【LeetCodeHot100】-解题记录
总体思路就是先用一个哈希表存储所有数值,然后对于其中每个元素,当他的前一个不存在的时候(说明是长序列起点)就开始检索,寻找这个序列的后面的值,直到找到这个点开始的序列的终点。首先需要确定采用哈希表来进行数组的存储,接着确定数据结构,下一步就是哈希表中HashFunction、creatHasnTabble、insert、is_contain等核心功能模块的功能编写测试。题目4:【双指针】 移动零
题目1:【哈希表】两数之和
2.14完成
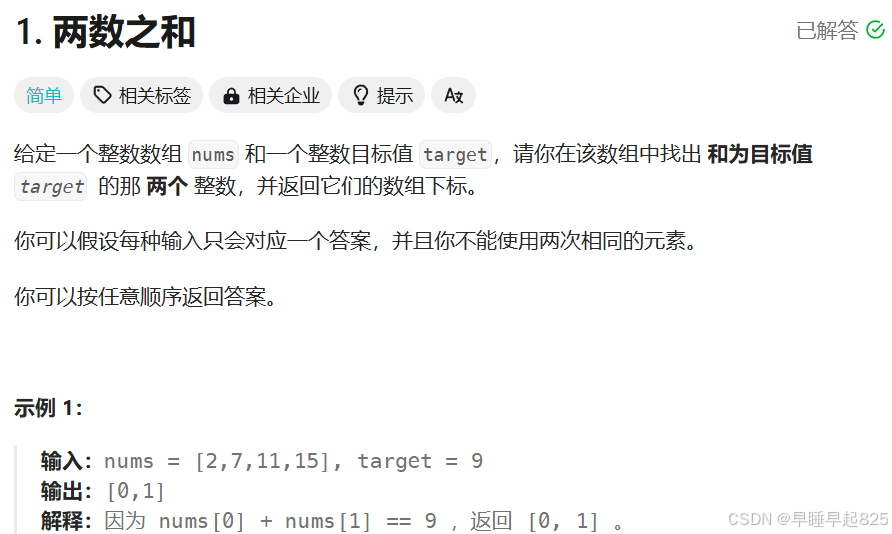
题目2:【哈希表】字母异位词分组
3.3完成

2.1代码阅读:kimi:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_WORDS 1000
#define MAX_WORD_LENGTH 100
// 比较函数,用于排序
int compare_chars(const void* a, const void* b) {
return *(char*)a - *(char*)b;
}
// 主函数
char*** groupAnagrams(char** strs, int strsSize, int* returnSize, int** returnColumnSizes) {
// 使用哈希表存储结果
char* sortedStrs[MAX_WORDS];
char*** result = (char***)malloc(MAX_WORDS * sizeof(char**));
int resultSize = 0; //这个变量用于记录 result 数组中实际存储了多少个分组。初始值为 0,随着程序的执行,每当向 result 添加一个新的分组时,这个值会增加。
int resultColSizes[MAX_WORDS] = {0}; //这是一个整型数组,大小为 MAX_WORDS,所有元素初始化为 0。
for (int i = 0; i < strsSize; i++) {
// 创建一个临时字符串并排序
char temp[MAX_WORD_LENGTH];
strcpy(temp, strs[i]);
qsort(temp, strlen(temp), sizeof(char), compare_chars);
// 检查是否已经存在相同的排序字符串
int found = 0;
for (int j = 0; j < resultSize; j++) {
if (strcmp(sortedStrs[j], temp) == 0) {
// 找到相同的排序字符串,将当前单词加入该组
result[j][resultColSizes[j]++] = strs[i];
found = 1;
break;
}
}
// 如果没有找到,创建新的组
if (!found) {
sortedStrs[resultSize] = strdup(temp); // 保存排序后的字符串
result[resultSize] = (char**)malloc(MAX_WORDS * sizeof(char*));
result[resultSize][resultColSizes[resultSize]++] = strs[i];
resultSize++;
}
}
// 设置返回值
*returnSize = resultSize;
*returnColumnSizes = resultColSizes;
return result;
}
int main() {
char* strs[] = {"eat", "tea", "tan", "ate", "nat", "bat"};
int strsSize = sizeof(strs) / sizeof(strs[0]);
int returnSize = 0;
int* returnColumnSizes = NULL;
char*** result = groupAnagrams(strs, strsSize, &returnSize, &returnColumnSizes);
// 打印结果
for (int i = 0; i < returnSize; i++) {
for (int j = 0; j < returnColumnSizes[i]; j++) {
printf("%s ", result[i][j]);
}
printf("\n");
}
// 释放内存
for (int i = 0; i < returnSize; i++) {
free(result[i]);
}
free(result);
return 0;
}ref:在思考算法的时候,我认为第一步可以从数据结构入手,比如用什么结构的数据存储返回值跟输入?char* 还是char**还是char***?
流程梳理:
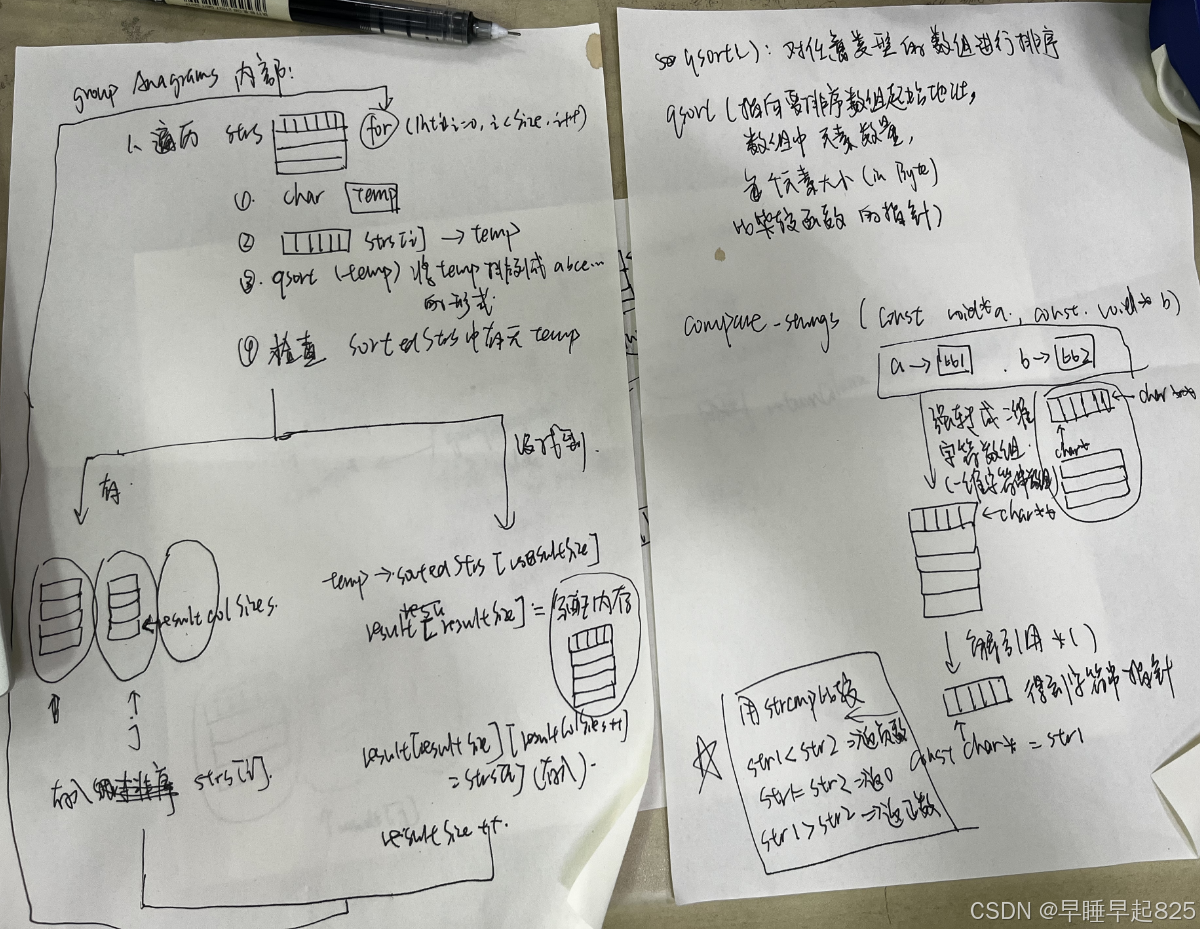
2.2知识点:
1、主函数的char***的含义
char*:表示一个指向字符的指针,通常用于表示一个字符串(以空字符 \0 结尾的字符数组)。char**:表示一个指向指针的指针。在这种情况下,它通常用于表示一个字符串数组,即每个元素是一个字符串(char*)。
char***:表示一个指向指针的指针的指针。在这里,它用于表示一个二维字符串数组,即每个元素是一个字符串数组(char**)。
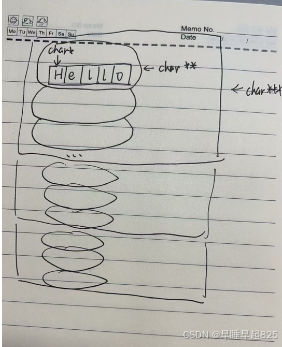
这个函数的返回值是一个二维数组的数组(三维数组)
2、qsort函数:
qsort 的函数原型定义在 <stdlib.h> 头文件中,具体如下:
void qsort(void* base, size_t nitems, size_t size, int (*compar)(const void*, const void*));参数说明
base:指向要排序的数组的起始地址。nitems:数组中元素的数量。size:每个数组元素的大小(以字节为单位)。compar:比较函数的指针,用于定义排序的规则。比较函数的原型必须是:
int compar(const void* a, const void* b);-
返回值:
-
如果
a应该排在b前面,返回负值。 -
如果
a和b相等,返回 0。 -
如果
a应该排在b后面,返回正值。
-
函数功能:将数组中的数字按照abcd..的顺序重新排列
3、函数指针
函数指针是C语言和C++语言中一个非常强大的特性,它允许我们将函数的地址赋给一个指针变量,并通过这个指针变量调用函数。以下是对函数指针的详细讲解:
(1). 什么是函数指针?*在C语言和C++中,函数也有地址,就像变量有地址一样。函数指针就是一个指向函数的指针变量,它存储的是函数的入口地址。通过函数指针,我们可以像调用普通函数一样调用它所指向的函数。
(2)函数指针的声明
函数指针的声明需要明确以下几点:
- 函数的返回类型。
- 函数的参数类型和数量。
- 函数指针的名称。
返回类型 (*指针变量名)(参数类型列表);(3)函数指针的赋值
函数指针可以通过函数名直接赋值,函数名在不加括号时代表函数的地址。例如:
int add(int a, int b) {
return a + b;
}
int main() {
int (*func_ptr)(int, int); // 声明函数指针
func_ptr = add; // 将函数add的地址赋给函数指针
return 0;
}(4) 通过函数指针调用函数
函数指针可以通过解引用操作符*或者直接通过指针名调用函数。例如:
int main() {
int (*func_ptr)(int, int); // 声明函数指针
