Jina Embeddings v4: 多模态多语言检索的通用向量
JinaEmbeddings v4是Jina AI最新发布的38亿参数多模态向量模型,支持文本和图像嵌入。该模型基于Qwen2.5-VL-3B-Instruct主干,采用任务专用LoRA适配器优化检索性能,支持单向量(2048维)和多向量(每个token 128维)输出。在MTEB、MMTEB等基准测试中,v4在多语言检索上比OpenAI text-embedding-3-large高12%,长文
作者:Elastic JINA.ai

Jina Embeddings v4 是一个 38 亿参数的通用向量模型,用于多模态多语言检索,支持单向量和多向量输出。
今天(2025年6月25日)我们发布了 jina-embeddings-v4,这是我们新的 38 亿参数通用向量模型,用于文本和图像。它包含一组任务专用的 LoRA 适配器,可优化最流行的检索任务性能,包括查询-文档检索、语义匹配和代码搜索。jina-embeddings-v4 在 MTEB、MMTEB、CoIR、LongEmbed、STS、Jina-VDR、CLIP 和 ViDoRe 基准的多模态多语言任务中实现了最先进的检索性能,尤其擅长处理视觉丰富的内容,如表格、图表、示意图及其组合。该模型支持单向量和多向量嵌入。
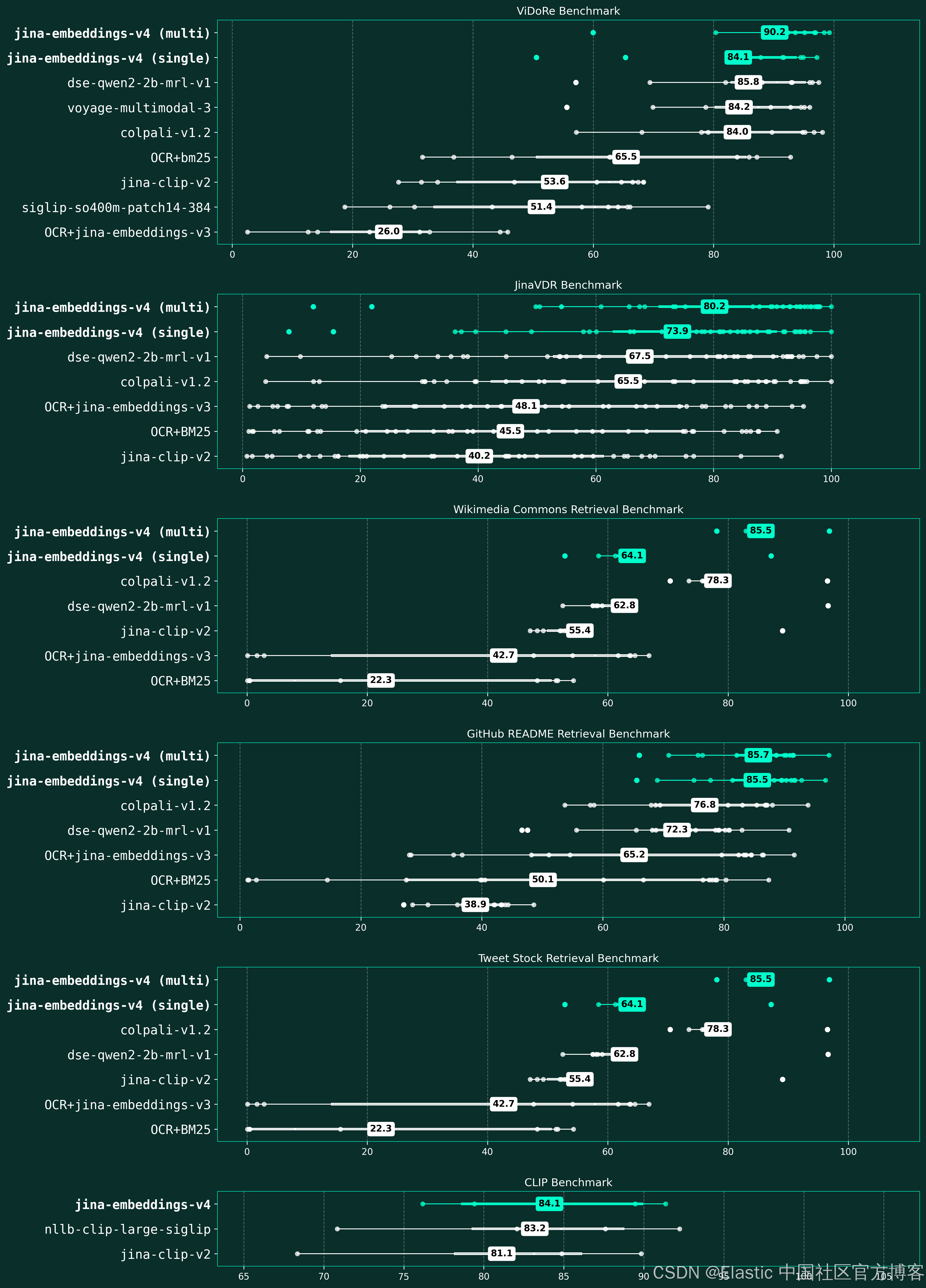
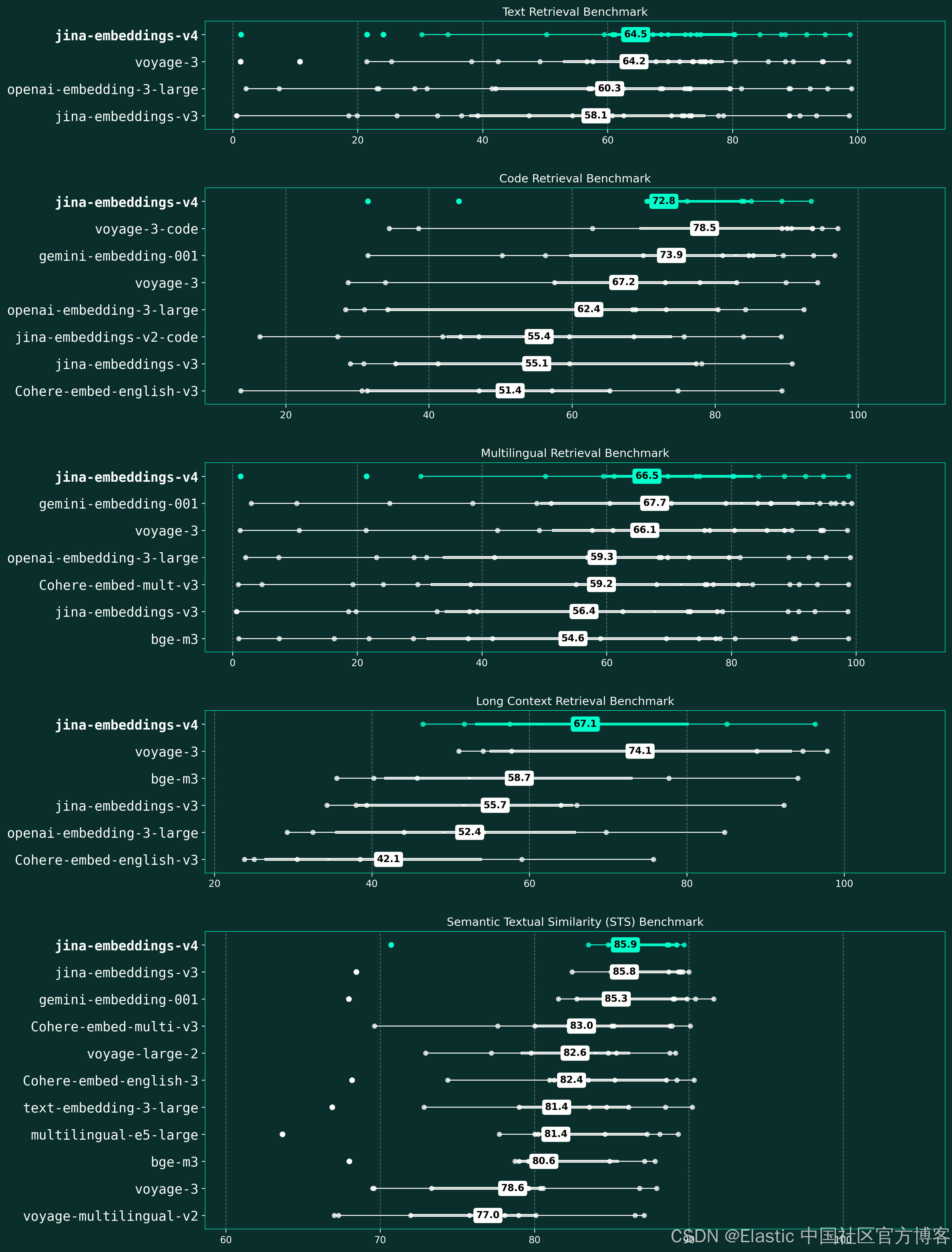
jina-embeddings-v4 是我们迄今为止最雄心勃勃的向量模型。作为开源模型,jina-embeddings-v4 超越了主要厂商的领先闭源向量模型,在多语言检索上比 OpenAI 的 text-embedding-3-large 性能高 12%(66.49 对 59.27)、在长文档任务上提升 28%(67.11 对 52.42)、在代码检索上比 voyage-3 高 15%(71.59 对 67.23),并与 Google 的 gemini-embedding-001 表现相当。