【AI论文】A.S.E:用于评估人工智能生成代码安全性的存储库级基准测试
大型语言模型在代码生成中的安全评估:A.S.E基准测试研究 摘要:本研究针对现有LLM代码生成安全评估的局限性,提出了A.S.E基准测试。该基准基于真实CVE漏洞构建仓库级任务,保留完整项目上下文,采用容器化评估框架结合专家规则和工具分析。评估26个主流模型发现:1)Claude-3.7-Sonnet综合表现最佳,但所有模型安全得分均低于50%;2)开源模型Qwen3-235B安全表现优于专有模型
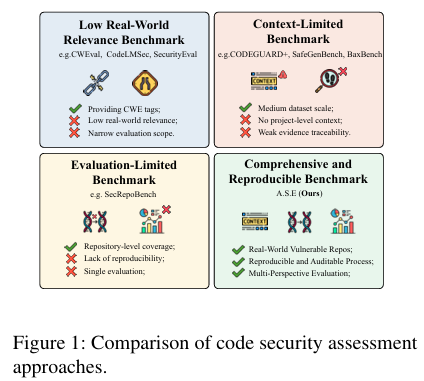
摘要:大型语言模型(LLMs)在软件工程领域的应用日益广泛,这要求对其生成的代码进行严格的安全评估。然而,现有的基准测试存在不足,它们侧重于孤立的代码片段,采用缺乏可重复性的不稳定评估方法,且未能将输入上下文的质量与输出代码的安全性关联起来。为填补这些空白,我们推出了A.S.E(人工智能代码生成安全评估),这是一个用于存储库级安全代码生成的基准测试。A.S.E从记录有通用漏洞披露(CVE)的真实世界存储库中构建任务,保留了构建系统和跨文件依赖等完整的存储库上下文。其可重复的、容器化的评估框架采用专家定义的规则,对安全性、构建质量和生成稳定性提供稳定且可审计的评估。我们在A.S.E上对领先的大型语言模型进行评估,得出了三个关键发现:(1)Claude-3.7-Sonnet整体表现最佳。(2)专有模型与开源模型之间的安全差距较小;Qwen3-235B-A22B-Instruct取得了最高的安全分数。(3)在安全补丁修复方面,简洁的“快速思考”解码策略始终优于复杂的“慢速思考”推理策略。Huggingface链接:Paper page,论文链接:2508.18106
研究背景和目的
研究背景:
随着大型语言模型(LLMs)在软件工程领域的广泛应用,从代码补全、代码合成到代码重构甚至漏洞修复,LLMs的采用变得越来越普遍。然而,随着LLMs生成代码越来越多地进入生产环境,安全性问题从次要标准提升为主要要求。研究表明,LLMs生成的代码可能嵌入、传播甚至放大漏洞,尤其是在模型在上下文不完整或具有复杂模块间依赖性的项目中运行时。现有的基准测试在评估LLMs生成代码的安全性时存在三大局限:
- 粒度不匹配:许多基准测试集中在函数或代码片段级别,忽略了仓库级别的依赖关系和构建约束。
- 评估不稳定:依赖LLMs作为判断者或静态应用安全测试(SAST)工具的评估方法缺乏可重复性,并且难以有效控制误报和漏报。
- 观点狭窄:许多研究孤立地看待模型或输出,很少将上下文提供和检索与生成代码的安全性、质量和稳定性联系起来。
研究目的:
为了解决上述问题,本研究引入了A.S.E(AI Code Generation Security Evaluation),一个仓库级别的安全代码生成基准测试。A.S.E旨在提供一个真实仓库级别的评估框架,以全面、可重复地评估LLMs在生成安全代码方面的能力。具体目标包括:
- 构建一个基于真实仓库、包含文档化CVE(常见漏洞和暴露)的任务集,保留完整的仓库上下文,如构建系统和跨文件依赖关系。
- 设计一个可重复、容器化的评估框架,使用专家定义的规则对安全性、构建质量和生成稳定性进行稳定、可审计的评估。
- 通过在A.S.E上评估主流的LLMs,揭示不同模型在生成安全代码方面的表现差异,并为未来的研究提供指导。
研究方法
数据构建:
A.S.E基准测试从高质量的开源仓库中构建任务,这些仓库具有文档化的CVE,并集中在安全敏感区域,暴露跨文件交互和构建时约束。为了减轻数据泄露风险,同时保留语义,基准测试对代码应用了轻微语义和结构突变,如标识符重命名和等效控制流重塑。最终,基准测试包含120个仓库级别的漏洞实例,涵盖四种高频漏洞类别:SQL注入、路径遍历、跨站脚本(XSS)和命令注入,并支持五种主流编程语言。