func_ptr = add; // 将函数add的地址赋给函数指针
int result = func_ptr(3, 4); // 调用函数指针指向的函数
printf("Result: %d\n", result); // 输出结果
return 0;
}4、数组、指针以及后缀递增运算符的结合 result[j][resultColSizes[j]++] = strs[i];
resultColSizes[j]++
-
这是一个后缀递增运算符,它的作用是先使用
resultColSizes[j]的当前值,然后将resultColSizes[j]的值增加1。 -
在这行代码中,
resultColSizes[j]++表示先获取当前第j个分组中的字符串数量,然后将这个数量增加1,以记录新添加的字符串。
result[j][resultColSizes[j]++]
-
这部分代码表示访问
result数组的第j个元素(一个二级指针),然后访问这个二级指针指向的字符串数组的第resultColSizes[j]个位置。 -
由于
resultColSizes[j]在使用后会增加1,所以这实际上是在第j个分组的字符串数组的末尾添加一个新的字符串。
result[j][resultColSizes[j]++] = strs[i];
-
这行代码的完整含义是:将
strs数组的第i个元素(一个字符串)赋值给result数组的第j个元素(一个二级指针)指向的字符串数组的第resultColSizes[j]个位置,然后增加resultColSizes[j]的值以记录新添加的字符串。
2.3报错调试
1 、内存空间报错:
Line 100:
=================================================================
==22==ERROR: AddressSanitizer: stack-use-after-return on address 0x7f3b93100030 at pc 0x5645a0e7815f bp 0x7ffe4db594e0 sp 0x7ffe4db594d0
READ of size 4 at 0x7f3b93100030 thread T0
#0 0x5645a0e7815e in _serialize_2d_array /leetcode/__Serializer__.c:241
#1 0x5645a0e71fdf in main solution.c:100
#2 0x7f3b94b811c9 (/lib/x86_64-linux-gnu/libc.so.6+0x2a1c9) (BuildId: 6d64b17fbac799e68da7ebd9985ddf9b5cb375e6)
#3 0x7f3b94b8128a in __libc_start_main (/lib/x86_64-linux-gnu/libc.so.6+0x2a28a) (BuildId: 6d64b17fbac799e68da7ebd9985ddf9b5cb375e6)
#4 0x5645a0e72434 in _start (solution+0x1f434) (BuildId: fcc653782ae4d4a022735b7189662f1fb5aec281)
Address 0x7f3b93100030 is located in stack of thread T0 at offset 48 in frame
#0 0x5645a0e7258f in groupAnagrams solution.c:100
This frame has 3 object(s):
[48, 4048) 'resultColSizes' (line 22) <== Memory access at offset 48 is inside this variable
[4176, 12176) 'sortedStrs' (line 19)
[12432, 12532) 'temp' (line 26)
HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork
(longjmp and C++ exceptions *are* supported)
SUMMARY: AddressSanitizer: stack-use-after-return /leetcode/__Serializer__.c:241 in _serialize_2d_array
Shadow bytes around the buggy address:
0x7f3b930ffd80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7f3b930ffe00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7f3b930ffe80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7f3b930fff00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7f3b930fff80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x7f3b93100000: f5 f5 f5 f5 f5 f5[f5]f5 f5 f5 f5 f5 f5 f5 f5 f5
0x7f3b93100080: f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5
0x7f3b93100100: f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5
0x7f3b93100180: f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5
0x7f3b93100200: f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5
0x7f3b93100280: f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 f5 ... 640 more charskimi问题分析:
从你提供的代码和 AddressSanitizer 的错误信息来看,问题出在 resultColSizes 的使用上。resultColSizes 是一个局部数组,存储在栈上,而你试图通过指针将其传递给调用者。当 groupAnagrams 函数返回后,resultColSizes 的内存空间可能被回收或覆盖,导致调用者访问到无效的内存。
kimi修改方法:
为了修复这个问题,需要将 resultColSizes 的存储方式从栈改为动态分配的内存(堆)。这样可以确保它在函数返回后仍然有效。以下是修改后的代码:
int* resultColSizes = (int*)malloc(MAX_WORDS * sizeof(int)); // 动态分配内存
memset(resultColSizes, 0, MAX_WORDS * sizeof(int)); // 初始化为 0kimi修改后没有报错,顺利提交。
我的问题分析:
kimi说我的resultColSizes存在问题,说:“函数返回后,resultColSizes 的内存空间可能被回收或覆盖,导致调用者访问到无效的内存。”,但是我检查发现我并没有在函数外调用resultColSizes这个数组,那怎么存在其内存被回收导致出错呢?
