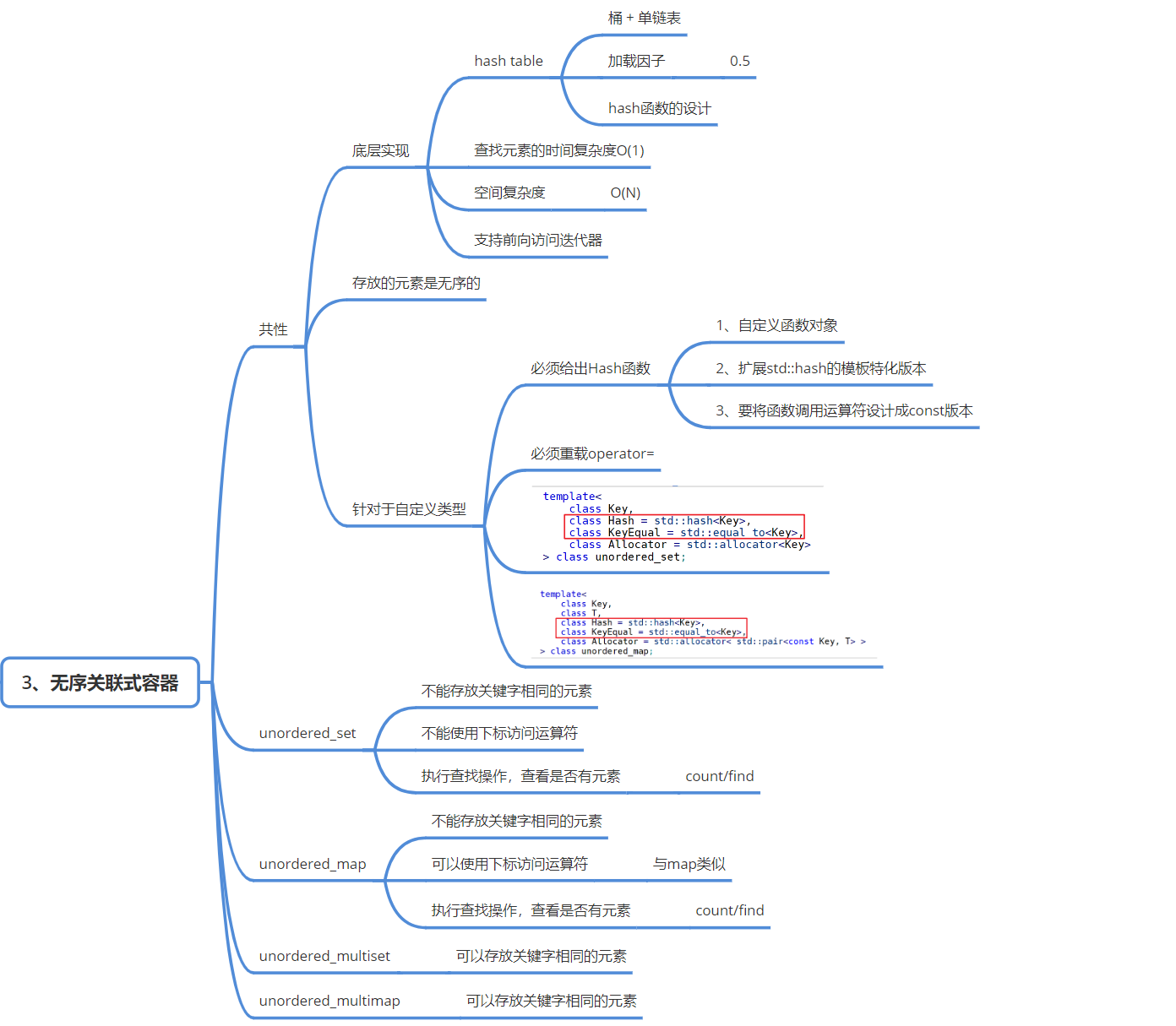
关联容器(Associative containers)1
可以推导出。
| 类别 | 容器名称 | 底层实现 | 核心特性 |
|---|---|---|---|
| 有序关联容器 | set |
平衡二叉搜索树 | 存储唯一键,键即值,元素按键升序排列(默认 std::less<Key>) |
multiset |
平衡二叉搜索树 | 存储可重复键,键即值,元素按键升序排列 | |
map |
平衡二叉搜索树 | 存储「键值对(key-value)」,键唯一,元素按键升序排列 | |
multimap |
平衡二叉搜索树 | 存储「键值对」,键可重复,元素按键升序排列 | |
| 无序关联容器 | unordered_set |
哈希表 | 存储唯一键,键即值,元素无序(按哈希值存储),查找效率更高(平均 O (1)) |
unordered_multiset |
哈希表 | 存储可重复键,键即值,元素无序 | |
unordered_map |
哈希表 | 存储「键值对」,键唯一,元素无序 | |
unordered_multimap |
哈希表 | 存储「键值对」,键可重复,元素无序 |
容器的介绍
具体的话可以参考手册cppreference_docs/html_book_20190607/reference/en/cpp/container.html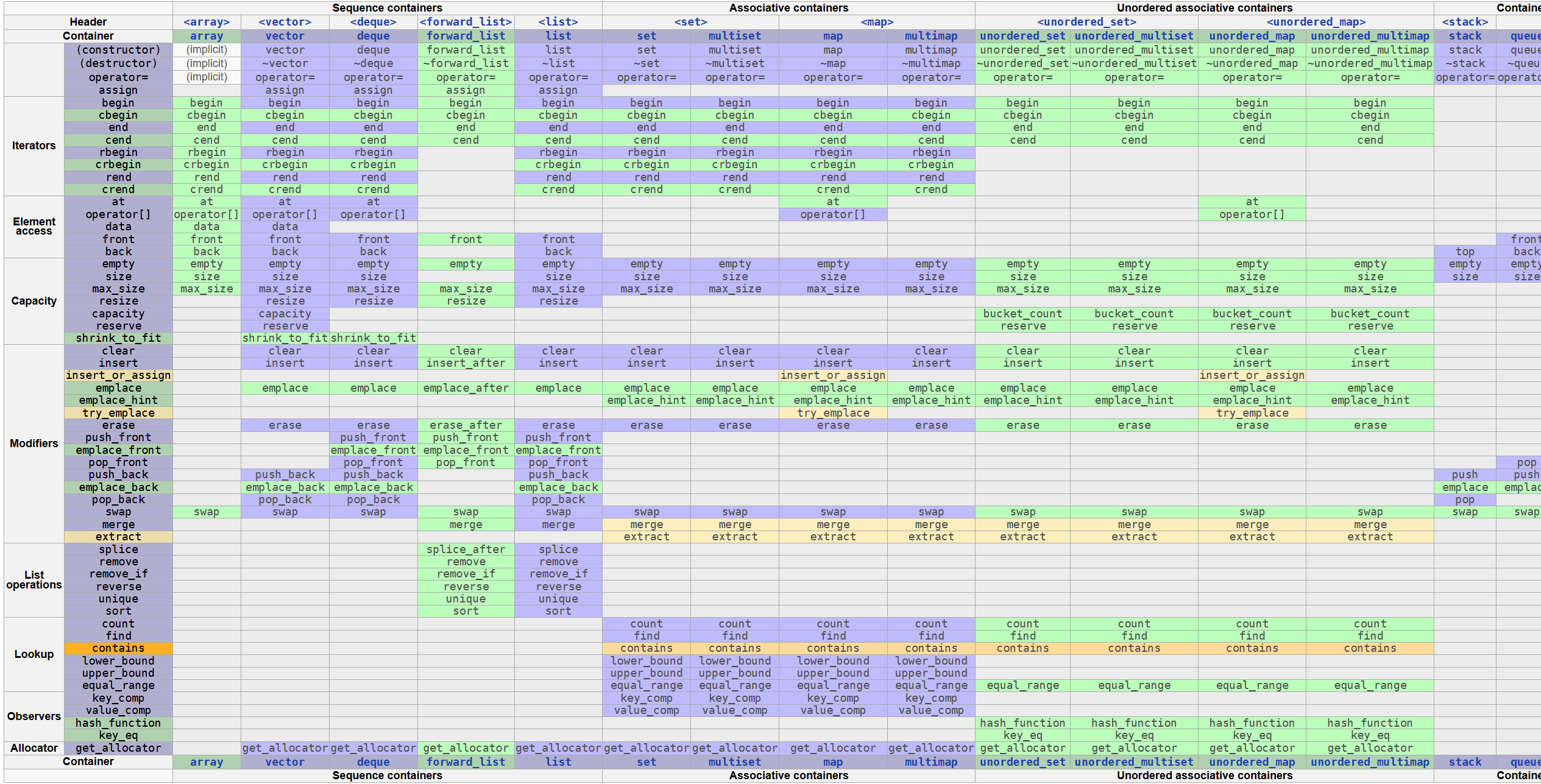
关联式容器
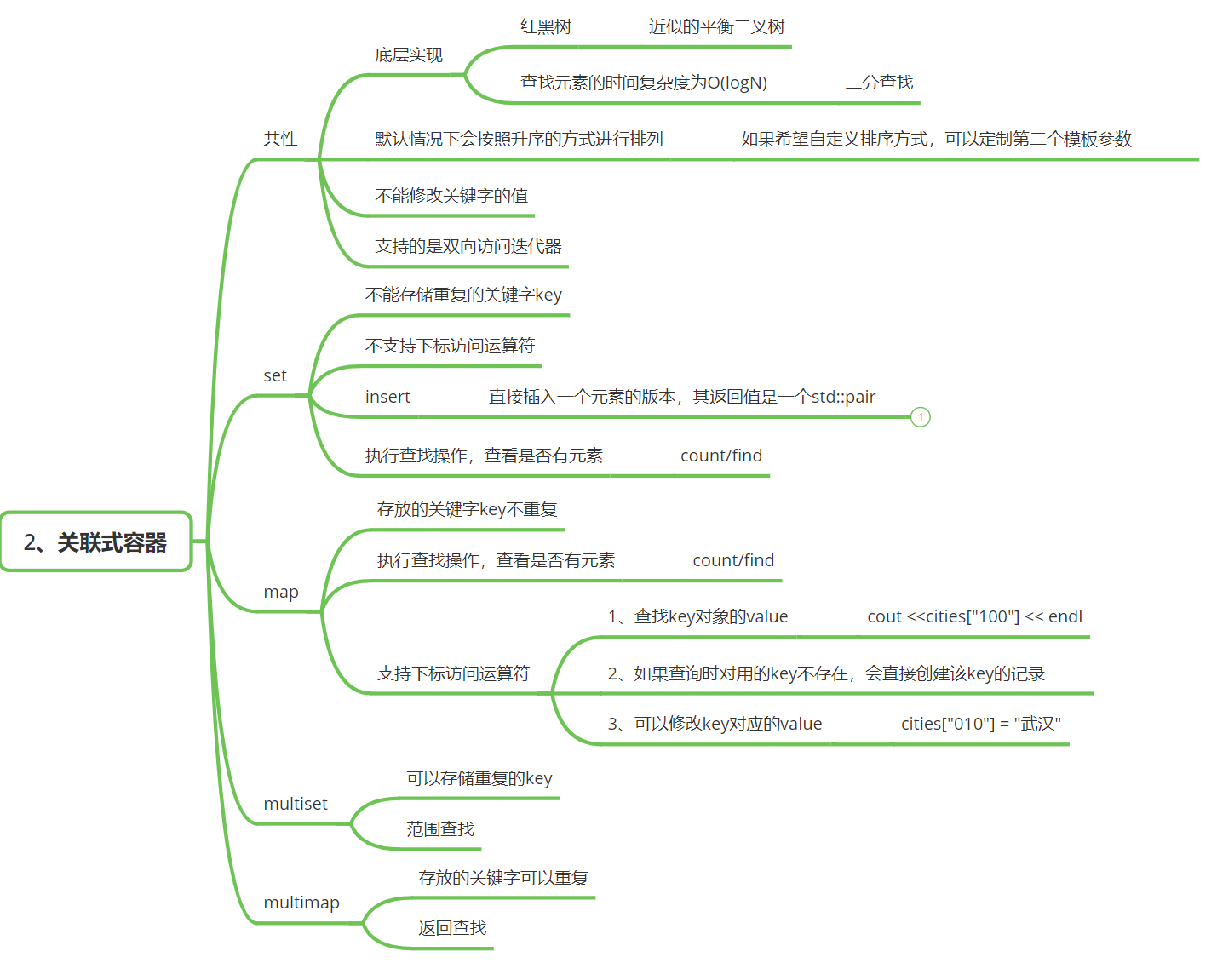
set
set的特征:
(1)set中存放的元素是唯一的,不能重复;
(2)默认情况下,会按照元素进行升序排列;
以下是 std::set 和 std::vector 的核心区别对比表格:
| 特性 | std::set |
std::vector |
|---|---|---|
| 容器类型 | 关联容器(有序、唯一) | 序列容器(动态数组) |
| 存储结构 | 通常基于平衡二叉树(如红黑树) | 连续内存空间(动态数组) |
| 元素顺序 | 按键(元素本身)的排序规则存储(默认升序) | 按插入顺序存储,元素顺序由插入位置决定 |
| 元素唯一性 | 元素唯一(不允许重复,重复插入会被忽略) | 允许重复元素,插入多少保留多少 |
| 随机访问 | 不支持(需通过迭代器顺序访问,时间复杂度 O (n)) | 支持(通过下标 [] 或 at(),时间复杂度 O (1)) |
| 插入效率 | 任意位置插入 O (log n)(基于树结构) | 尾部插入 O (1)( amortized,平均);中间 / 头部插入 O (n)(需移动元素) |
| 删除效率 | 任意元素删除 O (log n)(通过键查找后删除) | 尾部删除 O (1);中间 / 头部删除 O (n)(需移动元素) |
| 查找效率 | 按值查找 O (log n)(基于树的二分查找) | 按值查找 O (n)(需遍历整个容器) |
| 迭代器稳定性 | 插入 / 删除元素时,其他元素的迭代器不受影响 | 插入元素可能导致迭代器失效(内存重分配时);删除元素会导致该位置及之后的迭代器失效 |
| 内存占用 | 额外内存开销较大(树节点需存储指针等信息) | 内存连续,额外开销小(仅需存储容量信息等) |
| 典型应用场景 | 需要快速查找、去重、有序存储的场景(如集合运算) | 需要随机访问、尾部频繁增删的场景(如动态数组、缓冲区) |
set的构造
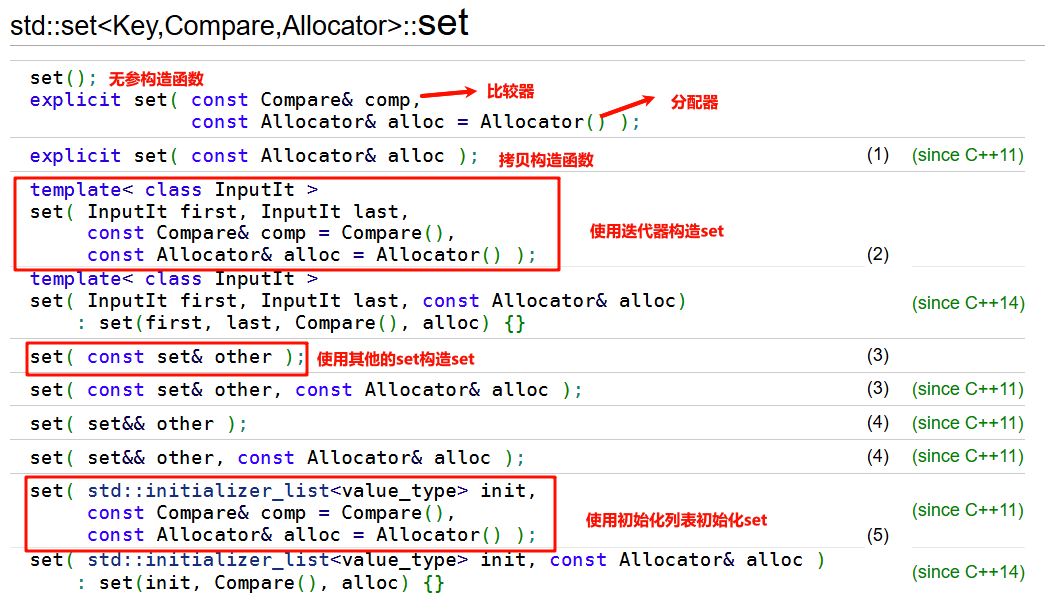
void test(){
//无参构造
set<int> numbers;
//标准初始化列表
set<int> numbers2 = {4, 2, 1, 3, 4, 3, 2, 6};
//拷贝构造形式
set<int> numbers3 = numbers2;
//迭代器进行构造
set<int> numbers4(numbers2.begin(), numbers2.end());
}set的增删改查
find
iterator find( const Key& key );根据具有与指定键相等的键值的元素进行迭代。若未找到此类元素,则返回指向序列末尾的(见 end())迭代器。
std::set<int> example = {1, 2, 3, 4};
auto search = example.find(2);
if (search != example.end()) {
std::cout << "Found " << (*search) << '\n';
} else {
std::cout << "Not found\n";
}count
size_type count( const Key& key ) const;
//Returns the number of elements with key key.返回具有与指定参数()该参数要么为 1 要么为 0相等的键的元素数量。由于此容器不允许重复元素,因此该数量要么为 1 要么为 0 。
insert
std::pair<iterator,bool> insert( const value_type& value );
void insert( InputIt first, InputIt last );返回一个包含两个元素的元组:一个是指向插入元素(或者阻止插入的元素)的迭代器,另一个是一个布尔值,若插入操作成功则该值设为 true 。
Example
void test3(){
set<int> number = {1, 2, 3, 4, 5};
pair<set<int>::iterator, bool> result = number.insert(4);
if(result.second){
cout << "该元素插入成功:"
<< *(result.first) << endl;
}else {
cout << "该元素插入失败,原本就存在" << endl;
}
//插入一组元素
int arr[6] = {33, 5, 1, 4, 56};
number.insert(arr, arr + 6);
for(auto & e : number){
cout << e << " ";
}
cout << endl;
//大括号形式插入一组元素
number.insert({100, 99, 87, 99});
for(auto & e : number){
cout << e << " ";
}
cout << endl;
}注意:
-
set容器不支持下标访问,因为没有operator[] 重载函数
-
不能通过set的迭代器直接修改key值,set的底层实现是红黑树,结构稳定,不允许直接修改。
multiset
std::multiset 是一种有序、可重复的关联式容器,底层基于红黑树实现(保证 O (log n) 的时间复杂度)。其核心特性是:元素按指定规则(默认升序)自动排序,且允许存储多个相同值的元素。
由于 std::multiset 的 “有序性” 依赖元素值,因此它不支持直接修改元素(元素被设计为 const 类型,避免破坏排序),“改” 操作需通过 “先删后增” 间接实现。下面详细讲解 multiset 的增、删、改、查操作,包含函数用法、示例代码和注意事项。
增(插入元素)
multiset 提供 insert 和 emplace 两类插入函数,支持单个元素、多个元素、范围插入,且允许插入重复值。
核心插入函数
| 函数原型 | 功能说明 | 返回值 |
|---|---|---|
iterator insert(const T& val) |
插入元素 val(拷贝构造),自动按排序规则插入到正确位置 |
指向插入元素的迭代器(即使重复) |
iterator insert(T&& val) |
插入元素 val(移动构造),效率高于拷贝构造 |
指向插入元素的迭代器 |
template <class InputIt> void insert(InputIt first, InputIt last) |
插入 [first, last) 范围内的所有元素(左闭右开) |
无(void) |
void insert(initializer_list<T> ilist) |
插入初始化列表中的元素(如 {1,2,3}) |
无(void) |
template <class... Args> iterator emplace(Args&&... args) |
直接在容器中构造元素(避免拷贝 / 移动),参数为元素构造函数的参数 | 指向新构造元素的迭代器 |
示例代码
void test_insert() {
multiset<int> ms;
// 1. 插入单个元素(允许重复)
ms.insert(3);
ms.insert(1);
ms.insert(2);
