联邦学习论文分享:PPC-GPT: Federated Task-Specific Compression of Large LanguageModels via Pruning and Chain
框架介绍PPC-GPT 是一个隐私保护的联邦学习框架,用于将大型语言模型(LLM)压缩成任务特定的小型模型(SLM)。压缩过程结合了剪枝(pruning)和链式推理蒸馏(COT distillation)。DP扰动数据(DP Perturbed Data):对客户端数据进行差分隐私保护。合成数据生成(Synthetic Data Generation):生成可用于训练的小规模数据。逐层结构化剪枝(
摘要
-
问题背景:
-
LLMs 很大,部署成本高。
-
将 LLM 压缩成 SLM(小语言模型) 有两个挑战:
-
保护领域特定知识的隐私。
-
处理资源有限的问题。
-
-
-
提出的方法 PPC-GPT:
-
架构:采用服务器-客户端的联邦学习(federated)架构。
-
隐私保护:客户端发送经过差分隐私(DP)扰动的任务数据给服务器。
-
数据生成:服务器端的 LLM 使用这些数据生成 合成数据和对应的推理过程(rationales)。
-
模型压缩:利用这些合成数据进行 LLM剪枝 和 SLM重训练。
-
Chain-of-Thought (COT) 知识蒸馏:进一步用合成数据改进结构化剪枝后的 SLM。
-
-
实验结果:
-
PPC-GPT 在多种文本生成任务上表现良好。
-
在压缩模型的同时,也保证了数据隐私。
-
引言
1. 研究背景与动机
-
LLMs(大型语言模型):
-
如 GPT-4、LLaMA3-70B,拥有数十亿参数,文本生成能力强。
-
问题:训练成本高,部署困难,尤其在资源受限的环境中。
-
-
SLMs(小型语言模型):
-
如 OPT-1.3B、Pythia-1.4B,更高效、响应快,适合实时应用。
-
企业更倾向部署 SLM,以避免潜在的数据泄露。
-
但从零训练 SLM 仍需高昂计算成本,而且性能有限。
-
-
核心问题:是否能利用已有 LLM,在资源有限和隐私受限的情况下,生成任务专用、性能良好的 SLM?
2. 技术手段
-
结构化剪枝(Structured Pruning):
-
通过去除冗余参数压缩模型,加速推理,同时尽量保持任务性能。
-
-
主要挑战:
-
数据隐私问题:企业无法独立剪枝 LLM,需要将数据传到远程服务器,但这存在隐私风险。
-
性能保持问题:剪枝会导致性能下降,如何保证 SLM 性能接近原 LLM?
-
3. 提出的方法:PPC-GPT
-
框架特点:
-
隐私保护的联邦学习架构(server-client)。
-
客户端发送经过差分隐私扰动(DP-perturbed)的任务数据到服务器。
-
服务器端的 LLM 生成 合成数据和对应推理过程(rationales)。
-
对原 LLM(LLMo)进行剪枝,生成目标 SLM(SLMt)。
-
使用 COT(Chain-of-Thought)知识蒸馏对 SLMt 进行再训练。
-
最终将优化后的 SLMt 发送回客户端,客户端可使用本地私有数据进一步微调。
-
4. 贡献
-
隐私保护的联邦 LLM 压缩框架:用 DP 数据生成合成数据指导剪枝。
-
COT 知识蒸馏:用合成数据改善剪枝后 SLM 的性能。
-
实证验证:在 LLaMA、OPT 等模型上进行文本生成任务实验,证明 PPC-GPT 能有效压缩 LLM 并保持竞争性能。
相关工作
差分隐私

差分隐私合成数据
1. 生成方法
-
基本思路:
-
