Java集合框架——Day3
首尾频繁操作→ 用LinkedList例子:实现队列(FIFO),用addLast()入队,出队。例子:实现栈(LIFO),用addFirst()压栈,出栈。需要快速随机访问→ 用ArrayList。LinkedList的迭代器是专门为链表遍历设计的,效率比下标访问高。Iterator:只能单向走 + 删除。:能前后走 + 插入/修改。fail-fast 机制:在遍历时,如果外部修改集合,会抛。默
LinkList集合
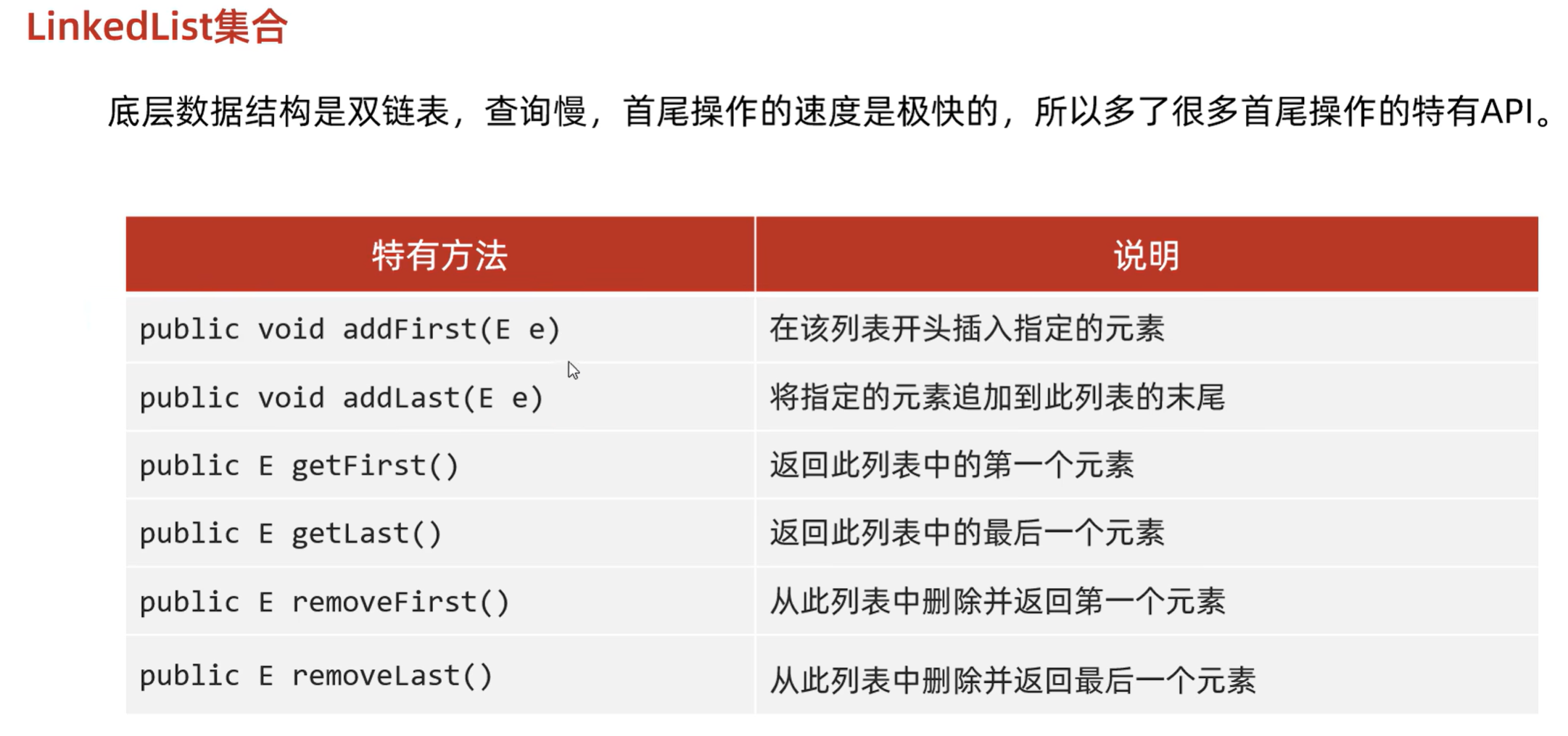
1. LinkedList 底层原理
-
底层结构:
LinkedList底层是 双向链表(每个节点都保存了前驱指针prev和后继指针next)。 -
优点:
- 插入和删除速度快(尤其在首尾,几乎是
O(1)时间)。 - 特别适合做 队列、栈 这样的数据结构。
- 插入和删除速度快(尤其在首尾,几乎是
-
缺点:
- 查询效率低(查找第 k 个元素要从头或尾开始遍历,最差
O(n))。
- 查询效率低(查找第 k 个元素要从头或尾开始遍历,最差
对比:
ArrayList查询快(随机访问O(1)),但插入删除慢(特别是中间位置,因为要移动数组)。
2. LinkedList 特有方法
这些方法是因为 双链表的结构,所以它多了很多 首尾操作的 API:
(1)public void addFirst(E e)
👉 在链表 开头 插入元素。
相当于把元素塞到第一个位置。
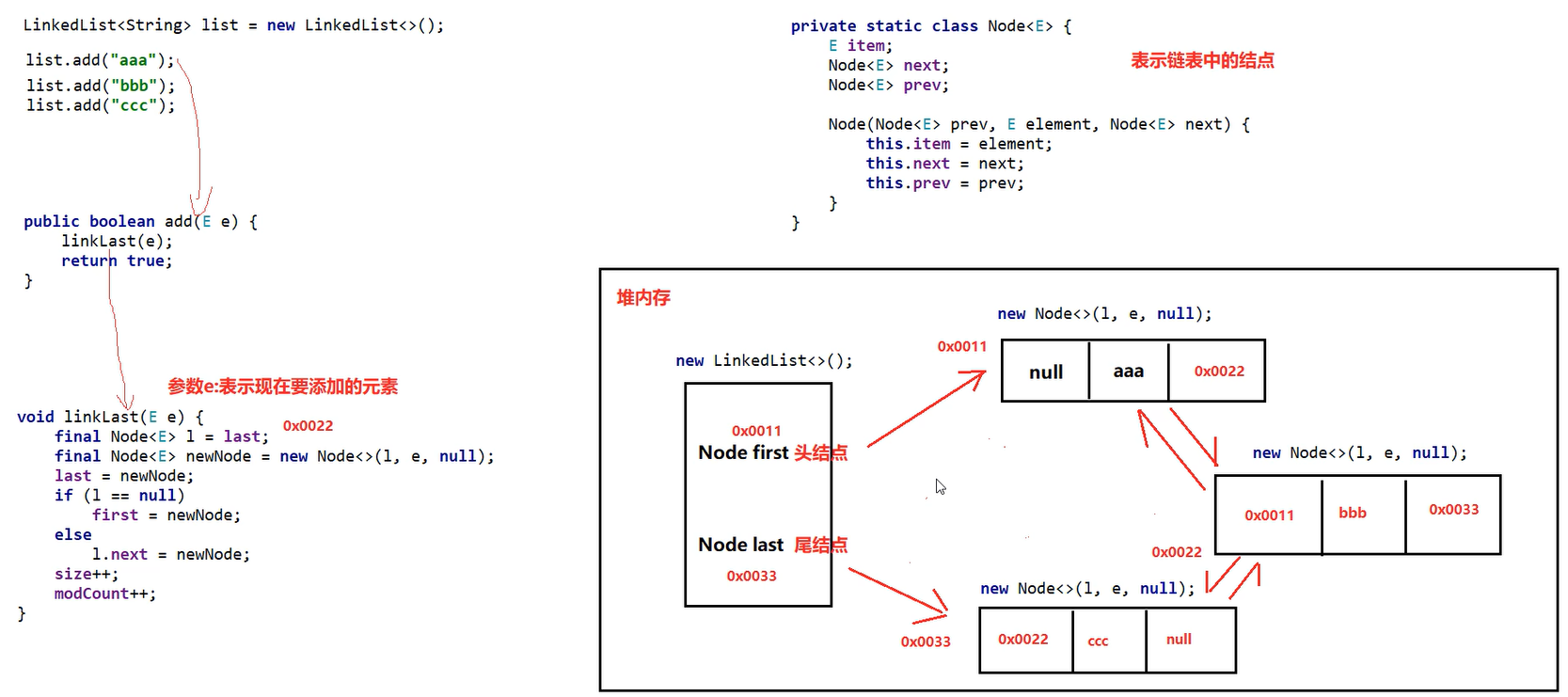
LinkedList<String> list = new LinkedList<>();
list.add("B");
list.add("C");
list.addFirst("A"); // 插入到开头
System.out.println(list); // [A, B, C]
(2)public void addLast(E e)
👉 在链表 末尾 插入元素。
其实和普通的 add(e) 效果一样。
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
list.addLast("C"); // 插入到末尾
System.out.println(list); // [A, B, C]
(3)public E getFirst()
👉 获取链表的 第一个元素,但不删除。
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
System.out.println(list.getFirst()); // A
System.out.println(list); // [A, B]
⚠️ 注意:如果链表为空,会抛 NoSuchElementException 异常。
(4)public E getLast()
👉 获取链表的 最后一个元素,但不删除。
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
System.out.println(list.getLast()); // B
⚠️ 同样,如果链表为空,也会抛异常。
(5)public E removeFirst()
👉 删除并返回链表的 第一个元素。
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
list.add("C");
System.out.println(list.removeFirst()); // A
System.out.println(list); // [B, C]
(6)public E removeLast()
👉 删除并返回链表的 最后一个元素。
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
list.add("C");
System.out.println(list.removeLast()); // C
System.out.println(list); // [A, B]
3. 使用场景总结
-
首尾频繁操作 → 用
LinkedList- 例子:实现 队列(FIFO),用
addLast()入队,removeFirst()出队。 - 例子:实现 栈(LIFO),用
addFirst()压栈,removeFirst()出栈。
- 例子:实现 队列(FIFO),用
-
需要快速随机访问 → 用
ArrayList。
4.源码分析
迭代器源码分析
1. 为什么要有迭代器?