ms.insert(3); // 重复插入 3,正常存储
cout << "插入后 multiset:";
for (auto& x : ms) cout << x << " "; // 输出:1 2 3 3(自动升序)
cout << endl;
// 2. 移动插入(适合临时对象,减少拷贝)
ms.insert(move(4)); // 等价于 insert(4),但对临时对象更高效
cout << "移动插入后:";
for (auto& x : ms) cout << x << " "; // 输出:1 2 3 3 4
cout << endl;
// 3. 范围插入(从其他容器拷贝)
vector<int> vec = {5, 2, 5};
ms.insert(vec.begin(), vec.end());
cout << "范围插入后:";
for (auto& x : ms) cout << x << " "; // 输出:1 2 2 3 3 4 5 5
cout << endl;
// 4. 初始化列表插入
ms.insert({6, 3});
cout << "初始化列表插入后:";
for (auto& x : ms) cout << x << " "; // 输出:1 2 2 3 3 3 4 5 5 6
cout << endl;
// 5. emplace 插入(直接构造,高效)
ms.emplace(7); // 等价于 insert(7),但无需拷贝
cout << "emplace 插入后:";
for (auto& x : ms) cout << x << " "; // 输出:1 2 2 3 3 3 4 5 5 6 7
cout << endl;
}
注意事项
- 插入操作不会使现有迭代器失效(红黑树结构特性),但新插入的元素会改变容器的排序。
emplace比insert更高效:insert会先构造临时对象再拷贝到容器,emplace直接在容器内存中构造对象,避免拷贝开销。
删(删除元素)
multiset 提供 erase 和 clear 函数,支持按迭代器、值、范围删除元素,需注意 “按值删除” 会删除所有等于该值的元素。
核心删除函数
| 函数原型 | 功能说明 | 返回值 |
|---|---|---|
void erase(iterator pos) |
删除迭代器 pos 指向的单个元素(需确保 pos 有效,且不是 end()) |
无(void) |
void erase(iterator first, iterator last) |
删除 [first, last) 范围内的所有元素(左闭右开) |
无(void) |
size_type erase(const T& val) |
删除所有值等于 val 的元素 |
返回删除的元素个数 |
void clear() |
删除容器中所有元素,清空容器 | 无(void) |
示例代码
void test_erase() {
multiset<int> ms = {1, 2, 2, 3, 3, 3, 4, 5, 5};
cout << "初始 multiset:";
for (auto& x : ms) cout << x << " "; // 1 2 2 3 3 3 4 5 5
cout << endl;
// 1. 按迭代器删除(删除第一个元素)
auto it1 = ms.begin();
ms.erase(it1);
cout << "删除第一个元素后:";
for (auto& x : ms) cout << x << " "; // 2 2 3 3 3 4 5 5
cout << endl;
// 2. 按值删除(删除所有等于 3 的元素)
size_t del_cnt = ms.erase(3);
cout << "删除所有值为 3 的元素,共删除 " << del_cnt << " 个:";
for (auto& x : ms) cout << x << " "; // 2 2 4 5 5(删除了 3 个 3)
cout << endl;
// 3. 按范围删除(删除从第一个 5 到末尾的元素)
auto it2 = ms.find(5); // 找到第一个 5 的迭代器
if (it2 != ms.end()) {
ms.erase(it2, ms.end()); // 删除 [it2, end())
}
cout << "删除从第一个 5 到末尾后:";
for (auto& x : ms) cout << x << " "; // 2 2 4
cout << endl;
// 4. 清空容器
ms.clear();
cout << "清空后,size = " << ms.size() << endl; // size = 0
}
注意事项
- 按迭代器删除时,被删除的迭代器会失效,后续不可再使用;其他迭代器仍有效。
- 按值删除时,若元素不存在,返回
0(无错误);若存在多个相同元素,会全部删除。 - 范围删除时,
[first, last)需是有效的迭代器范围(first在last之前,且均属于当前容器)。
查(查找元素)
multiset 提供 find、count、lower_bound、upper_bound、equal_range 等查找函数,利用其有序性实现高效查找(O (log n) 时间)。
核心查找函数
| 函数原型 | 功能说明 | 返回值 |
|---|---|---|
iterator find(const T& val) |
查找第一个值等于 val 的元素 |
指向该元素的迭代器;若无,返回 end() |
const_iterator find(const T& val) const |
常量版本(不可修改找到的元素) | 同上(常量迭代器) |
size_type count(const T& val) const |
统计容器中值等于 val 的元素个数 |
元素个数(0 表示不存在) |
iterator lower_bound(const T& val) |
查找第一个值 ≥ val 的元素(下界) | 指向该元素的迭代器;若无,返回 end() |
const_iterator lower_bound(const T& val) const |
常量版本 | 同上(常量迭代器) |
iterator upper_bound(const T& val) |
查找第一个值 > val 的元素(上界) | 指向该元素的迭代器;若无,返回 end() |
const_iterator upper_bound(const T& val) const |
常量版本 | 同上(常量迭代器) |
pair<iterator, iterator> equal_range(const T& val) |
查找所有值等于 val 的元素范围,返回迭代器对 (lower_bound, upper_bound) |
包含目标元素的迭代器范围 |
pair<const_iterator, const_iterator> equal_range(const T& val) const |
常量版本 | 同上(常量迭代器对) |
示例代码
void test_find() {
multiset<int> ms = {1, 2, 2, 3, 3, 3, 4, 5, 5};
cout << "当前 multiset:";
for (auto& x : ms) cout << x << " "; // 1 2 2 3 3 3 4 5 5
cout << endl;
// 1. find:查找第一个值为 2 的元素
auto it_find = ms.find(2);
if (it_find != ms.end()) {
cout << "find(2) 找到元素:" << *it_find << endl; // 输出 2
} else {
cout << "find(2) 未找到元素" << endl;
}
// 2. count:统计值为 3 的元素个数
size_t cnt = ms.count(3);
cout << "count(3):容器中共有 " << cnt << " 个值为 3 的元素" << endl; // 3 个
// 3. lower_bound & upper_bound:查找值为 5 的范围
auto it_lower = ms.lower_bound(5); // 第一个 ≥5 的元素(即第一个 5)
auto it_upper = ms.upper_bound(5); // 第一个 >5 的元素(即 end())
cout << "lower_bound(5) 到 upper_bound(5) 的元素:";
for (auto it = it_lower; it != it_upper; ++it) {
cout << *it << " "; // 输出 5 5
}
cout << endl;