在私有数据上使用 差分隐私训练(DP-SGD) 训练语言模型(如 LLaMa2-7B)。
-
利用训练好的 DP 模型反复采样生成 合成数据。
-
-
效果:研究表明,用 DP 合成数据训练下游模型,性能可接近直接在真实数据上使用 DP 训练的效果,说明合成数据质量高。
2. 存在的挑战
-
闭源或大模型限制:
-
GPT-4 等前沿 LLM 无法获取模型权重,无法进行 DP 微调。
-
即便是开源 LLM(如 LLaMa3-70B),DP 微调也需要大量计算资源。
-
-
信任服务器依赖:
-
传统 DP 微调方法需要可信服务器收集数据训练模型。
-
在缺乏可信服务器的场景下(如本文研究场景),这种方法不可行。
-
3. 研究背景约束
-
本文采用 客户端-服务器架构,服务器端无法对 LLM 进行微调,因此需要其他方式生成隐私保护的合成数据。
模型剪枝
1. 模型剪枝的定义与目的
-
概念:通过移除冗余参数来压缩模型、降低计算开销。
-
历史:最早由 LeCun 等(1989)提出,Han 等(2015)进一步完善。
-
目标:减少模型冗余,实现压缩与加速推理,同时尽量保持性能。
2. 剪枝方法分类
-
非结构化剪枝(Unstructured Pruning):
-
直接剪掉单个神经元或参数,不考虑模型内部结构。
-
优点:压缩率高。
-
缺点:产生非结构化稀疏性,部署困难。
-
-
结构化剪枝(Structured Pruning):
-
按有组织的模式移除参数,如整个层、注意力头(MHA)、隐藏层大小(FFN)或混合方式。
-
优点:便于实际部署,更实用。
-
近期研究大量集中在 LLM 结构化剪枝:
-
ShortGPT、LaCo、Shortened LLaMa:主要剪掉深度(层数)。
-
LLM-Pruner:剪掉宽度相关的耦合结构,同时保持层数。
-
Sheared-LLaMA:通过掩码学习(mask learning)识别可剪枝组件,在宽度和深度上进行优化。
-
本文采用的是 LLM 的结构化剪枝 方法。
-
-
补充
一些常见的剪枝方法
1. 基于权重大小(Magnitude-based Pruning)
-
原理:假设权重越小,对输出的贡献越小,可以优先剪掉。
-
操作:计算每个参数的绝对值,低于阈值的参数被剪掉。
-
优点:简单、高效,不需要复杂计算。
-
缺点:忽略了参数在网络中的协同作用,有可能误删重要参数。
2. 基于梯度或敏感度(Gradient/Sensitivity-based Pruning)
-
原理:评估每个参数对损失函数的敏感度。
-
如果参数变化对损失影响小,则可以剪掉。
-
常用方法:Hessian-based pruning(LeCun et al., 1989)。
-
-
优点:理论上更准确,因为考虑了参数对性能的实际贡献。
-
缺点:计算 Hessian 矩阵很昂贵,尤其是大型模型。
3. 结构化指标(Structured Pruning)
-
原理:剪掉整个结构单元(如层、注意力头、隐藏神经元)时,用某种评分指标判断重要性。
-
常用评分:
-
激活值(Activation-based):平均激活低的神经元或头,认为重要性低。
-
注意力权重(Attention weight):对注意力头的重要性排序。
-
梯度×权重(Gradient × Weight):衡量参数对损失的实际影响。
-
-
-
优点:剪掉的是结构单元,更利于硬件部署。
4. 学习掩码(Mask Learning / Learnable Pruning)
-
原理:给每个参数或结构单元分配一个可学习的掩码(0 或 1),训练过程中学习哪些可以关闭。
-