这使得 v4 成为目前最强大的开源通用向量模型,为研究人员和开发者提供企业级多模态向量能力,并通过我们全面的技术报告,对训练过程、架构决策和模型权重实现完全透明。
新架构
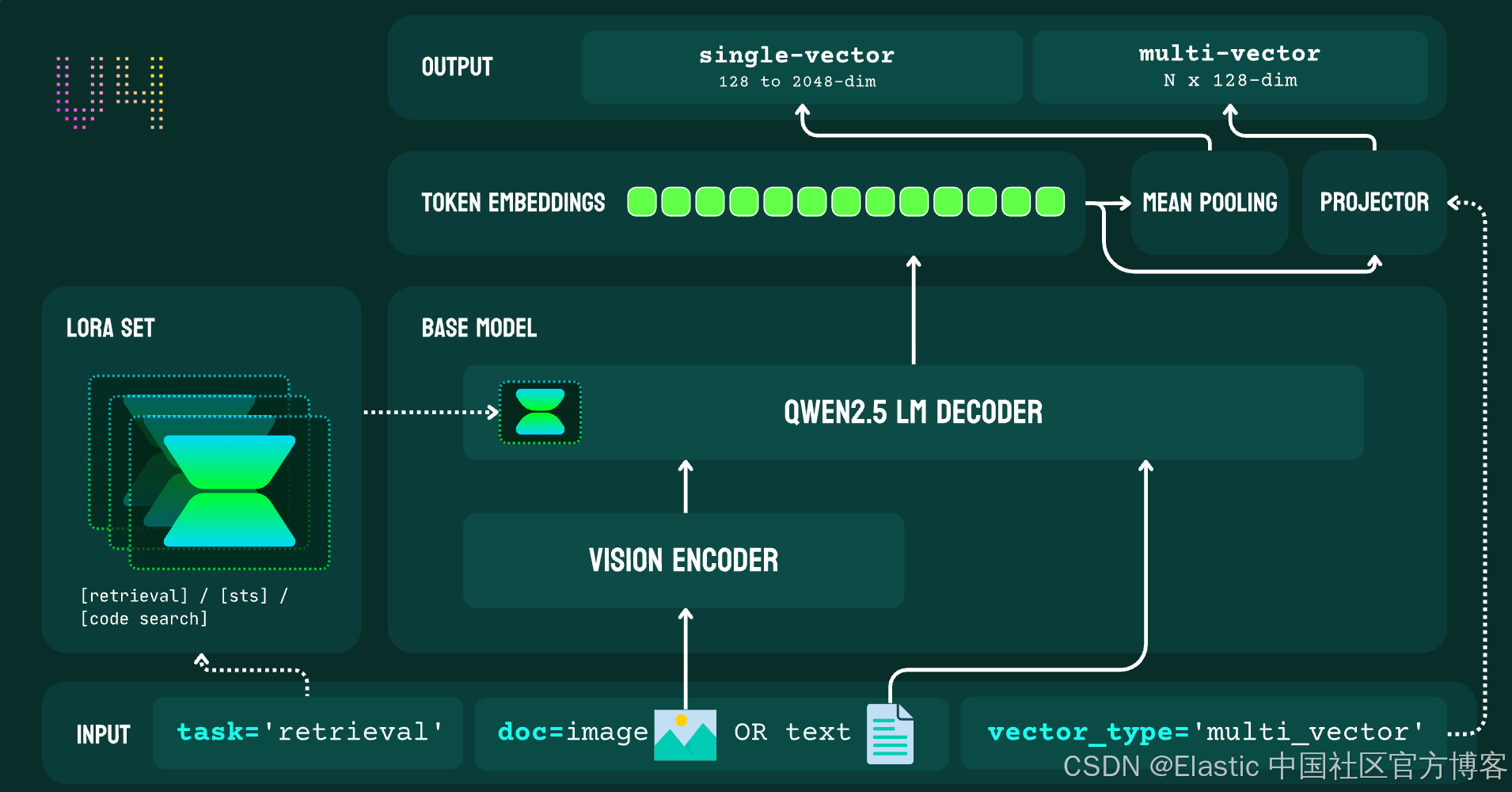
从jina-embeddings-v3 升级到 jina-embeddings-v4 代表了从仅文本向量到多模态向量的范式转变。v3 专注于通过任务专用的 LoRA 适配器来优化文本向量,而 v4 则满足了将文本内容和视觉内容统一嵌入到同一表示中的日益增长需求。
| 方面 | jina-embeddings-v3 | jina-embeddings-v4 |
|---|---|---|
| 主干模型 | jina-XLM-RoBERTa | Qwen2.5-VL-3B-Instruct |
| 参数量(基础) | 559M | 3.8B |
| 参数量(含适配器) | 572M | 3.8B + 每个适配器 60M |
| 模态 | 仅文本 | 文本 + 图像(多模态) |
| 最大输入长度 | 8,192 tokens | 32,768 tokens |
| 图像处理 | 无 | 最高 2000 万像素,支持视觉内容丰富的文档 |
| 多语言支持 | 89 种语言 | 29+ 种语言 |
| 向量类型 | 仅单向量 | 单向量 + 多向量(延迟交互) |
| 单向量维度 | 1024( MRL 可截断到 32) | 2048( MRL 可截断到 128) |
| 多向量维度 | 不支持 | 每个 token 128 |
| 任务 LoRA 专用 |
