AI基础学习周报十二
本周系统研究了Transformer架构中的关键优化技术与视觉Transformer模型演进。深入分析了残差连接解决网络退化问题的机制及其在梯度传播中的重要作用,剖析了层归一化在稳定训练过程与加速收敛方面的核心价值;完整解析了Vision Transformer的图像分块嵌入、位置编码与Transformer编码器集成架构;重点研究了Swin Transformer的层次化设计、滑动窗口注意力机制
摘要
本周系统研究了Transformer架构中的关键优化技术与视觉Transformer模型演进。深入分析了残差连接解决网络退化问题的机制及其在梯度传播中的重要作用,剖析了层归一化在稳定训练过程与加速收敛方面的核心价值;完整解析了Vision Transformer的图像分块嵌入、位置编码与Transformer编码器集成架构;重点研究了Swin Transformer的层次化设计、滑动窗口注意力机制与移位窗口计算策略,建立了从基础模块优化到视觉应用创新的完整技术认知体系。
Abstract
This week systematically investigated key optimization techniques in Transformer architecture and the evolution of visual Transformer models. In-depth analysis was conducted on residual connections addressing network degradation and their critical role in gradient propagation, alongside layer normalization’s core value in stabilizing training and accelerating convergence. The complete architecture of Vision Transformer was examined, including patch embedding, positional encoding, and Transformer encoder integration. Focus was placed on Swin Transformer’s hierarchical design, sliding window attention mechanism, and shifted window computation strategy, establishing a comprehensive technical understanding from basic module optimization to visual application innovation.
1、残差连接和层归一化

这种现象并不符合常理,因为更深的网络结构通常被认为应该表现得更好。
例如,一个56层的深层网络在测试集上的错误率有时会高于一个20层的浅层网络,且这并非数据问题导致。即使在训练集上,深层网络的表现也不如浅层网络,这种现象称为“网络退化”。
Add(残差连接): 残差连接(Residual Connection)或跳跃连接(Skip Connection)最早由何凯明等人在2015年提出的ResNet(Residual Network)中引入,成为了解决深层网络网格退化的一种有效方法。