应用:例如 Sheared-LLaMA,通过掩码学习找到可剪枝组件。
-
优点:自动化,更灵活,能考虑参数间的依赖关系。
5. 结合知识蒸馏或任务性能
-
在剪枝后,用 合成数据或原任务数据评估剪枝对模型性能的影响。
-
这种反馈可以指导下一轮剪枝,使重要部分保留,性能尽量不下降
算法
问题定义
-
框架介绍:
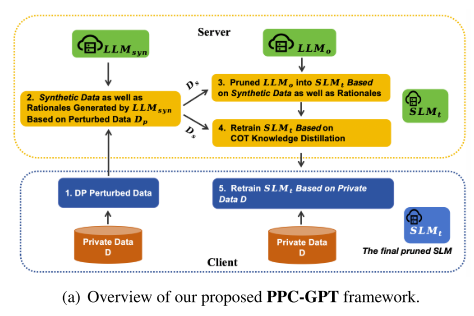
-
PPC-GPT 是一个 隐私保护的联邦学习框架,用于将大型语言模型(LLM)压缩成 任务特定的小型模型(SLM)。
-
压缩过程结合了 剪枝(pruning) 和 链式推理蒸馏(COT distillation)。
-
框架包含四个核心模块:
-
DP扰动数据(DP Perturbed Data):对客户端数据进行差分隐私保护。
-
合成数据生成(Synthetic Data Generation):生成可用于训练的小规模数据。
-
逐层结构化剪枝(Layer-Wise Structured Pruning):压缩模型参数。
-
再训练(Retraining):对压缩后的模型进行优化。
-
-
-
问题定义(Problem Formulation):
-
给定一个原始 LLM f 和一个包含私有数据的任务数据集 D,目标是得到 小型任务特定模型 fθt。
-
需要找到 最优剪枝策略 P 和 最优再训练方法 R,以在 保持数据隐私的前提下 最小化压缩模型的损失:
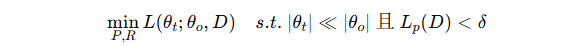
-
∣θt∣和 ∣θo∣分别是压缩模型和原模型的参数量。
-
Lp(D)表示因数据扰动产生的隐私损失。
-
约束保证模型小且隐私得到保护。
-
-
-
假设:
-
服务器是 半诚实(semi-honest) 的,即可能尝试从接收到的信息中推断客户端数据,但不会主动篡改或破坏流程。
-
DP Perturbed Data(差分隐私扰动数据)
-
目标:保护客户端的私有数据
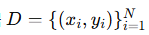 的隐私,同时仍能用于训练模型。
的隐私,同时仍能用于训练模型。 -
方法:
-
使用 指数机制(Exponential Mechanism) 对原始数据进行扰动。
-
输出扰动后的数据集
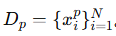 。
。 -
扰动遵循 ϵ-DP(差分隐私)标准。
-
概率分布:
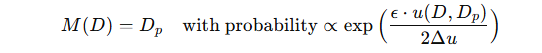
-
u(D,Dp) 是效用函数,用于衡量扰动后数据的“质量”。
-
Δu 是效用函数的敏感度。
-
-
Synthetic Data Generation(合成数据生成)
-
目标:服务器端利用扰动数据 Dp生成高质量的 合成数据 Ds,并附带 推理理由(rationales),用于模型剪枝和再训练。
-
生成流程:
-
问题生成:
-
从扰动问题出发,利用 LLMsyn 创建新的问题。
-
三个约束:
-
新问题符合常识。
-
独立可解,不依赖原问题。
-
不包含答案。
-
-
格式根据数据集需求定制。
-
-
答案生成:
-
LLMsyn 对每个新问题生成 链式推理(COT)答案。
-
同一问题生成三次答案,若不一致则丢弃。
-
-
推理理由生成:
-
对每条合成数据生成相应的 rationale,说明答案推理过程。
-
-
-
输出:合成数据集
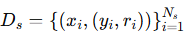 ,用于后续的模型剪枝和再训练。
