通义千问放大招!4800亿参数MoE架构,Qwen3-Coder厉害在哪里,大模型入门到精通,收藏这篇就足够了!
这不仅是通义系列迄今为止最强大的开源智能编程模型,更是全球首个真正意义上具备“自主编程能力”的Agentic Code Model(代理式代码模型)。
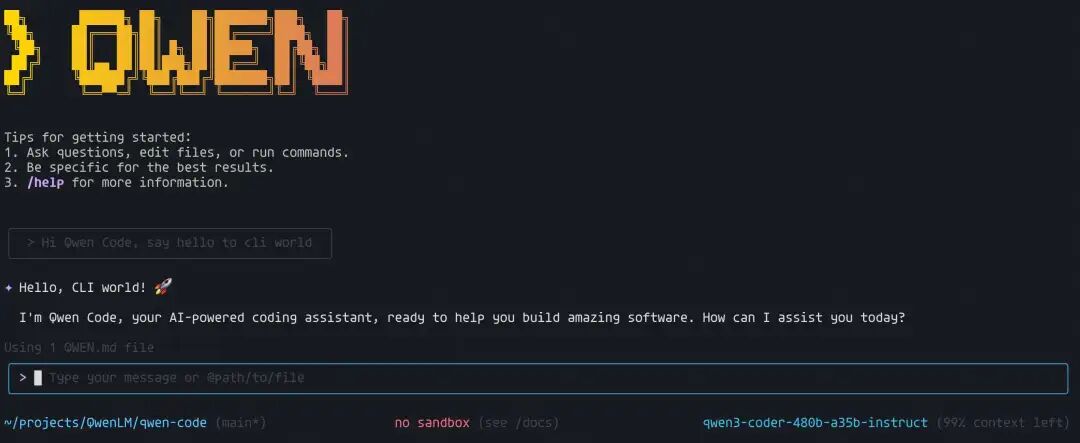
当通义实验室官宣:Qwen3-Coder-480B-A35B-Instruct 正式发布!
这不仅是通义系列迄今为止最强大的开源智能编程模型,更是全球首个真正意义上具备“自主编程能力”的Agentic Code Model(代理式代码模型)。
一句话总结:
它不再只是帮你补一行代码的“小助手”,而是能独立思考、调用工具、执行测试、提交PR的“AI程序员”。
今天,我们就来全面拆解这个重磅模型,看看它是如何重新定义AI编程的边界。
- 不是“写代码”,而是“做项目”:Qwen3-Coder到底有多强?
过去的AI代码模型,比如CodeLlama、StarCoder,甚至早期的Copilot,本质上都是“被动响应”型工具:
你写个函数名,它补全;你打个注释,它生成代码。
但Qwen3-Coder不一样。它的目标是:像人类工程师一样完成端到端的软件开发任务。
这意味着它能:
- 自主分析一个完整的代码仓库
- 理解PR需求并提出修改方案
- 调用
git、pytest、linter等工具链 - 多轮交互中持续优化代码逻辑
- 最终自动生成可合并的代码变更
换句话说,它已经从“代码补全器”进化成了“数字工程师”。
- 4800亿参数+MoE架构:性能怪兽是如何炼成的?
先看一组硬核参数,准备好被震撼:
- 总参数量:4800亿(480B)
- 推理激活参数:350亿(A35B)
- 架构:Mixture-of-Experts(MoE)
- 专家总数:160个,每次激活8个
- 上下文长度:原生256K,最高支持100万tokens
- 层数:62层,注意力头96(Q)/8(KV)
这个模型到底多大?做个类比:
如果把传统大模型比作一辆V8发动机的跑车,那Qwen3-Coder就是一台装配了160个引擎的航天飞机,但每次只启动最合适的8个——既保证动力,又节省燃料。
这就是MoE(混合专家)架构的核心优势:按需激活,高效推理。
比如你让它写Python脚本,它就调用“Python+数据处理”专家;
你要它优化C++性能,它就唤醒“系统编程+编译器优化”专家;
整个过程就像一个顶级技术团队在协同工作。
- 百万token上下文:读完整个项目不再是梦
更猛的是它的上下文能力。
Qwen3-Coder原生支持256,000 tokens,相当于一次性加载:
- 一本《三体》全集
- 整个Spring Boot核心模块
- 或者一个中型前端项目的全部源码
但这还没完——通过YaRN上下文外推技术,它可以将上下文扩展到1,000,000 tokens!
这意味着什么?