残差连接在构建深层神经网络时,被视为一种有效的兜底策略。 当网络已经达到或接近其性能的最优解时,如果继续增加网络深度(即添加更多的层),这些新增的层(被视为冗余层)不应该对网络的性能产生负面影响。
Skip connections的实现方式通常是将某一层的输出(通常经过一个恒等映射或简单的线性变换)直接加到下一层(或更深层)的输出上。 这样,网络的输出就可以表示为输入的非线性变换与输入的线性叠加,即y = F(x) + x,其中F(x)表示输入x经过一系列非线性变换后的输出,x表示直接传递的输入。**********skip connections************
例如:模型一共56层,若第20层时模型已经充分学习达到测试集最佳效果,则让从21层开始到第56层学习一种恒等变换,在最后一层将第20层的输出恒等映射出来。
残差网络: 残差网络(ResNet)通过残差连接,使得输入信息可以直接跨越一层或多层,与后续层的输出相加,从而缓解了深层网络中的梯度消失和梯度爆炸问题,使得网络可以扩展到更深的层数。**
-
梯度消失:在深层网络中,梯度需要通过多个层次进行反向传播。根据链式法则,梯度在传播过程中会不断相乘,当层数较多时,梯度值可能会以指数形式衰减并趋近于零,导致梯度消失。
-
梯度爆炸:深层网络中的梯度在传播过程中也可能因链式法则的连乘效应而迅速增长,甚至呈指数级增长,导致网络参数更新过大,网络不稳定。
归一化(Normalization): 一种数据预处理技术,旨在通过线性或非线性变换,将输入数据或神经网络层的输出数据映射到一个特定的数值范围或分布之中。这一处理过程对于提升神经网络训练过程的稳定性、加速收敛速度以及最终提高模型性能至关重要。
在神经网络中,常见的归一化方法包括 :
-
批归一化(Batch Normalization): 它通过在每个批次中对输入数据进行规范化,使其均值为0、方差为1,从而加速网络的收敛过程,降低网络对初始化和学习率的敏感性,同时也有一定的正则化效果。
-
层归一化(Layer Normalization): 与批归一化不同,它在每层中对所有样本的输出进行规范化,而不是对每个批次进行规范化。层归一化在处理序列数据等不适合批处理的情况下,可以作为替代方案使用。
-
组归一化(Group Normalization): 组归一化是一种介于批归一化和层归一化之间的方法,它将输入数据分成多个小组,然后对每个小组内的样本进行归一化,从而减小小组之间的相关性,提高网络的学习能力。

Transformer使用的是层归一化, 通过对层内所有神经元的输出进行归一化处理,使得输出的分布具有稳定的均值和方差。
在Transformer中,层归一化通常是在残差连接之后进行,主要用于解决内部协变量偏移问题,即减少层与层之间数据分布的差异,从而加速训练过程。
层归一化会对残差连接后的输出进行归一化处理,然后使用可学习的参数(如beta和gamma)对归一化后的输出进行缩放和平移。这样既可以保持数据的分布稳定性,又可以保留一定的灵活性
2、Vision Transformer
2.1 简介
CNN的在处理VC大模型遇到了困境的原因分析:卷积进行中,越来越多的网络结构,必须堆叠多层卷积,逐层对特征图进行处理中,感受野才不断增大,慢慢才有了全局的信息提取;从小规模数据开始,进行模型训练。
Transfomer网络处理VC的大模型优势表现突出,是因为从第一层开始,就全局计算序列中各个向量的关联权重。但是需要足够多的数据,全局学习需要非常大量的数据才能表现卓越,这是所有论文中模型的测试效果好的前提条件。预训练模型开始,对其微调就可以适合个性化场景。