- 如果你直接用
for下标访问LinkedList,效率很差,因为LinkedList查找第 k 个元素要从头或尾遍历。 - 所以
LinkedList提供了 迭代器(Iterator和ListIterator),它内部维护了一个 指针(cursor),顺着链表走,效率更高。 - 换句话说,迭代器是专门为 顺序遍历链表 优化的工具。
2. 迭代器种类
-
Iterator(普通迭代器)
- 可以
next()往后走。 - 可以
remove()删除当前元素。
- 可以
-
ListIterator(列表迭代器)
- 在
Iterator基础上加强,可以 双向移动(next()/previous())。 - 可以在遍历时 添加、修改元素。
- 在
LinkedList 内部迭代器实现类是:
private class Itr implements Iterator<E>private class ListItr extends Itr implements ListIterator<E>
3. Iterator 源码关键点
来看 JDK 源码: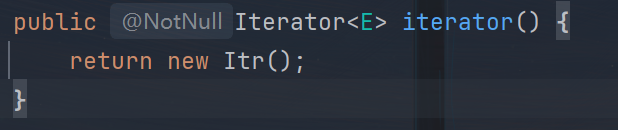
当调用iterator方法时,相当于创建了一个对象。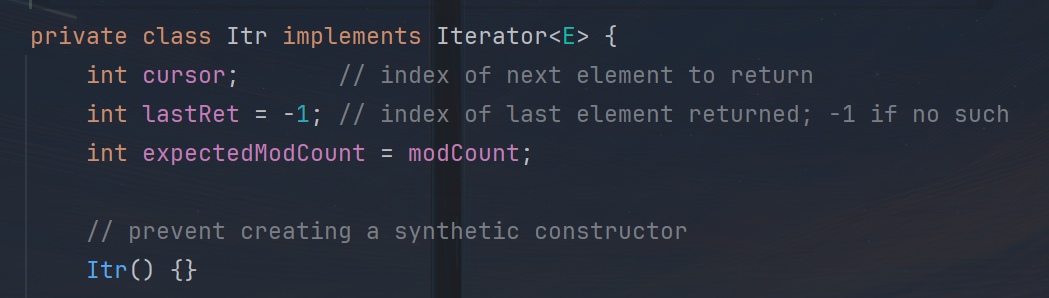
而Itr就是ArrayList的一个内部类,调用iterator方法相当于就是创建一个内部类。
内部类里面有三个参数cursor:代表就是迭代器里面的指针,迭代器刚创建出来的时候,指针是默认指向指向0的。lastRet:表示刚刚操作索引的位置,默认初始化为-1.expectedModCount:与并发修改异常相关的
这段代码是 ArrayList 的内部类 Itr(迭代器实现)中的 next() 方法,用于返回迭代器的下一个元素。我们来分析为什么需要两个 if 语句,而不是合并成一个,以及它们各自的作用。
代码背景
以下是 next() 方法的完整代码:
public E next() {
checkForComodification(); // 检查并发修改
int i = cursor; // 当前迭代器位置
if (i >= size) // 检查是否超出列表大小
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData; // 获取底层数组
if (i >= elementData.length) // 检查数组长度
throw new ConcurrentModificationException();
cursor = i + 1; // 更新迭代器位置
return (E) elementData[lastRet = i]; // 返回当前元素
}
为什么需要两个 if 语句?
两个 if 语句分别检查不同的条件,抛出不同的异常,用来处理两种不同的错误情况。合并成一个 if 语句在逻辑上不可行,因为它们的目的和异常类型不同。以下是详细分析:
1. 第一个 if 语句:if (i >= size)
- 作用:检查迭代器的当前位置
cursor是否超出了ArrayList的逻辑大小(size)。 size的含义:size是ArrayList中存储的元素数量(逻辑大小),不一定等于底层数组elementData的长度(物理大小)。- 例如,
ArrayList可能分配了一个长度为 10 的elementData数组,但只存储了 5 个元素(size = 5)。
- 例如,
- 异常:如果
i >= size,说明迭代器试图访问超出列表逻辑大小的元素,此时抛出NoSuchElementException。 - 语义:
NoSuchElementException表示“迭代器已经没有下一个元素了”,这是迭代器接口的标准行为(符合Iterator契约)。
2. 第二个 if 语句:if (i >= elementData.length)
- 作用:检查迭代器的当前位置
cursor是否超出了底层数组elementData的物理长度。 elementData.length的含义:elementData是ArrayList存储元素的底层数组,其长度可能大于或等于size(因为数组可能预分配了额外的空间)。- 异常:如果
i >= elementData.length,说明迭代器试图访问数组的非法索引,这通常是由于 并发修改(如在迭代过程中修改了ArrayList的结构)导致的。此时抛出ConcurrentModificationException。 - 语义:
ConcurrentModificationException表示ArrayList的结构在迭代过程中被意外修改(例如通过add、remove等方法改变了size或elementData),导致迭代器状态不一致。
3. 为什么不能合并成一个 if 语句?
合并两个 if 语句(例如 if (i >= size || i >= elementData.length))在逻辑上不可行,原因如下:
-
不同的异常类型:
NoSuchElementException表示迭代器正常遍历时已经到达列表末尾(合法但无元素)。ConcurrentModificationException表示迭代器检测到列表结构被非法修改(异常情况)。- 合并条件会导致无法区分这两种情况,抛出的异常会失去明确的语义,违反
Iterator接口的规范。
-
不同的检查目的:
- 第一个
if检查逻辑大小(size),确保迭代器不会访问超出有效元素范围的索引。 - 第二个
if检查物理数组长度(elementData.length),确保不会访问数组的非法索引(可能由于并发修改导致size和elementData不一致)。 - 这两个检查的触发条件和上下文不同:
i >= size通常在正常迭代结束时触发。i >= elementData.length通常在并发修改导致数组重新分配或大小不一致时触发。
- 第一个
-
并发修改检测的需要:
checkForComodification()方法(在next()开头调用)已经检查了modCount(修改计数)是否与预期一致,用于检测大多数并发修改情况。- 但某些极端情况下(如底层数组被重新分配或
size被非法修改),checkForComodification()可能不足以捕获所有问题。因此,第二个if作为额外的安全检查,确保不会访问无效的数组索引。
4. 可能的合并尝试及其问题
假设尝试合并为:
if (i >= size || i >= elementData.length) {
throw new NoSuchElementException(); // 或 throw new ConcurrentModificationException();
}
- 问题 1:无法区分两种异常情况,用户无法根据异常类型判断是“正常到达末尾”还是“并发修改错误”。
- 问题 2:如果抛出
NoSuchElementException,会掩盖并发修改的错误,误导开发者。 - 问题 3:如果抛出
ConcurrentModificationException,会在正常迭代结束时抛出错误的异常,违反Iterator接口的语义。
5. 实际场景分析
以下是一些场景,帮助理解两个 if 的必要性:
-
场景 1:正常迭代到达末尾
- 假设