,用于后续的模型剪枝和再训练。
逐层结构化剪枝
-
背景与动机:
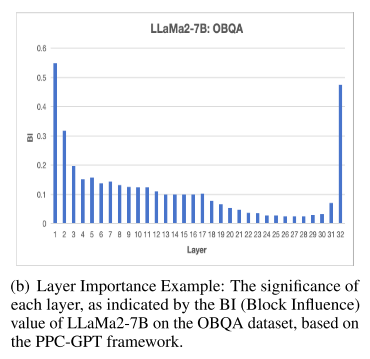
-
神经网络存在 高度冗余层,某些层对最终模型性能贡献很小。
-
LLM(大型语言模型)也存在这种现象,尤其在 深层中冗余更明显。
-
因此,需要一个 衡量每一层重要性的指标,以决定哪些层可以剪掉而不显著影响模型性能。
-
-
衡量层重要性的指标:Block Influence(BI):
-
基于 ShortGPT(Men et al., 2024) 提出的 BI 指标。
-
核心假设:一个 transformer block 对隐藏状态的修改越多,它的重要性越高。
-
数学表达:
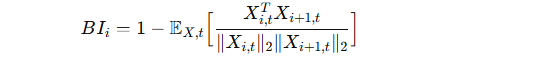
-
Xi 表示第 i 层输入,Xi,t 表示其第 t 行。
-
值越高表示该层对模型的重要性越大。
-
-
-
BI指标的扩展:
-
原始 BI 仅考虑输入和任务标签(label)信息。
-
在 PPC-GPT 中,将 BI 扩展为两部分:
-
BILabel,i:层对任务标签预测的重要性。
-
BIRationale,i:层对生成推理理由(rationale)的重要性。
-
-
综合 BI:
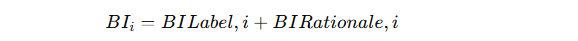
-
-
剪枝策略:
-
将层按 BI 得分 从低到高排序。
-
移除 BI 低的层(冗余层),保留重要层,以减小模型规模,同时尽量保持性能。
-
再训练
1. Server-side Retraining(服务器端再训练)
-
数据来源:使用前面生成的 合成数据集 Ds。
-
方法:提出 基于推理理由(rationale)的链式思维知识蒸馏(COT knowledge distillation)。
-
训练目标:将再训练建模为一个 多任务学习(multi-task learning) 问题:
-
任务1:预测标签
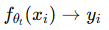
-
任务2:生成推理理由
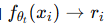
-
-
损失函数:
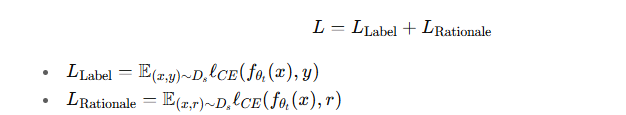
-
意义:让模型不仅能给出 正确预测,还能生成 合理解释,提升透明度和可解释性。
2. Client-side Retraining(客户端再训练)
-
数据来源:使用 客户端本地私有数据 D。
-
方法:传统监督训练,仅利用真实标签进行微调。
-
损失函数:
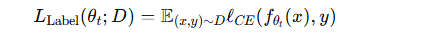
-
意义:在保证隐私的前提下,用真实标签进一步提升压缩后小模型(SLMt)的性能。
补充
背景设定
-
假设我们有一个 12 层 Transformer LLM(比如简化版 BERT/LLM)。
-
目标是压缩它,变成一个更小的任务特定模型(SLM),比如只保留 6 层,同时不影响下游任务(如情感分类)。
-
我们要用 Block Influence (BI) 指标,来判断每一层的重要性,然后剪掉不重要的层。
剪枝流程(逐层结构化剪枝)
步骤 1:准备数据
-
使用前面步骤得到的 合成数据集 Ds(输入+标签+推理理由)。
例子:-
输入句子:"The movie was surprisingly good."
-
标签:Positive
-
推理理由:"The word ‘good’ indicates positive sentiment."
