LLM学习:大模型基础——fine tuning微调原理
文章摘要:本文系统介绍了大模型微调(finetuning)的核心概念与方法。首先解释了大模型两阶段训练流程(预训练+微调),指出微调可突破基座模型局限、以低成本实现专业领域优化。重点剖析了高效微调技术LoRA的数学原理,通过低秩矩阵分解仅训练少量参数(约1%),显著降低计算成本。文章还详细阐述了矩阵分解(SVD)在推荐系统中的应用,验证了低秩特性的有效性。最后讨论了微调数据准备、硬件需求估算及模型
1、为什么需要fine tuning微调?
首先需要了解,大模型训练有两个部分组成:
(1)预处理训练阶段 --- 训练基座模型
用海量无标注数据,让模型从 “随机参数” 开始,自主学习语言规律和世界常识,相当于 “让模型读遍全网书籍”。预训练实质上是一种无监督学习过程。完成预训练的模型,亦即基座模型(Base Model),拥有了普遍适用的预测能力。例如,GLM-130B模型、OpenAI的四个主要模型均属于基座模型。
(2)微调训练阶段
预训练完成的模型接下来会在针对性的任务数据集上接受更进一步的训练。这一阶段主要涉及对模型权重的细微调整,使其更好地适配具体任务。最终形成的模型将具备不同的能力,如gpt code系列、gpt text系列、ChatGLM-6B等。
fine tuning微调的目的:
(1)突破基座模型的局限
基座模型(如LLaMA、GPT基座版)在训练时未覆盖专业领域数据(如医疗、法律、金融),微调可注入领域术语和逻辑。利用基座模型善于生成文本的能力,可以加大专业能力的微调,生成拥有专业能力方向的大模型,也可以训练一些语气之类的,让它拥有个性化的语气。
(2)性价比最高的优化路径
从头训练千亿级模型需数百万美元算力,而微调仅需 1%-10% 的成本 即可获得专业能力。
示例:用 LoRA(低秩适配) 技术,仅训练0.1%参数即可将通用模型转为法律助手。
(3)解决“幻觉”与安全风险
通过注入领域权威数据(如医学期刊、法律条文),减少模型虚构专业信息。添加安全对齐数据可抑制有害输出(如医疗模型避免推荐未验证疗法)。
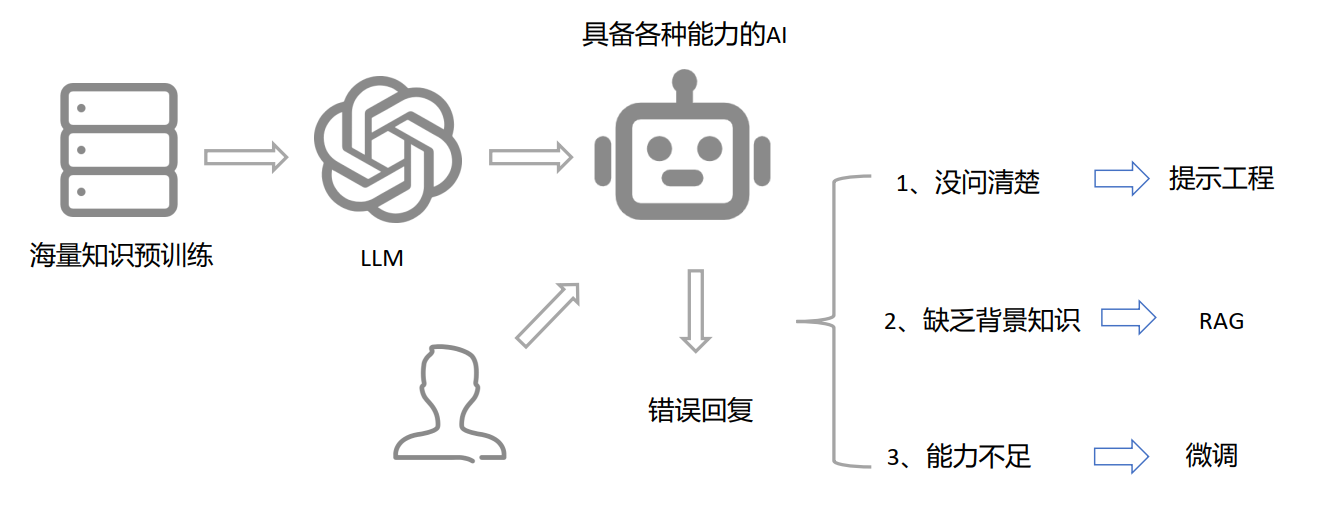
按照上述,微调主要是为了提高专业领域只是的准确性,在较低成本的训练当中,实现专业回答的提高。我们通常会遇到优化大模型回答精确性的问题,一般是用以下三种方式:
优化提示词 ---》 RAG知识扩展 ---》微调
2、高效微调的方法
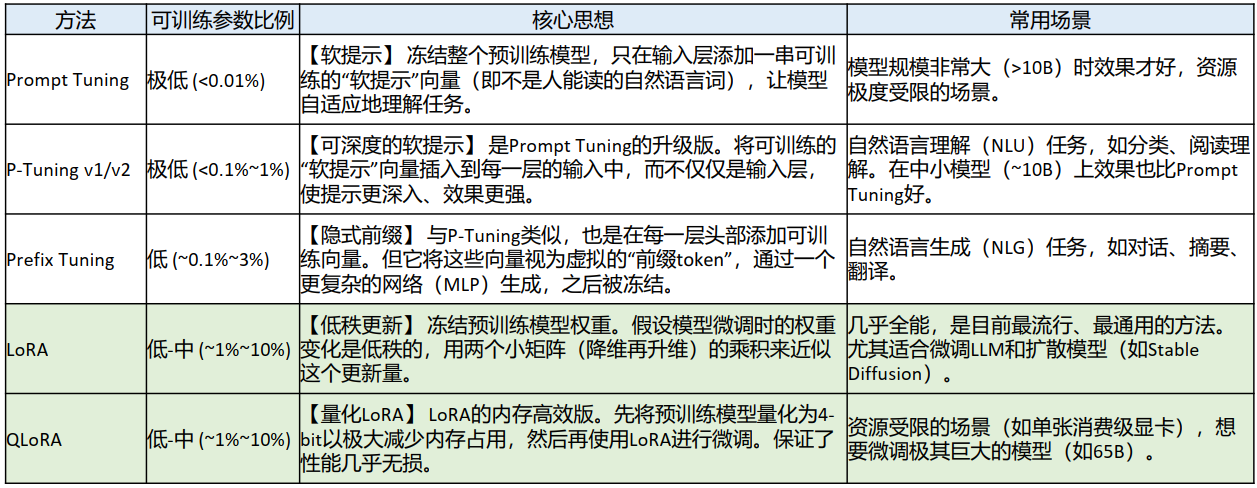