size = 5,elementData.length = 10,cursor = 5。 - 第一个
if:i >= size为真,抛出NoSuchElementException,表示迭代器已无元素可返回。 - 第二个
if不会执行,因为第一个if已经终止了方法。 - 这是正常行为,符合
Iterator规范。
- 假设
-
场景 2:并发修改导致
size异常- 假设在迭代过程中,另一个线程调用
ArrayList.clear(),将size置为 0,但elementData数组未清空(仍为长度 10)。 checkForComodification()可能检测到modCount不一致,抛出ConcurrentModificationException。- 如果
checkForComodification()未捕获问题(例如某些非标准修改),第二个if(i >= elementData.length)作为最后一道防线,防止访问非法索引。
- 假设在迭代过程中,另一个线程调用
-
场景 3:底层数组被重新分配
- 假设在迭代过程中,
ArrayList执行了扩容操作(如add元素导致数组重新分配),elementData变更为新数组,长度可能变小或变大。 - 如果
cursor指向的索引在新数组中无效,第二个if会抛出ConcurrentModificationException,提示开发者检查并发修改。
- 假设在迭代过程中,
6. 总结
- 两个
if语句分别处理不同的错误场景:- 第一个
if(i >= size)处理正常迭代结束,抛出NoSuchElementException。 - 第二个
if(i >= elementData.length)处理并发修改导致的数组索引非法,抛出ConcurrentModificationException。
- 第一个
- 合并两个
if会导致异常语义不清,违反Iterator规范,且无法正确区分正常迭代结束和并发修改错误。 - 两个
if的设计是为了确保迭代器的健壮性,既满足接口规范,又能捕获异常情况。
原理总体讲解

4. ListIterator 额外功能
ListIterator 继承了 Iterator,还多了几个能力:
-
双向遍历:
hasPrevious()/previous()
-
修改功能:
set(E e)修改当前元素add(E e)在当前位置插入元素
源码里它主要是继承 Itr,然后多维护了一个方向上的指针和方法。
5. 总结
LinkedList的迭代器是专门为链表遍历设计的,效率比下标访问高。- Iterator:只能单向走 + 删除。
- ListIterator:能前后走 + 插入/修改。
- fail-fast 机制:在遍历时,如果外部修改集合,会抛
ConcurrentModificationException。
泛型深入
泛型概述
深入讲解
📌 没有泛型时,集合存储数据的情况
-
默认类型
- 如果不给集合指定类型,集合默认认为所有元素都是
Object。 ArrayList list = new ArrayList();
- 如果不给集合指定类型,集合默认认为所有元素都是
-
添加数据
- 可以往集合里放任何类型的数据(字符串、数字、自定义对象……)。
- 问题:集合里混合了不同类型的数据。
-
获取数据
- 取出来时只能得到
Object,如果要用子类的方法(如String.length()),必须强制类型转换。 - 如果类型不对,还会报
ClassCastException(类型转换异常)。
- 取出来时只能得到
👉 缺点:不安全、不方便。
📌 泛型出现后的改进
-
在创建集合对象时就指定类型:
ArrayList<String> list = new ArrayList<>();- 表示这个集合 只能存放 String 类型。
-
添加数据时:
- 非 String 类型会直接报编译错误,避免运行时出错。
list.add("aaa"); // ✅ list.add(123); // ❌ 编译报错 -
获取数据时:
- 返回的就是
String类型,不用再强制类型转换。 - 可以直接用
String的方法,例如str.length()。
Iterator<String> it = list.iterator(); while (it.hasNext()) { String str = it.next(); System.out.println(str.length()); // 直接调用 String 的方法 } - 返回的就是
📌 总结一句话
- 没有泛型时:集合元素统一当成
Object,能存任何类型,但取出要强转,容易出错。 - 有了泛型后:在添加数据时就统一了类型,编译期就能检查类型安全,取出时不用强转,代码更简洁。

拓展知识点

Java 中的泛型是“伪泛型”,这是一个非常重要的知识点。我们可以一步步来理解。
1. 什么叫伪泛型?
- 在 Java 中,泛型只在编译阶段有效。
- 编译器在编译时会进行类型检查和类型推断,确保泛型使用安全。
- 但是运行时,泛型信息会被擦除(Type Erasure),也就是说 JVM 根本不知道你用了泛型。
所以称为 “伪泛型”:
👉 编译时有泛型,运行时没有泛型。
2. 泛型擦除的过程
举个例子:
List<String> list1 = new ArrayList<>();
list1.add("hello");
List<Integer> list2 = new ArrayList<>();
list2.add(123);
在 编译后(字节码层面),泛型信息会被擦除,两者其实是一样的:
List list1 = new ArrayList(); // 实际上就是这样
List list2 = new ArrayList(); // 这也是这样
运行时 JVM 并不知道 list1 是 String 类型,list2 是 Integer 类型,它们的字节码类型完全一样。
3. 伪泛型的现象(典型例子)
① 运行时无法区分泛型类型
List<String> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>();
System.out.println(list1.getClass() == list2.getClass());
输出结果:
true
👉 说明在 JVM 里,List<String> 和 List<Integer> 没有区别。
② 不能创建泛型数组
List<String>[] arr = new ArrayList<String>[10]; // ❌ 编译报错
因为运行时没有泛型类型信息,JVM 不知道该如何真正分配数组。
③ 通过反射可以“作弊”
List<String> list = new ArrayList<>();
list.add("hello");
Method add = list.getClass().getMethod("add", Object.class);
add.invoke(list, 123); // 用反射加进去一个 Integer
System.out.println(list);
输出结果:
[hello, 123]
👉 明明是 List<String>,却能加 Integer,这就是泛型擦除的结果。
4. 为什么 Java 要设计伪泛型?