-
步骤 2:计算每一层的 Block Influence (BI)
-
对每一层,我们输入样本,得到这一层的输入向量 XiX_iXi 和输出向量 Xi+1。
-
计算它们的余弦相似度,得到层对表示的“改变量”:
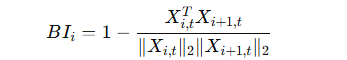
-
如果某一层的输出和输入几乎一样(相似度接近 1),说明这一层“没干啥事”,BI 值很小。
-
我们在 PPC-GPT 中扩展了 BI:不仅计算对 标签预测 的影响,还要计算对 推理理由生成 的影响:
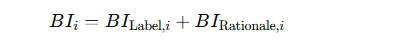
举例:
假设计算后得到 12 层的 BI 分数:
| 层号 | BI 分数 |
|---|---|
| 1 | 0.18 |
| 2 | 0.25 |
| 3 | 0.10 |
| 4 | 0.32 |
| 5 | 0.08 |
| 6 | 0.40 |
| 7 | 0.12 |
| 8 | 0.37 |
| 9 | 0.42 |
| 10 | 0.09 |
| 11 | 0.45 |
| 12 | 0.50 |
步骤 3:选择要剪掉的层
-
将层按 BI 从小到大排序。
-
比如最低的 5 层是:第 5 层 (0.08)、第 10 层 (0.09)、第 3 层 (0.10)、第 7 层 (0.12)、第 1 层 (0.18)。
-
这些层对整体性能贡献不大 → 剪掉它们。
步骤 4:得到压缩后的模型
-
原始模型:12 层 → 剪枝后:7 层。
-
保留下来的都是 BI 高的重要层,比如第 6、9、11、12 层等。
-
剪枝完成后,模型参数量显著减少,计算速度提升。
步骤 5:再训练
-
在服务器端,用合成数据 Ds 进行 COT蒸馏 + 多任务训练(预测+推理理由)。
-
在客户端,用本地私有数据 D 做 微调,进一步恢复模型性能。

实验
设置
1. 实验架构
-
客户端-服务器架构:
-
服务器端 (Server):负责合成数据生成,使用 LLaMA3-70B (LLMsyn)。
-
客户端 (Client):进行模型剪枝和再训练,源模型 (LLMo) 来自 LLaMA2-7B 和 OPT-6.7B。
-
-
默认参数:
-
隐私预算 ϵ=3
-
合成数据比例 = 8
-
2. 数据集与评估指标
-
数据集(以 QA 任务为主):
-
CommonsenseQA (CQA)
-
OpenBookQA (OBQA)
-
ARC-C、ARC-E
-
FiQA-SA
-
-
评估指标:
-
Accuracy(准确率)
-
-
评估方式:
-
全部方法都做 zero-shot evaluation
-
使用 lm-evaluation-harness 工具包
-
3. 对比基线方法
-
DenseSFT:客户端用私有数据直接微调 LLMo(无剪枝)。
-
Plain-C:客户端自己剪枝 LLMo(假设能部署大模型),再用私有数据微调。
-
