用于对齐。
训练
用内部数据做了ViT的预训练。
同样是分步训练,
第一阶段仅训练视觉ViT;
第二阶段解冻所有层,进行训练;
第三阶段,增加序列长度,结合视频等数据,扩展上下文能力和多模态能力。
前两阶段最长序列为8192 token, 第三阶段最长为32768 token

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)