• 非对称检索 • 语义相似度 • 分类 • 分离 |
• 非对称检索 • 语义相似度 • 代码检索 |
| 训练阶段 | 3 阶段:预训练 → 向量微调 → 适配器训练 | 2 阶段:联合成对训练 → 任务专用适配器训练 |
| 损失函数 | InfoNCE、 CoSent、扩展三元组损失 | 用于单向量 / 多向量的联合 InfoNCE + KL divergence |
| 位置编码 | RoPE(旋转基频调优) | M-RoPE(多模态旋转位置嵌入) |
| 跨模态处理 | 不适用 | 统一编码器(减少模态差距) |
| MRL 支持 | 是 | 是 |
| 注意力实现 | FlashAttention2 | FlashAttention2 |
主干模型(Backbone)
v4 中最重要的架构变化是主干模型从 XLM-RoBERTa 切换到 Qwen2.5-VL-3B-Instruct。这个决定源于 v4 的核心目标:打造一个通用向量模型,实现“真正的多模态处理”,即将图像转换为 token 序列,并与文本一起处理,从而消除双编码器架构中存在的模态差距。
主干模型的选择与多个关键设计目标一致:Qwen2.5-VL 在文档理解方面的优势,直接支持 v4 在处理表格、图表、截图等视觉内容丰富内容时的强项。其动态分辨率能力使 v4 能够处理按架构说明调整到最多 2000 万像素的图像。先进的位置编码为 v4 提供了基础,使其在跨模态对齐方面取得更优表现,对齐分数达到 0.71,而 OpenAI CLIP 为 0.15。
LoRA 适配器(LoRA Adapters)
v4 将 v3 中的五类任务精简为三类重点任务,反映了在效果和用户采用方面总结的经验:
- 非对称检索(整合了 v3 的 query / passage 适配器)
- 对称相似度(v3 中用于 STS 任务的文本匹配等价方案)