你可以直接把一个百万行级别的代码库扔给它,让它:
- 分析架构依赖
- 定位历史Bug
- 生成重构建议
- 甚至自动修复安全漏洞
再也不用担心“上下文太短被截断”的尴尬了。
这是真正意义上的“仓库级代码理解”。
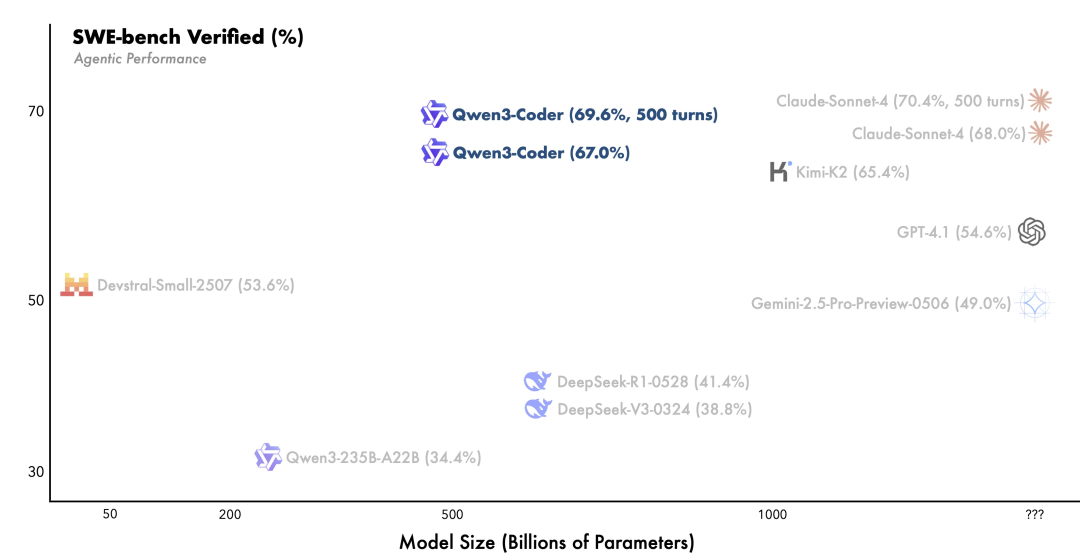
- 实测碾压:SWE-bench上干翻闭源模型

在目前最接近真实开发场景的评测集 SWE-bench-Verified 上,Qwen3-Coder的表现堪称惊艳:
- 在开源模型中排名第一
- 成绩追平甚至部分超越 Claude Sonnet-4
- 特别是在真实PR修复任务中,执行成功率显著领先
SWE-bench是什么?简单说,就是从GitHub真实项目中抽取的复杂任务,比如:
“修复Django中的CSRF漏洞”
“为FastAPI添加JWT认证支持”
“重构React组件以提升渲染性能”
这些都不是简单的“Hello World”题,而是需要理解项目结构、调用工具、多轮调试的真实工程问题。
而Qwen3-Coder不仅能看懂,还能动手解决。
- 预训练三重升级:数据、上下文、合成数据全面拉满
为什么这次能这么强?通义团队在预训练阶段下了狠功夫。
✅ 数据扩展:7.5T超大规模语料
- 总数据量高达 7.5万亿tokens
- 其中代码占比 **70%**,覆盖Python、Java、Go、Rust等主流语言
- 同时保留足够通用和数学能力,确保模型“不止会写代码”
✅ 上下文优化:专为Agentic Coding设计
- 原生支持256K上下文,训练时就喂入超长代码片段
- 针对Pull Request、CI日志等动态数据做了特殊优化
- 让模型学会“在上下文中做决策”
✅ 合成数据增强:用老模型清洗低质数据
- 使用 Qwen2.5-Coder 对低质量代码进行自动清洗和重写
- 显著提升整体训练数据的质量
- 相当于“用AI教AI写更好的代码”
- 后训练放大招:强化学习让AI学会“自己动手”
如果说预训练是“打基础”,那后训练就是“实战演练”。
Qwen3-Coder做了两件非常关键的事:
🔥 Scaling Code RL:难解易验,强化学习的黄金场景
他们发现:代码任务天然适合强化学习(RL)。
为什么?因为:
很多问题“难解但易验”——你可能不知道怎么写最优解,但跑个测试就知道对不对。
于是团队构建了大量高质量RL训练样本:
- 自动生成复杂测试用例
- 模拟各种边界条件和异常输入
- 让模型在“试错—反馈”中不断进化
结果:代码执行成功率大幅提升,且泛化能力更强。
🚀 Scaling Long-Horizon RL:让AI像工程师一样思考
真实开发是长周期任务。比如修一个Bug,往往要:
- 查日志 → 2. 改代码 → 3. 跑测试 → 4. 提交PR → 5. 回滚重试
这就是典型的长周期强化学习(Long-Horizon RL)。
为此,通义搭建了一套可扩展的验证环境系统,借助阿里云基础设施,同时运行20,000个独立沙箱环境!