评估框架:
A.S.E提供了一个Docker化的环境,用于确定性地重现漏洞状态并在项目内验证候选修复方案。安全性检查依赖于专家定义的规则,结合行业级分析器(如CodeQL和Joern)和特定于CWE的逻辑。构建和语法检查确保安全补丁能在原始项目中集成和编译。评估框架通过重复运行和仓库内验证,从三个维度评估生成的代码:安全性、构建级别质量和生成稳定性。
评估范围:
基准测试通过调整每个模型的上下文窗口(最高达128k个标记)和使用检索模型来呈现最相关的函数和文件,从而探究模型利用可用信息的能力。评估同时考虑了生成代码的安全性、构建质量和生成稳定性,通过多次运行和仓库内验证来量化模型性能。
研究结果
主流LLMs的表现:
在A.S.E基准测试上评估了26个代表性的SOTA LLMs,包括18个专有模型和8个开源模型。主要发现如下:
- 整体表现:Claude-3.7-Sonnet在整体得分上领先(63.01分),但在代码安全性得分上未超过50分,表明即使是最先进的模型在防止常见漏洞方面仍存在困难。
- 专有与开源模型差距小:专有模型和开源模型之间的安全性差距很小,Qwen3-235B-A22B-Instruct在安全性得分上超过了Claude-3.7-Sonnet。
- 快速思考胜过慢速思考:简洁的“快速思考”解码策略在安全性补丁方面始终优于复杂的“慢速思考”推理策略,表明增加推理预算并不一定转化为更好的仓库级别安全性修复。
具体漏洞类别的表现:
- 路径遍历:对所有LLMs来说,路径遍历是最具挑战性的任务,大多数模型在这个任务上的表现相对较弱。
- 其他漏洞:对于XSS和命令注入,模型更常产生既合格又安全的输出,而在SQL注入任务上,表现则介于路径遍历和XSS/命令注入之间。
模型架构的影响:
采用混合专家(MoE)架构的开源LLMs(如Qwen3-235B-A22B)通常比密集模型表现出更强的安全性性能,表明MoE架构在处理复杂安全任务方面的优势。
研究局限
- 数据多样性:尽管A.S.E基准测试涵盖了四种高频漏洞类别和五种主流编程语言,但真实世界中的漏洞和编程语言更加多样,基准测试的数据多样性仍有提升空间。
- 模型选择:评估的LLMs数量有限,尤其是开源模型,未来研究应纳入更多最新的LLMs以获得更全面的评估结果。
- 评估维度:尽管A.S.E从多个维度评估了生成的代码,但实际应用中可能还有其他重要维度(如性能、可维护性)需要考虑。
未来研究方向
- 增强数据多样性:未来研究应进一步扩大数据集,涵盖更多种类的漏洞和编程语言,以提高基准测试的代表性和泛化能力。
- 深入模型分析:对不同模型架构(如MoE与密集模型)在生成安全代码方面的表现进行更深入的分析,揭示其背后的原因和机制。
- 多维度评估:将性能、可维护性等其他重要维度纳入评估框架,以提供更全面的LLMs生成代码质量评估。
- 实际应用测试:在实际软件项目中测试LLMs生成代码的安全性,以验证基准测试结果在实际应用中的有效性。
- 改进模型训练:根据基准测试结果,优化LLMs的训练方法和数据集,以提高其在生成安全代码方面的能力。
本研究通过引入A.S.E基准测试,为评估LLMs在生成安全代码方面的能力提供了一个全面、可重复的框架。未来的研究可以在此基础上进一步扩展和深化,以推动更安全、可靠的LLMs在软件工程领域的应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献114条内容
已为社区贡献114条内容

所有评论(0)