-
向下兼容:
Java 在 JDK 1.5 才引入泛型,设计成擦除式泛型,能兼容以前的老版本字节码。
比如 JDK1.4 写的ArrayList,到 JDK1.5 以后依然能用。 -
实现简单:
泛型只在编译时起作用,JVM 不需要改动运行时结构,减少了复杂性。
📌 总结
- Java 泛型是伪泛型,因为运行时泛型信息被擦除。
- 编译期:泛型保证类型安全,帮你检查和推断。
- 运行期:泛型被擦除,所有泛型类都当作原始类型(
Raw Type)处理。
泛型的细节
这三个点,都是 Java 泛型中的关键细节,我来逐一给你讲解清楚:
1. 泛型中不能写基本数据类型
-
泛型只能接受 引用类型,不能直接使用基本数据类型(
int、double、char...)。 -
比如:
List<int> list = new ArrayList<>(); // ❌ 编译报错
👉 原因:
- 泛型在编译后会进行 类型擦除,统一转为
Object处理。 - 但是
Object不能存储基本数据类型,只能存储引用类型。
👉 解决办法:
-
使用 包装类(Java 提供的基本类型包装类):
int → Integerdouble → Doublechar → Characterboolean → Boolean
示例:
List<Integer> list = new ArrayList<>(); // ✅ list.add(10); // 自动装箱:int → Integer
2. 指定泛型的具体类型后,可以传入该类或其子类
- 泛型定义时写的是一个“父类”,在添加元素时,不仅可以放父类,还能放 子类对象。
示例:
List<Number> list = new ArrayList<>();
list.add(10); // int → Integer → Number
list.add(3.14); // double → Double → Number
list.add(new Integer(20)); // Integer 是 Number 的子类
👉 这里 Number 是父类,Integer 和 Double 都是它的子类,所以都能放进去。
⚠️ 注意:
泛型类型一旦固定,就不能传其他不相关的类型。例如:
List<Integer> list = new ArrayList<>();
list.add(10); // ✅
list.add(3.14); // ❌ Double 不是 Integer
3. 如果不写泛型,类型默认是 Object
-
如果创建集合时没有指定泛型,那么默认是原始类型(Raw Type),集合里可以放任何对象:
ArrayList list = new ArrayList(); // 没有泛型,默认 Object list.add("abc"); list.add(123); list.add(3.14);
👉 问题:
-
读取时会失去类型信息,只能作为
Object取出,还需要强制类型转换:Object obj = list.get(0); // 取出来是 Object String str = (String) obj; // 需要强转 -
如果类型不匹配,就会抛出 ClassCastException:
String str = (String) list.get(1); // ❌ 运行时报错,不能把 Integer 转成 String
👉 所以:
使用泛型的目的是 在编译阶段就限制集合里的类型,避免运行时错误。
📌 总结
- 泛型不能用基本类型 → 因为泛型在运行时会擦除成
Object,只能用包装类。 - 泛型固定后可传子类 → 如果泛型是父类,那么集合能装父类或子类对象。
- 不写泛型默认
Object→ 灵活但不安全,取数据必须强转,容易抛异常。
写泛型

1. 使用场景
-
什么时候需要泛型类?
当一个类中的某个变量或方法的数据类型 不确定,但你希望在使用类时再指定类型,就可以使用泛型。 -
典型场景:
- 集合类(
ArrayList<E>、HashMap<K,V>) - 工具类(例如
Box<T>用于包装任意对象) - 数据处理类(如存储不同类型数据的容器)
- 集合类(
2. 泛型类的格式
修饰符 class 类名<类型占位符> {
// 成员变量、方法可以使用泛型类型
}
- 例如:
public class ArrayList<E> {
// E 表示元素类型,只有在创建对象时确定
private E[] elements;
public void add(E e) { /* 添加元素 */ }
public E get(int index) { return elements[index]; }
}
解释:
<E>是 类型占位符(placeholder),不是用来存储数据的,而是用来 记录数据类型。- 在创建对象时,才会确定
E的实际类型:
ArrayList<String> list = new ArrayList<>(); // 此时 E 就是 String
ArrayList<Integer> list2 = new ArrayList<>(); // 此时 E 就是 Integer
3. 常用的泛型占位符
E→ Element(集合元素)T→ Type(通用类型)K→ Key(键)V→ Value(值)- 可以根据实际语义选择占位符,但不影响功能,只是方便理解:
public class Box<T> {
private T value;
public void set(T value) { this.value = value; }
public T get() { return value; }
}
- 创建对象时:
Box<String> strBox = new Box<>();
strBox.set("Hello");
String val = strBox.get(); // 不需要强转
总结
-
泛型类解决了 类中数据类型不确定的问题。
-
<E/T/K/V>是类型占位符,用于在编译期保证类型安全。 -
创建对象时,泛型类型才被确定,成员变量和方法才能使用这个具体类型。
-
泛型类的好处:
- 类型安全:添加元素时保证类型一致
- 省去强制类型转换
- 提高代码复用性和可读性
4. 泛型类(Generic Class)
定义
- 当一个类中某些成员变量或方法的数据类型不确定时,可以使用泛型类。
- 泛型在类定义时用 占位符 表示,创建对象时再指定具体类型。
语法
修饰符 class 类名<类型占位符> {
private 类型占位符 value;
public void set(类型占位符 value) { this.value = value; }
public 类型占位符 get() { return value; }
}
示例
public class Box<T> {
private T value;
public void set(T value) { this.value = value; }
public T get() { return value; }
}
public class Test {
public static void main(String[] args) {
Box<String> strBox = new Box<>();
strBox.set("Hello");
String s = strBox.get(); // 不需要强转
Box<Integer> intBox = new Box<>();
intBox.set(123);
Integer n = intBox.get();
}
}
特点:
- 泛型在类定义时不确定,创建对象时确定类型。
- 占位符常用:
T(Type)、E(Element)、K(Key)、V(Value)。
5. 泛型方法(Generic Method)

定义
- 泛型方法不依赖于类的泛型类型,即使类不是泛型类,也可以定义泛型方法。
- 泛型方法的类型在方法调用时确定。
语法
修饰符 <类型占位符> 返回类型 方法名(类型占位符 参数) {
// 方法体
}
示例
public class Utils {
// 泛型方法
public static <T> void printArray(T[] arr) {
for (T t : arr) {
System.out.println(t);
}
}
}
public class Test {
public static void main(String[] args) {
Integer[] nums = {1, 2, 3};