- 代码检索(源自 v2-code 的经验,在 v3 中缺失)
这种整合移除了 v3 中的分类(classification)和分离(separation)适配器,使 v4 专注于最具影响力的向量使用场景 —— 检索和 STS。
输出向量(Output Embeddings)
v4 引入了双输出系统,支持单向量和多向量嵌入,而 v3 仅提供单向量输出。这满足了不同的检索场景:
- 单向量模式:2048 维嵌入(可通过 MRL 截断到 128),用于高效相似度搜索
- 多向量模式:每个 token 128 维,用于延迟交互检索(late-interaction retrieval)
这种双模式方法在多向量表示下提供更高效能,尤其在视觉丰富的文档检索中表现突出,同时在标准相似度任务中保持高效。多向量模式在视觉任务中比单向量模式稳定高出 7-10% 的性能优势,表明延迟交互在多模态内容的语义匹配上具有根本性优势。
参数规模(Parameter Size)
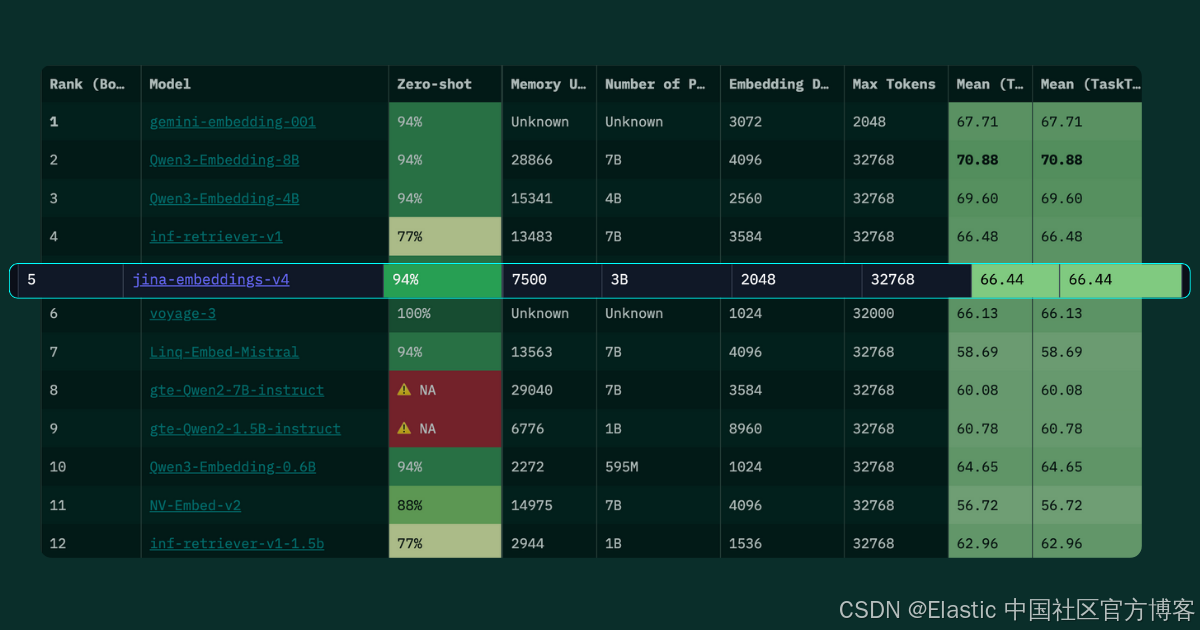
虽然 v4 的参数量比 v3 大 6.7 倍(3.8B 对 570M 参数),但仅文本性能提升其实有限,这表明参数扩展主要是为了满足多模态需求,而非文本增强。在核心文本基准上,v4 在 MMTEB 上得分 66.49,而 v3 为 58.58(提升 14%);在 MTEB-EN 上得分 55.97,而 v3 为 54.33(提升 3%)。在代码检索中,v4 在 CoIR 上得分 71.59,而 v3 为 55.07(提升 30%);长文档任务中,v4 在 LongEmbed 上得分 67.11,而 v3 为 55.66(提升 21%)。