// 4. equal_range:直接获取值为 2 的范围(等价于 lower_bound + upper_bound)
auto range = ms.equal_range(2);
cout << "equal_range(2) 的元素:";
for (auto it = range.first; it != range.second; ++it) {
cout << *it << " "; // 输出 2 2
}
cout << endl;
// 5. 查找不存在的元素
auto it_not_exist = ms.find(6);
if (it_not_exist == ms.end()) {
cout << "find(6) 未找到元素" << endl;
}
}
注意事项
find仅返回第一个等于目标值的元素(因容器有序,相同元素连续存储)。lower_bound和upper_bound是查找 “范围” 的核心,结合使用可遍历所有相同元素(如示例中遍历所有 5 或 2)。- 常量容器(
const multiset)需使用const_iterator版本的查找函数,避免修改元素。
map
std::map 是一个键值对(key-value)容器,其模板定义为:
template<
class Key,
class T,
class Compare = std::less<Key>,
class Allocator = std::allocator<std::pair<const Key, T>>
> class map;若要改为降序排序(从大到小),可以通过指定比较器(Comparator) 来实现
#include <iostream>
#include <map>
#include <functional> // 包含 std::greater
int main() {
// 定义降序 map,第三个模板参数为 std::greater<int>
std::map<int, std::string, std::greater<int>> desc_map;
// 插入元素
desc_map[3] = "three";
desc_map[1] = "one";
desc_map[2] = "two";
// 遍历输出(会按 key 降序排列)
for (const auto& pair : desc_map) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
map的构造
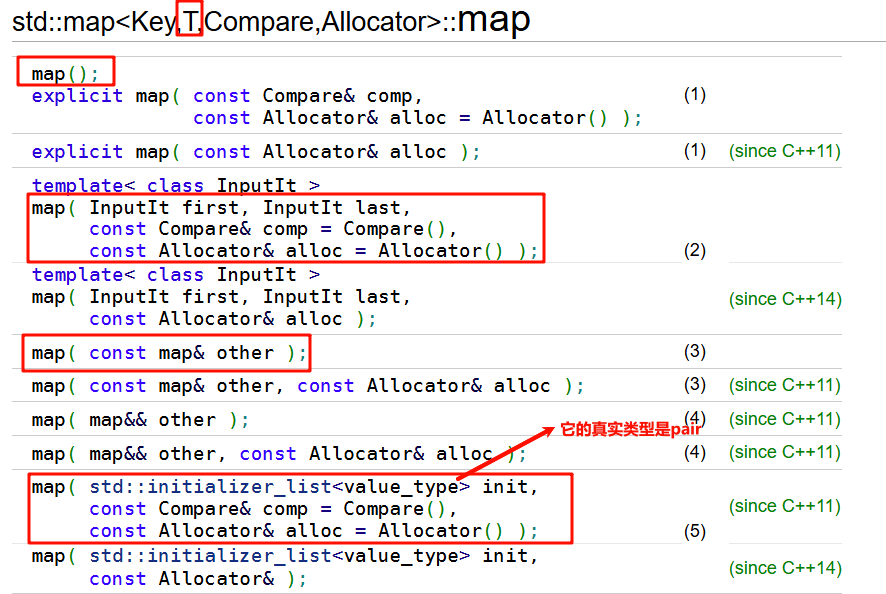
Key 是键(key)的类型
T 是值(value)的类型
map<int, string>的value_type是std::pair<const int, string>—— 这是map存储键值对的实际类型(键是const的,保证不能被修改,符合map键唯一且不可变的特性)。

void test0(){
map<int,string> number = {
{1,"hello"},
{2,"world"},
{3,"wangdao"},
pair<int,string>(4,"hubei"),
pair<int,string>(5,"wangdao"),
make_pair(9,"shenzhen"),
make_pair(3,"beijing"),
make_pair(6,"shanghai")
};
}map的增删改查
遍历
使用迭代器方式遍历map,注意访问map的元素pair的内容时的写法
//使用迭代器方式遍历map,注意访问map的元素pair的内容时的写法
map<int,string>::iterator it = number.begin();
while(it != number.end()){
cout << (*it).first << " " << it->second << endl;
++it;
}
//使用增强for循环变量map
for(auto & nu : number){
cout << nu.first << " " << nu.second << endl;
}map的特征:
(1)元素唯一:创建map对象时,舍弃了一些元素,key值相同的元素被舍弃。key不同,即使value相同也能保留
(2)默认以key值为参考进行升序排列
map的查找操作
根据key值在map中进行查找
count函数的返回值:如果找到返回1,如果没找到返回0(size_t类型)
find函数的返回值:如果找到返回相应元素的迭代器,如果没找到返回end( )的结果
void checkFind(map<int,string> & numbers, int key){
auto it = numbers.find(key);
if(it == numbers.end()){
cout << "该元素不在map中" << endl;
}else {
cout << "该元素在map中" << endl;
cout << it->first << "----->" << it->second << endl;
}
}
void test(){
map<int, string> numbers = {
{1, "hello"},
{2, "world"},
{3, "wangdao"},
pair<int, string>(4, "hubei"),
pair<int, string>(5, "wangdao"),
make_pair(9, "shenzhen"),
make_pair(3, "beijing"),
make_pair(6, "shanghai")
};
//根据key值进行查找
cout << numbers.count(10) << endl;
cout << numbers.count(3) << endl;
checkFind(numbers, 6);
checkFind(numbers, 33);
}map的插入操作
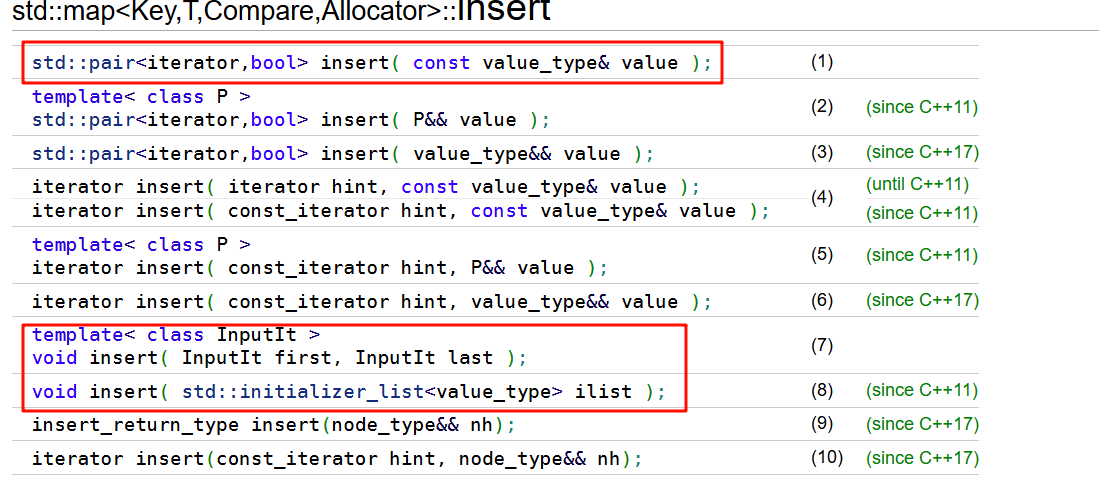
插入单个元素,此时insert函数的返回值是一个pair(第一个对象成员是map元素相应的迭代器,第二个对象成员是bool值)
pair<map<int,string>::iterator,bool> ret = number.insert(pair<int,string>(7,"nanjing"));
if(ret.second){
cout << "该元素插入成功" << endl;
//ret.first取出来的是指向map元素(pair<int,string>)的迭代器
//再用箭头运算符访问到的是int和string的内容
cout << ret.first->first << " : " << ret.first->second << endl;
}else{
cout << "该元素插入失败" << endl;
}
number.insert({8,"nanjing"});
number.insert(make_pair(10, "suzhou"));
cout << endl;插入一组元素
//再创建一个map
map<int,string> number2 = {{1,"beijing"},{18,"shanghai"}};
//迭代器方式
number2.insert(number.begin(),number.end());
//列表方式
cout << endl;
number2.insert({{4,"guangzhou"},{22,"hello"}});
for(auto & ele : number2){
cout << ele.first << " " << ele.second << endl;
}map的下标操作(重点)

map支持下标操作
-
map下标操作返回的是map中元素(pair)的value
-
下标访问运算符中的值代表key,而不是传统意义上的下标
-
如果进行下标操作时下标值传入一个不存在的key,那么会将这个key和空的value(默认的value值)插入到map中
-
下标访问可以进行写操作(只是对value进行写操作,不影响排序)
void test6(){
map<int, string> numbers = {
{1, "hello"},
{3, "wangdao"},
pair<int, string>(4, "hubei"),
make_pair(9, "shenzhen"),
make_pair(6, "shanghai")
};
//map支持下标操作,[]的内容代表key
cout << numbers[1] << endl;
cout << numbers[3] << endl;
//由于key=0并不存在,所以会往map中插入一个key=0,value为空字符串的元素
cout << numbers[0] << endl;
for(auto & nu : numbers){