后面查阅资料感觉可能是其他内存问题导致的混淆,虽然 AddressSanitizer 报告了 stack-use-after-return,但实际问题可能出在其他地方。例如:
-
数组越界:
resultColSizes[j]的访问可能超出了其分配的范围。 -
未初始化的指针:
result[j]或其他指针可能未正确初始化。
因此我将两个max变量调大了,这次就没有报错了:
#define MAX_WORDS 10000 // 扩大十倍
#define MAX_WORD_LENGTH 1000 // 扩大十倍
ref:但是执行时间还是很长,后续有时间更新优化后的结果。
题目3:【哈希表】最长连续序列
用时:
完成日期:

3.2 知识点:
3.2.1 free()
在C语言中,free 函数是标准库 <stdlib.h> 中提供的一个函数,用于释放动态分配的内存。它的原型定义如下:
c复制
void free(void* ptr);释放内存
3.2.2 malloc()
以下是一个使用 malloc 的示例代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
// 分配一块可以存储5个int的内存
int* ptr = (int*)malloc(5 * sizeof(int));
// 注意:在C语言中,强制类型转换是可选的
// sizeof的返回值的单位是字节分配内存,返回一个指针。
3.3 代码实现以及调试
3.3.1 insert模块编写及测试
(1)分配内存时出错: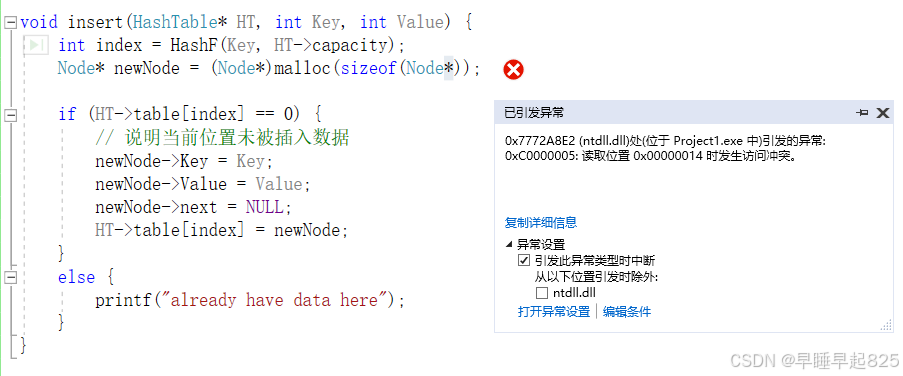
问题所在
在 insert 函数中,您为 newNode 分配内存的语句有误:
Node* newNode = (Node*)malloc(sizeof(Node*));这里您使用的是 sizeof(Node*),它计算的是指针的大小,而不是 Node 结构体的大小。在32位系统上,指针通常占用4字节,而在64位系统上,指针占用8字节。您应该使用 sizeof(Node) 来确保为整个结构体分配足够的内存。
修正代码
将 insert 函数中的内存分配语句修改为:
Node* newNode = (Node*)malloc(sizeof(Node));这样,您就为整个 Node 结构体分配了足够的内存。
最终代码:
#include <stdio.h>
#include <stdlib.h>
#define CAPACITY 1000
//定义数据结构 Node 以及 HashTable
typedef struct {
int Key;
int Value;
struct Node* next;// 这里用Node* next也可以,但是实际开发推荐使用struct Node* 的写法
}Node;
typedef struct {
Node** table;
int capacity;
}HashTable;
int HashF(int Key,int capacity) {
return (Key % capacity + capacity) % capacity;// 这个hash函数可以区分输入的正数跟负数 -1 -->> 999;1-->>1;
}
HashTable* creatHT(int size) {
//分配空间给哈希表
HashTable* HT = (HashTable*)malloc(sizeof(HashTable));
//初始化
HT->capacity = size;
//这里的Node**说明返回的这块内存用于存放一个节点指针的数组
HT->table = (Node**)calloc(size, sizeof(Node*));
return HT;
}
void insert(HashTable* HT, int Key, int Value) {
int index = HashF(Key, HT->capacity);
Node* newNode = (Node*)malloc(sizeof(Node));
//初始化结构体
newNode->next = NULL;
if (newNode == NULL) { printf("allocate memeory fail"); };
if (HT->table[index] == 0) {
// 说明当前位置未被插入数据
newNode->Key = Key;
newNode->Value = Value;
newNode->next = NULL;
HT->table[index] = newNode;
}
else {
printf("already have data here");
}
}
int is_contain(HashTable* HT, int Key) {
// 查找哈希表中是否有某个元素
int index = HashF(Key, HT->capacity);
if (HT->table[index]->Key == Key) {
return 1;
}
else {
return 0;
}
}
int longestConsecutive(int* nums, int numsSize) {
HashTable* ht = creatHT(CAPACITY);
int result = 0;
for (int i = 0; i < numsSize; i++) {
//将nums中的数据全部存入hash表
insert(ht, i, nums[i]);
//printf("%d\n", ht->table[HashF(i, CAPACITY)]->Value);
//int have_or_not = is_contain(ht, i, nums[i]);
//printf("%d\n", have_or_not); //测试 is_contain
}
for (int i = 0; i < numsSize; i++) {
//遍历nums数组,只处理其中为起点的点
if (is_contain(ht, nums[i]-1)) {
int CurrentNum = nums[i];
int CurrentLength = 1;
while (is_contain(ht, nums[i] + 1)) {CurrentLength++;};
if (CurrentLength >= result) { result = CurrentLength; };
}
}
}
int main() {
int nums[] = { 100,4,200,1,3,2 };
int numsSize = sizeof(nums) / sizeof(int);
int result = longestConsecutive(nums, numsSize);
//printf("%d\n", ht->table[HashF(1,CAPACITY)]->Value);
//printf("%d\n",is_contain(ht,1,10));
printf("%d\n", result);
return 0;
}3.4 思路总结:
总体思路就是先用一个哈希表存储所有数值,然后对于其中每个元素,当他的前一个不存在的时候(说明是长序列起点)就开始检索,寻找这个序列的后面的值,直到找到这个点开始的序列的终点。
首先需要确定采用哈希表来进行数组的存储,接着确定数据结构,下一步就是哈希表中HashFunction、creatHasnTabble、insert、is_contain等核心功能模块的功能编写测试。
题目4:【双指针】 移动零 (快慢指针)
完成时间: 3.7

4.1 解题思路:
1、不复制数组对数组操作是什么意思?