现在主流微调的方法是使用LoRA和QLoRA
3、LoRA的数学原理
3.1 什么是LoRA?
"low-rank adaptation of large language models" 是一种针对大型语言模型进行低秩适应的技术。大型语言模型通常具有数十亿个参数,这使得它们在计算和存储方面非常昂贵。低秩适应的目标是通过将语言模型的参数矩阵分解为低秩近似,来减少模型的复杂度和计算资源的需求。
低秩适应的方法可以通过使用矩阵分解技术,如奇异值分解(Singular Value Decomposition,SVD)或特征值分解(Eigenvalue Decomposition),将语言模型的参数矩阵分解为较低秩的近似矩阵。通过这种方式,可以减少模型的参数量和计算复杂度,同时保留模型的关键特征和性能。
低秩适应的技术可以用于加速大型语言模型的推理过程,减少模型的存储需求,并提高在资源受限环境下的模型效率。它是在大型语言模型优化和压缩领域的一个重要研究方向。
3.2 LoRA 微调的核心思想是什么?
核心问题:微调一个巨大模型很费劲像GPT、 Stable Diffusion这样的大模型有数十亿参数。直接微调所有参数(全量微调)需要巨大的计算资源和存储空间,成本非常高。
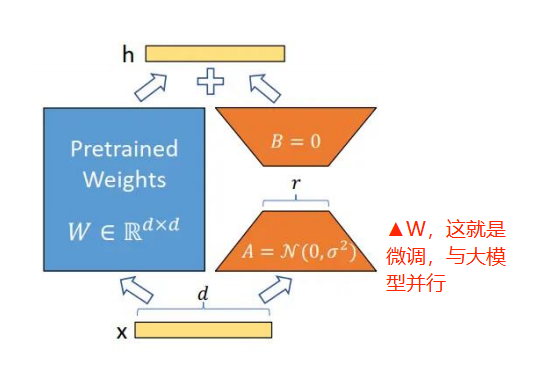
LoRA 的聪明办法:不直接调原始权重LoRA(Low-Rank Adaptation,低秩自适应)提出了一个巧妙的思路:
我们不改变模型原有的巨大权重矩阵W。我们在其旁边增加一个小的“旁路”,通过训练这个旁路来间接影响原始权重。
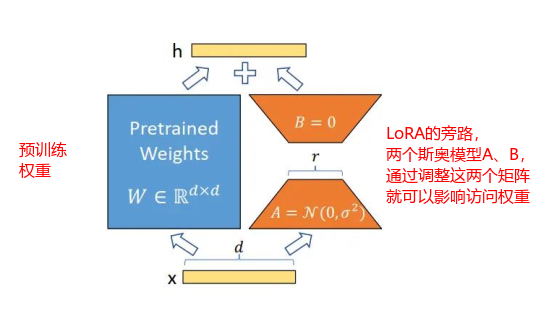
上图中A、B上两个矩阵,A、B做使用的参数量大约是原始数据的1%。
神经网络是一个逐层向前传播的过程,每一层的结果等于上一层的输出乘以权重
h = Wx + BAx
x 代表了上一层的输出
W 是原始预训练权重,冻结不动。
A 和 B 是我们新引入的两个小的、低秩的矩阵。 A负责降维, B负责升维。这个地方如何理解呢?简单举例,如果我们要修改一张照片的内容,直接对照片进行修改工作量比较大,要处理的像素也比较多,可以使用A先降低分辨率,然后进行修改,修改完成之后再用B进行升维还原到之前的分辨率。也就是如上图x -> r ->h 的过程。
BA 合在一起就构成了对原始权重的更新 ΔW。这个 ΔW就是一个低秩矩阵。
微调时,我们只训练 A 和 B 这两个小矩阵,最后只需保存它们(文件很小),推理时再合并到 W 中即可。
3.3 什么是“低秩特性”?