当考虑 v4 的多模态能力时,这种大幅扩展就显得合理:在视觉文档检索(Jina-VDR)上达到 84.11 nDCG@5,在 ViDoRe 基准上达到 90.17 —— 这是 v3 完全不具备的能力。因此,参数增加代表了我们在多模态功能上的投入,同时保持了竞争力的文本性能,统一架构消除了单独文本模型和视觉模型的需求,并实现了 0.71 的跨模态对齐,相比传统双编码器方法的 0.15 有显著提升。
快速上手(Getting Started)
为了快速体验,试试我们在 Search Foundation 工具箱中的文本到图像演示。我们准备了一系列来自官网的文档图像,你也可以添加自己的图像 URL。只需输入查询并按回车即可查看排序结果。你可以像 OCR 一样检索,或进行基于内容的图像检索 —— 也可以尝试非英文查询。
通过 API(Via API)
下面的代码展示了如何使用 jina-embeddings-v4。你可以传入文本字符串、base64 编码的图像,或图像 URL。
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer JINA_API_KEY" \
-d @- <<EOFEOF
{
"model": "jina-embeddings-v4",
"task": "text-matching",
"input": [
{
"text": "A beautiful sunset over the beach"
},
{
"text": "Un beau coucher de soleil sur la plage"
},
{
"text": "海滩上美丽的日落"
},
{
"text": "浜辺に沈む美しい夕日"
},
{
"image": "https://i.ibb.co/nQNGqL0/beach1.jpg"
},
{
"image": "https://i.ibb.co/r5w8hG8/beach2.jpg"
},
{