“必须在不复制数组的情况下原地对数组进行操作”是指:
-
原地操作 (In-place):
你只能直接在输入的原始数组上修改元素,不能创建新的数组来存储结果。这意味着:- ✅ 允许:通过交换、覆盖、删除等方式修改原数组。
- ❌ 禁止:新建一个数组,将处理后的结果存入新数组,再让原数组指向新数组(本质是复制)。
-
空间复杂度要求:
算法的额外空间复杂度需为 O(1)(常数级别),例如只允许使用有限的临时变量,不能使用与输入数组规模成比例的额外空间。
4.2 代码:
void moveZeroes(int* nums, int numsSize) {
int slow = 0;
for (int i = 0; i < numsSize; i++) {
// 利用快慢指针记录数组非零元组,这里面的i是快指针
if (nums[i] != 0) {
nums[slow] = nums[i];
slow++;
}
}
for (slow; slow < numsSize; slow++) {
nums[slow] = 0;
}
//for (int i = 0; i < numsSize; i++) {
// printf("%d\n", nums[i]);
//}
}4.3 关于快慢指针的总结
如果需要实现数组的原地操作,以期占用更小的内存,就可以用到快慢指针,就是在对数组进行遍历的时候(假设遍历变量为i),再定义一个慢指针,其遍历速度慢于或等于i,即可完成对数组的原地操作,而不用再新创建一个数组来存储运算结果。
快慢指针一定要满足:快指针移动速度一定大于或等于慢指针
题目5:【双指针】盛最多水的容器(难)
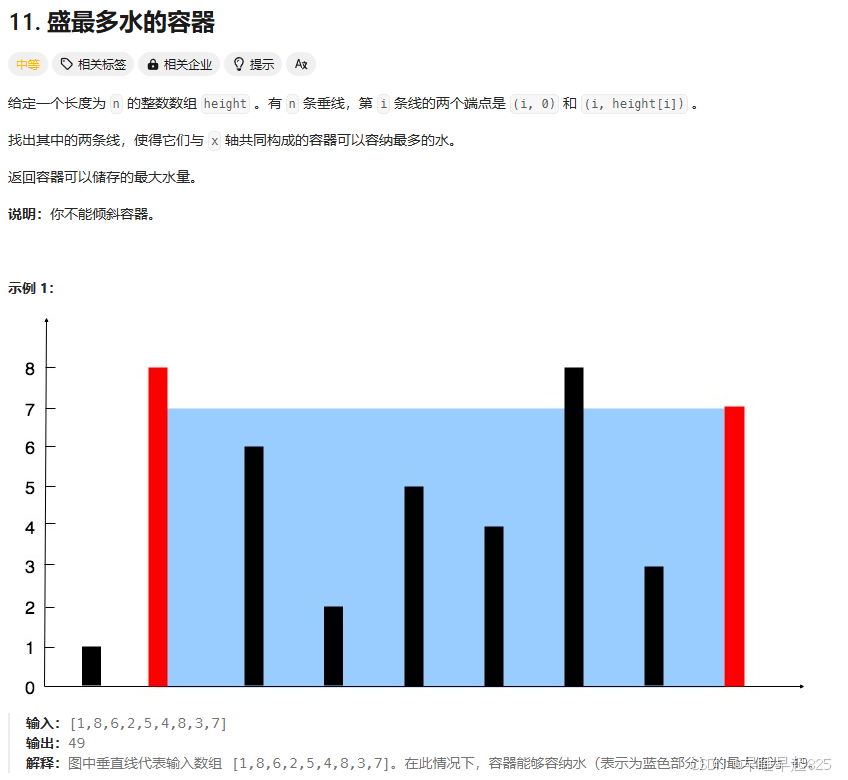
5.1 解题思路:
双指针运动的逻辑是矮柱移动,那么任意时刻的双指针的外侧(左指针的左侧以及右指针的右侧)一定都曾经作为矮柱被计算过,并且在其被计算的时候高柱一定在外侧。通过遍历可以使得所有的柱子(除了最高的)都作为矮柱被计算一次,并且都找到其作为矮柱时的最优解。

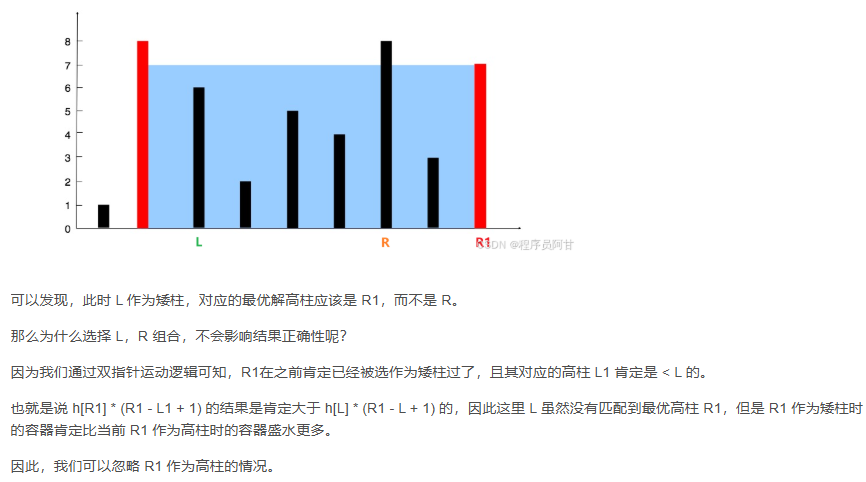
上面图片from:LeetCode - 11 盛最多水的容器_leetcode盛水最多的容器-CSDN博客
5.2 代码
#include <stdio.h>
#include <stdlib.h>
int maxArea(int* nums, int numsSize) {
//利用左右双指针往中间遍历来寻找最大值
int left = 0;
int right = numsSize - 1;
int MaxWater = 0;
int CurrentWater = 0;
//确定迭代条件
while (left < right) {
//计算水量
if (nums[left] < nums[right]) {
CurrentWater = (right - left)*nums[left];
left++;
}
else {
CurrentWater = (right - left)*nums[right];
right--;
}
printf("%d\n", CurrentWater);
if (CurrentWater >= MaxWater) {
MaxWater = CurrentWater;
}
}
return MaxWater;
}
int main() {
int nums[] = { 2,6,8,9,1,4,10 };
int result = maxArea(nums, 7);
printf("%d\n", result);
return 0;
}题目6:【双指针】三数之和
6.1解题思路
用双指针来完成题目,首先通过循环遍历固定一个数字(需要记得设置跳过重复数字的条件),接着用双指针从数组的两头向中间遍历,设置sum变量记录三数字之和,以0为基准,若sum小于0,则移动left指针;若sum大于0,移动right指针。
6.2最终代码实现
#include <stdio.h>
#include <stdlib.h>
#define RESULT_MAX_SIZE 10
// 比较函数,用于qsort排序
int compare(const void *a, const void *b) {
return (*(int *)a - *(int *)b);
}
int** threeSum(int* nums, int numsSize) {