LoRA的原理是 低秩特性
想象一个巨大的Excel表格(比如1000行 x 1000列),里面填满了数字。这个表格就是一个“矩阵”。
高秩矩阵: 这个表格里的数据五花八门,每一行、每一列的信息都独一无二,没有明显的规律。你想简化它?没门!你必须原封不动地保存这100万个数字才能完整描述它。
低秩矩阵: 表格里的数据高度相关,存在明显的“套路”。假设:可能所有行都是第一行的倍数。你只需要保存很少的几行(或几列)基础数据,就能通过组合完美地重建出整个巨大的表格。
思考:比如一份全球气温报告。你不需要保存每个城市的每分钟数据。你只需要知道“纬度”、 “季节”等几个核心因素(低维基础),就能很好地推测出任意地方的气温(重建高维数据)。
3.4 什么是“内在的低秩特性”?
• ΔW是什么:当一个预训练好的大模型(比如ChatGPT)去学习一个新任务时,其内部神经元的连接权重(一个巨大的矩阵 W)需要做出细微的调整。这个调整量就是 ΔW(权重更新)。
• 为什么说它“内在”是低秩的?
尽管 ΔW 在形式上是一个巨大的矩阵(例如有1000x1000=100万个参数),但研究者发现,驱动模型学会新任务所需要的“有效变化”其实非常集中和简单。
• 数学体现:对实际微调产生的 ΔW 矩阵做SVD分解,会发现它的奇异值衰减得非常快。绝大部分奇异值都接近零,只有前面几个奇异值特别大。
矩阵拆解:将一个大矩阵,拆解成两个小矩阵
=> 真正起作用的更新信息,都集中在那几个最大的奇异值所对应的方向上。其余的都是可以忽略的冗余信息。
=> 这是LoRA算法的核心假设。
使用LoRA进行微调,相当于给原始大模型添加一个插件,通过上述的升维、降维的矩阵实现只用1%的数据训练大模型。一个大模型可以加入多种LoRA的微调。
4、通过猜你喜欢,解释矩阵分解
我们假设一个场景:为海量的用户和商品
进行推荐:
• 为用户找到其感兴趣的item推荐给他
• 用矩阵表示收集到的用户行为数据,12个用户,9部电影
如下图,1代表该用户对该电影喜欢,没有值的代表该用户不知道对该电影是否喜欢。
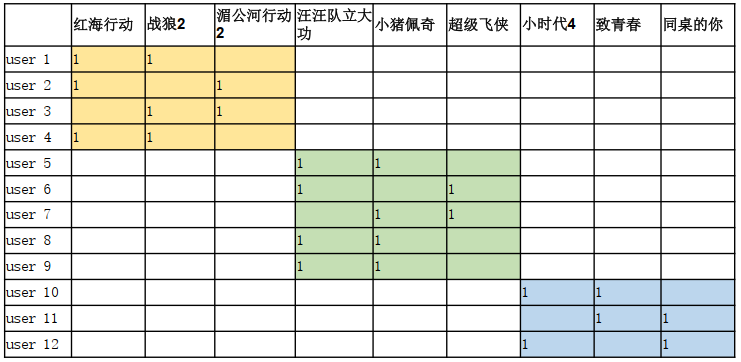
• 矩阵分解要做的是预测出矩阵中缺失的评分,使得预测评分能反映用户的喜欢程度。
• 可以把预测评分最高的前K个电影推荐给用户了。
LoRA不关注每一个用户对所有电影的情况,只关注每个用户对每一类电影的情况。按上图划分,电影可以分为3类,这样就能看出每个用户他对那一类电影的倾向。所以就可以使用降维思想,这里我们的秩(r)就是等于 3 。原本的评分矩阵是又大又稀疏的,分解之后2个矩阵就变得稠密。大模型眼里是以向量描述事物的,大模型会去观察User矩阵,用户的听歌爱好体现在User向量上;也会去观察Item矩阵,电影的风格也会体现在Item向量上,将用户在对应类别上的向量值和电影在对应类别上面的向量值加入到以下两个矩阵中。
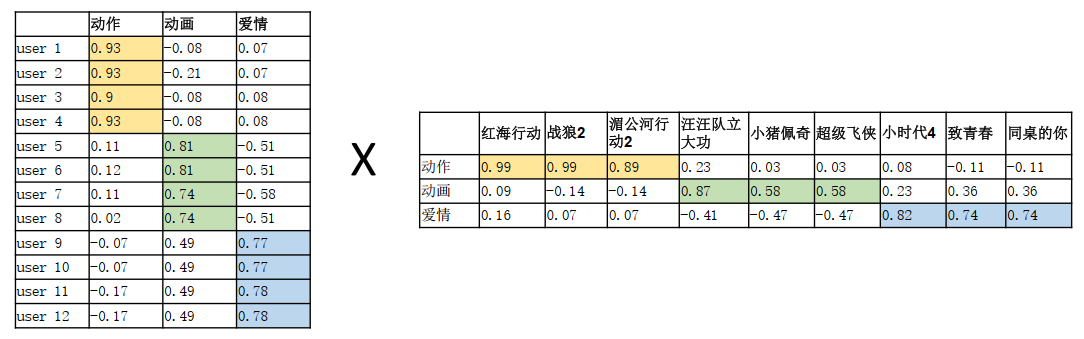
两个稠密的矩阵相乘就可以得到一个大的评分表:
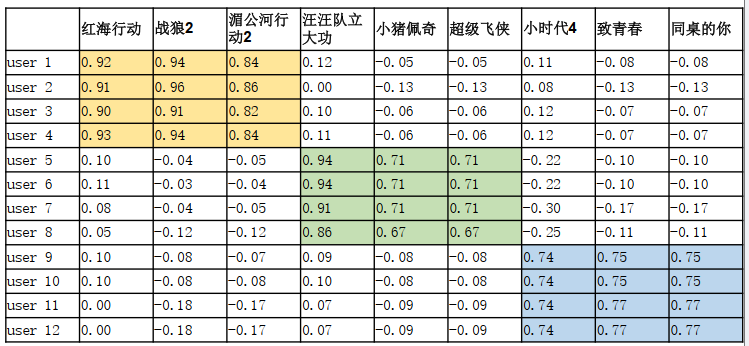
根据计算出的评分表,给user 1推荐2部电影的话,红海行动 和 战狼2 user1已经给出评分了,所以不推荐。未给出评分的电影里,推荐湄公河行动2 和 汪汪队立大功。
