OpenMMLab AI实战二——姿态估计
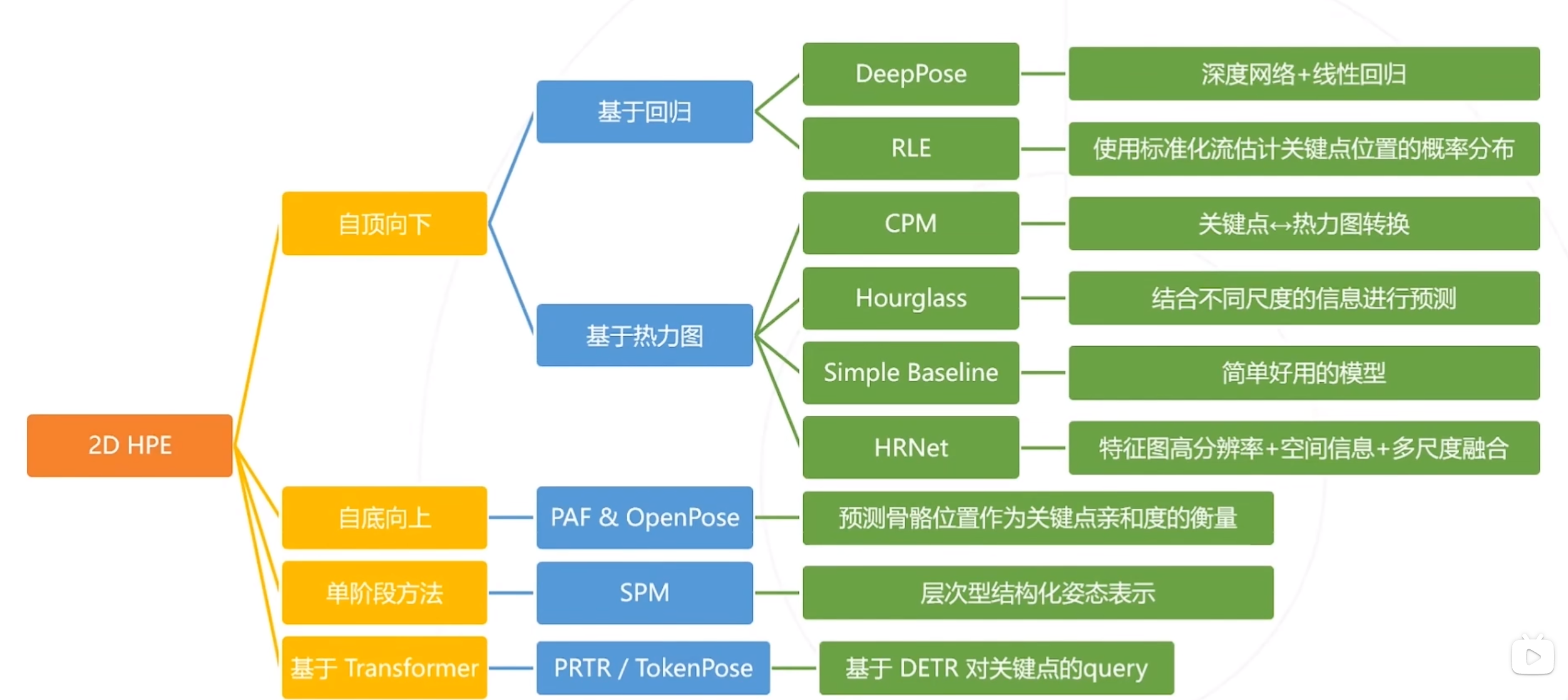
2D目标检测主要有四种方法:自顶而下方法、自低向上方法、单阶段的方法、基于Transformer的方法,现在较多是基于热力图的方式进行检测,但是该方法计算量较大。:基于图像同时预测关节位置和四肢走向,利用肢体走向辅助关键点的聚类,即,如果某两个关键点由末端肢体相连,则两个关键点属于同一人。如果预测关节和真实关节之间的距离在某个阈值(可变)内,则认为检测到的关键点是正确的(2D、3D均可用)?概念:
姿态估计
概念:从给定的图像中识别人脸、手部、身体等关键点。
输入:图像I
输出:所有关键点的像素坐标(x1,y1),(x2,y2)……(xj,yj),其中j为关键点的总数,取决于具体的关键点模型。