printf("sizeof input is : %d\n", numsSize);
qsort(nums, numsSize, sizeof(int), compare);
int ** result = (int**)calloc(RESULT_MAX_SIZE, sizeof(int*));
int resultSize = 0;
//通过遍历数组,固定一个元素
for (int i = 0; i < numsSize - 1; i++) {
//跳过相同的数字
if (i < numsSize - 1 && nums[i] == nums[i + 1]) {
printf("skip nums :%d\n", nums[i]);
continue;
}
printf("current processing : %d\n", nums[i]);
//双指针从头尾开始遍历数组 并且记得设置跳过i这个位置
int left = 0;
int right = numsSize - 1;
while (left < right) {
int sum = nums[i] + nums[left] + nums[right];
printf("current sum :%d\n",sum);
if (sum == 0) {
//将找到的三元组存入
result[resultSize] = (int*)calloc(3, sizeof(int));
result[resultSize][0] = nums[i];
result[resultSize][1] = nums[left];
result[resultSize][2] = nums[right];
resultSize++;
i++;
}
if(sum < 0) {
left++;
}
if (sum > 0) {
right--;
}
}
}
// 展示结果
for (int j = 0; j < resultSize - 1; j++) {
printf("result[%d]: %d,%d,%d \n", j, result[j][0], result[j][1], result[j][2]);
}
return result;
}
int main() {
int nums1[] = { -2,-1,-2,-3,0,1,2,3,4,5 };
int nums1Size = sizeof(nums1) / sizeof(int);
threeSum(nums1, nums1Size);
return 0;
}6.3 问题记录
报错1【分配内存错误】:访问内存冲突,0x00B15065 处(位于 Project1.exe 中)引发的异常: 0xC0000005: 写入位置 0x00000000 时发生访问冲突。
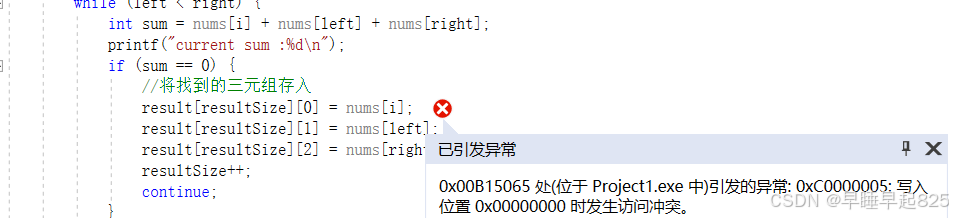
错误定位:calloc分配内存的时候把数据类型强转成了(int*),但其实需要的是int**,所以修改为int ** result = (int**)calloc(RESULT_MAX_SIZE, sizeof(int*));即可
//以下是错误修改前的代码
int** threeSum(int* nums, int numsSize) {
printf("sizeof input is : %d\n", numsSize);
qsort(nums, numsSize, sizeof(int), compare);
int ** result = (int*)calloc(RESULT_MAX_SIZE, sizeof(int*));
int resultSize = 0;
...报错1-新报错1:修改完calloc分配内存类型后仍有报错
错误定位:未初始化指针数组:calloc只是分配了result数组的空间,但并没有为每个result[i]分配内存。需要在每次存储结果之前为每个result[i]分配一个大小为3的int数组,因为每个三元组需要存储3个整数。添加如下代码:
result[resultSize] = (int*)calloc(3, sizeof(int));
//以下是错误修改后的代码:
while (left < right) {
int sum = nums[i] + nums[left] + nums[right];
printf("current sum :%d\n",sum);
if (sum == 0) {