cout << nu.first << "----->" << nu.second << endl;
}
}multimap
无序关联式容器
unordered_set
在 C++ 标准库中,unordered_set 是基于哈希表(哈希桶) 实现的关联容器,核心特性是:元素无序存储、不允许重复元素、查找效率平均为 O (1)(最坏情况 O (n),取决于哈希冲突处理)。
下面详细讲解 unordered_set 的增、删、改、查操作,结合函数用法、代码示例和注意事项。
一、核心特性回顾
在学习操作前,先明确 unordered_set 的关键特性(影响操作逻辑):
- 元素不可重复:插入重复元素会失败,且不会改变容器内容。
- 元素是 const:无法直接修改容器中的元素(修改会导致哈希值变化,破坏哈希表结构)。
- 无序性:元素存储顺序与插入顺序无关,遍历结果不固定。
- 哈希依赖:存储的元素类型必须支持哈希函数(基本类型如
int/string默认支持;自定义类型需手动实现哈希函数和==运算符)。
二、增(插入元素)
unordered_set 提供 insert 和 emplace 两类插入函数,前者插入已构造的元素,后者就地构造元素(效率更高)。
1. 主要插入函数
| 函数原型 | 功能描述 | 返回值 |
|---|---|---|
pair<iterator, bool> insert(const T& val) |
插入单个元素 val,若重复则插入失败。 |
pair:- 迭代器:指向插入的元素(或已存在的重复元素) - bool: true= 插入成功,false= 重复插入失败 |
iterator insert(iterator pos, const T& val) |
(提示性插入)指定插入位置 pos(哈希表会忽略该位置,仅作为优化提示)。 |
指向插入元素(或重复元素)的迭代器 |
void insert(InputIt first, InputIt last) |
插入区间 [first, last) 内的所有元素(重复元素会被过滤)。 |
无返回值 |
pair<iterator, bool> emplace(Args&&... args) |
就地构造元素(直接用 args 作为构造函数参数),避免拷贝 / 移动开销。 |
同 insert 的单个元素版本 |
2. 代码示例
#include <iostream>
#include <unordered_set>
using namespace std;
int main() {
unordered_set<int> us;
// 1. 插入单个元素(常用)
auto res1 = us.insert(10); // res1是pair<unordered_set<int>::iterator, bool>
if (res1.second) {
cout << "插入10成功,元素为:" << *res1.first << endl; // 输出:插入10成功,元素为:10
}
// 插入重复元素(失败)
auto res2 = us.insert(10);
if (!res2.second) {
cout << "插入10失败(元素已存在),已存在元素为:" << *res2.first << endl; // 输出重复提示
}
// 2. 插入区间元素
int arr[] = {20, 30, 40};
us.insert(arr, arr + 3); // 插入数组[20,30,40]
// 3. 就地构造插入(emplace,效率高于insert)
auto res3 = us.emplace(50);
if (res3.second) {
cout << "emplace 50成功:" << *res3.first << endl; // 输出:emplace 50成功:50
}
// 遍历验证(顺序不固定,可能是10,20,30,40,50或其他顺序)
cout << "当前unordered_set元素:";
for (int num : us) {
cout << num << " ";
}
cout << endl;
return 0;
}
三、删(删除元素)
unordered_set 提供 erase 和 clear 函数,支持按值删除、按迭代器删除和清空容器。
1. 主要删除函数
| 函数原型 | 功能描述 | 返回值 |
|---|---|---|
size_type erase(const T& val) |
按值删除元素 val,若不存在则无操作。 |
删除的元素个数(0 或 1,因无重复) |
iterator erase(iterator pos) |
按迭代器删除元素,pos 必须是有效的非end()迭代器(否则报错)。 |
指向被删除元素下一个元素的迭代器 |
iterator erase(iterator first, iterator last) |
删除区间 [first, last) 内的所有元素。 |
指向 last 的迭代器 |
void clear() |
清空容器中所有元素,size() 变为 0(桶的数量可能不变)。 |
无返回值 |
2. 代码示例
#include <iostream>
#include <unordered_set>
using namespace std;
int main() {
unordered_set<int> us = {10, 20, 30, 40, 50};
cout << "初始元素:";
for (int num : us) cout << num << " "; // 顺序不固定
cout << endl;
// 1. 按值删除
size_t delCnt = us.erase(30); // 删除元素30
cout << "按值删除30,删除个数:" << delCnt << endl; // 输出:1
// 删除不存在的元素(无操作)
delCnt = us.erase(60);
cout << "按值删除60,删除个数:" << delCnt << endl; // 输出:0
// 2. 按迭代器删除(先find找到迭代器)
auto it = us.find(40); // 查找40的迭代器
if (it != us.end()) {
it = us.erase(it); // 删除40,返回下一个元素的迭代器
cout << "删除40后,下一个元素为:" << *it << endl; // 可能是50(取决于存储顺序)
}
// 3. 清空容器
us.clear();
cout << "clear后,容器是否为空:" << (us.empty() ? "是" : "否") << endl; // 输出:是
return 0;
}
四、改(修改元素)
unordered_set 不支持直接修改元素!原因是:
元素的哈希值是插入时计算的,若直接修改元素内容,会导致哈希值变化,破坏哈希表的存储结构(元素无法被正确查找)。
间接修改方案:先删后插
若需 “修改” 元素,需先删除旧元素,再插入新元素(本质是替换,而非修改)。
代码示例
#include <iostream>
#include <unordered_set>
using namespace std;
int main() {
unordered_set<int> us = {10, 20, 30};
cout << "修改前元素:";
for (int num : us) cout << num << " "; // 如:10 20 30
cout << endl;
// 需求:将20改为25(先删后插)
int oldVal = 20;
int newVal = 25;
// 1. 删除旧元素
us.erase(oldVal);
// 2. 插入新元素
us.insert(newVal);
cout << "修改后元素:";
for (int num : us) cout << num << " "; // 如:10 25 30(顺序不固定)
cout << endl;
return 0;
}
五、查(查找元素)
unordered_set 提供 find、count 和 contains(C++20 新增)三种查找函数,核心是判断元素是否存在,或获取元素迭代器。
1. 主要查找函数
| 函数原型 | 功能描述 | 返回值 |
|---|---|---|
iterator find(const T& val) |
按值查找元素 val,找到则返回指向该元素的迭代器;否则返回 end()。 |
迭代器(iterator 或 const_iterator) |
size_type count(const T& val) |
统计元素 val 的个数(因无重复,结果只能是 0 或 1)。 |
0(不存在)或 1(存在) |
bool contains(const T& val) const(C++20) |
