AI智能体(Agent)大模型入门【1】--什么是RAG?
从本篇章开始,一起开始进入大模型的学习。不再是直接调用官方文档直接部署别人已经配置好的模型。而是建立自己的大模型,通过自己的知识库去创建自己的大模型。
目录
前言
从本篇章开始,一起开始进入大模型的学习。
不再是直接调用官方文档直接部署别人已经配置好的模型。
而是建立自己的大模型,通过自己的知识库去创建自己的大模型。
RAG 的概念
在学习和使用大模型之前,我们需要去先学习什么是rag.
RAG(Retrieval-Augmented Generation)是一种结合检索(Retrieval)与生成(Generation)的模型架构,旨在通过动态检索外部知识库增强生成式模型的输出准确性。其核心思想是在生成答案前,先从大规模文档中检索相关信息,再基于检索结果生成更可靠的回答。
为什么需要RAG
为了改善⼤模型输出在时效性、可靠性与准确性⽅⾯的不⾜(特别是“幻觉”问题),以便让其在更⼴泛 的空间⼤展拳脚,特别是为了给有较⾼⼯程化能⼒要求的企业级应⽤做 AI 赋能,各种针对⼤模型应⽤的 优化⽅法应运⽽⽣。RAG 就是其中⼀种被⼴泛研究与应⽤的优化架构。截⾄⽬前,RAG 在⼤量的场景中 展示了强⼤的适应性与⽣命⼒
RAG的工作流程
简单来说就是了解一下大模型是怎么工作。
为了更好的了解一下这个流程,可以观看下面这一张图
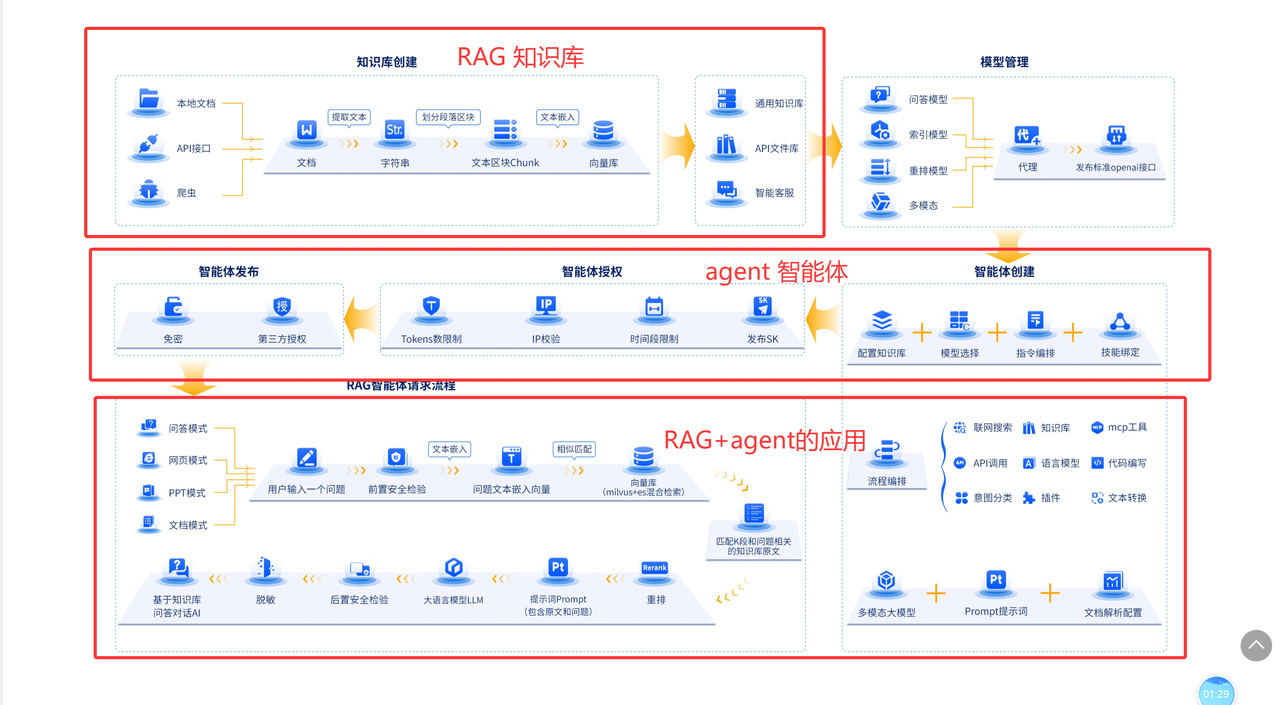
若还是不太了解,这里放一张简化的流程图进行主要了解
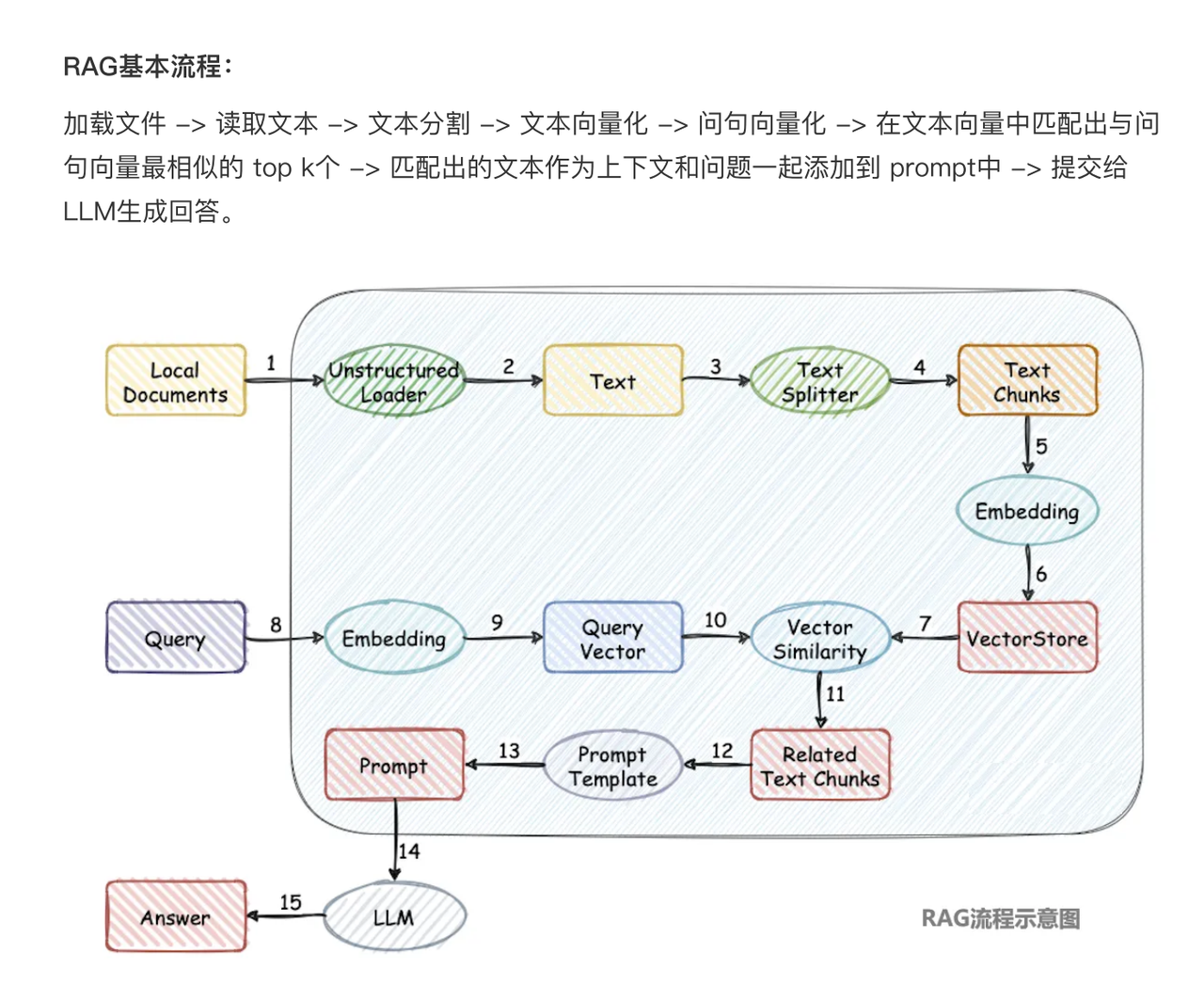