//将找到的三元组存入
result[resultSize] = (int*)calloc(3, sizeof(int));
result[resultSize][0] = nums[i];
result[resultSize][1] = nums[left];
result[resultSize][2] = nums[right];
resultSize++;
i++;
}
if(sum < 0) {
left++;
}
if (sum > 0) {
right--;
}
}题目7:【双指针】接雨水
7.1 解题思路1双指针
由题目5的总结我们可以知道,双指针接水问题其实本质上是通过遍历使得每个柱子(除了最高柱子)都充当一遍矮柱子,同时指针移动的过程中当前双指针的外侧一定都充当过矮柱子参与过计算。
所以这道题就要在这个基础上进行算法设计。需要在指针移动的过程中对矮柱当前点的积水量进行计算,同时还需要维护左右两侧局部最值两个变量(left_max与right_max)

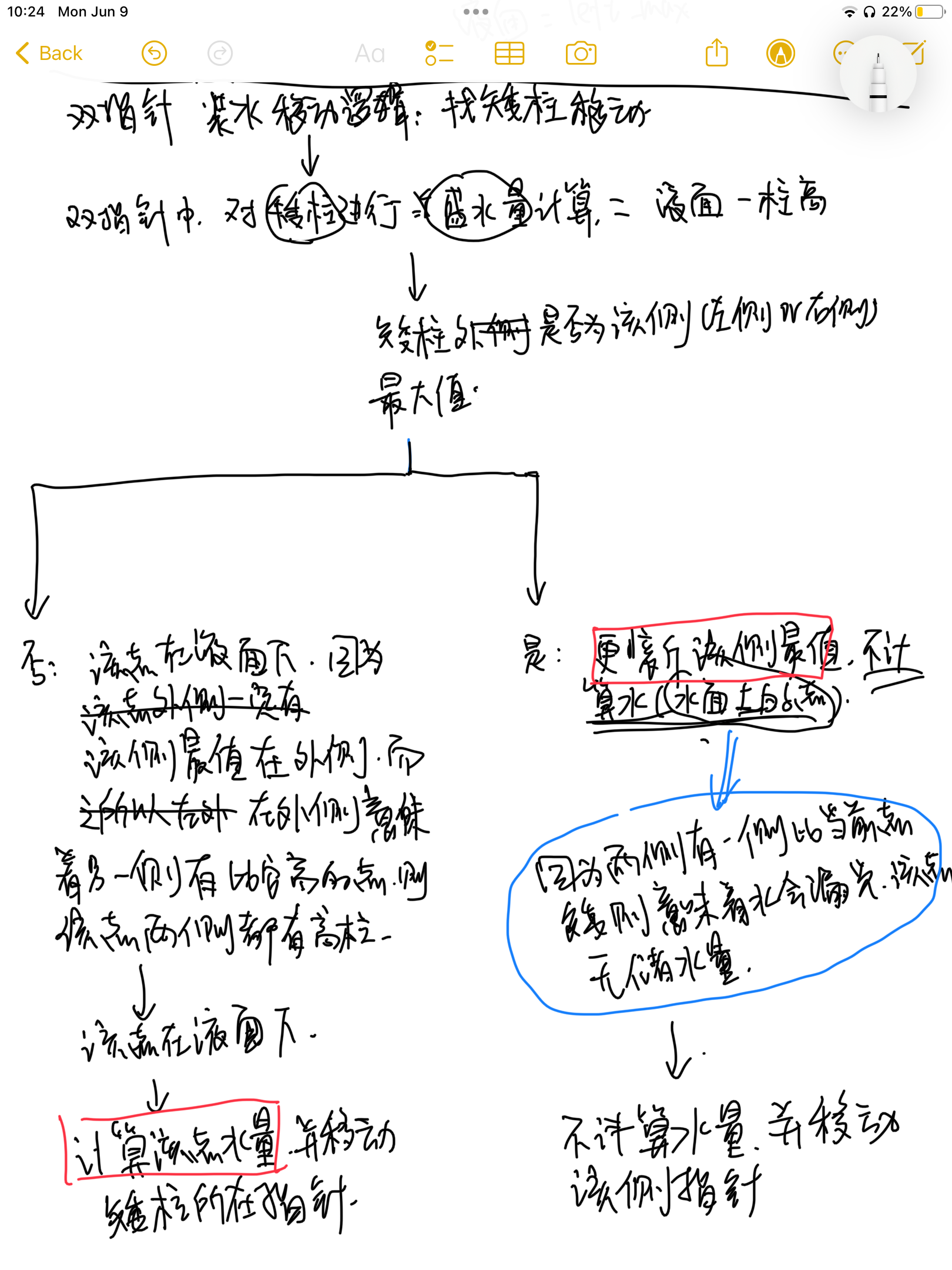
7.2 最终代码实现1
class Solution {
public:
int trap(vector<int>& height) {
int left = 0, right = height.size() - 1;
int left_max = 0;
int right_max = 0;
int result = 0;
while(left<right){
if(height[left]<height[right]){
// 说明左侧是矮柱
if(height[left]>left_max){
//更新该侧最大值,不计算水量
left_max = height[left];
}else{
//该点位于液面以下
result += left_max - height[left];
}
left++;
}else{
//说明右侧是矮柱
if(height[right]>right_max){
//更新该侧最大值,不计算水量
right_max = height[right];
}else{
//该点位于液面以下
result += right_max - height[right];
}
right--;
}
}
return result;
}
};7.3 解题思路2单调栈⭐
该方法跟ai给我的思路不太一样,但是我觉得我这种算法其实是一种分而治之:把水池子划分为不同的单调递减的区,接着进行水量计算。具体思路入下:
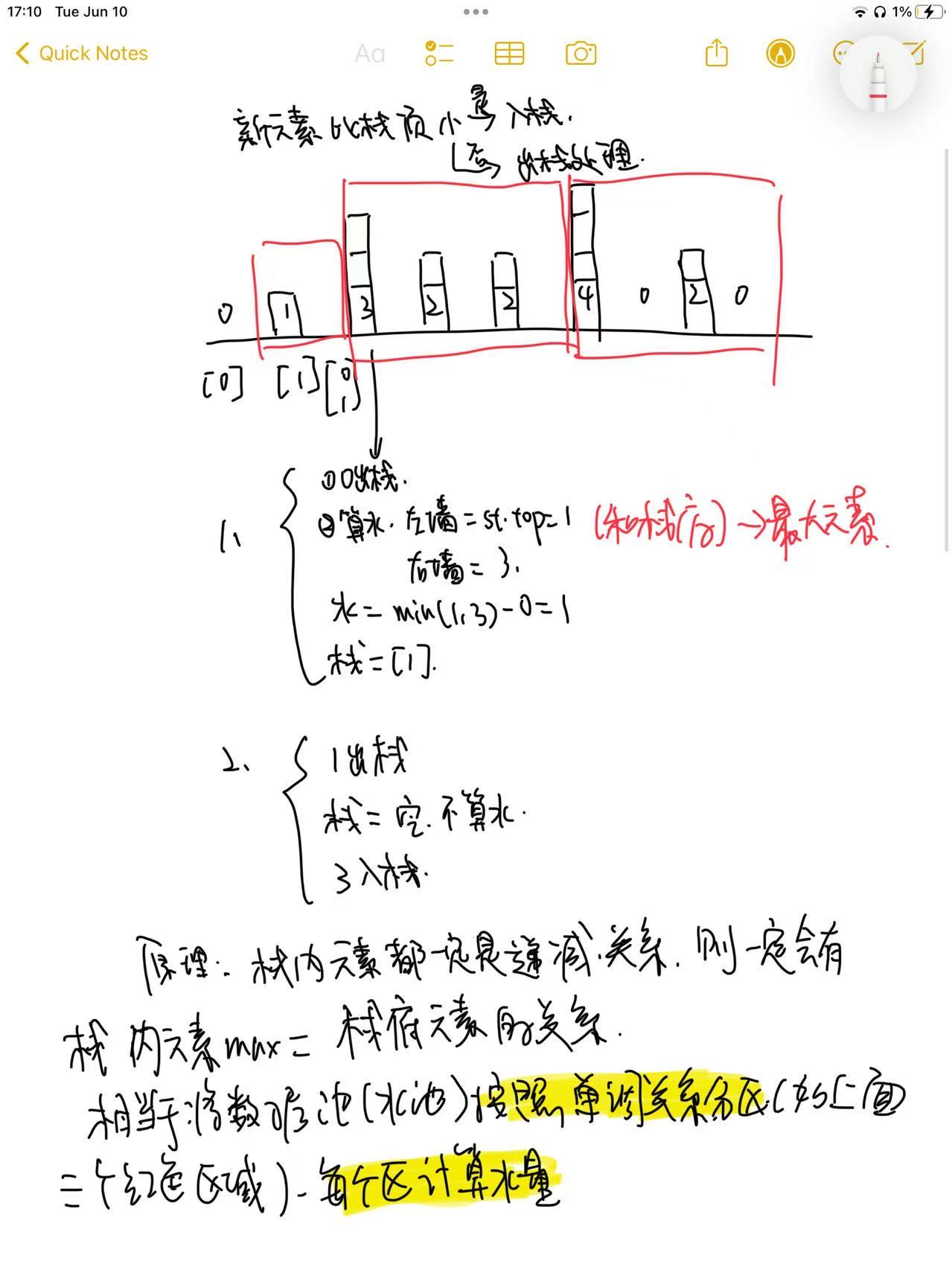
题目8:【双指针】无重复字符最长子串⭐
8.1 解题思路
本题通过维护两个指针来指示子串的两端,其中右指针(end)在循环中不断向后移动,碰到重复的则移动左指针(start)。关键是每次移动左值针的时候跳过重复的值,需要在每次移动左值针之前判断当前处理的字母上一次出现的位置是在当前左值针的外侧还是内侧。如果在外侧的话就不用处理,因为必定包含之前已经计算过的子序列(lastIndex<start且end>=上一次计算start时候的end)
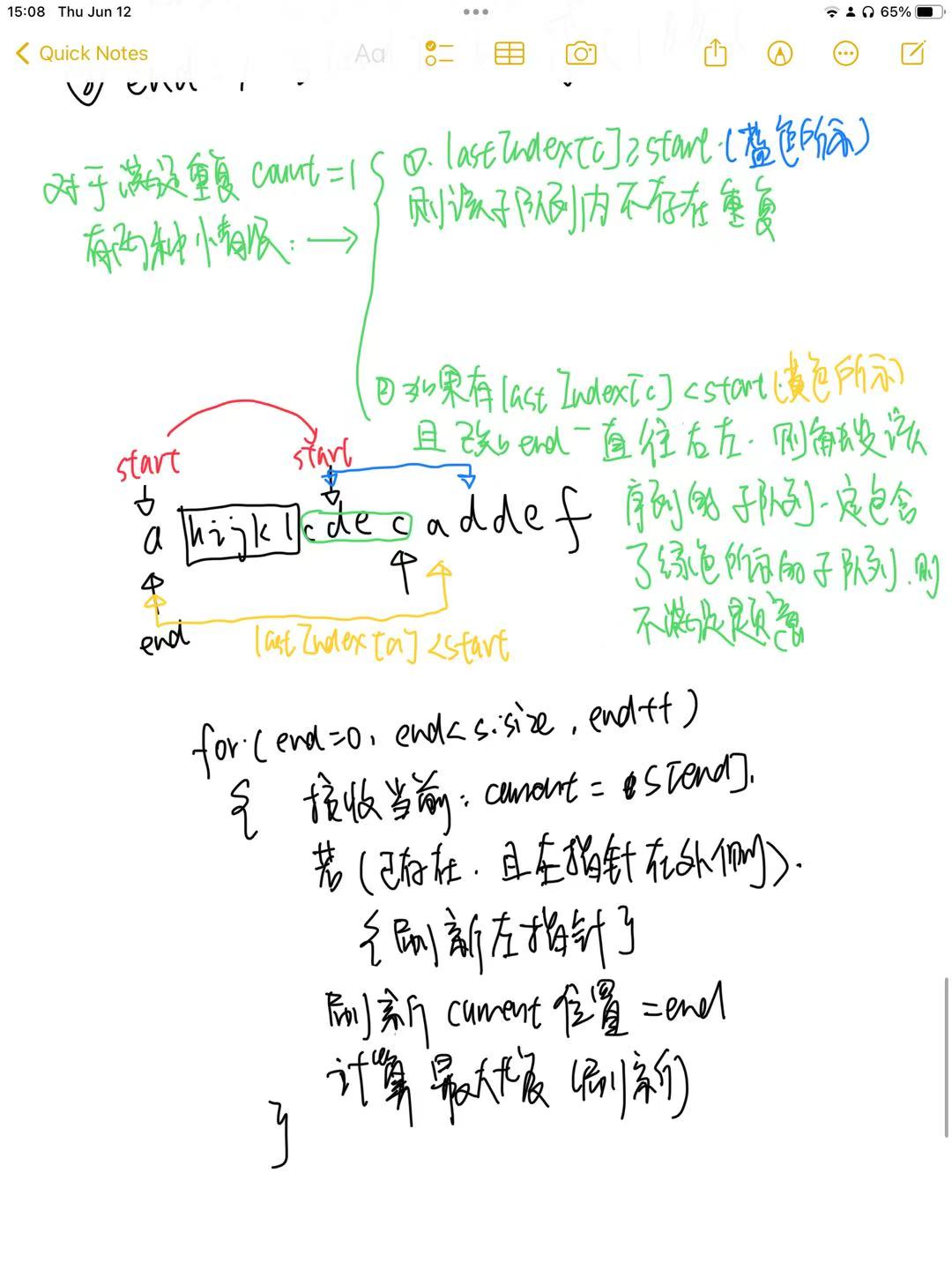

题目9:【双指针】找到字符串中所有字母异位词-0905复习/
438. 找到字符串中所有字母异位词 - 力扣(LeetCode)
9.1 解题思路
9.1.1 提取字符串的子串
使用strncpy_s函数来复制原字符串的对应位置的子串:
errno_t strncpy_s(
char *dest, // 目标缓冲区
rsize_t destsz, // 目标缓冲区大小
const char *src, // 源字符串
rsize_t count // 要复制的最大字符数
);
| 参数 | 类型 | 说明 |
|---|---|---|
dest |
char* |
目标缓冲区,用于存储复制后的字符串。 |
destsz |
rsize_t |
目标缓冲区的大小(单位:字节),必须足够容纳 count 个字符 + 终止符 \0(即 destsz >= count + 1)。 |
src |
const char* |
源字符串,从中复制字符。 |
count |
rsize_t |
要复制的最大字符数(不包括 \0)。如果 src 长度不足,剩余部分用 \0 填充。 |
//提取子串代码
char sub_temp[TEMP_LEN] = { 0 };