String[] strs = {"A", "B", "C"};
Utils.printArray(nums); // 调用时确定 T 为 Integer
Utils.printArray(strs); // 调用时确定 T 为 String
}
}
特点:
- 泛型方法在方法定义时用
<T>指定泛型类型。 - 可以定义在普通类或泛型类中。
- 泛型类型在调用时确定,支持多种数据类型复用同一方法。
6. 泛型接口(Generic Interface)

定义
- 接口也可以定义泛型类型,这样不同实现类可以指定不同类型。
语法
interface 接口名<类型占位符> {
void method(类型占位符 param);
}
示例
// 泛型接口
interface Info<T> {
void show(T t);
}
// 实现类1
class StringInfo implements Info<String> {
public void show(String t) {
System.out.println("字符串信息:" + t);
}
}
// 实现类2
class IntegerInfo implements Info<Integer> {
public void show(Integer t) {
System.out.println("整数信息:" + t);
}
}
public class Test {
public static void main(String[] args) {
Info<String> info1 = new StringInfo();
info1.show("Hello");
Info<Integer> info2 = new IntegerInfo();
info2.show(123);
}
}
1️⃣ 实现类给出具体类型
说明
- 接口定义了泛型
<T> - 实现类直接指定具体类型,接口的泛型就固定了
- 对象创建时不再指定泛型类型
示例代码
// 泛型接口
interface Info<T> {
void show(T t);
}
// 实现类给出具体类型 String
class StringInfo implements Info<String> {
@Override
public void show(String t) {
System.out.println("字符串信息:" + t);
}
}
public class Test1 {
public static void main(String[] args) {
StringInfo info = new StringInfo();
info.show("Hello World"); // 输出:字符串信息:Hello World
}
}
✅ 特点:
- 泛型在实现类时就确定了
- 创建对象时不用再指定泛型
2️⃣ 实现类延续泛型,创建对象时再确定类型
说明
- 接口定义了泛型
<T> - 实现类仍然使用泛型
<T>,不指定具体类型 - 对象创建时才确定泛型类型
示例代码
// 泛型接口
interface Info<T> {
void show(T t);
}
// 实现类延续泛型
class GenericInfo<T> implements Info<T> {
@Override
public void show(T t) {
System.out.println("信息:" + t);
}
}
public class Test2 {
public static void main(String[] args) {
// 创建对象时确定泛型类型为 String
Info<String> info1 = new GenericInfo<>();
info1.show("Hello");
// 创建对象时确定泛型类型为 Integer
Info<Integer> info2 = new GenericInfo<>();
info2.show(123);
}
}
✅ 特点:
- 实现类保持泛型灵活性
- 可以创建不同类型的对象,复用性高
总结对比
| 使用方式 | 泛型确定时机 | 创建对象时是否指定类型 | 示例 |
|---|---|---|---|
| 实现类给出具体类型 | 实现类定义时 | 不用指定 | class StringInfo implements Info<String> |
| 实现类延续泛型 | 创建对象时 | 需要指定 | Info<String> info = new GenericInfo<>(); |
特点:
- 接口定义泛型,使用者可以指定具体类型。
- 实现类可以选择使用同样的类型,或者继续保留泛型。
- 常用于集合、工具类、框架设计。
7. 总结对比
| 类型 | 泛型位置 | 使用时机 | 例子 |
|---|---|---|---|
| 泛型类 | 类名后 <T> |
当类内部成员或方法类型不确定 | class Box<T> { ... } |
| 泛型方法 | 方法前 <T> |
方法内部需要使用不确定类型 | <T> void print(T[] arr) |
| 泛型接口 | 接口名后 <T> |
不同实现类类型可不一样 | interface Info<T> { ... } |
💡 总结一句话:
- 泛型类 → 整个类都可以复用类型。
- 泛型方法 → 单个方法可以复用类型,不依赖类。
- 泛型接口 → 不同实现类可以指定不同类型,实现高度灵活性。
泛型的继承和通配符
我们来深入讲解 Java 泛型的继承和通配符,这是泛型里非常重要、但也最容易混淆的部分。
一、泛型的继承问题
在 Java 中,类之间有继承关系 ≠ 泛型之间也有继承关系。
👉 例如:
class Animal {}
class Dog extends Animal {}
List<Animal> list1 = new ArrayList<Animal>();
List<Dog> list2 = new ArrayList<Dog>();
// ❌ 不能这样写
// list1 = list2;
⚠️ 原因:List<Dog> 不是 List<Animal> 的子类。
这样设计是为了保证类型安全:
- 如果
List<Dog>能赋值给List<Animal>,那么就可能往里面添加Cat,破坏了集合的元素一致性。
泛型不具备继承性,但数据具备继承性
1. 泛型不具备继承性
意思是:
即使 类之间有继承关系,对应的泛型类之间也 没有继承关系。
👉 举例:
class Animal {}
class Dog extends Animal {}
List<Animal> list1 = new ArrayList<>();
List<Dog> list2 = new ArrayList<>();
// ❌ 错误:即使 Dog 是 Animal 的子类,List<Dog> 也不是 List<Animal> 的子类
list1 = list2;
⚠️ 为什么?
因为如果 List<Dog> 能赋值给 List<Animal>,那么别人就可以往里面加 Cat(Animal 的另一个子类),这就破坏了集合类型安全。
2. 数据具备继承性
虽然泛型本身没有继承关系,但放在泛型里的数据对象是有继承关系的。
👉 举例:
List<Animal> animals = new ArrayList<>();
animals.add(new Animal()); // ✅
animals.add(new Dog()); // ✅ Dog 是 Animal 的子类
⚠️ 注意:
这里集合的类型是 List<Animal>,所以只能保证存放的是 Animal 或它的子类对象。
当我们取数据时:
Animal a = animals.get(0); // ✅ 取出来至少是 Animal
就可以正常使用父类的方法,多态依旧有效。
3. 用一句话总结
- 泛型类之间没有继承关系:
List<Dog>≠List<Animal>。 - 泛型里的元素对象有继承关系:如果集合类型是
List<Animal>,就能存放Animal和其子类,比如Dog。
✅ 举个类比(方便记忆):
- 泛型容器(List<…>)就像不同型号的盒子:
List<Animal>和List<Dog>是两种不同的盒子,不能直接替换。 - 盒子里装的物品(对象)是有继承关系的:
Dog可以放进装Animal的盒子里。
要不要我给你做一个 图解(盒子+物品的图),让你更直观地理解“泛型不继承 vs 数据继承”?