总之,Transformer和CNN在不同的任务中表现出色,但在处理序列数据方面,Transformer具有更好的建模能力和计算效率,可以处理更长的序列,更容易扩展到其他NLP任务。
为了解决上述问题,Google的研究团队提出了ViT模型。ViT是谷歌提出的把Transformer应用到图像分类的模型,虽然不是第一篇将transformer应用在视觉任务的论文,但是因为其模型“简单”且效果好,可扩展性强(模型越大效果越好),成为了transformer在CV领域应用的里程碑著作。
ViT原论文中最核心的结论是,当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。CNN具有两种归纳偏置,一种是局部性,即图片上相邻区域具有相似的特征,一种是平移不变性,CNN具有上面两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习到一个比较好的模型。
2.2 模型结构
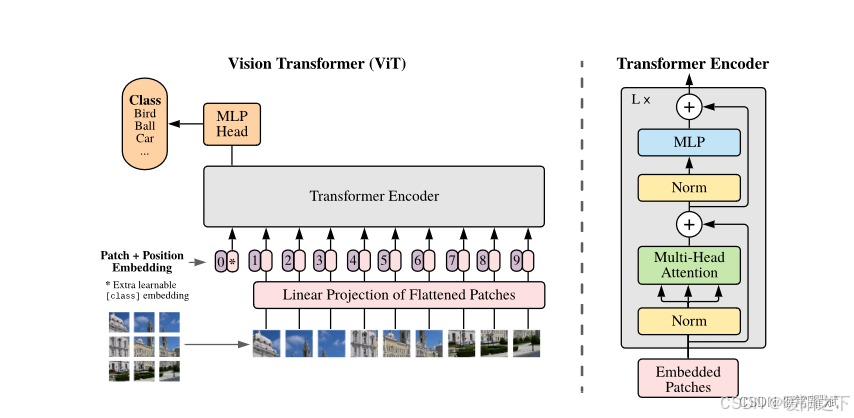
我们先结合下面的动图来粗略地分析一下ViT的工作流程,如下:
- 将一张图片分成patches;
- 将patches铺平;
- 将铺平后的patches的线性映射到更低维的空间;
- 添加位置embedding编码信息;
- 将图像序列数据送入标准Transformer encoder中去;
- 在较大的数据集上预训练;
- 在下游数据集上微调用于图像分类;
模型简介代码:
## from https://github.com/lucidrains/vit-pytorch
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
# einops张量操作神器
# helpers
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.1):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x): ## 最重要的都是forword函数了
qkv = self.to_qkv(x).chunk(3, dim = -1)
## 对tensor张量分块 x :1 197 1024 qkv 最后 是一个元组,tuple,长度是3,每个元素形状:1 197 1024
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)
# 分成多少个Head,与TRM生成qkv 的方式不同, 要更简单,不需要区分来自Encoder还是Decoder
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
# 1. VIT整体架构从这里开始
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
# 初始化函数内,是将输入的图片,得到 img_size ,patch_size 的宽和高
image_height, image_width = pair(image_size) ## 224*224 *3
patch_height, patch_width = pair(patch_size)## 16 * 16 *3
#图像尺寸必须能被patch大小整除