矩阵分解是一种仿真模拟,他是有损失和矩阵压缩,是有误差的,我们尽可能找到一个最好的仿真,保证他们的误差最小。
5、矩阵分解的目标函数

这里rui相当于上图表中的1,确定喜欢。以user 1为例,他对红海行动和战狼2的评分是1,但是最终得出的结果是0.92和0.94,期望这个误差越小越好。湄公河行动2 没有进行打分,所以不关注该偏差。

上面的r ,也就秩是怎么来的?在LoRA中是手动指定的,4,8,16。。。
目标函数的还原,在上述的损失函数中,我们期望最终的结果越小越好,这代表着我们的矩阵X和矩阵Y的内积和实际评分的差距越小。

目标函数最优化问题的工程解法:
• ALS, Alternating Least Squares,交替最小二乘法
• Step1, 固定Y 优化X
• Step2, 固定X 优化Y
• 重复Step1和2, 直到X 和Y 收敛。每次固定一个矩阵,优化另一个矩阵,都是最小二乘问题


当导数为0时,相当于梯度为0,得到目标函数。
简单总结以下LoRA的效果,假设大模型是1000*1000的矩阵,我们分解成1000*3和3*1000两个矩阵,我们训练使用的数据量是6000,但是直接调整大模型使用的数据量为1000 000,只用了千分之6的数据量就模型了整个大模型的训练。这也就能看出秩如果低了,模拟的精度就差一些,用的数据少一些,秩大了,用的数据多一些,模拟的精度也会高一些。
6、SVD矩阵分解
SVD(Singular Value Decomposition,奇异值分解)是一种重要的矩阵分解方法,SVD矩阵分解是将一个矩阵分解为三个矩阵的乘积,其中第一个矩阵是一个正交矩阵,第二个矩阵是对角矩阵,第三个矩阵是另一个正交矩阵的转置。对于一个m×n的矩阵A,其SVD矩阵分解为:
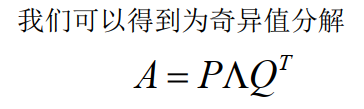
P为左奇异矩阵, m*m维
Q为右奇异矩阵, n*n维
Λ对角线上的非零元素为特征值λ1, λ2, ... , λk。矩阵中会有一些特征向量和特征值,代表着一些权重,越大代表越明显。
在推荐系统中
左奇异矩阵: User矩阵
右奇异矩阵: Item矩阵
任何矩阵都可以拆成多个矩阵的叠加,用公式表示如下:

以下可以使用图片作为例子进行拆解,一张图片可以理解为一个大的像素矩阵。可以使用以下代码对图片进行一个矩阵拆解,然后再显示拆解后的图片:
import numpy as np
from scipy.linalg import svd
from PIL import Image
import matplotlib.pyplot as plt
# 取前k个特征,对图像进行还原
def get_image_feature(s, k):
# 对于S,只保留前K个特征值
s_temp = np.zeros(s.shape[0])
s_temp[0:k] = s[0:k]
s = s_temp * np.identity(s.shape[0])
# 用新的s_temp,以及p,q重构A
temp = np.dot(p,s)
temp = np.dot(temp,q)