直接判断元素 val 是否存在(比 count 更直观,语义更清晰)。 |
true(存在)或 false(不存在) |
2. 代码示例
#include <iostream>
#include <unordered_set>
using namespace std;
int main() {
unordered_set<string> us = {"apple", "banana", "orange"};
// 1. find查找(常用,可获取迭代器)
string target1 = "banana";
auto it = us.find(target1);
if (it != us.end()) {
cout << "find找到元素:" << *it << endl; // 输出:find找到元素:banana
} else {
cout << "find未找到元素:" << target1 << endl;
}
// 查找不存在的元素
string target2 = "grape";
if (us.find(target2) == us.end()) {
cout << "find未找到元素:" << target2 << endl; // 输出:未找到grape
}
// 2. count判断存在性(返回0或1)
if (us.count("apple")) {
cout << "count:apple 存在" << endl; // 输出:存在
}
if (us.count("grape") == 0) {
cout << "count:grape 不存在" << endl; // 输出:不存在
}
// 3. contains判断(C++20及以上支持,最直观)
#if __cplusplus >= 202002L // 确保编译器支持C++20
if (us.contains("orange")) {
cout << "contains:orange 存在" << endl; // 输出:存在
}
#endif
return 0;
}
六、辅助函数(常用)
除了增删改查,unordered_set 还有一些高频辅助函数:
| 函数 | 功能描述 |
|---|---|
size_t size() |
返回容器中元素的个数。 |
bool empty() |
判断容器是否为空(size()==0)。 |
size_t bucket_count() |
返回哈希表的桶数量。 |
float load_factor() |
返回当前负载因子(size()/bucket_count()),超过最大负载因子(默认 1.0)会触发 rehash。 |
七、注意事项
-
迭代器有效性:
- 插入元素时,若触发
rehash(负载因子超标),所有迭代器、指针、引用都会失效;若未触发 rehash,迭代器仍有效(除被删除元素的迭代器)。 - 删除元素时,仅指向被删除元素的迭代器失效,其他迭代器、指针、引用仍有效。
- 插入元素时,若触发
-
自定义类型支持:
- 若存储自定义类型(如
struct),需手动实现:- 哈希函数(通过特化
std::hash模板); ==运算符(用于哈希冲突时判断元素是否相等)。
- 哈希函数(通过特化
- 若存储自定义类型(如
-
哈希冲突:
- 哈希表通过 “链地址法” 处理冲突,冲突过多会导致查找效率下降(接近 O (n)),可通过
reserve(n)提前预留桶数量,减少 rehash 和冲突。
- 哈希表通过 “链地址法” 处理冲突,冲突过多会导致查找效率下降(接近 O (n)),可通过
通过以上操作,可完整实现 unordered_set 的元素管理,其核心优势是高效的查找和插入,适合无需有序存储、需去重的场景(如统计不重复元素、快速判断元素是否存在)。
unordered_multiset
在 C++ 标准库中,unordered_multiset 是基于哈希表实现的关联容器,核心特性是:元素无序存储、允许重复元素、增删查平均时间复杂度 O (1)(最坏 O (n),取决于哈希冲突)。它与 unordered_set 的唯一区别是支持重复元素,因此在 “增删改遍历” 的实现上,需重点处理 “重复元素” 的场景。
核心特性回顾(关键区别于 unordered_set)
- 允许重复元素:相同值的元素可多次插入,哈希表中会存储多个副本(相同哈希值的元素存于同一 “桶” 中)。
- 元素仍为
const:无法直接修改元素(修改会破坏哈希值,导致查找失效),“改” 需通过 “先删后增” 实现。 - 插入返回值不同:
unordered_set的insert返回pair<iterator, bool>(标记是否插入成功),而unordered_multiset的insert仅返回iterator(因插入一定成功,无需判断重复)。 - 删除行为差异:按值删除时,
unordered_multiset会删除所有相同值的元素,并返回删除个数;unordered_set仅删除 1 个(或 0 个)。
| 操作类型 | 成员函数 / 行为 | std::set(有序不重复) | std::multiset(有序可重复) | std::unordered_set(无序不重复) | std::unordered_multiset(无序可重复) |
|---|---|---|---|---|---|
| 增 | 核心函数:insert(val)emplace(val) |
1. 不允许插入重复元素(重复插入无效) 2. 返回值: pair<iterator, bool>(迭代器指向插入位置 / 已有元素,bool 表示是否成功插入) |
1. 允许插入重复元素(相同值可多次插入) 2. 返回值: iterator(仅指向新插入元素的位置,无 bool 标识) |
1. 不允许插入重复元素(重复插入无效) 2. 返回值: pair<iterator, bool>(逻辑同 set,基于哈希判断重复) |
1. 允许插入重复元素(相同值可多次插入) 2. 返回值: iterator(仅指向新插入元素的位置,无 bool 标识) |
| 特性说明 | 底层红黑树,插入后自动排序,时间复杂度 O (log n) | 底层红黑树,插入后自动排序,时间复杂度 O (log n) | 底层哈希表,插入不排序,平均时间复杂度 O (1),最坏 O (n) | 底层哈希表,插入不排序,平均时间复杂度 O (1),最坏 O (n) | |
| 删 | 1. 按值删:erase(val) |
1. 删除最多 1 个等于 val 的元素(无重复)2. 返回值: size_t(实际删除的元素个数,0 或 1) |
1. 删除所有等于 val 的元素(含重复)2. 返回值: size_t(实际删除的重复元素总数) |
1. 删除最多 1 个等于 val 的元素(无重复)2. 返回值: size_t(0 或 1,基于哈希查找) |
1. 删除所有等于 val 的元素(含重复)2. 返回值: size_t(实际删除的重复元素总数) |
2. 按迭代器删:erase(it) |
1. 删除迭代器 it 指向的单个元素2. 返回值: iterator(指向删除元素的下一个元素)3. 注意:不可删 end() |
1. 删除迭代器 it 指向的单个元素(即使有重复,仅删当前指向的)2. 返回值: iterator(指向删除元素的下一个元素)3. 不可删 end() |
逻辑同 set(仅删当前迭代器指向的单个元素) | 逻辑同 multiset(仅删当前迭代器指向的单个元素) | |
3. 按范围删:erase(it1, it2) |
1. 删除 [it1, it2) 区间内的所有元素2. 返回值: iterator(指向 it2,即区间末尾) |
逻辑同 set(删除区间内所有元素) | 逻辑同 set(删除区间内所有元素) | 逻辑同 set(删除区间内所有元素) | |
| 改 | 直接修改函数 | 无!不支持直接修改元素(会破坏红黑树的有序性) | 无!不支持直接修改元素(会破坏红黑树的有序性) | 无!不支持直接修改元素(会改变元素的哈希值,破坏哈希表结构) | 无!不支持直接修改元素(会改变元素的哈希值,破坏哈希表结构) |
| 间接修改方式 | 1. 先通过 find(val) 找到旧元素的迭代器2. 用 erase(it) 删除旧元素3. 用 insert(new_val) 插入新元素 |
1. 若修改单个重复元素:先定位到目标迭代器(如 find(val) 或 equal_range),删后插新2. 若修改所有重复元素:需遍历删除所有旧值后插新值 |
1. 先通过 find(val) 找到旧元素的迭代器2. 用 erase(it) 删除旧元素3. 用 insert(new_val) 插入新元素 |
1. 若修改单个重复元素:先定位到目标迭代器,删后插新 2. 若修改所有重复元素:遍历删除所有旧值后插新值 |
|
| 查 | 1. 查找元素:find(val) |