DP-Instruct-C (Yu et al., 2024):
-
客户端先用 DP-SGD 微调一个生成器(如 LLaMA2-1.3B)。
-
用生成器产生的合成数据去剪枝 LLMo。
-
最后再用私有数据微调剪枝后的模型。
-
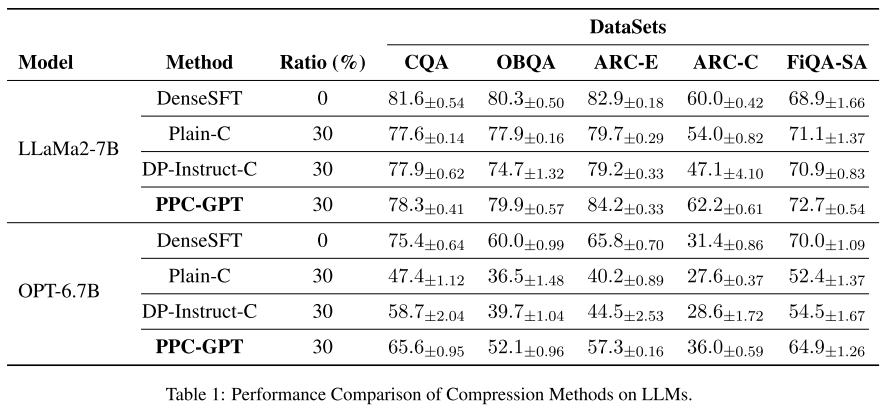
结果
1. 实验设置回顾
-
剪枝比例:由于现有结构化剪枝通常最多能减少 30% 参数,所以实验主要采用 约 30% 参数剪枝 的设置。
2. 总体结果
-
PPC-GPT 的优势:
-
在保证 隐私保护 的前提下,能有效压缩大模型(LLM)为小模型(SLM)。
-
优于 DP-Instruct-C:后者使用 DP-SGD 来保证隐私,但效果不如 PPC-GPT。
-
优于 Plain-C:后者直接用私有数据进行剪枝和微调,但效果也不如 PPC-GPT。
-
甚至优于 DenseSFT:在一些数据集上,PPC-GPT 压缩后的 SLM 还能超过 DenseSFT 使用原始大模型的表现。
-
3. 具体数据(以 LLaMA2-7B 为例)
-
与 DP-Instruct-C 对比:
-
CQA: +0.4%
-
OBQA: +5.2%
-
ARC-E: +5%
-
ARC-C: +15.1%
-
FiQA-SA: +1.8%
-
-
与 Plain-C 对比:
-
CQA: +0.7%
-
OBQA: +2%
-
ARC-E: +4.5%
-
ARC-C: +8.2%
-
FiQA-SA: +1.6%
-
消融实验
隐私预算的影响
1. 实验设置
-
探索了不同隐私预算下(ϵ = 1, 3, 5, 10)PPC-GPT 的表现。
-
对比结果见 Table 2,并与 Table 1(默认 ϵ=3) 做比较。
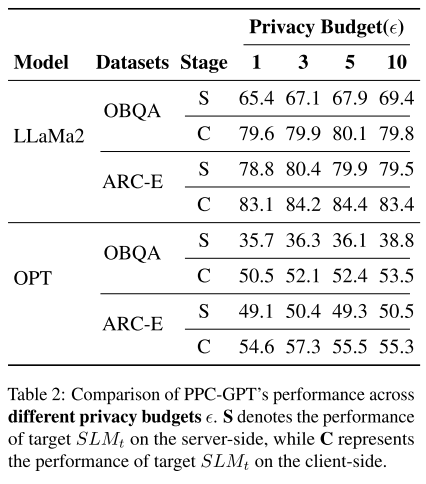
2. 主要发现
-
即使在最严格的隐私保护下(ϵ=1):
-
在 LLaMA2-7B 上,PPC-GPT 依然比 Plain-C 高:
-
OBQA: +1.7%
-
ARC-E: +3.4%
-
-
在 OPT-6.7B 上,提升更大:
-
OBQA: +14%
-
ARC-E: +14.4%
-
-
-
随着隐私预算 ϵ 增大:
-
模型性能显著提升。
-
说明 PPC-GPT 能很好地在 隐私保护(低 ϵ) 与 模型效能(高 ϵ) 之间取得平衡。
-
合成数据的影响
1. 合成数据比例 (Synthetic Data Ratio)
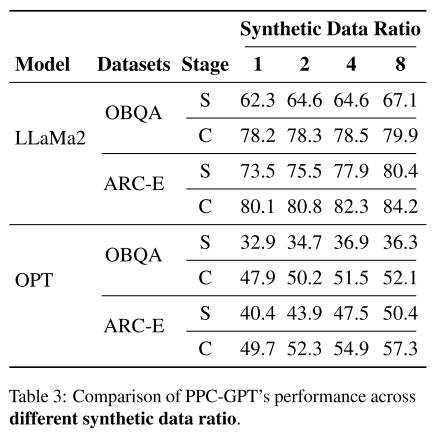
-
实验测试了不同比例 (1, 2, 4, 8) 的合成数据。
-
结果:随着合成数据比例增加,PPC-GPT 性能显著提升。
-
例子:
-
在 LLaMA2-7B 上:
-
ratio=8 比 ratio=1 提升 OBQA: +1.7%,ARC-E: +4.1%
-
-
在 OPT-6.7B 上:
-