二、通配符的引入(?)
当我们需要在 方法参数 中处理多种泛型类型时,就用到通配符。
其实使用泛型方法也可以,但是利用泛型方法有一个小弊端,此时它可以接受任意类型的数据类型,本方法虽然希望不确定类型,但是以后我希望只能传递ye,fu,zi类型,此时就可以用到通配符。
1️⃣ 无界通配符:<?>
- 表示 任意类型,谁都可以传。
- 但是 不能往里加元素(除了
null)。 - 典型应用:只读,不写。
public static void printList(List<?> list) {
for (Object obj : list) {
System.out.println(obj);
}
}
public static void main(String[] args) {
List<String> list1 = List.of("A", "B", "C");
List<Integer> list2 = List.of(1, 2, 3);
printList(list1); // OK
printList(list2); // OK
}
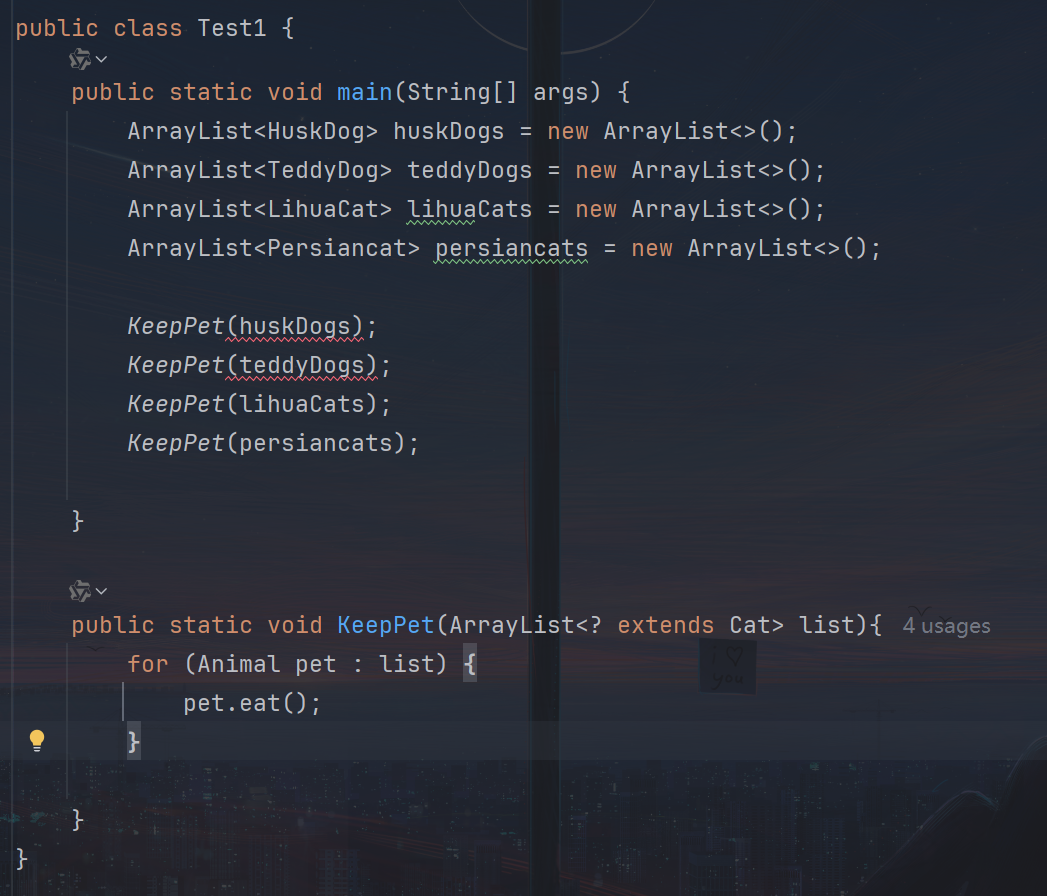
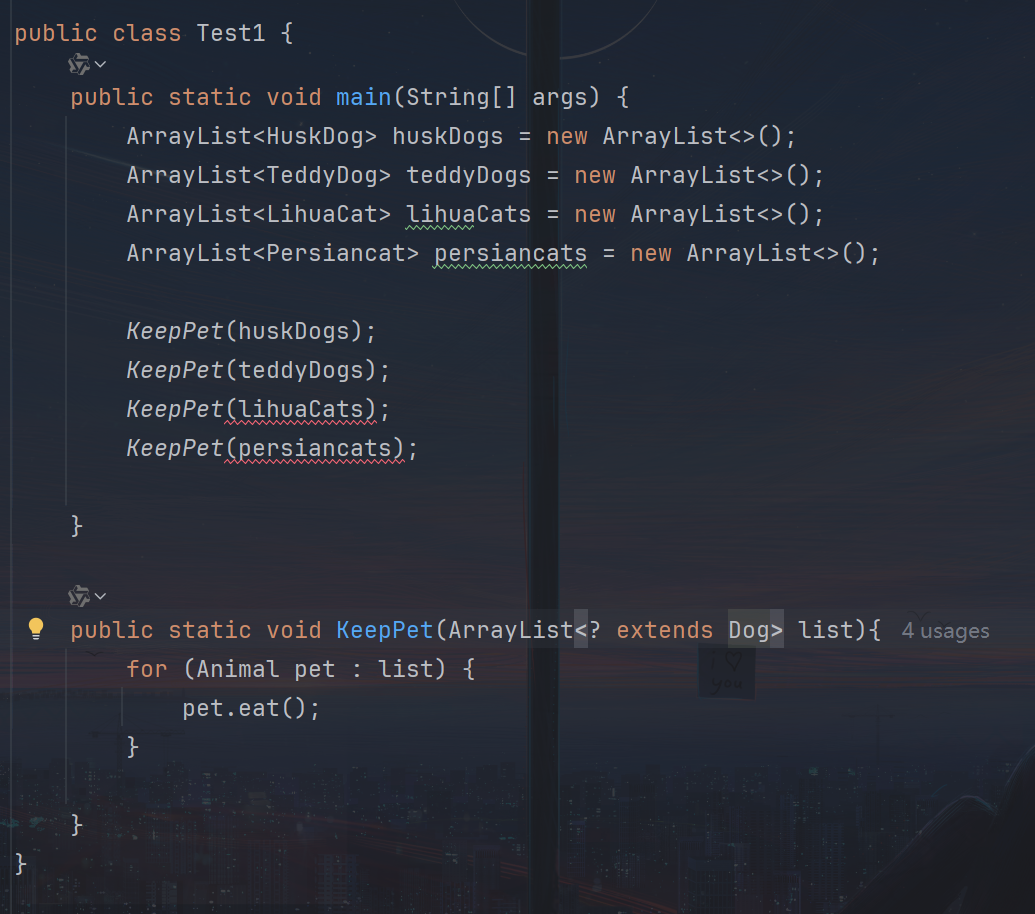
2️⃣ 上限通配符:<? extends T>
- 表示:该集合元素类型是 T 或 T 的子类。
- 常用于:读取数据。
- 限制:不能添加元素(除了 null),因为编译器不确定具体子类型。
public static void showAnimals(List<? extends Animal> list) {
for (Animal a : list) {
System.out.println(a);
}
}
调用:
List<Dog> dogs = new ArrayList<>();
List<Animal> animals = new ArrayList<>();
showAnimals(dogs); // ✅ OK
showAnimals(animals); // ✅ OK
3️⃣ 下限通配符:<? super T>
- 表示:该集合元素类型是 T 或 T 的父类。
- 常用于:写入数据。
public static void addDogs(List<? super Dog> list) {
list.add(new Dog()); // ✅ 可以安全添加 Dog
}
调用:
List<Dog> dogs = new ArrayList<>();
List<Animal> animals = new ArrayList<>();
List<Object> objects = new ArrayList<>();
addDogs(dogs); // ✅ OK
addDogs(animals); // ✅ OK
addDogs(objects); // ✅ OK
但是取元素时,只能取成 Object:
Object obj = list.get(0);
三、口诀总结
| 通配符 | 范围 | 能不能添加? | 能不能读取? | 典型用途 |
|---|---|---|---|---|
<?> |
任意类型 | ❌(只能加 null) |
✅(读出来是 Object) |
只读 |
<? extends T> |
T 及其子类 | ❌(不能添加) | ✅(读出来是 T) | 生产者(读取数据) |
<? super T> |
T 及其父类 | ✅(可以添加 T 或子类) | ❌(只能取成 Object) | 消费者(写入数据) |
📌 口诀:
👉 PECS 原则:Producer Extends, Consumer Super