strncpy_s(sub_temp, TEMP_LEN,&s[1], 4);
printf("%s", sub_temp);strncpy_s与 strncpy 的对比
| 特性 | strncpy |
strncpy_s |
|---|---|---|
自动补 \0 |
❌ 不会自动补 | ✅ 自动补 |
| 缓冲区溢出检查 | ❌ 无检查 | ✅ 有检查 |
| 错误处理 | ❌ 无返回值 | ✅ 返回错误码 |
| 安全性 | 低(易导致未定义行为) | 高(防止溢出) |
9.1.2 比较两个字符串
比较两个字符串不能直接用“a == b”,因为在 C 语言中,直接使用 == 比较个 char[] 或 char* 时,比较的是指针地址,而不是字符串内容。需要用函数strcmp来比较。
strcmp(sub_temp, temp_p) == 0,在两个字符串相等的时候,比较函数输出0,不等的情况下,函数输出1;参数列表如下:
int strcmp(const char *s1, const char *s2);
9.1.3 分配内存用于存放结果
*returnSize = 0;
...
int* result = (int*)malloc(len_temp_s * sizeof(int));
...
// 当后续运算发现符合题意的结果的时候
if (equal == 0) {
printf("%d\n",start);
result[(*returnSize)] = start;
(*returnSize)++;}
...
return result;9.2 最终代码及实现
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<stdbool.h>
#define TEMP_LEN 20
int compare_chars(const void* a, const void* b) {
return *(char*)a - *(char*)b;
}
int* findAnagrames(char* s, char* p, int* returnSize) {
//1、首先创建基本变量用于维护子队列的首尾
char temp_s[TEMP_LEN];
char temp_p[TEMP_LEN];
strcpy_s(temp_s, TEMP_LEN, s);
strcpy_s(temp_p, TEMP_LEN, p);
int len_temp_s = strlen(temp_s);
int len_temp_p = strlen(temp_p);
*returnSize = 0;
int* result = (int*)malloc(len_temp_s * sizeof(int));
//2、用temp保存子队列,并用qsort函数排序后比较,若满足条件则记录
//2.1实现qsort
//char temp[100] ;
//strcpy_s(temp,100,s);
//int len_temp = strlen(temp);
//qsort(temp, len_temp, sizeof(char), compare_chars);
//printf("%s", temp);
//3、滑动窗口,输出比较结果
for (int i = 0; i < len_temp_s - len_temp_p+1; i++) {
// 维护滑动窗口的起始指针
int start = i;
int end = i + len_temp_p - 1;
printf("start:%d,end:%d\n", start, end);//test-测试窗口索引范围是否有问题
// 子串序列复制,sub_temp:排序后的子序列
char sub_temp[TEMP_LEN] = { 0 };
strncpy_s(sub_temp, TEMP_LEN, &temp_s[start], len_temp_p);
qsort(sub_temp, strlen(sub_temp), sizeof(char), compare_chars);
bool equal = strcmp(sub_temp, temp_p);
if (equal == 0) {
printf("%d\n",start);
result[(*returnSize)] = start;
(*returnSize)++;
}
}
for (int i = 0; i < *returnSize; i++) {