这个概念不复杂,具体可以分为两个主要阶段:数据索引阶段和数据查询阶段。
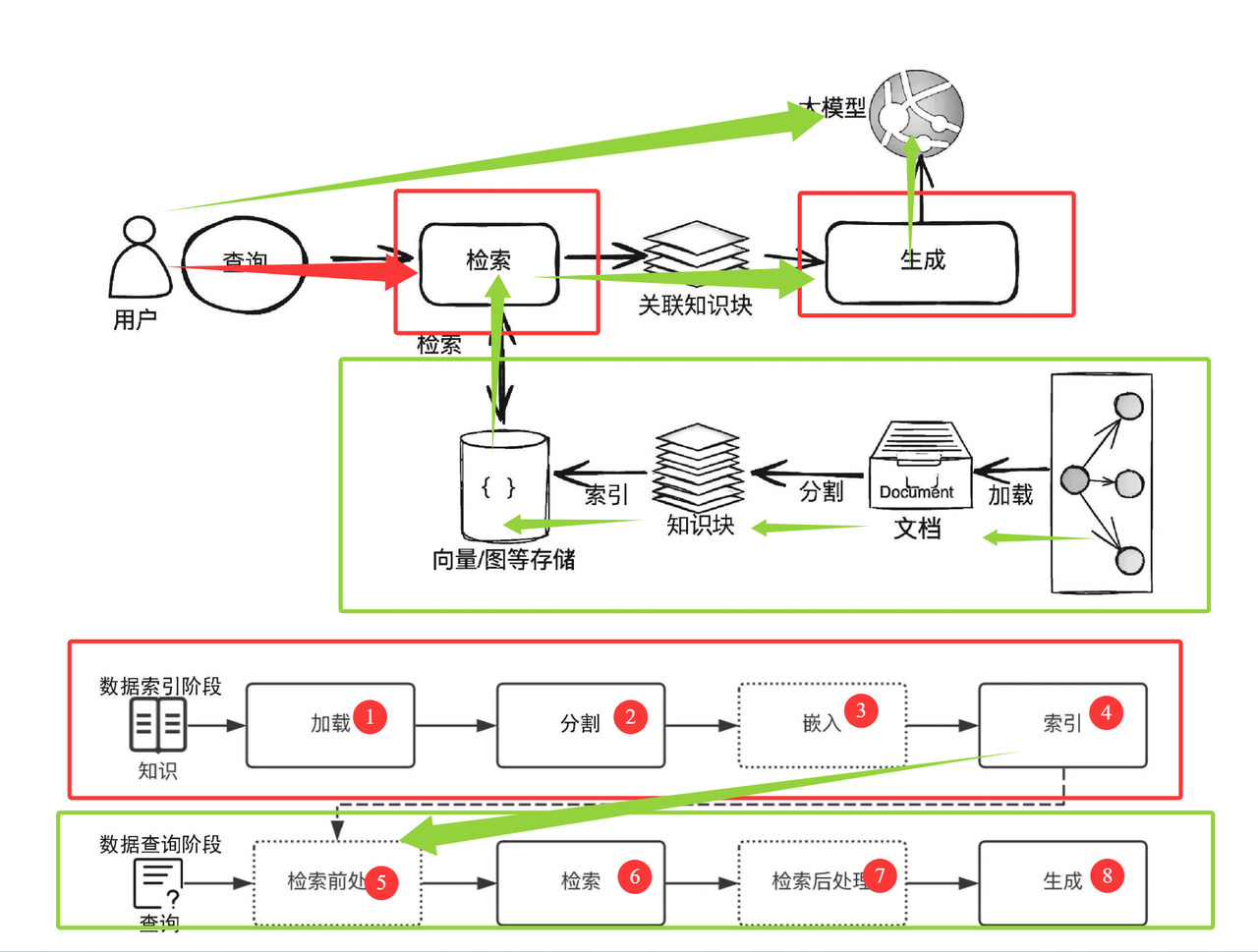
数据索引阶段
数据索引阶段通常包含以下⼏个关键阶段。
(1)加载(Loading):RAG 应⽤需要的知识可能以不同的形式与模态存在,可以是结构化的、半结构 化的、⾮结构化的、存在于互联⽹上或者企业内部的、普通⽂档或者问答对。因此,对这些知识,需要 能够连接与读取内容。
(2)分割(Splitting):为了更好地进⾏检索,需要把较⼤的知识内容(⼀个 Word/PDF ⽂档、⼀个 Excel ⽂档、⼀个⽹⻚或者数据库中的表等)进⾏分割,然后对这些分割的知识块(通常称为 Chunk) 进⾏索引。当然,这就会涉及⼀系列的分割规则,⽐如知识块分割成多⼤最合适?在⽂档中⽤什么标记 ⼀个段落的结尾?