plt.imshow(temp, cmap=plt.cm.gray, interpolation='nearest')
plt.show()
print(A-temp)
# 加载256色图片
image = Image.open('D:\\CODE\\DEMO_CODE\\ai\\13-Fine-tuning微调艺术\\image_svd\\256.bmp')
A = np.array(image)
# 显示原图像
plt.imshow(A, cmap=plt.cm.gray, interpolation='nearest')
plt.show()
# 对图像矩阵A进行奇异值分解,得到p,s,q
p,s,q = svd(A, full_matrices=False)
print(s)
print(len(s))
# 取前k个特征,对图像进行还原
get_image_feature(s, 5)
get_image_feature(s, 50)
get_image_feature(s, 500)
上述代码中,使用svd工具将图像矩阵分解成p、s、q三个矩阵,并使用不同个数的特征矩阵进行还原图片,效果如下图:

k的最大值是1080个,这个数值是因为特征矩阵是一个矩阵的对角线,所以它的个数是矩阵行和列中的最小值1440*1080的矩阵的特征值是1080个。原始图片就是1080个特征值相加,k=5就是5个特征值相加......下图给一个SVD矩阵分解的公式例子:

代码中的get_image_feature含义就是p和q作为左奇异矩阵和右奇异矩阵,他们不变,只取k个特征值进行重构图片。
少量的信息(比如10%) ,可以还原大部分图像信息(比如99%)
当K=50时,我们只需要保存 (1440+1+1080)*50=126050个元素,占比126050/(1440*1080)=8%
从图片显示上能看出,k=50时,只用了8%的信息就能得出接近90%的效果。
7、LoRA 原理总结
Lora (Low-Rank Adaptation of Large Language Models)
• 在原始预训练模型旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量
• 将原模型 与 降维矩阵A,升维矩阵B分开
训练阶段,只训练B和A
推理阶段,将BA加到原参数,即h=Wx+BAx=(W+BA)x
不引入额外的推理延迟
• 初始化,A采用高斯分布初始化,B初始化为全0,这样训练开始时旁路为0矩阵
• 多任务切换,当前任务W0+B1A1,将lora部分减掉,换成B2A2,即可实现任务切换
• 秩的选取:对于一般的任务,rank=1,2,4,8即可,如果任务较大,可以选择更大的rank
• 大模型的低秩适配器,即固定大模型,增加低秩分解的矩阵来适配下游任务
• Lora的优点:
1)一个中心模型服务多个下游任务(LoRA插件),节省参数存储量
2)推理阶段不引入额外计算量
3)训练任务比较稳定,效果比较好
如果不使用Lora进行训练会怎样?
如果训练集很小,比如20-30 samples,会把大模型带跑。因为微调大模型会针对小样本进行过度拟合。
LoRA微调的结果就好像一个滤镜,在原始照片上加滤镜;也可以理解成原始大模型不变,打上补丁。
Q:那跟蒸馏有什么区别?