ratio=8 比 ratio=1 提升 OBQA: +4.2%,ARC-E: +7.6%
-
-
-
结论:更多合成数据 → 性能更好。
2. 合成数据中的推理理由 (Synthetic Data Rationales)
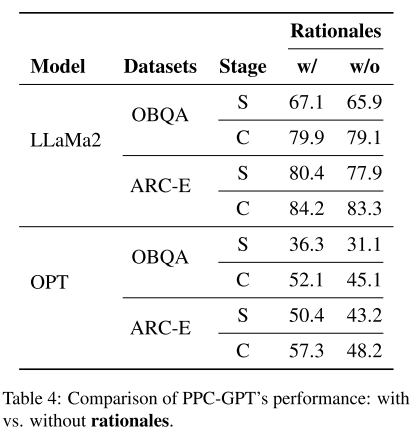
-
对比了两种情况:
-
带推理理由 (w/ rationales)
-
不带推理理由 (w/o rationales)
-
-
结果:使用推理理由的数据性能更好。
-
例子:
-
在 LLaMA2-7B 上:
-
w/ rationales 比 w/o rationales 提升 OBQA: +0.8%,ARC-E: +0.9%
-
-
在 OPT-6.7B 上:
-
提升更明显 OBQA: +7%,ARC-E: +9.1%
-
-
-
结论:合理利用 推理理由(CoT rationales) 能进一步提升模型性能。
再训练的影响
1. 实验内容
-
对比了 有服务器端再训练 (w/ retraining) 和 没有服务器端再训练 (w/o retraining) 的 PPC-GPT 表现。
2. 实验结果
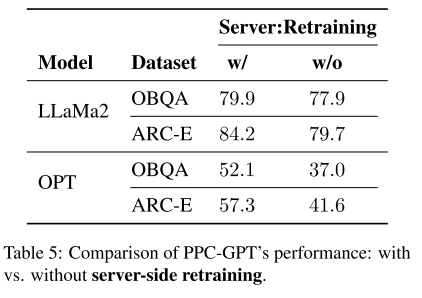
-
在 LLaMA2-7B 上:
-
w/ retraining 比 w/o retraining 高:
-
OBQA: +2%
-
ARC-E: +4.5%
-
-
-
在 OPT-6.7B 上:
-
w/ retraining 比 w/o retraining 高:
-
OBQA: +15.1%
-
ARC-E: +15.7%
-
-
3. 结论
-
服务器端再训练显著提升了模型性能。
-
在大模型(如 OPT-6.7B)上的提升尤其明显,说明再训练在压缩模型性能恢复中非常关键。
不同剪枝策略和剪枝比例的影响
1. 不同的重要性度量方式 (Importance Metric)
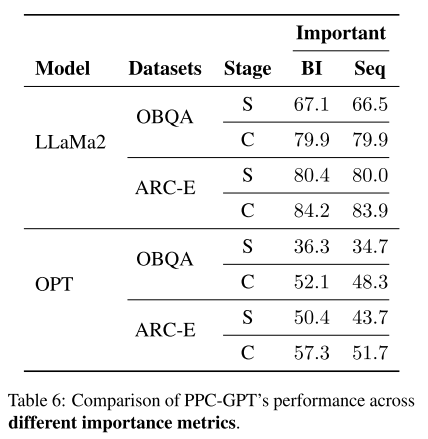
-
Seq 方法:按照层的深浅来衡量,浅层重要性更高。
-
BI 方法:基于前面介绍的 Block Influence (BI) 指标来衡量层的重要性。
-
结果:实验表明,采用 BI 的性能明显优于采用 Seq,说明 BI 更能有效指导剪枝。
2. 不同的模型剪枝比例 (Model Pruning Ratio)
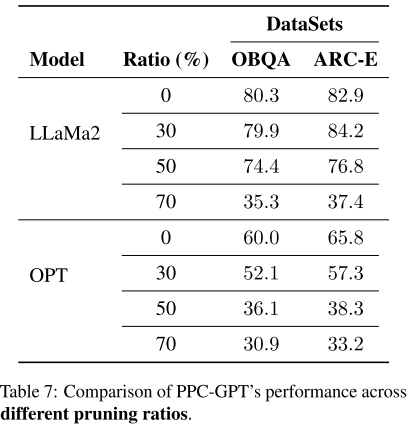
-
测试了 0%、30%、50%、70% 的剪枝比例。
-
结果:随着剪枝比例的增加,性能逐渐下降。
-
结论:过度剪枝会显著损伤模型性能,合理的剪枝比例(如 30%)在压缩和性能之间能达到平衡。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 42
42 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)