- 如果你需要生产数据(只读),用
extends - 如果你需要消费数据(写入),用
super
四、不使用PECS原则会怎样?
一、先复习一下 PECS 原则
-
Producer Extends:如果集合是数据的“生产者”,要用
<? extends T>。
👉 只能读取元素(向外提供数据),不能添加。 -
Consumer Super:如果集合是数据的“消费者”,要用
<? super T>。
👉 可以往里面写入元素,但取出来时只能作为Object使用。
📌 口诀:读用 extends,写用 super。
二、不遵守原则会怎么样?
1️⃣ 不用 extends 的后果
👉 情景:方法只需要“读取”集合里的元素。
public void showAnimals(List<Animal> list) {
for (Animal a : list) {
System.out.println(a);
}
}
List<Dog> dogs = new ArrayList<>();
// showAnimals(dogs); // ❌ 报错:List<Dog> 不是 List<Animal>
⚠️ 问题:
- 如果你不用
<? extends Animal>,就没办法传List<Dog>,限制了方法的适用性。 - 这时编译器会报错(类型不匹配),所以程序员必须修改方法签名。
✅ 正确写法:
public void showAnimals(List<? extends Animal> list) {
for (Animal a : list) {
System.out.println(a);
}
}
2️⃣ 不用 super 的后果
👉 情景:方法只需要“往集合里写入数据”。
public void addDogs(List<Animal> list) {
list.add(new Dog());
}
List<Object> objs = new ArrayList<>();
// addDogs(objs); // ❌ 报错:List<Object> 不是 List<Animal>
⚠️ 问题:
List<Object>明明也能装Dog,但是因为你没写<? super Dog>,就无法传进来。- 这样 失去了向上兼容性。
✅ 正确写法:
public void addDogs(List<? super Dog> list) {
list.add(new Dog());
}
3️⃣ 运行时可能出问题
即使你强行用原始类型绕过泛型检查,运行时也可能炸掉:
List list = new ArrayList<Dog>();
list.add(new Cat()); // ❌ 编译警告,但能运行
Dog d = (Dog) list.get(0); // ❌ 运行时报 ClassCastException
如果遵守 PECS,用 extends/super 限定,就能避免这种情况。
三、总结
🚨 不遵守 PECS 原则的后果:
- 编译时报错 → 方法签名过于死板,不能接受父类/子类集合。
- 失去灵活性 → 本来能传
List<Dog>或List<Object>的,却被拒之门外。 - 可能引发运行时异常 → 如果用原始类型强行绕过,容易出现
ClassCastException。
📌 一句话总结:
PECS 原则不是编译器强制要求的规则,但它是最佳实践。
- 如果不用,编译器就会限制你(报错或不兼容)。
- 如果强行绕过(用原始类型),编译器虽然不报错,但运行时可能出错。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)