"image": "iVBORw0KGgoAAAANSUhEUgAAABwAAAA4CAIAAABhUg/jAAAAMklEQVR4nO3MQREAMAgAoLkoFreTiSzhy4MARGe9bX99lEqlUqlUKpVKpVKpVCqVHksHaBwCA2cPf0cAAAAASUVORK5CYII="
}
]
}
EOFEOF
我们在 terminal 中打入如下的命令:
export JINA_API_KEY=<Your JINA API Key>你可参考文章 “Jina-VLM:小型多语言视觉语言模型” 来查看如何获得 JINA API Key:
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $JINA_API_KEY" \
-d @- <<EOFEOF
{
"model": "jina-embeddings-v4",
"task": "text-matching",
"input": [
{
"text": "A beautiful sunset over the beach"
},
{
"text": "Un beau coucher de soleil sur la plage"
},
{
"text": "海滩上美丽的日落"
},
{
"text": "浜辺に沈む美しい夕日"
},
{
"image": "https://i.ibb.co/nQNGqL0/beach1.jpg"
},
{
"image": "https://i.ibb.co/r5w8hG8/beach2.jpg"
},
{
"image": "iVBORw0KGgoAAAANSUhEUgAAABwAAAA4CAIAAABhUg/jAAAAMklEQVR4nO3MQREAMAgAoLkoFreTiSzhy4MARGe9bX99lEqlUqlUKpVKpVKpVCqVHksHaBwCA2cPf0cAAAAASUVORK5CYII="