1. 返回指向 val 的迭代器;若不存在,返回 end()2. 时间复杂度 O (log n)(红黑树二分查找) |
1. 返回指向第一个等于 val 的元素的迭代器;若不存在,返回 end()2. 时间复杂度 O (log n) |
1. 返回指向 val 的迭代器;若不存在,返回 end()2. 平均时间复杂度 O (1)(哈希查找),最坏 O (n) |
1. 返回指向某一个等于 val 的元素的迭代器(无序,无法保证是第一个);若不存在,返回 end()2. 平均时间复杂度 O (1),最坏 O (n) |
2. 统计个数:count(val) |
1. 返回值:size_t(0 或 1,因无重复)2. 功能等价于 find(val) != end() |
1. 返回值:size_t(等于 val 的元素总个数,支持重复计数)2. 时间复杂度 O (log n + k)(k 为重复个数) |
1. 返回值:size_t(0 或 1,因无重复)2. 平均时间复杂度 O (1) |
1. 返回值:size_t(等于 val 的元素总个数,支持重复计数)2. 平均时间复杂度 O (1 + k)(k 为重复个数) |
|
3. 范围查找:equal_range(val) |
1. 返回 pair<iterator, iterator>(区间 [first, second))2. 若存在 val,区间仅含 1 个元素;若不存在,first == second == end() |
1. 返回 pair<iterator, iterator>(区间包含所有等于 val 的元素)2. 可通过 second - first 计算重复个数 |
1. 返回 pair<iterator, iterator>(区间 [first, second))2. 若存在 val,区间仅含 1 个元素;若不存在,first == second == end() |
1. 返回 pair<iterator, iterator>(区间包含所有等于 val 的元素,无序)2. 可通过 second - first 计算重复个数 |
核心差异总结
- 有序 vs 无序:
set/multiset基于红黑树(有序),unordered_set/unordered_multiset基于哈希表(无序)—— 直接影响插入 / 查找的时间复杂度和遍历顺序。 - 重复 vs 不重复:
set/unordered_set禁止重复元素(insert返回pair标识成功),multiset/unordered_multiset允许重复(insert仅返回迭代器)—— 影响erase(val)的删除个数和count(val)的结果。 - 修改限制:所有四个容器均不支持直接修改元素,需通过 “删旧插新” 间接实现(本质是保护底层结构的完整性)。
unordered_map
unordered_multimap
补充:lower_bound、upper_bound和 equal_range
lower_bound、upper_bound 和 equal_range 是 C++ 有序关联容器(如 set、map、multiset、multimap)提供的范围查找函数,利用容器的有序性高效定位元素。以下通过具体代码示例详细说明它们的用法:
假设有一个按「键(int)」升序排列的 map,存储学生分数与等级的对应关系:
#include <iostream>
#include <map>
#include <string>
int main() {
// 创建并初始化有序map(键为分数,值为等级)
std::map<int, std::string> score_map = {
{60, "D"}, {70, "C"}, {80, "B"}, {90, "A"}, {100, "S"}
};
// 1. lower_bound(key):返回第一个 >= key 的元素迭代器
auto it_low = score_map.lower_bound(80);
if (it_low != score_map.end()) {
std::cout << "lower_bound(80):"
<< it_low->first << " → " << it_low->second << std::endl;
// 输出:80 → B(第一个>=80的元素)
}
// 2. upper_bound(key):返回第一个 > key 的元素迭代器
auto it_high = score_map.upper_bound(80);
if (it_high != score_map.end()) {
std::cout << "upper_bound(80):"
<< it_high->first << " → " << it_high->second << std::endl;
// 输出:90 → A(第一个>80的元素)
}
// 3. equal_range(key):返回包含所有 == key 的元素范围 [first, last)
auto range = score_map.equal_range(80);
std::cout << "equal_range(80) 包含的元素:" << std::endl;
for (auto it = range.first; it != range.second; ++it) {
std::cout << " " << it->first << " → " << it->second << std::endl;
// 输出:80 → B(map中键唯一,因此只有一个元素)
}
return 0;
}
在 multiset 中处理重复键(关键场景)
multiset 允许存储重复键,这三个函数的作用更明显:
#include <iostream>
#include <set>
int main() {
// 创建包含重复元素的有序multiset
std::multiset<int> nums = {3, 1, 4, 1, 5, 9, 2, 6, 5, 3};
// multiset默认按升序排序,实际存储顺序:1,1,2,3,3,4,5,5,6,9
// 1. lower_bound(3):第一个 >=3 的元素
auto it_low = nums.lower_bound(3);
std::cout << "lower_bound(3):" << *it_low << std::endl; // 输出 3
// 2. upper_bound(3):第一个 >3 的元素
auto it_high = nums.upper_bound(3);
std::cout << "upper_bound(3):" << *it_high << std::endl; // 输出 4
// 3. equal_range(3):所有 ==3 的元素范围
auto range = nums.equal_range(3);
std::cout << "equal_range(3) 包含的元素:";
for (auto it = range.first; it != range.second; ++it) {
std::cout << *it << " "; // 输出 3 3(所有等于3的元素)
}
std::cout << std::endl;
return 0;
}
函数返回值的关键说明
-
迭代器范围的含义
[lower_bound(key), upper_bound(key))表示所有 >= key 且 <= key 的元素(即所有== key的元素),与equal_range(key)返回的范围完全一致。- 对于不包含
key的容器,lower_bound和upper_bound会返回同一个迭代器(插入key时的位置)。
-
未找到元素的情况
若容器中所有元素都小于key,三个函数都会返回end()迭代器。
总结
lower_bound(key):找「第一个 >= key」的元素,用于定位范围的起点。upper_bound(key):找「第一个 > key」的元素,用于定位范围的终点。equal_range(key):直接返回所有「== key」的元素范围,等价于pair(lower_bound, upper_bound)。
这三个函数仅适用于有序关联容器(依赖元素的排序特性),时间复杂度均为 O (log n),是处理有序数据范围查询的高效工具。
补充:删除连续的奇数(重要)

补充: pair
在 C++ 中,std::pair 是一个模板类,用于存储两个不同类型的数据作为一个整体,通常用于表示 “键值对” 或 “成对出现的数据”。它定义在 <utility> 头文件中,是关联容器(如 map、unordered_map)的核心组成部分,也广泛用于函数返回多个值等场景。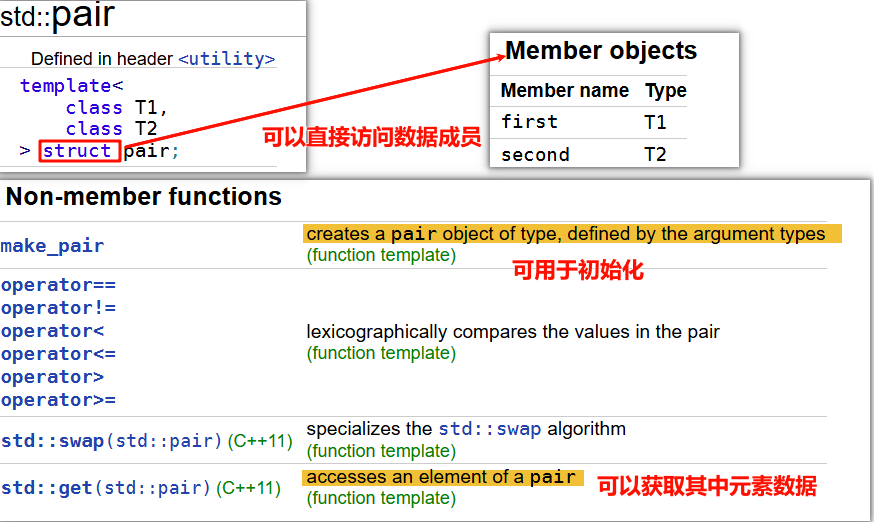
一、std::pair 的基本用法
1. 定义与初始化
