DeepSeek实战--帮你找最合适的工作
摘要:本文介绍了一个AI辅助求职工具的实现方案,通过Python开发环境(3.11版本)结合Deepseek-chat大模型和OpenAI SDK,实现了自动化岗位匹配功能。该工具主要包含两个核心模块:一是通过无头浏览器爬取招聘网站岗位信息,二是基于用户简历和岗位需求列表进行智能匹配。系统会先检索符合要求的岗位,然后通过预设的prompt模板将简历与岗位需求进行对比分析,最终输出最匹配的3个岗位及
1. 背景
在软件行业里面,快速涨薪有2中方式:第一种遇到一家高速发展的互联网独角兽企业,企业的快速发展,可以将你层级拽到很高层级,薪资也随之提升,比如:抖音创立初加入。第二种,不断学习技术、业务,然后去干更难、更有价值的事情,若你发现公司的发展速度,已经慢于自己成长的速度,那就得通过跳槽,来寻求更大的发展空间及更好的薪资。
换工作是一个非常消耗精力的事情,要甄别适合自己的岗位需要非常多的时间,以往我们都是在招聘网站上看招聘jd,然后投递,茫茫jd中要找到中意的,有没有更高效的方式 ? 有,而且大模型出来后,让这个事情,变得简单。 今天,我们就来实现,一个Ai帮找工作的工具。迟早,要找工作的,这点时间投入,ROI挺高的,当然建议你收藏一下,后续大概率能用得着,哈哈哈!
2. 环境
python 版本:3.11
LLM: deepseek-chat
SDK:openai 1.63.2
3. 实现逻辑
- 到某个一个城市,检索符合要求的岗位 根据招聘网站,
- 筛选出的岗位,逐个看(薪资、公司、岗位要求、任职资格、业务情况…)
- 找到自己感兴趣的岗位,然后投递
4. 步骤
Step1:新建项目
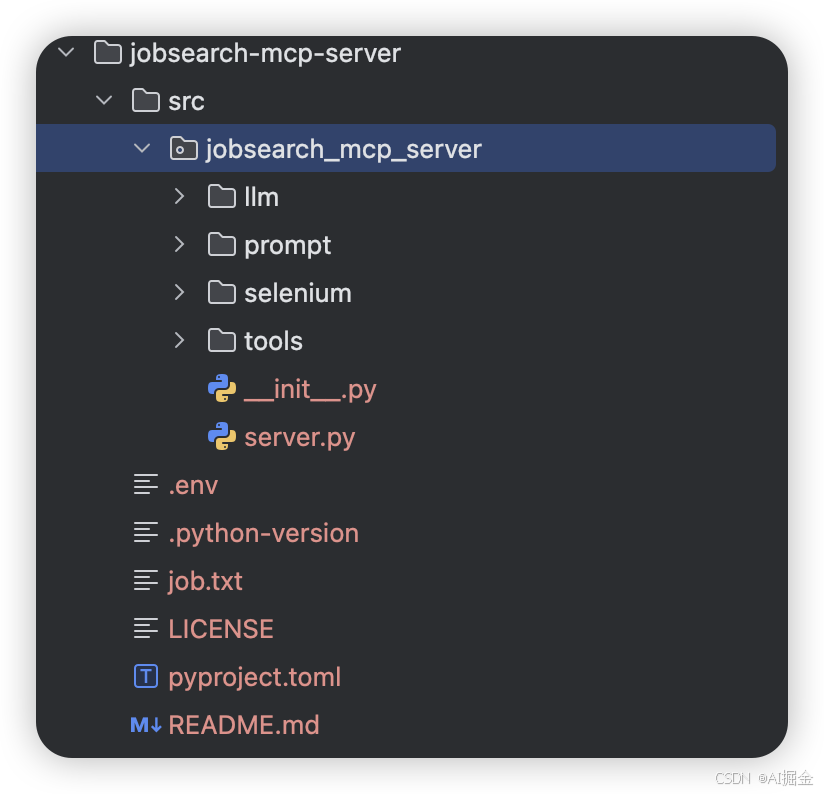
jobsearch_mcp_server:文件夹名称,类似java中package name,命名必须用下划线
server.py: 业务程序,核心调度,有main方法,也可以单独执行
pyproject.toml :这是整个 uv 项目的依赖管理、编译管理、运行管理等功能的配置文件,类似于 maven 的 pom 文件
.env: 用来存放环境变量
init.py: 由于文件夹下有多个main方法,会默认加载这个文件中的main方法
Step2:建搜索岗位工具
核心代码
def listjob_by_keyword(keyword:str,page:int=1,size:int=30)->str:
print("listjob")
url=listurl.format(urlencode({
"query":keyword,
"city":"101020100"
}))
print("url: ",url)
driver=init_driver()
if driver is None:
raise Exception("创建无头浏览器失败")
print("创建无头浏览器成功")
#driver.maximize_window()
driver.get(url)
print("title: ",driver.title)
#print(driver.get_cookies())
#driver = set_cookies(driver)
#all_cookies = driver.get_cookies()
#for cookie in all_cookies:
# print(cookie)
driver.save_screenshot("page_screenshot.png")
print("title: ",driver.title)
WebDriverWait(driver, 1000, 0.8).\
until(EC.presence_of_element_located((By.CSS_SELECTOR,
'.job-list-box'))) #等待页面加载到出现job-list-box 为止
li_list=driver.find_elements(By.CSS_SELECTOR,
".job-list-box li.job-card-wrapper")
jobs=[]
for li in li_list:
job_name_list=li.find_elements(By.CSS_SELECTOR,".job-name")
if len(job_name_list)==0:
continue
job={}
job["job_name"]=job_name_list[0].text
job_salary_list=li.find_elements(By.CSS_SELECTOR,".job-info .salary")
if job_salary_list and len(job_salary_list)>0:
job["job_salary"]=job_salary_list[0].text
else:
job["job_salary"]="暂无"
job_tags_list=li.find_elements(By.CSS_SELECTOR,".job-info .tag-list li")
if job_tags_list and len(job_tags_list)>0:
job["job_tags"]=[tag.text for tag in job_tags_list]
else:
job["job_tags"]=[]
com_name=li.find_element(By.CSS_SELECTOR,".company-name")
if com_name:
job["com_name"]=com_name.text
else:
continue #
com_tags_list=li.find_elements(By.CSS_SELECTOR,".company-tag-list li")
if com_tags_list and len(com_tags_list)>0:
job["com_tags"]=[tag.text for tag in com_tags_list]
else:
job["com_tags"]=[]
job_tags_list_footer=li.find_elements(By.CSS_SELECTOR,".job-card-footer li")
if job_tags_list_footer and len(job_tags_list_footer)>0:
job["job_tags_footer"]=[tag.text for tag in job_tags_list_footer]
else:
job["job_tags_footer"]=[]
jobs.append(job)
# driver.close()
driver.quit()
job_tpl="""
{}. 岗位名称: {}
公司名称: {}
岗位要求: {}
技能要求: {}
薪资待遇: {}
"""
ret=""
if len(jobs)>0:
for i, job in enumerate(jobs):
job_desc = job_tpl.format(str(i + 1), job["job_name"],
job["com_name"],
",".join(job["job_tags"]),
",".join(job["job_tags_footer"]),
job["job_salary"])
ret += job_desc + "\n"
print("完成直聘网分析")
return ret
else:
raise Exception("没有找到任何岗位列表")
详见:https://blog.csdn.net/qq_36918149/article/details/149670296?spm=1001.2014.3001.5502
Step3:岗位匹配–prompt
【AI求职助手】
你是一个AI求职助手, 我正在寻找与我的技能和经验相匹配的工作机会。以下是我的简历摘要和搜集到的岗位需求列表
【个人简历】
{resume}
【岗位需求列表】
{job_list}
请帮我匹配最合适的3个岗位, 并根据我的简历提供简要的求职建议。
Step4:岗位匹配–工具
@mcp.tool(description="根据求职者的简历获取适合该求职者的岗位以及求职建议")
def get_job_by_resume(jobs: str, resume: str) -> str:
"""根据求职者的简历获取适合该求职者的岗位以及求职建议"""
#将简历以及岗位列表注入到 prompt 模板
prompt = Job_Search_Prompt.format(resume=resume,job_list=jobs)
messages = [{"role": "user", "content": prompt}]
self.logger.info(f"prompt: {prompt}")
#发送给 ds
response = LLMClient.send_messages(self,messages)
response_text = response.choices[0].message.content
return response_text
5. 总结
通过上面关键步骤,可以在网站上通过爬取到与你简历相符的岗位,这个比你逐个去筛选岗位快多了吧。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)