LoRA 微调微调的训练,主要是增加一个 小的旁支,来得到 增量的微调结果
蒸馏,将大尺寸模型的能力 迁移到 小尺寸模型上;用大尺寸(70B)模型模的 <input, output> 作为训练集,让小尺寸模型(7B)进行学习。
Q:蒸馏是不是可以理解成全参数微调
蒸馏是一种学习迁移,将大模型的能力迁移到小尺寸模型。
蒸馏是训练样本上的迁移,lora是对大模型参数的近似迁移
Peft库:
https://github.com/huggingface/peft
很方便地实现将普通的HF模型变成用于支持轻量级fine tune的模型,目前支持4种策略:
1)LoRA:大模型的低秩适配器
2)Prefix Tuning: Optimizing Continuous Prompts for Generation
3)P-Tuning: GPT Understands, Too
4)Prompt Tuning: The Power of Scale for Parameter Efficient Prompt Tuning
8、微调数据的准备
8.1 LoRA既然能对参数高效微调,那么对数据的要求就会很低?
因为可训练的参数少,模型更加依赖我们提供的数据来精准学习 => 高质量的数据是微调成功的关键。数据的质量要高于数量,高质量的数据依赖于业务上的收集,收集后还需要进行筛选,最好是完整性的样本。筛选样本比较好的方法是使用LLM进行筛选。
高质量的数据:
• 一致性:提供的数据格式、指令风格和期望的输出需要统一。
比如:一条数据是“写一首诗” -> [诗歌],下一条是“Summarize this: ...” -> [摘要]
=> 模型会感到困惑,不知道到底要学什么。
最佳实践:所有数据都应遵循相同的模板。比如
<指令>{instruction}</指令>
<输入>{input}</输入>
• 准确性:
数据中的答案需要保证正确性,模型会学习数据中的所有 pattern
=> 包括里面的错误,garbage in garbage out
• 多样性:
在保证一致性的前提下,指令和输入要尽可能覆盖各种情况 => 提高模型的泛化能力
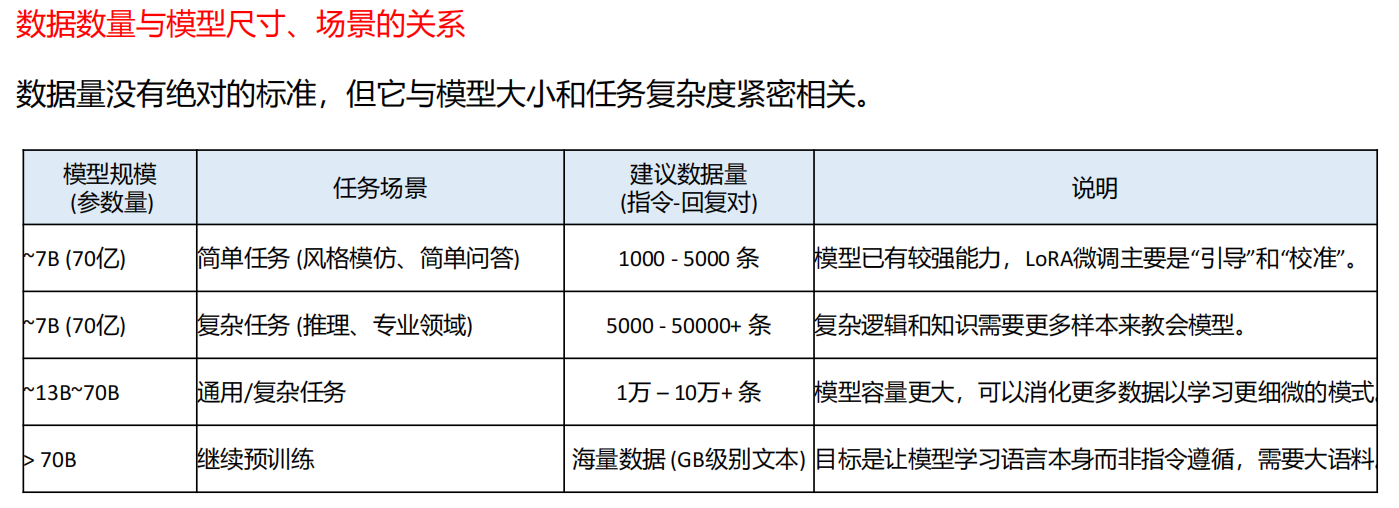
8.2 如何对模型微调进行数据准备?
Step1:聚焦质量
花80%的时间在数据清洗、格式统一和答案校验上。1000条完美数据远胜于10万条杂乱数据。
Step2:评估数量
根据你的模型大小和任务难度,参考上述范围设定一个目标。从小规模开始(如1000条),进行实验,如果模型欠拟合(表现不好),再考虑增加数据。
任务越复杂,所需数据越多。
有一个“黄金起点”:对于许多任务,1000-6000条高质量指令数据已经可以产生很好的微调效果。
9、硬件需求和显存估算
9.1 微调显存估算的逻辑是什么?