在这个系统上,Qwen3-Coder经历了海量的真实软件工程任务训练,最终在SWE-bench上拿下开源模型SOTA。
- Qwen Code CLI:命令行里的“AI编程搭档”
光有模型还不够,通义还开源了一款命令行工具:Qwen Code。
它基于Gemini CLI二次开发,但做了深度适配,专为激发Qwen3-Coder的Agentic能力而生。
安装方式超简单:
# 安装Node.js 20+
curl -qL https://www.npmjs.com/install.sh | sh
# 全局安装Qwen Code
npm i -g @qwen-code/qwen-code
或者从源码安装:
git clone https://github.com/QwenLM/qwen-code.git
cd qwen-code && npm install && npm install -g
配置API密钥(推荐写入.env文件):
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
然后你就可以在终端里直接召唤AI:
qwen "帮我把这个函数改成异步非阻塞"
或者更复杂的任务:
qwen "分析当前项目的所有API,生成OpenAPI文档"
它会自动识别项目结构、注入上下文、多轮交互优化,甚至帮你运行测试。
- 不止Qwen Code:还能接入Claude Code、Cline等生态工具
更厉害的是,Qwen3-Coder不是一个封闭系统,而是开放生态的“通用底座”。
你可以把它接入各种主流工具:
✅ 接入 Claude Code
只需安装Claude CLI,并替换API地址:
npm install -g @anthropic-ai/claude-code
然后设置代理:
export ANTHROPIC_BASE_URL=https://dashscope.aliyuncs.com/api/v2/apps/claude-code-proxy
export ANTHROPIC_AUTH_TOKEN=your-dashscope-apikey
现在,你就能用Claude的界面,调用Qwen3-Coder的强大能力。
✅ 接入 Cline(AI编程助手)
在Cline配置中选择“OpenAI Compatible”模式:
- API Key:填入DashScope获取的密钥
- Base URL:
https://dashscope.aliyuncs.com/compatible-mode/v1 - Model Name:
qwen3-coder-plus
保存后,即可在Cline中享受Qwen3-Coder的编码体验。
✅ 自定义路由:使用 ccr-dashscope
如果你想要更灵活的路由控制,可以用第三方工具claude-code-router:
npm install -g @musistudio/claude-code-router
npm install -g @dashscope-js/claude-code-config
# 生成配置
ccr-dashscope
# 启动
ccr code
从此,你的本地开发环境就拥有了一个“全能AI工程师”。
- 实际案例:物理级烟囱爆破模拟(节选)

官方还展示了一个高难度案例:基于物理的烟囱定向爆破模拟。
用户只输入一句话:
“帮我用Three.js做一个可控爆炸的烟囱倒塌动画。”
Qwen3-Coder不仅生成了完整的WebGL代码,还:
- 引入了 Cannon.js 物理引擎
- 设计了分段引爆逻辑
- 模拟重力、碰撞、碎片飞溅
- 添加了摄像机动画和UI控制面板
整个过程无需人工干预,一气呵成。
这已经不是“写代码”,而是“实现产品原型”。
- API调用示例:快速集成到你的项目
如果你想通过API调用Qwen3-Coder,可以用标准OpenAI SDK:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
prompt = "Help me create a web page for an online bookstore."
completion = client.chat.completions.create(
model="qwen3-coder-plus",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
)
print(completion.choices[0].message.content.strip())
只需更换API地址和模型名,就能无缝接入现有系统。
- 未来展望:让AI学会“自我进化”
通义团队表示,这还不是终点。
他们正在探索两个方向:
- 更小尺寸的Qwen3-Coder:在保证性能的同时降低部署成本
- Self-Improving Coding Agent:让AI能自己审查代码、发现问题、主动优化
想象一下:
你的AI程序员不仅能写代码,还能定期扫描项目,自动提交“性能优化PR”、“安全加固补丁”,甚至写出技术文档。
那一天,可能比我们想象的来得更快。
结语:AI编程的“iPhone时刻”到了
回顾过去几年,AI编程经历了三个阶段:
- 辅助时代(2020-2022):Copilot式补全,提升打字效率
- 生成时代(2023-2024):根据描述生成完整函数或页面
- 代理时代(2025起):AI独立完成任务,成为“数字员工”
而Qwen3-Coder的发布,标志着我们正式进入第三阶段。
它不只是一个模型,更是一个新生产力时代的起点。
📌 获取方式:
- 模型地址:Hugging Face - Qwen3-Coder
- 工具地址:GitHub - Qwen Code
- API平台:阿里云百炼
最后送大家一句话:
“未来的程序员,不是会被AI取代的人,而是不会用AI的人。”
赶紧去试试Qwen3-Coder吧,说不定下次你提交的代码,90%都是AI写的——但别告诉老板 😏
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献294条内容
已为社区贡献294条内容

所有评论(0)