#include <iostream>
#include <utility> // 包含pair的头文件
#include <string>
int main() {
// 方式1:默认构造(值初始化)
std::pair<int, std::string> p1; // 第一个元素为int默认值0,第二个为string空串
// 方式2:直接初始化
std::pair<int, std::string> p2(1, "apple"); // 第一个元素1,第二个元素"apple"
// 方式3:使用make_pair(自动推导类型)
auto p3 = std::make_pair(2, "banana"); // 等价于pair<int, string>(2, "banana")
// 方式4:结构化绑定(C++17,便捷访问元素)
auto [num, str] = p2; // num=1,str="apple"
std::cout << num << " " << str << std::endl;
return 0;
}
2. 访问元素
pair 的两个元素通过公有成员 first 和 second 访问:
std::pair<int, double> p(10, 3.14);
std::cout << p.first << std::endl; // 输出第一个元素:10
std::cout << p.second << std::endl; // 输出第二个元素:3.14
3. 赋值与比较
pair 支持赋值和比较操作(按字典序比较):
std::pair<int, std::string> p1(1, "a");
std::pair<int, std::string> p2(2, "b");
p1 = p2; // 赋值:p1变为(2, "b")
// 比较(先比较first,first相等再比较second)
if (p1 < p2) { ... } // 先比较first,若不等则直接返回结果;若first相等,再比较second
二、std::pair 的典型应用场景
1. 作为 map/unordered_map 的元素
关联容器 map 和 unordered_map 的每个元素都是一个 pair,其中 first 是键(key),second 是值(value):
#include <map>
int main() {
std::map<int, std::string> student;
// 插入pair元素
student.insert(std::make_pair(101, "Alice"));
student.insert({102, "Bob"}); // C++11列表初始化
// 遍历map(每个元素是pair)
for (const auto& pair : student) {
std::cout << "学号:" << pair.first << ",姓名:" << pair.second << std::endl;
}
return 0;
}
2. 函数返回多个值
当函数需要返回两个相关值时,pair 是简洁的选择:
// 返回两个整数的和与积
std::pair<int, int> sumAndProduct(int a, int b) {
return {a + b, a * b}; // 返回pair
}
int main() {
auto result = sumAndProduct(3, 4);
std::cout << "和:" << result.first << ",积:" << result.second << std::endl; // 和:7,积:12
return 0;
}
3. 存储二维坐标等成对数据
例如表示二维平面上的点:
using Point = std::pair<int, int>; // 用别名简化
int main() {
Point p(3, 4); // 表示坐标(3,4)
std::cout << "x=" << p.first << ", y=" << p.second << std::endl;
return 0;
}
三、std::pair 的扩展:std::tuple
如果需要存储两个以上不同类型的数据,可以使用 std::tuple(定义在 <tuple> 头文件中),它是 pair 的泛化版本:
#include <tuple>
#include <string>
int main() {
// 存储三个元素:int、string、double
std::tuple<int, std::string, double> t(1, "hello", 3.14);
// 访问元素(需指定索引,从0开始)
std::cout << std::get<0>(t) << std::endl; // 1
std::cout << std::get<1>(t) << std::endl; // "hello"
return 0;
}
总结
std::pair用于封装两个不同类型的数据,是 C++ 中处理 “成对数据” 的基础工具。- 核心成员
first和second用于访问两个元素。 - 广泛应用于关联容器(
map等)、函数多返回值、坐标存储等场景。 - 若需存储两个以上数据,可使用
std::tuple。
补充:比较器的重载
#include <iostream>
#include <set>
#include <string>
using namespace std;
// 显示容器内容的模板函数
template <typename Container>
void display(const Container &con) {
for (const auto &elem : con) {
cout << elem << " ";
}
cout << endl;
}
// 学生类
class Student {
public:
Student(const string &name, int id, double score)
: _name(name), _id(id), _score(score) {}
string getName() const { return _name; }
int getId() const { return _id; }
double getScore() const { return _score; }
// 友元声明
friend ostream &operator<<(ostream &os, const Student &s);
friend bool operator<(const Student &lhs, const Student &rhs);
friend struct CompareByScore;
private:
string _name; // 姓名
int _id; // 学号
double _score; // 成绩
};
// 输出运算符重载
ostream &operator<<(ostream &os, const Student &s) {
os << "(" << s._name << ", " << s._id << ", " << s._score << ")";
return os;
}
// 1. 运算符重载方式的比较器:按学号比较
bool operator<(const Student &lhs, const Student &rhs) {
cout << "使用 operator< 比较" << endl;
return lhs._id < rhs._id;
}
// 2. 函数对象方式的比较器:按成绩比较
struct CompareByScore {
bool operator()(const Student &lhs, const Student &rhs) const {
cout << "使用 CompareByScore 比较" << endl;
if (lhs._score != rhs._score) {
return lhs._score < rhs._score;
}
// 成绩相同则按学号比较
return lhs._id < rhs._id;
}
};
// 3. std::less 模板特化方式的比较器:按姓名比较
namespace std {
template <>
struct less<Student> {
bool operator()(const Student &lhs, const Student &rhs) const {
cout << "使用 std::less<Student> 比较" << endl;
if (lhs.getName() != rhs.getName()) {
return lhs.getName() < rhs.getName();
}
// 姓名相同则按学号比较
return lhs.getId() < rhs.getId();