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width) ## 步骤1.一个图像 分成 N 个patch
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),# 步骤2.1将patch 铺开
nn.Linear(patch_dim, dim), # 步骤2.2 然后映射到指定的embedding的维度
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
x = self.to_patch_embedding(img) ## img 1 3 224 224 输出形状x : 1 196 1024
b, n, _ = x.shape ##
#将cls 复制 batch_size 份
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
# 将cls token在维度1 扩展到输入上
x = torch.cat((cls_tokens, x), dim=1)
# 添加位置编码
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
# 输入TRM
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
v = ViT(
image_size = 224,
patch_size = 16,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 224, 224)
preds = v(img) # (1, 1000)
3、Swin Transformer
Swin Transformer是2021年微软研究院发表在ICCV上的一篇best paper。该论文已在多项视觉任务中霸榜(分类、检测、分割)。
《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
论文地址:https://arxiv.org/pdf/2103.14030.pdf
3.1 简介
Swin Transformer是一种为视觉领域设计的分层Transformer结构。它的两大特性是滑动窗口和分层表示。滑动窗口在局部不重叠的窗口中计算自注意力,并允许跨窗口连接。分层结构允许模型适配不同尺度的图片,并且计算复杂度与图像大小呈线性关系。Swin Transformer借鉴了CNN的分层结构,不仅能够做分类,还能够和CNN一样扩展到下游任务,用于计算机视觉任务的通用主干网络,可以用于图像分类、图像分割、目标检测等一系列视觉下游任务。
3.2 模型结构
SwinTransformer 针对ViT使用了**“窗口”和“分层”**的方式来替代长序列进行改进。网络架构如下图所示。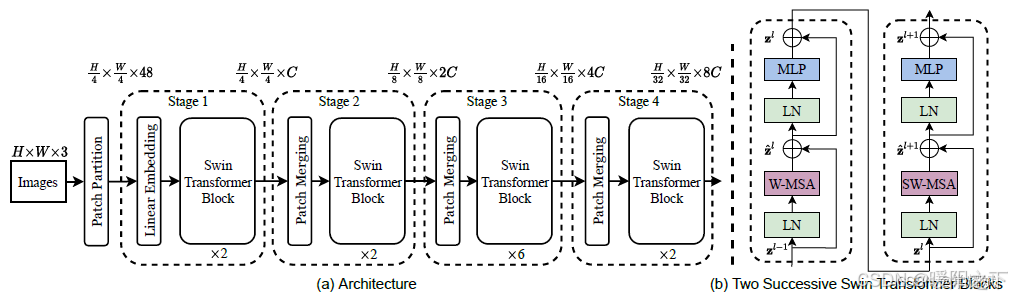
- 输入:首先输入还是一张图像数据,224(宽) ∗ 224(高) ∗ 3(通道)
- 处理过程:通过卷积得到多个特征图,把特征图分成每个Patch,堆叠Swin Transformer Block,与Swin TransformerBlock在每次堆叠后长宽减半,特征图个数翻倍。
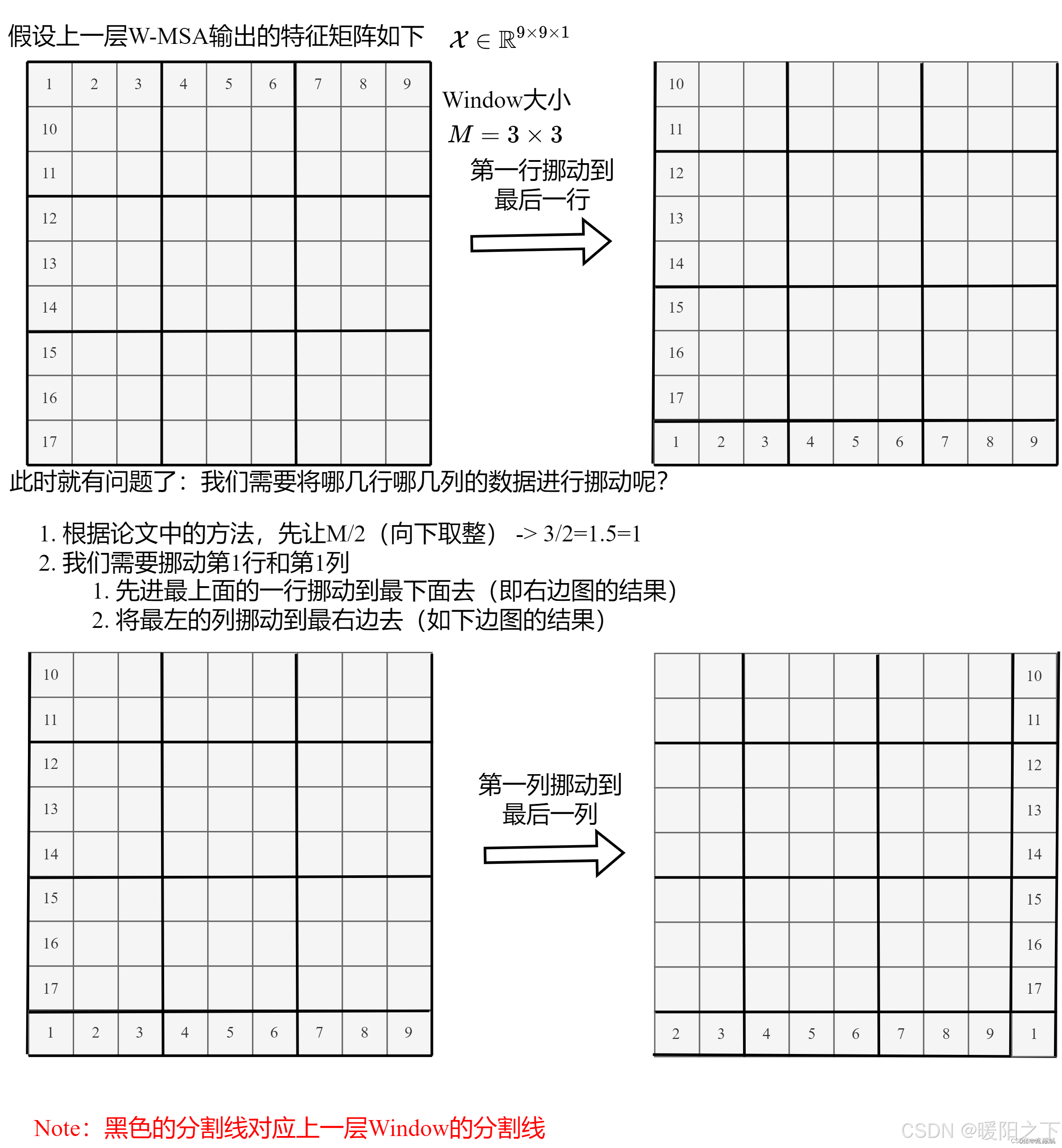