常见任务:2D位姿估计、3D位姿估计、人体参数化模型。
下游任务:行为识别、CG、动画、人机交互、动物行为识别。
2D姿态估计——给张图片,估计姿态
概念:在图像上定位人体关键点(通常为人体的主要关节)的坐标
例如:
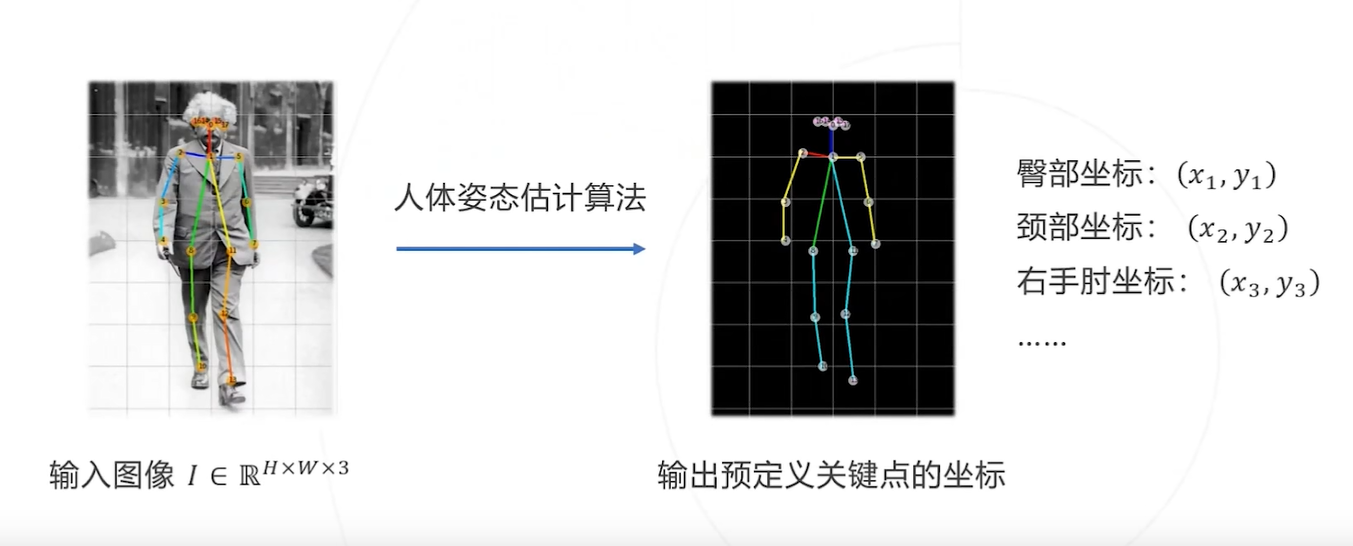
基本思路:将关键点检测问题建模乘一个回归问题,让模型直接回归关键点的坐标(类似单阶段目标检测?)例如:(现有问题:模型直接回归坐标有些困难,精度不是最优)
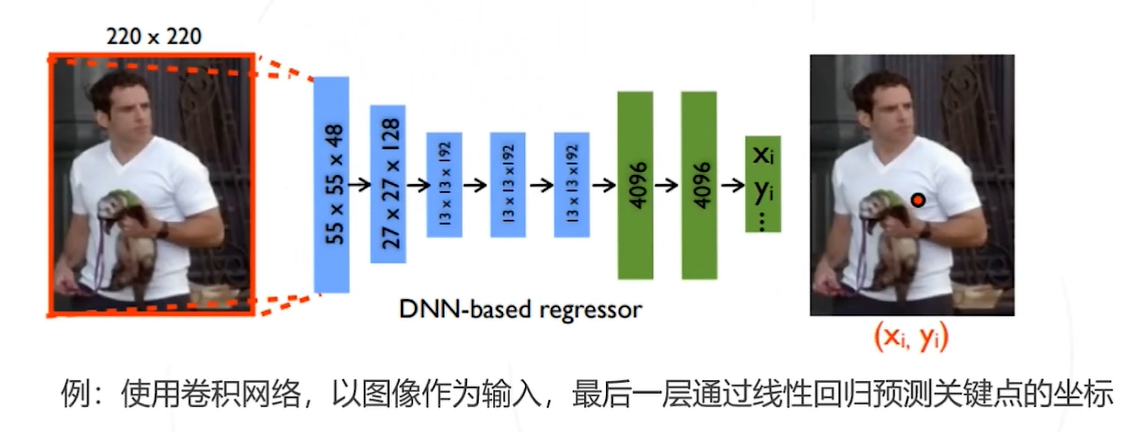
针对上述问题,采用不直接回归关键点的坐标,而是预测关键点位于每个位置的概率。
例:表示关键点
位于
的概率为1,
为热力图,尺寸与原图
相同或按比例缩小(是否可以认为是预测图像中每个点是否为关键点的概率,类似于yolov3中的置信度?)