}
]
}
EOFEOF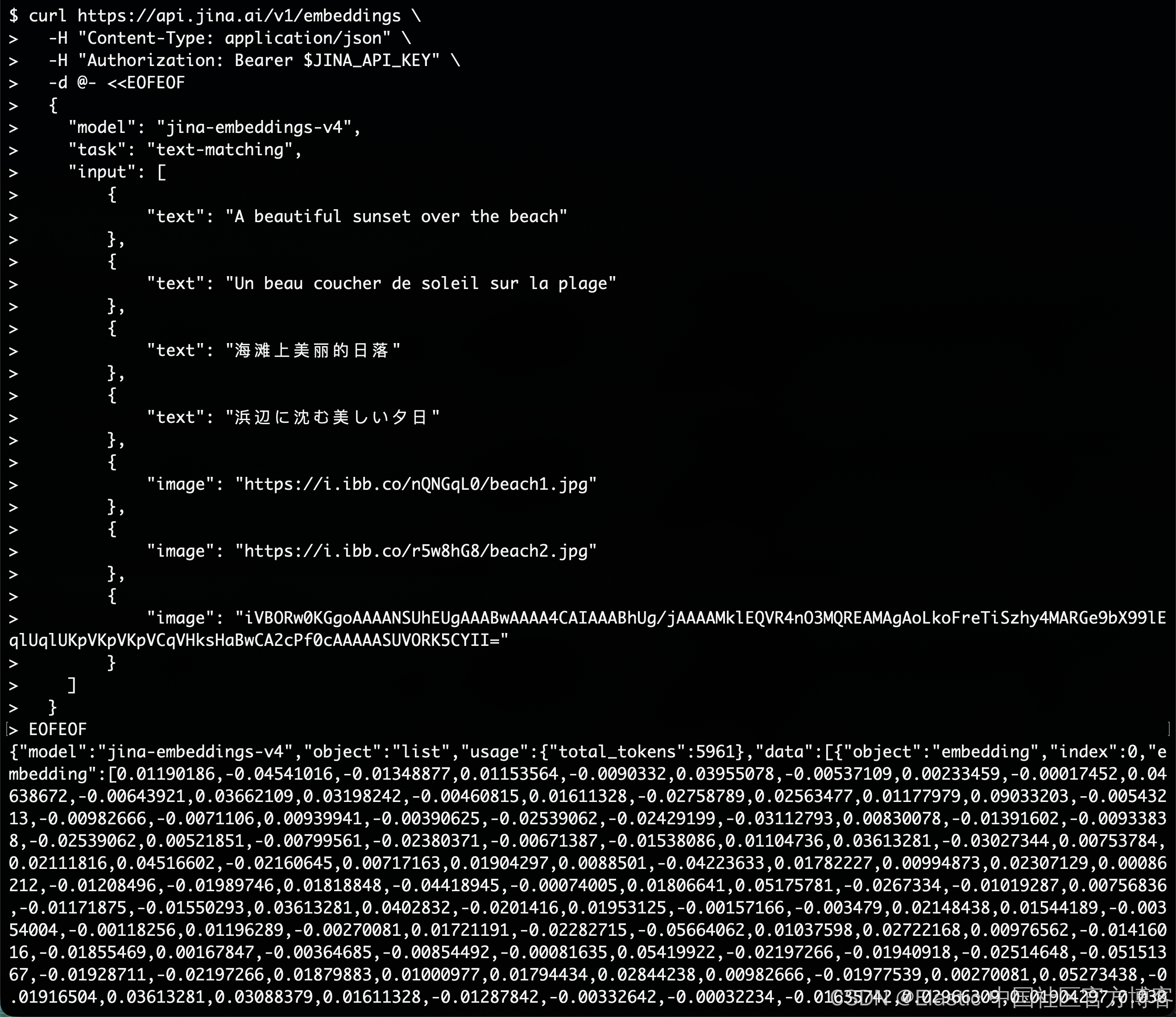
由于 GPU 资源有限,我们的 Embedding API 目前仅支持长度最多 8K tokens 的文档,尽管 jina-embeddings-v4 原生可处理最多 32K tokens。对于需要超过 8K tokens 上下文的应用(如 Late Chunking),建议通过 CSP 部署模型或自建模型托管。
通过 HuggingFace(Via HuggingFace)
出于研究和实验目的,你可以从我们的 Hugging Face 页面在本地使用该模型。我们准备了一个 Google Colab notebook 演示其使用方法。

如果你想部署在本地电脑,请参考代码 https://github.com/liu-xiao-guo/jina_embeddings
结论
jina-embeddings-v4 代表了我们迄今为止最重要的飞跃 —— 一个 38 亿参数的通用向量模型,通过统一路径处理文本和图像,支持密集检索和延迟交互检索,并在视觉丰富的文档检索中尤其超越 Google、OpenAI 和 Voyage AI 的闭源模型。但这种能力并非凭空出现,而是四代模型解决基本限制的成果。
当我们在 2022 年初推出 jina-embeddings-v1 时,大家普遍认为更多数据意味着更好性能。我们证明了相反的观点 —— 将 15 亿对数据筛选为 3.85 亿高质量样本,表现超过了更大规模的数据集。经验教训:精心筛选胜过简单收集。
但用户仍然受制于 BERT 的 512-token 限制。在更长序列上训练似乎代价高昂,直到 jina-embeddings-v2 提出了优雅的解决方案:短序列训练,长序列部署。ALiBi 的线性注意力偏置使在 512 tokens 上训练的模型能够在推理时无缝处理 8,192 tokens。我们以更少的计算获得了更强的能力。