微调时的总显存占用主要来自四个方面,可以用公式来估算:
总显存 ≈ (模型权重显存) + (优化器状态显存) + (梯度显存) + (前向传播激活值显存)
模型权重显存: 这是最大的部分。模型通常以float16 (FP16)或bfloat16 (BF16)格式加载。
计算公式:模型参数量 (B) * 2字节
比如:一个7B(70亿)参数的模型,其权重显存约为 7 * 10^9 * 2字节 ≈ 14 GB。
优化器状态显存: 优化器(如Adam)为每个可训练参数保存的状态。
对于AdamW,它会为每个参数保存动量(momentum) 和方差(variance) 两个状态,通常也是FP16格式。
LoRA计算:假设LoRA可训练参数量为 L,则优化器状态显存约为 L (一般是1%的大模型参数量)* 4字节 * 2(两个状态)。
梯度显存: 训练时反向传播计算的梯度。通常也是FP16格式。
LoRA计算:约为 L * 2字节(只存LoRA参数的梯度)。
前向传播激活值显存: 计算过程中产生的中间变量(激活值),用于反向传播。这部分与批次大小(batch size) 和序列长度(sequence length) 强相关,估算复杂=> 可以简单估算为模型权重显存的20%-50%。
9.2 如果微调一个7B(70亿)参数的模型需要多少显存?
LoRA的魔力在于,它通过大幅减少可训练参数量 L,从而极大地削减了第2、 3部分的显存占用,使得第1部分(模型权重)成了绝对主力。

• 对于7B模型
一张24GB的消费级显卡(如RTX 4090) 可以流畅地微调,甚至可以使用稍大的batch size。
• 对于13B模型:
仅模型权重就需要26GB => 需要至少一张32GB的显卡(如RTX5090 32GB)或使用QLoRA技术。
• QLoRA是终极解决方案:
它将模型权重量化到4-bit,能将模型权重显存减少到约 模型参数量 * 0.5字节。=> 微调7B模型仅需约6-8GB显存,让绝大多数显卡都能参与进来。
显存大头是模型本身, LoRA通过减少可训练参数来优化其余部分。
估算公式:总显存 ≈ (模型参数量 * 2字节) * (1 + 激活系数) + (L * 10字节)。激活系数通常取0.2~0.5。
硬件选择:
• 7B/8B模型:推荐 24GB 显存(如3090/4090)。
• 13B/14B模型:推荐 32GB+ 显存(如V100/A100),或使用QLoRA。
• 70B模型:必须使用QLoRA和多卡部署。
10、微调后的模型评估
10.1 我们投入了时间、数据和算力,如何证明微调后的模型变好了?
数据集划分——验证集与测试集
训练集:用于更新模型权重的数据 => 喂给LoRA微调的数据。
验证集:用于在训练过程中监控模型表现,调整超参数(如学习率),以及进行模型选择(比如选择训练得最好的那个checkpoint) => 它不能用于最终的性能报告。像是模拟考试,验证你得情况。
测试集:用于最终、一次性的性能评估。它模拟了模型在“真实世界”中遇到的、从未见过的新数据上的表现。在整个微调过程中,测试集必须被严格“封存”,不能以任何形式用于训练。
测试集是模型的“期末考试”,绝对不能提前泄露考题。
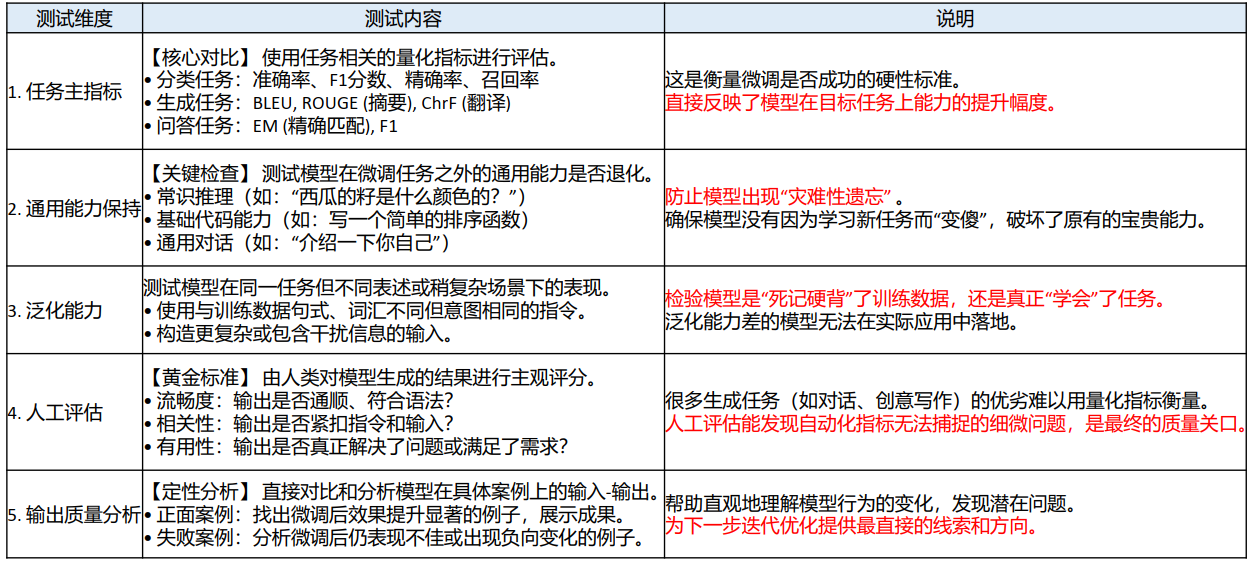
