AI、人工智能础: 实体命名!
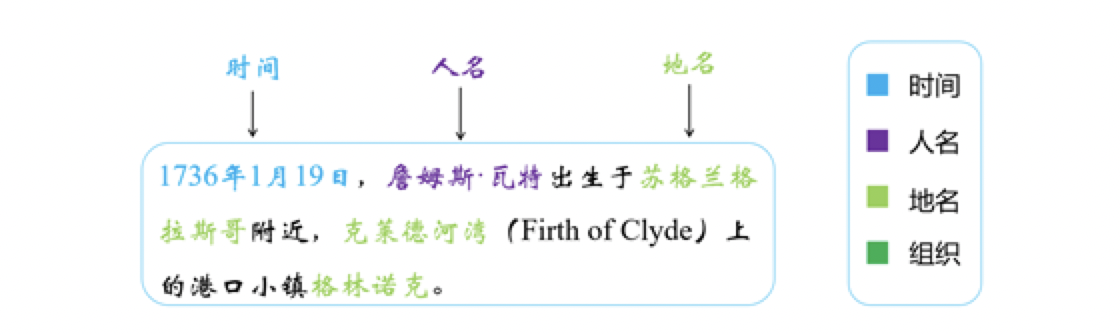
实体是文本之中承载信息的语义单元,是文本语义理解的基础,像一句话之中的人名地名就是一种实体。实体抽取,又称为命名实体识别(named entity recognition,NER),指的是从文本之中抽取出命名性实体,并把这些实体划分到指定的类别。常见的实体包括七种类别:人名、地名、机构名、时间、日期、货币、百分比。如图所示,“1973年1月19日”是时间实体;“詹姆斯·瓦特”是人名实体;“苏格兰”
·
命名实体识别
1 什么是NER
- 实体是文本之中承载信息的语义单元,是文本语义理解的基础,像一句话之中的人名地名就是一种实体。
- 实体抽取,又称为命名实体识别(named entity recognition,NER),指的是从文本之中抽取出命名性实体,并把这些实体划分到指定的类别。
- 常见的实体包括七种类别:人名、地名、机构名、时间、日期、货币、百分比。
-
如图所示,“1973年1月19日”是时间实体;“詹姆斯·瓦特”是人名实体;“苏格兰”、“格拉斯哥”、“克莱德河湾”、“格林诺克”是地名实体。在不同领域的实体抽取任务之中,还会增加其他类型的实体。例如,在一般的医疗知识图谱之中,还会增加疾病、药物、治疗方法等实体。
2 命名实体识别方法
- 命名实体识别一直是自然语言处理中非常重要的一个任务。目前,命名实体识别的方法大致可以分为基于规则的方法、基于传统机器学习的方法、基于深度学习的方法三大类。
2.1 基于规则的方法
- 基于规则:针对有特殊上下文的实体,或实体本身有很多特征的文本,使用规则的方法简单且有效。比如抽取文本中物品价格,如果文本中所有商品价格都是“数字+元”的形式,则可以通过正则表达式”\d*.?\d+元”进行抽取。但如果待抽取文本中价格的表达方式多种多样,例如“一千八百万”,“伍佰贰拾圆”,“2000万元”,遇到这些情况就要修改规则来满足所有可能的情况。随着语料数量的增加,面对的情况也越来越复杂,规则之间也可能发生冲突,整个系统也可能变得不可维护。因此基于规则的方式比较适合半结构化或比较规范的文本中的进行抽取任务,结合业务需求能够达到一定的效果。
- 优点:简单,快速。
- 缺点:适用性差,维护成本高后期甚至不能维护。
2.2 基于传统机器学习的方法
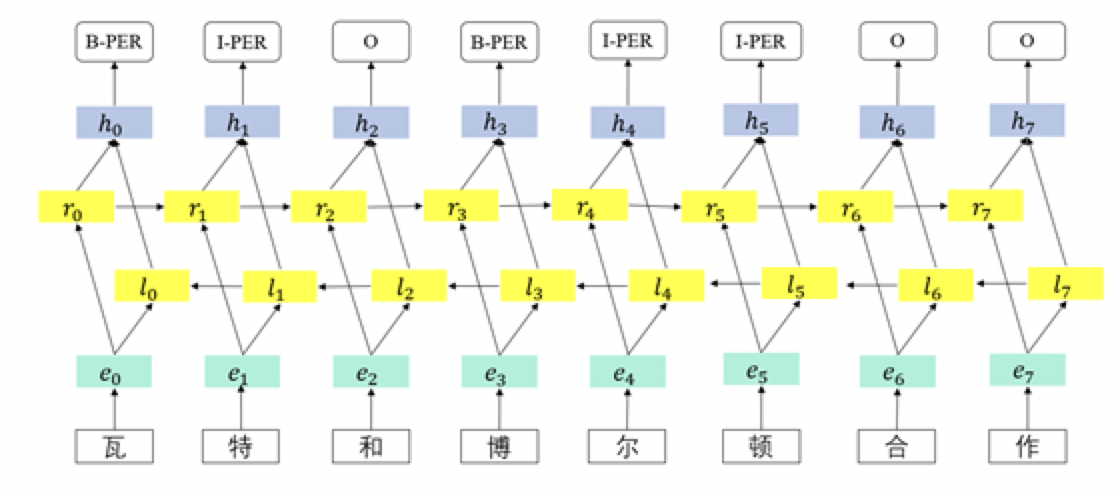
- 早期使用于命名实体识别任务之中的机器学习方法,主要是一些基于统计的方法。使用统计方法,包括三个步骤:①选择特征。传统统计方法需要人工选择特征。这些特征包括词语上下文信息、词缀、词性上下文特征等等。②选择模型并训练模型。③预测实体。这一步是使用已经训练好的模型来预测实体。
| 文本序列 | IO标注体系 | BIO标注体系 | BIOES标注模式 |
|---|---|---|---|
| 瓦 | I-PER | B-PER | B-PER |
| 特 | I-PER | I-PER | E-PER |
| 出 | O | O | O |
| 生 | O | O | O |
| 于 | O | O | O |
| 苏 | I-LOC | B-LOC | B-LOC |
| 格 | I-LOC | I-LOC | I-LOC |
| 兰 | I-LOC | I-LOC | E-LOC |
- 基于序列标注方法的统计模型,常见的包括:支持向量机(SVM)、隐马尔科夫模型(HMM)、条件随机场(CRF)等。在实际研究之中,研究人员往往把这些模型和其他方法结合在一起。
- 在传统的统计方法之中,特征的选择是至关重要的,选择更好的特征能够提高实体抽取的效果。常见的特征可以分为形态、词汇、句法、全局特征、外部信息等。统计学习方法较之基于规则的方法,更加灵活和健壮,可以移植到其他领域。但是这些模型依赖人工设计的特征和现有的自然语言处理工具(如分词工具)。人工设计的特征和自然语言处理工具直接影响到统计模型的性能。
2.3 基于深度学习的方法
-
在近年来深度学习模型逐渐火爆的背景下,大量的深度学习模型被使用到实体抽取任务之中。基于深度学习的方法,不需要设计复杂的特征,对自然语义处理工具的依赖也较少。基于深度学习的方法主要使用神经网络模型,结合条件随机场模型。常用的神经网络模型包括卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等,其中BiLSTM-CRF是目前最为常用的命名实体识别模型.