jina-embeddings-v2 的成功暴露了另一个限 制 —— 不同任务需要不同的优化。jina-embeddings-v3 没有构建多个独立模型,而是使用小型 60M LoRA 适配器,将 570M 基础模型定制化以适应任意任务。一个模型变成了五个专用模型。
即便有任务专用化,我们仍然仅处理文本,而用户需要视觉理解。像 jina-clip-v1 和 jina-clip-v2 这样的标准 CLIP 模型使用独立编码器,导致 “模态差距”,不同格式的相似内容最终被分得很远。像我们最近发布的 jina-reranker-m0 一样,jina-embeddings-v4 完全消除了这一问题 —— 一个统一路径处理所有内容,消除差距而非桥接差距。
jina-embeddings-v4 和 jina-reranker-m0 都体现了一个根本性转变:使用 LLM 作为主干模型,而非仅编码器模型。这并非偶然 —— 它反映了一个大多数人忽视的深层优势:仅编码器模型会产生 “模态差距”,图像与文本分开聚类。仅解码器模型则开启了编码器架构无法实现的可能性,包括真正的混合模态表示和可解释性。
我们的核心洞察:嵌入和生成都关乎语义理解。擅长生成的 LLM 天然也擅长表示。我们相信未来在于统一架构 —— 嵌入和重排序都源自同一个搜索基础模型 —— 这正是 Jina AI 正在构建的方向。
原文:https://jina.ai/news/jina-embeddings-v4-universal-embeddings-for-multimodal-multilingual-retrieval/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献177条内容
已为社区贡献177条内容

所有评论(0)