- Block含义:最核心的部分是对Attention的计算方法做出了改进,每个Block包括了一个W-MSA和一个SW-MSA,成对组合才能串联成一个Block。W-MSA是基于窗口的注意力计算。SW-MSA是窗口滑动后重新计算注意力。
Patch Embbeding介绍
- 输入:图像数据(224,224,3)
- 输出:(3136,96)相当于序列长度是3136个,每个的向量是96维特征
- 处理过程:通过卷积得到,Conv2d(3, 96, kernel_size=(4, 4), stride=(4, 4)),3136也就是 (224/4) * (224/4)得到的,也可以根据需求更改卷积参数
- 实际上就是一个下采样的操作,是不同于池化,这个相当于间接的对H和W维度进行间隔采样后拼接在一起,得到H/2,W/2,C*4。
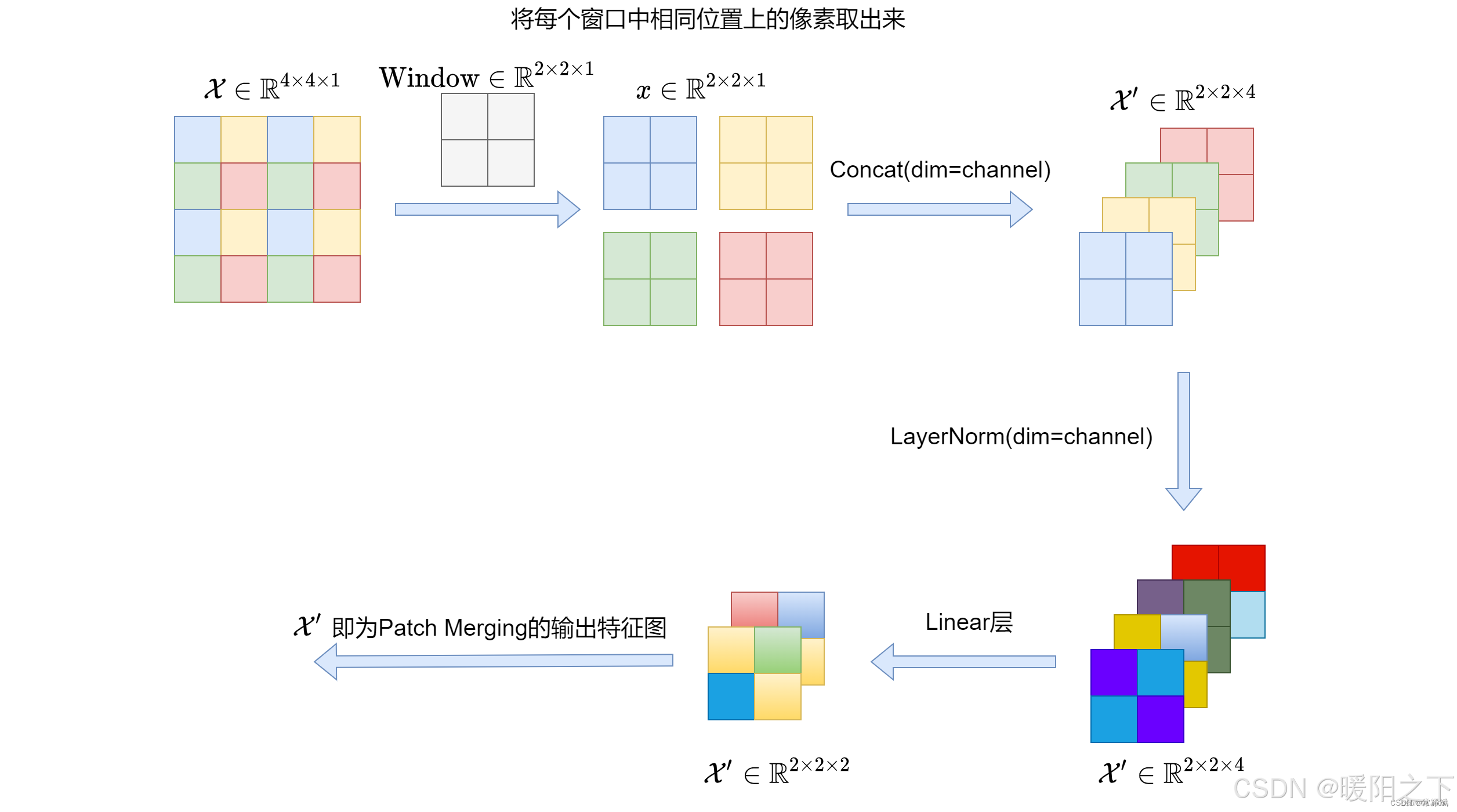
window_partition介绍 - 输入:特征图(56,56,96)
- 默认窗口大小为7,所以总共可以分成8*8个窗口
- 输出:特征图(64,7,7,96)
- 处理过程:之前的单位是序列,现在的单位是窗口(共64个窗口),56=224/4,5656分成每个都是77大小的窗口,一共可以的得到88的窗口,因此输出为(64,7,7,96),因此输入变成了64个窗口不再是序列了。
W-MSA(Window Multi-head Self Attention) - 对得到的窗口,计算各个窗口自己的自注意力得分。
- qkv三个矩阵放在一起了:(3,64,3,49,32),3个矩阵,64个窗口,heads为3,窗口大小7*7=49,每个head特征96/3=32。
attention结果为:(64,3,49,49) 每个头都会得出每个窗口内的自注意力 - 原来有64个窗口,每个窗口都是7*7的大小,对每个窗口都进行Self Attention的计算(3,64,3,49,32),第一个3表示的是QKV这3个,64代表64个窗口,第二个3表示的是多头注意力的头数,49就是77的大小,每头注意力机制对应32维的向量。
- attention权重矩阵维度(64,3,49,49),64表示64个窗口,3还是表示的是多头注意力的头数,49*49表示每一个窗口的49个特征之间的关系
Window_reverse - 通过得到的attention计算得到新的特征(64,49,96),总共64个窗口,每个窗口7*7的大小,每个点对应96维向量。
- window_reverse就是通过reshape操作还原回去(56,56,96),还原的目的是为了循环,得到了跟输入特征图一样的大小,但是其已经计算过了attention,attention权重与(3,64,3,49,32)乘积结果为(64,49,96),这是新的特征的维度,96还是表示每个向量的维度,这个时候的特征已经经过重构,96表示了在一个窗口的每个像素与每个像素之间的关系。
总结
残差连接与层归一化是Transformer稳定训练的基础保障,ViT开创了纯Transformer架构处理视觉任务的先河,而Swin Transformer通过引入局部性先验和层次化设计成功解决了ViT的计算复杂度问题。这些技术形成了从基础优化到应用创新的完整发展脉络,为后续研究更高效的视觉Transformer模型奠定了坚实基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 34
34 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)