-
热力图可以基于原始关键点坐标生成,作为训练网络的监督信息
-
网络预测的热力图也可以通过求极大值等方法得到关键点的坐标
优点:模型预测热力图比直接回归坐标相对容易,模型精度相对更高,因此主流算法更多基于热力图
缺点:计算消耗量更大
方法步骤:
1. 从数据标注生成热力图:主要以高斯核的形式生成热力图(概率图)
2. 利用热力图训练模型
3. 从热力图还原关键点
-
方法一:朴素方法:求热力图最大值位置
-
方法二:归一化热力图形成点位于不同位置的概率,在计算位置的期望(取平均值)
多人估计
常用方法:
1. 自顶向下方法
-
Step1:使用目标检测算法检测出每个人体
-
Step2 :基于单人图像估计每个人的姿态
-
缺点:整体精度受限于检测器的精度、速度和计算量会正比于人数
2. 自底向上方法
-
Step1:使用关键点模型检测出所有人体关键点
-
Step2 :基于位置关系或其他辅助信息将关键点组合成不同的人(聚类)
-
优点:推理速度和人数无关
基于回归的自顶向下方法
Residual Log-likelihood Estimation(RLE)(2021)
基于热力图的自顶向下方法
Stacked Hourglass Networks for Human Pose Estimation(2016)
Simple Baselines for Human Pose Estimation and Tracking(2018)
Deep High-Resolution Representation Learning for Human Pose Estimation(2020)
自底向下方法
基本思路:基于图像同时预测关节位置和四肢走向,利用肢体走向辅助关键点的聚类,即,如果某两个关键点由末端肢体相连,则两个关键点属于同一人
例如: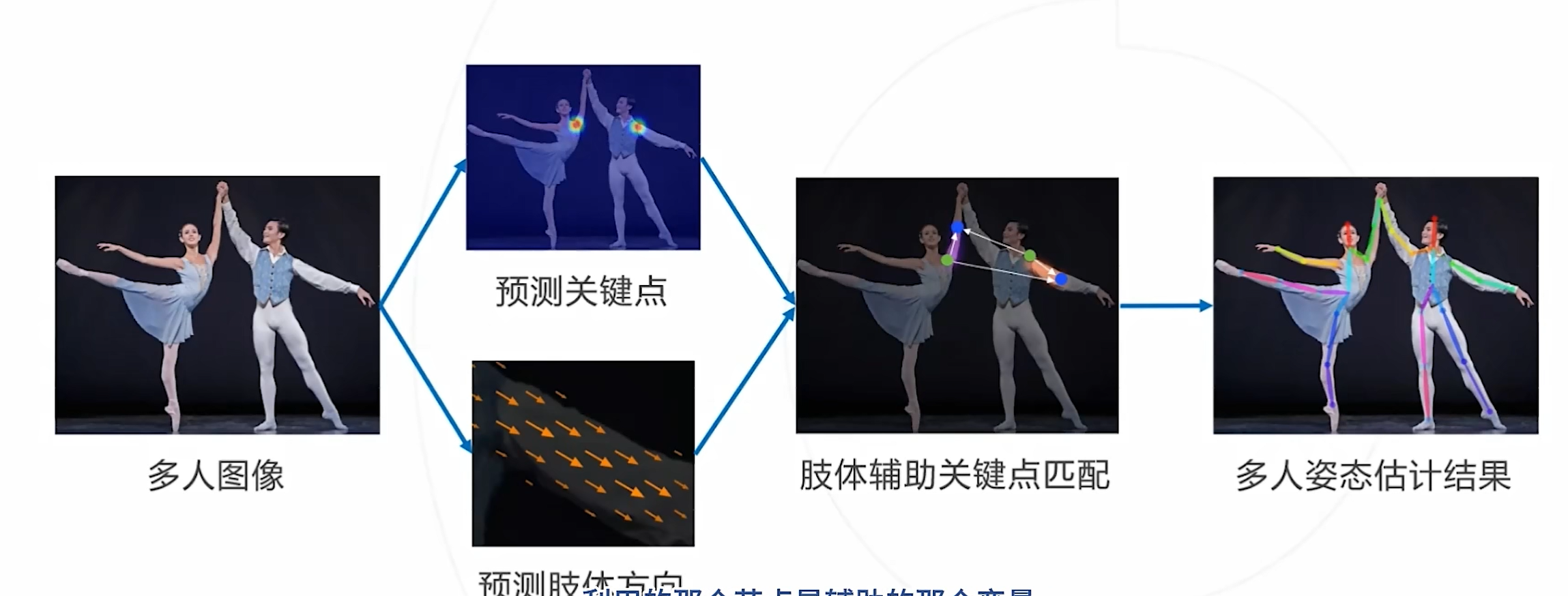
单阶段方法
Single-Stage Multi-Person Pose Machines(2019) 论文方法与YOLO类似,目标检测中回归两个向量,这篇文章回归n个向量
基于Transformer的方法
Pose recognition with cascade transformers(2021)
Tokenpose: Learning Keypoint Tokens for Human Pose Estimation(2021)
Transformer在目标检测中的应用也比较多,如最近的RT-DERT等目标检测器,实现了较为SOTA的效果。
小结
2D目标检测主要有四种方法:自顶而下方法、自低向上方法、单阶段的方法、基于Transformer的方法,现在较多是基于热力图的方式进行检测,但是该方法计算量较大