(3)嵌⼊(Embedding):如果你需要开发 RAG 应⽤中最常⻅的向量存储索引,那么需要对分割后的 知识块做嵌⼊。简单地说,就是把分割后的知识块转换为⼀个⾼维(⽐如 1024 维等)的向量。嵌⼊的过 程需要借助商业或者开源的嵌⼊模型(Embedding Model)来完成,⽐如 OpenAI 的 text-embedding 3-small 模型。
(4)索引(Indexing):对于向量存储索引来说,需要将嵌⼊阶段⽣成的向量存储到内存或者磁盘中做 持久化存储。在实际应⽤中,通常建议使⽤功能全⾯的向量数据库(简称向量库)进⾏存储与索引。向 量库会提供强⼤的向量检索算法与管理接⼝,这样可以很⽅便地对输⼊问题进⾏语义检索。注意:在⾼ 级的 RAG 应⽤中,索引形式往往并不只有向量存储索引这⼀种。因此,在这个阶段,很多应⽤会根据⾃ 身的需要来构造其他形式的索引,⽐如知识图谱索引、关键词表索引等
数据查询阶段
在数据索引准备完成后,RAG 应⽤在数据查询阶段的两⼤核⼼阶段是检索与⽣成(也称为合成)。
(1)检索(Retrieval):检索的作⽤是借助数据索引(⽐如向量存储索引),从存储库(⽐如向量库) 中检索出相关知识块,并按照相关性进⾏排序,经过排序后的知识块将作为参考上下⽂⽤于后⾯的⽣ 成。
(2)⽣成(Generation):⽣成的核⼼是⼤模型,可以是本地部署的⼤模型,也可以是基于 API 访问 的远程⼤模型。⽣成器根据检索阶段输出的相关知识块与⽤户原始的查询问题,借助精⼼设计的 Prompt,⽣成内容并输出结果。以上是⼀个经典 RAG 应⽤所包含的主要阶段。随着 RAG 范式与架构 11 的不断演进与优化,有⼀些新的处理阶段被纳⼊流程,其中典型的两个阶段为检索前处理与检索后处 理。
检索前处理(Pre-Retrieval):顾名思义,这是检索之前的步骤。在⼀些优化的 RAG 应⽤流程 中,检索前处理通常⽤于完成诸如查询转换、查询扩充、检索路由等处理⼯作,其⽬的是为后⾯的 检索与检索后处理做必要准备,以提⾼检索阶段召回知识的精确度与最终⽣成的质量。
检索后处理(Post-Retrieval):与检索前处理相对应,这是在完成检索后对检索出的相关知识块 做必要补充处理的阶段。⽐如,对检索的结果借助更专业的排序模型与算法进⾏重排序或者过滤掉 ⼀些不符合条件的知识块等,使得最需要、最合规的知识块处于上下⽂的最前端,这有助于提⾼⼤ 模型的输出质量
给中文版的实例图
RAG 的优势
动态知识更新:无需重新训练模型,仅需更新知识库即可适应新领域或时效性信息。
可解释性:生成结果可追溯至检索到的文档片段,便于验证可信度。
降低训练成本:相比纯生成模型,RAG 减少了对海量参数记忆知识的需求。
RAG 的应用场景
开放域问答:如客服系统、百科式问答。
长文本生成:辅助生成基于多文档的综述或报告。
领域适配:医疗、法律等专业领域的信息整合与输出。
RAG 的局限性
检索效率:大规模知识库可能增加延迟。
依赖检索质量:若检索片段不相关,生成结果可能偏离预期。
知识覆盖:未包含在知识库中的信息无法被有效利用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)