CosyVoice安装部署和基本使用
CosyVoice是阿里开源的多语言语音生成大模型,支持文本转语音、音色克隆和跨语种合成。安装需拉取GitHub源码,创建Python 3.10虚拟环境并安装依赖库。提供三种模型:基础版(300M)、微调版(300M-SFT)和指令版(300M-Instruct),可通过ModelScope下载。运行WebUI后,用户可上传音频或文本生成语音,支持自然语言指令控制语调、情感等参数。该工具适用于语音
·
| CosyVoice 是阿里通义语音实验室发布的开源多语言语音生成大模型,依托大规模预训练语言模型,深度融合文本理解与语音生成技术,能够将各类文本内容精准转化为高度拟人化的自然语音。 |
安装部署
拉取源码
从github上拉去代码,并且进入目录更新
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
cd CosyVoice
git submodule update --init --recursive
创建虚拟环境(python 3.10环境)
利用conda创建环境cosyvoice,并且激活环境
conda create -n cosyvoice python=3.10
conda activate cosyvoice
安装依赖库
conda install -y -c conda-forge pynini==2.1.5
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
安装音频处理工具和开发依赖库
ubuntu系统环境下
sudo apt-get install sox libsox-dev
centos系统环境下
sudo yum install sox sox-devel
下载模型
通过魔塔下载
pip install modelscope
模型选择
CosyVoice-300M(基础版)
模型定位:通用语音合成解决方案
核心功能:
- 零样本音色克隆:仅需3-10秒原始音频即可复现音色特征(含韵律、情感等细节)
- 跨语种合成:支持中/英/日/韩及粤语、四川话等多方言
- 实时响应:采用双向流建模技术,首包延迟低至150ms
modelscope download --model iic/CosyVoice-300M
CosyVoice-300M-SFT(微调版)
模型优化:通过领域数据专项训练提升任务表现
增强功能:
- 保留基础版所有能力
- 内置预置音色库(免样本输入)
- 强化情感与方言调控,支持更精细的口音/情绪调整
modelscope download --model iic/CosyVoice-300M-Instruct
CosyVoice-300M-Instruct(指令版)
交互方式:支持自然语言指令控制
特色功能:
- 通过文本标签(如
<laugh>)或自然指令(如"用欢快语气")调节说话人参数(身份/情绪/性别/语速/音高)- 支持插入环境音效(笑声/呼吸声)及词汇重音强调
modelscope download --model iic/CosyVoice-300M-SFT
启用ui界面
指定下载模型的目录,一般通过魔塔下载的模型存在于/root/.cache/modelscope/下
默认运行在8000端口,也可以通过–port指定端口
python3 webui.py --model_dir /root/.cache/modelscope/hub/iic/CosyVoice-300M
访问ip地址+端口,例如192.168.10.100:8000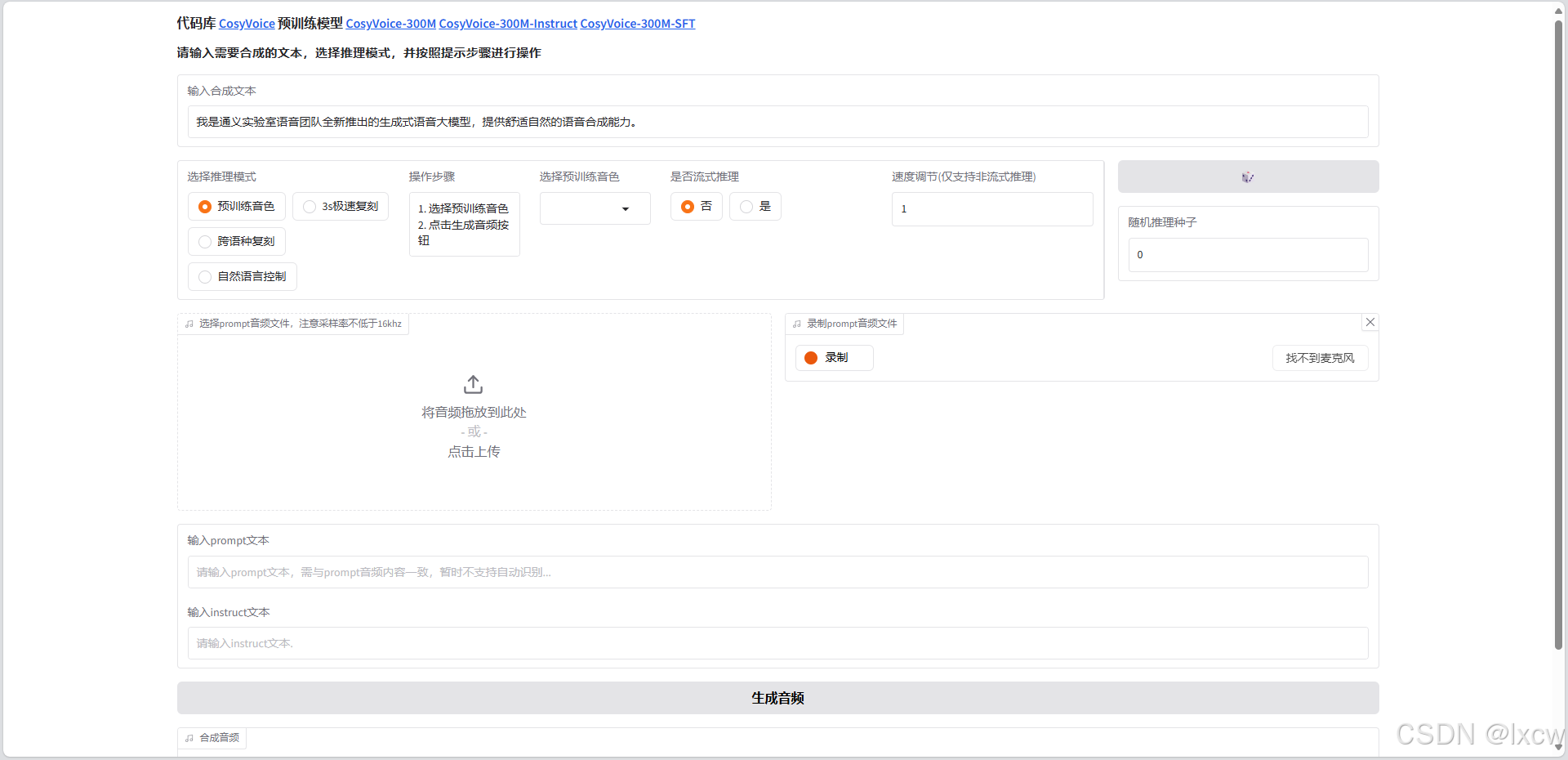
若使用自然语言控制,需要指定CosyVoice-300M-Instruct模型
python3 webui.py --port 8001 --model_dir /root/.cache/modelscope/hub/iic/CosyVoice-300M-Instruct
3s极速复刻,输入合成文本,可以通过麦克风录入一段音频,或者上传本地音频,输入prompt文本,也就是上传音频的文字内容,要准确,然后点击生成音频,等待几秒生成即可
ok,部署和基本使用介绍完了,后面再介绍进阶的开发使用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)