3D姿态估计
概念:通过给定的图像预测人体关键点在三维空间中的坐标,可以在三维空间(相对关系)中还原人体的姿态
输入:图像I
输出:所有人的所有关键点的空间坐标 i=1……N j=1……J,其中
为图中总人数,
为关键点总数例如:
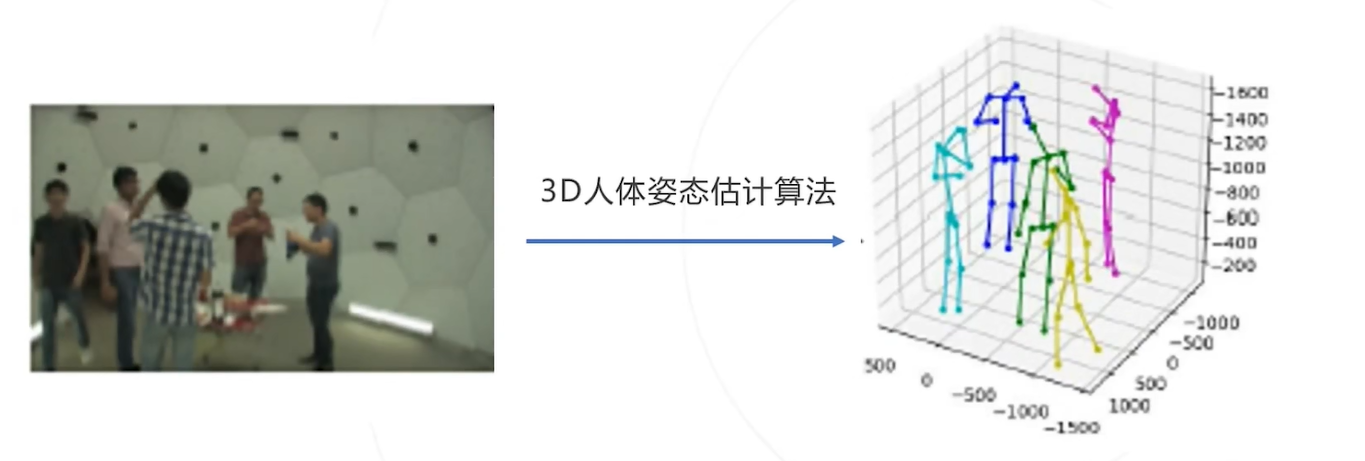
常用思路:
-
思路一:直接预测,直接从2D图像回归3D坐标,而2D坐标不包含深度,利用语义特征或者人体的刚性实现3D位姿推理
-
思路二:利用视频信息,可利用视频来获得更多的帧间信息辅助判断
-
思路三:利用多视角图像,直接运用同一对象的多视角拍摄的图片来预测和还原出3D信息
Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose(2017)
A simple yet effective baseline for 3d human pose estimation(2017)
VoxelPose: Towards Multi-camera 3D Human Pose Estimation in Wild Environment(2020)
评估指标
1. Percentage of Correct Parts(PCP):PCP以肢体的检出率为评价指标
2. Percentage of Detected Joints(PDJ):PDJ关节点的位置精度作为评价指标
-
考虑每个人的左右大臂、小臂、大腿、小腿、头部共计4 x 2=8+1 个肢体
-
如果两个预测关节位置和诊室肢体关节位置之间的距离小于等于肢体长度的一半,则认为肢体已经检测到且是正确的部分
-
对于某个特征部位,完整数据集上的指标为PCP=整个数据集中正确检出的此部位数/整个数据集中此部位总数
-
考虑头、肩、肘、腕、臀、膝、踝几个关键点
-
如果预测关节和真实关节之间的距离在躯干直径的某个比例范围内,则认为检测到了关节
-
可通过改变比例,获得不同程度的定位精度的检测率
3. Percentage of Correct Key-points(PCK):PCK以关键点的检测精度作为评价指标
-
如果预测关节和真实关节之间的距离在某个阈值(可变)内,则认为检测到的关键点是正确的(2D、3D均可用)
-
PCK阈值通常是根据对象的比例设置的,对象的比例封闭在边界框内
4. Object Keypoint Similarity(OKS) based mAP
-
OKS based mAP以关键点相似度(OKS)作为评价指标计算mAP,OKS为MS COCO竞赛指定的关键点评价指标

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)