- 基于深度学习的方法,不需要人工来设计特征,同时能够取得较高的准确率和召回率。但是这些模型十分依赖人工标注数据,标注语料的缺乏为模型的训练带来了极大的困难。
3 NER评测标准
- NER的评测标准通常包括:准确率 ( Precision ) 、召回率 ( Recall ) 和 F1 值三个方面
- 准确率:模型识别出来的实体中,被所有预测为正的样本中实际为正样本的概率
- 召回率:模型识别出来的实体中,实际为正的样本中被预测为正样本的概率
- 而 F1 值则是准确率和召回率的调和平均值,可以对系统的性能进行综合性的评价
- 对应的计算为:

4 NER的常见问题
- 现阶段的实体抽取模型很少考虑标签重叠问题。所谓标签重叠,指的是每个词或字具有两种以上的标签。而现阶段的模型,每个词或字只能属于某一类标签。对于多标签的实体抽取,仍然是实体抽取未来的主要研究方向之一。
- 目前的实体抽取方法大都局限于抽取人名、地名、机构名等传统实体类别,而实际应用中,所需要抽取的类别会更多,并且缺乏标注数据。
基于规则实现NER
学习目标
- 理解什么是规则派的NER
- 掌握NER任务常见的规则处理方法.
1 基于规则实现NER的原理
- 基于规则的方法多采用语言学专家手工构造规则模板, 选用特征包括统计信息, 标点符号, 关键字, 指示词和方向词, 位置词(如尾字), 中心词等方法, 以模式和字符串相匹配为主要手段, 这类系统大多依赖于知识库和词典的建立.
- 基于规则和词典的方法是命名实体识别中最早使用的方法.
- 一般而言, 当提取的规则能比较精确地反映语言现象时, 基于规则的方法性能要优于基于统计的方法.
- 但是这些规则往往依赖于具体语言, 领域和文本风格, 编制过程耗时且难以涵盖所有的语言现象, 特别容易产生错误, 系统可移植性不好, 对于不同的系统需要语言学专家重新书写规则. 基于规则的方法的另外一个缺点是代价太大, 存在系统建设周期长, 移植性差而且需要建立不同领域知识库作为辅助以提高系统识别能力等问题.
2 常见的规则处理方法
- 工业界常用的规则处理方法:
- 领域字典匹配
- 定义正则表达式
3 案例分析
- 为了更好地理解基于规则的NER方法,我们来看一个具体的例子。假设我们要从一段新闻报道中识别出机构名。首先,我们设计以下规则:
- 如果一个词语后面紧跟着“公司”、“集团”等词,那么它可能是一个机构名的开始。
- 如果一个词语后面紧跟着“局”、“部”等词,那么它可能是一个机构名的结束。
- 然后,我们构建一个包含“公司”、“集团”、“局”、“部”等词的词典。接下来,我们对新闻报道进行序列标注,将词典中的词标记为B或E,其余词语标记为O。最后,我们使用正则表达式“B+OE”从标注序列中抽取出机构名。
- 代码实现:
import jieba import jieba.posseg as pseg import re org_tag = ['公司', '有限公司', '大学', '政府', '人民政府', '总局'] def extract_org(text): # 使用jieba的词性标注进行分词 words_flags = pseg.lcut(text) words, features = [], [] for word, flag in words_flags: words.append(word) if word in org_tag: features.append('E') else: if flag in ['ns']: # 地名关键词,利用jieba的词性标注,'ns'代表地名 features.append('S') else: features.append('O') labels = ''.join(features) pattern = re.compile('S+O*E+') match_label = re.finditer(pattern, labels) match_list = [] for ne in match_label: match_list.append(''.join(words[int(ne.start()):int(ne.end())])) return match_list text = "可在接到本决定书之日起六十日内向中国国家市场监督管理总局申请行政复议,杭州海康威视数字技术股份有限公司." print(extract_org(text)) ##result: ['中国国家市场监督管理总局', '杭州海康威视数字技术股份有限公司']
1

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)