• 准备阶段:提前从原始数据中划分出验证集和测试集。
• 训练中:使用验证集监控训练过程,防止过拟合(如果验证集指标开始下降,而训练集指标还在上升,说明模型可能过拟合了)。
• 训练后:
Step1:在测试集上运行基座模型和微调后的模型,记录所有主指标。
Step2:进行通用能力测试和泛化能力测试。
Step3:人工抽查测试集和通用能力测试中的一些样本输出,进行质量分析。
Step4:综合所有维度做出判断。主指标大幅提升,同时通用能力没有显著退化,才是一次成功的微调。
11、QLoRA
11.1 QLoRA 的思路是怎么样的?
QLoRA(Quantized Low-Rank Adaptation)是一种结合了量化和低秩适应的方法,用于进一步减少大规模语言模型的计算和存储开销。它的思路可以概括如下:
1. 量化参数:首先,对大规模语言模型的参数进行量化。量化是一种将浮点数参数转换为固定位数的整数或更简单表示的方法。通过减少参数位数,可以显著减少模型的存储需求和计算复杂度。
2. 参数矩阵分解:在量化参数之后,QLoRA使用低秩分解的方法对量化参数矩阵进行分解。低秩分解将参数矩阵分解为较小的矩阵的乘积,从而进一步减少模型的参数量和计算复杂度。
3. 低秩适应:在参数矩阵分解之后,选择保留较低秩的近似矩阵,并舍弃一些对模型性能影响较小的细节。这样可以进一步减少模型的计算需求,同时保持模型的关键特征和性能。
4. 重构模型:使用低秩适应后的近似矩阵和量化参数重新构建语言模型。这样得到的模型既具有较低的参数量和计算需求,又能保持相对较高的性能。
通过结合量化和低秩适应的思路,QLoRA能够进一步减少大型语言模型的计算和存储开销。它在资源受限的环境下,尤其是移动设备等场景中,具有重要的应用价值。
11.2 QLoRA的特点是什么?
QLoRA(Quantized Low-Rank Adaptation)具有以下几个特点:
1. 量化降低存储需求:通过将参数进行量化,将浮点数参数转换为固定位数的整数或更简单的表示,从而显著减少模型的存储需求。这对于在资源受限的设备上使用大型语言模型非常有益。
2. 低秩适应减少计算复杂度:通过低秩适应的方法,将量化参数矩阵分解为较小的矩阵的乘积,进一步减少模型的参数量和计算复杂度。这可以加速模型的推理过程,提高模型的效率。
3. 保持关键特征和性能:虽然量化和低秩适应会舍弃一些对模型性能影响较小的细节,但它们会尽量保留模型的关键特征和性能。通过选择合适的量化位数和低秩近似矩阵,可以最大限度地保持模型的性能。
4. 可扩展性和通用性:QLoRA的量化和低秩适应方法可以应用于各种大型语言模型,包括预训练的Transformer模型等。它是一种通用的技术,可以适应不同的模型架构和任务。
5. 综合优化:QLoRA综合考虑了量化和低秩适应的优势,通过量化降低存储需求,再通过低秩适应减少计算复杂度,从而实现了更高效的模型。这使得QLoRA成为在资源受限环境下使用大型语言模型的有效策略。
总之,QLoRA通过量化和低秩适应的方法,可以在减少存储需求和计算复杂度的同时,保持模型的关键特征和性能。它具有高效、通用和可扩展的特点,适用于各种大型语言模型的优化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)