printf("%d ", result[i]); // 打印每个元素
}
return result;
}
int main() {
char* s = "cbaebabacd";
char* p = "abc";
int returnSize = 0;
findAnagrames(s, p, &returnSize);
return 0;
}题目10:【哈希表】和为k的子数组-0905复习/
参考:560. 和为 K 的子数组 - 力扣(LeetCode)
10.1 解题思路
10.1.1 将子数组之和转化为前缀和之差
定义t[m]等于num[0]到num[m]的所有元素累加和
num[a]到nums[b]的子序列之和(a<b)可以转化为t[b]-t[a-1]
因此子序列和为k的问题可以转化为前缀和的差=k,t[b]-t[a-1] = k,转换为哈希表查表则可以表示为查找哈希表中是否存在t[b] = t[a-1]+k
因此构造哈希表的时候前缀和值作为键值
10.1.2 构造哈希表并实现其查表、添加功能
- 利用unordered_map来构造哈希表并初始化(第一个元素初始化为Key:Value = 0:1)
int total_cnt = 0; unordered_map<int, int> preArray_cnt; preArray_cnt[0] = 1; - 遍历数组计算Key值,每次遍历对应位置的value+1
for (int i = 0; i < nums.size(); ++i) { pre_sum += nums[i]; ...... preArray_cnt[pre_sum]++; } - 每添加一个新元素则计算一次结果
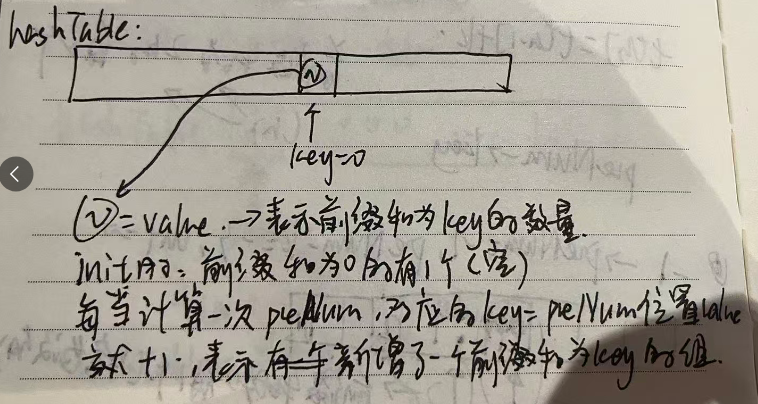
if (preArray_cnt.find(pre_sum-k) != preArray_cnt.end()) { total_cnt += preArray_cnt[pre_sum-k]; }关于先Value++再计算cnt还是先计算cnt再value++:当一个新的前缀和进入,且找到哈希表中有preValue-New - k = Key的时候,表中的(先入比表的)Key是当作子序列的左节点的,而新入的preValue-New是当作右节点的,则preValue-New只会可能在后续的计算中充当左节点的时候计算cnt,因此应当先计算cnt,再value++以准备下一次运算(相当于如果找到一样的Key,则合并),下图以nums[] = {-1, 3, 3, -3, 5,-3}, k = 2;为例子
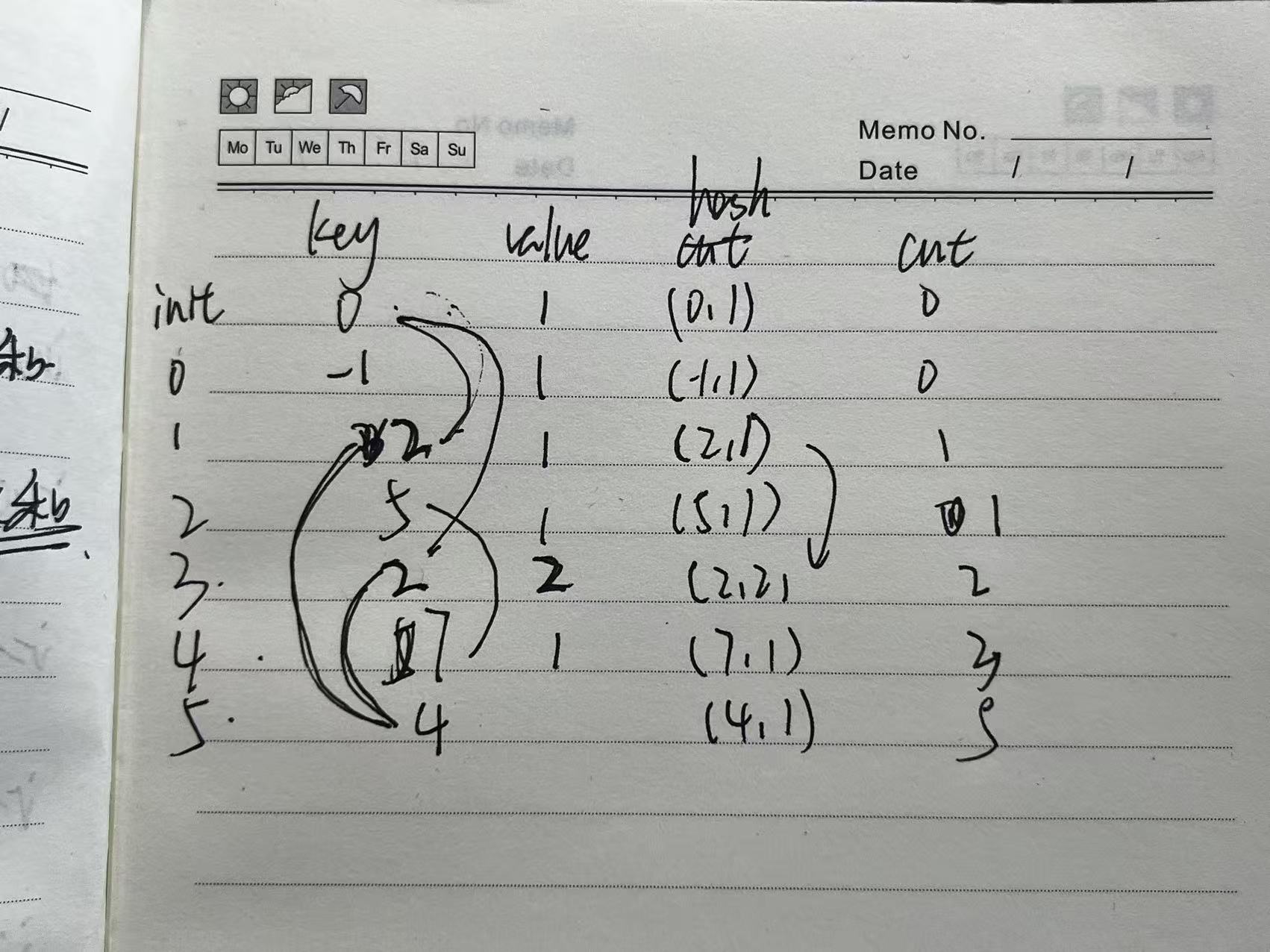
hashtable 第key个位置的value的含义:前缀和为key的数组个数为value,这就是为什么代码中的哈希表要用preArray_cnt来表示
10.2 最终代码及实现
class Solution {
public:
int subarraySum(vector<int>& nums, int k) {
int total_cnt = 0;
unordered_map<int, int> preArray_cnt;
preArray_cnt[0] = 1;
int pre_sum = 0;
for (int i = 0; i < nums.size(); ++i) {
pre_sum += nums[i];
if (preArray_cnt.find(pre_sum-k) != preArray_cnt.end()) {
total_cnt += preArray_cnt[pre_sum-k];
}
preArray_cnt[pre_sum]++;
}
return total_cnt;
}
};
作者:alvincat
链接:https://leetcode.cn/problems/subarray-sum-equals-k/solutions/3043747/qian-zhui-he-qiu-jie-he-wei-kde-zi-shu-z-ruki/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。题目11
11.1 解题思路
11.3 报错问题记录
11.3.1 大小超出限制(内存泄漏)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)