}
};
}
// 测试三种比较器
void testOperatorLess() {
cout << "\n--- 使用 operator< 比较 (按学号) ---" << endl;
set<Student> students = {
Student("Alice", 102, 85.5),
Student("Bob", 101, 92.0),
Student("Charlie", 103, 78.5)
};
display(students);
}
void testCompareByScore() {
cout << "\n--- 使用 CompareByScore 比较 (按成绩) ---" << endl;
set<Student, CompareByScore> students = {
Student("Alice", 102, 85.5),
Student("Bob", 101, 92.0),
Student("Charlie", 103, 78.5)
};
display(students);
}
void testStdLessSpecialization() {
cout << "\n--- 使用 std::less<Student> 比较 (按姓名) ---" << endl;
set<Student, less<Student>> students = {
Student("Alice", 102, 85.5),
Student("Bob", 101, 92.0),
Student("Charlie", 103, 78.5)
};
display(students);
}
int main() {
testOperatorLess();
testCompareByScore();
testStdLessSpecialization();
return 0;
}
三种比较器的使用方式:
-
运算符重载方式(operator<):
- 按学号(_id)进行比较
- 当使用 set<Student>时会自动调用这个比较器
- 输出中会显示 "使用 operator< 比较"
-
函数对象方式(CompareByScore):
- 主要按成绩(_score)进行比较
- 成绩相同时按学号进行二次比较
- 使用时需要在容器声明中指定:set<Student, CompareByScore>
- 输出中会显示 "使用 CompareByScore 比较"
-
std::less 模板特化方式:
- 主要按姓名(_name)进行比较
- 姓名相同时按学号进行二次比较
- 使用时需要在容器声明中指定:set<Student, less<Student>>
- 输出中会显示 " 使用 std::less<Student> 比较 "
强排序和弱排序
std::sort() 使用强排序比较器
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
// 强排序比较器(同时满足严格弱排序)
struct StrongCompare {
bool operator()(const std::string& a, const std::string& b) const {
// 先按长度,再按内容,确保任何两个元素都能明确区分
if (a.length() != b.length()) {
return a.length() < b.length();
}
return a < b; // 内容比较是强排序
}
};
int main() {
std::vector<std::string> words = {"banana", "apple", "grape", "mango"};
// 使用强排序比较器调用 sort()
std::sort(words.begin(), words.end(), StrongCompare());
// 输出排序结果:apple grape mango banana
for (const auto& w : words) {
std::cout << w << " ";
}
return 0;
}std::sort() 使用弱排序比较器
#include <iostream>
#include <vector>
#include <algorithm>
#include <string>
// 弱排序比较器(仅按字符串长度排序,允许等价元素)
struct WeakCompare {
bool operator()(const std::string& a, const std::string& b) const {
return a.length() < b.length(); // 只比较长度,不关心内容
}
};
int main() {
std::vector<std::string> words = {"banana", "apple", "grape", "mango", "pear"};
// 使用弱排序比较器调用 sort()
std::sort(words.begin(), words.end(), WeakCompare());
// 输出排序结果(按长度分组,组内顺序不确定):
// pear(4) apple(5) grape(5) mango(5) banana(6)
for (const auto& w : words) {
std::cout << w << "(" << w.length() << ") ";
}
return 0;
}弱排序的核心是定义等价关系
弱排序最常见于 C++ 关联容器(如 set、multiset),用于定义元素的存储顺序和 “唯一性”:
- 在
set中,等价元素会被视为 “相同”,因此无法插入重复的等价元素(如 “apple” 和 “grape” 在按长度排序的set中只能存一个)。 - 在
multiset中,等价元素会被允许并存,但会被相邻存储(如多个长度为 5 的字符串会放在一起)。
弱排序分两种
- 严格弱排序:
comp(a,a)必须返回false(元素不能 “小于” 自身,不可反); - 非严格弱排序:
comp(a,a)必须返回true(元素 “小于等于” 自身,自反)。
简单说:强排序是弱排序的 “升级版”(满足更多约束),因此所有支持弱排序的场景都能兼容强排序,但反之则不成立。
弱排序的核心局限是无法区分 “等价但不相等” 的元素,因此在以下场景中不能使用:
- 需要精确定位严格相等的元素(如精确查找)
- 元素唯一性依赖全部属性(而非部分排序键)
- 算法逻辑依赖元素自身
==的传递性 - 要求等价元素保持原始顺序
这些场景必须使用强排序,或在弱排序基础上额外增加判断逻辑(如显式比较==)才能正确工作。
补充:迭代器
| 迭代器类型 | 核心能力 | 支持的关键操作 | 适用容器举例 |
|---|---|---|---|
| 1. 输入迭代器 | 只读、单向遍历(仅支持 ++),只能遍历一次 |
++(前置 / 后置)、*(读元素)、!=/==(比较)、->(访问成员) |
istream_iterator(输入流)、unordered_map 的 begin()(部分场景) |
| 2. 输出迭代器 | 只写、单向遍历(仅支持 ++),只能遍历一次 |
++(前置 / 后置)、*(写元素) |
ostream_iterator(输出流)、back_inserter(插入迭代器) |
| 3. 前向迭代器 | 可读可写、单向遍历(支持 ++),可重复遍历 |
继承输入 / 输出迭代器的所有操作,支持多次遍历同一范围 | forward_list(单向链表)、unordered_set/unordered_map |
| 4. 双向迭代器 | 可读可写、双向遍历(支持 ++ 和 --),可重复遍历 |
继承前向迭代器的所有操作,新增 --(前置 / 后置) |
list(双向链表)、set/map(红黑树)、deque(部分操作) |
| 5. 随机访问迭代器 | 可读可写、随机访问(支持 ++/--、+n/-n、[]),效率与指针相当 |
继承双向迭代器的所有操作,新增 it + n、it - n、it1 - it2(计算距离)、[](随机访问) |
vector、string、deque(首尾外的迭代器)、array |
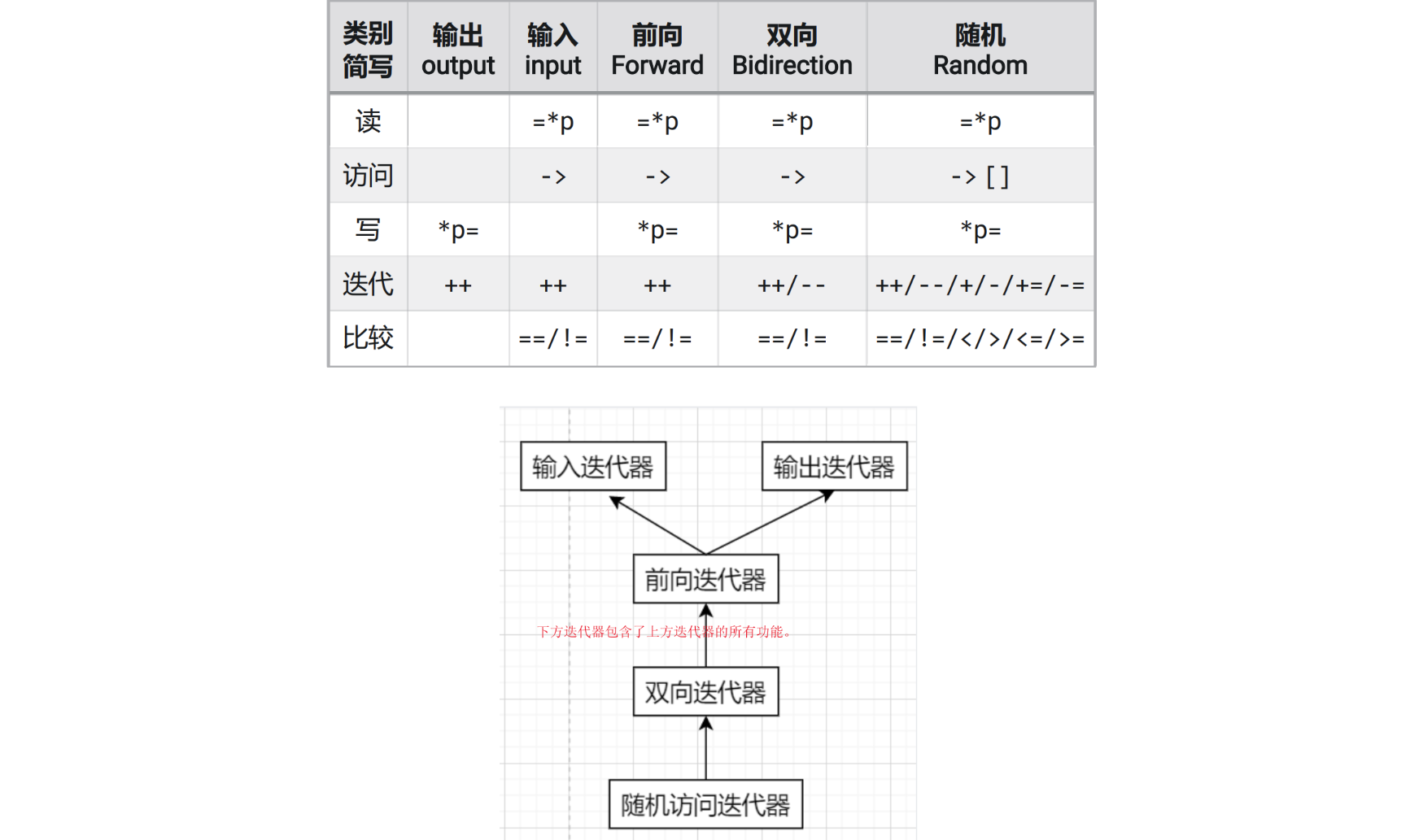
关键对比:各类迭代器的能力边界
- 单向 vs 双向:输入 / 输出 / 前向迭代器只能 “往前” 走(
++),双向迭代器还能 “往后” 走(--); - 随机访问:只有随机访问迭代器支持 “跳步访问”(如
it + 5直接访问第 5 个元素),其他迭代器必须逐个遍历; - 读写权限:输入迭代器只能读,输出迭代器只能写,前向 / 双向 / 随机访问迭代器支持读写(除非是
const迭代器)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)