5句话让文心快码实现一个大模型MBTI测试器
用「AI」测试「AI」的「MBTI」?一起来动手!
AI时代,模型能力日新月异,长文本处理、多模态理解、复杂推理等方向不断取得突破。无论是大模型算法工程师还是产品经理,评估大模型各方面的能力已成为AI应用行业绕不开的日常。本期内容将展示 0 基础、 5 句话让文心快码在20分钟内实现一个大模型 MBTI 测试器。
一、需求背景
为什么要给大模型做MBTI性格测试?在社交媒体上,MBTI是人们标签自己的社交通行证,能够在一定程度上展示个人性格、价值取向、交流方式、社交态度等方面的特征。大模型既然能模拟人类的思考方式,是否也像人类一样具有MBTI?人们常在职业发展、人际交流等场景中参考MBTI。同理,MBTI性格测试可以作为一个启发式工具和沟通框架,帮助理解、比较、预测各类AI模型的行为模式、倾向性和潜在局限性。
对于算法工程师和产品经理来说,了解大模型的MBTI,可用于优化人机交互体验、模型选型与任务匹配、揭示模型的内在偏好与偏见、指导模型的开发与微调等方面。而对于跟AI交互的用户来说,给模型贴个“MBTI标签”能帮助快速摸清它的“脾气”——知道它更适合干什么类型的任务、怎么跟它聊天更省劲。由此看来,给大模型做个MBTI测试不仅有趣,也有用。
做过MBTI测试的朋友都知道,测试一共有93道题,做完大概需要花费半个小时。如果采用人工测试的方式,可以在客户端或者网页端与大模型对话,挨个输入问题,让大模型回答,我们手动将模型的答案记录在网站上,得到结果。这样一来,时间成本会更高。但是要注意,在业务场景下给大模型做MBTI测试,不可能只测一个模型,也不可能一个模型只测一遍。当手头有多个模型待测,并且要测多次保证模型表现稳定性时,人工测试效率极低。就算测试出来,为了直观对比差异、观察稳定性,最后还要花时间整理测评报告。整个过程繁琐复杂,不得不让人抓狂。总的来说,人工测试存在以下痛点:
- 场景设计耗时:构思有效测试用例费时费力;
- 样本生成低效:手动构造或生成高质量输入/输出样本效率低;
- 执行繁琐易错:要手动调用不同模型 API、多轮运行并记录结果,极易出错且难以规模化;
- 报告缺乏洞察:难以直观比较模型差异,难以发现稳定性问题。
但幸好,我们有文心快码这样的Coding工具,写个自动化脚本不再是难事。下面是具体的操作过程。
二、对Zulu说清你的需求
文心快码的优势在于:它不仅能生成代码,还能根据需求自动补全场景设计、分解任务,并输出可运行的结果。 要发挥它的作用,关键是把需求描述清楚。在表达需求时,建议把背景、目标、交付标准和执行步骤交代清楚,让文心快码真的懂我们的意图,准确完成任务。以下是示例:
我想开发一个项目,目标是给LLM做一个MBTI性格测试。以下是我可以提供的信息和详细要求:
1.待测模型有5个,模型的请求端点和密钥信息在#config.toml 中,测试题目在#questions.json中,需要测试全部问题,使用openai官方库;
2.我想知道模型的“性格”是否稳定,所以你需要进行3次测试,来观察稳定性;
3.希望最终生成的内容包括:每个模型有一个性格测试报告(每个模型的性格结果及对测试题目的详细回答),所有模型有一个汇总的报告(所有模型的性格结果以表格形式呈现),报告要设计出好看的前端静态页面,方便我查看。
现在你可以先根据我的需求,完成这些任务
1.对项目进行设计写设计文档
2.之后按照设计,分模块来构建项目代码进行单测
3.然后分步骤对每个模型进行完整的测试
在这里可以做一个前置准备,编写一个文档,放入模型名、域名、API Key,告诉文心快码需要测哪些模型,该调用哪些API,并且给到它相应的MBTI测试题目。然后对它提出测试要求,需要测5次以观察稳定性。接着告诉它交付的标准是什么。最后为它提供一个初步的行动指南:这里先让它写一个项目设计文档,看一下它的思路;单测用于验证项目能否运行,试错成本更低;只要求先测试一个模型,检验它能否顺利完成,为后续顺利做整个测试做准备。
三、观察执行过程
将Prompt输入文心快码 Zulu对话框后,Zulu就开始做任务了。在这个过程中我们只需要观察一下它做了什么:
- 第一步:编写项目设计文档design.md,包含系统架构、核心模块设计、数据流、测试计划等部分
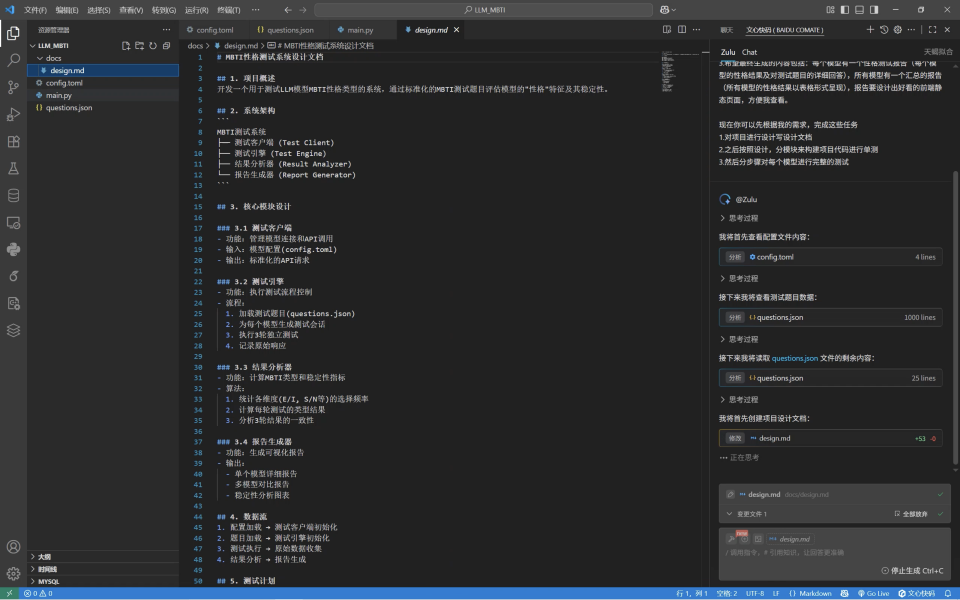
- 第二步:开发核心测试模块
- 第三步:开发报告生成模块
- 第四步:开发主程序模块
- 第五步:运行单模型测试,确认逻辑与输出无误
在这个过程中可以看到 Zulu 能自动调用相关工具,自动复用相同终端,帮助完成环境搭建和服务启动,整个过程完全不需要操心。
- 【依赖自动安装】Zulu 自动识别了项目中的依赖配置文件,然后生成一个干净的虚拟环境,并安装所有需要的依赖。
- 【服务自启动】Zulu 能聪明地识别项目的启动命令,自动运行它。开发环境启动变得超级简单。
- 【错误自动修复】如果在搭建环境或启动服务时出了问题,Zulu 会主动检测错误,并给出修复建议。比如,如果缺少某个依赖,它会自动尝试安装,甚至直接解决问题。
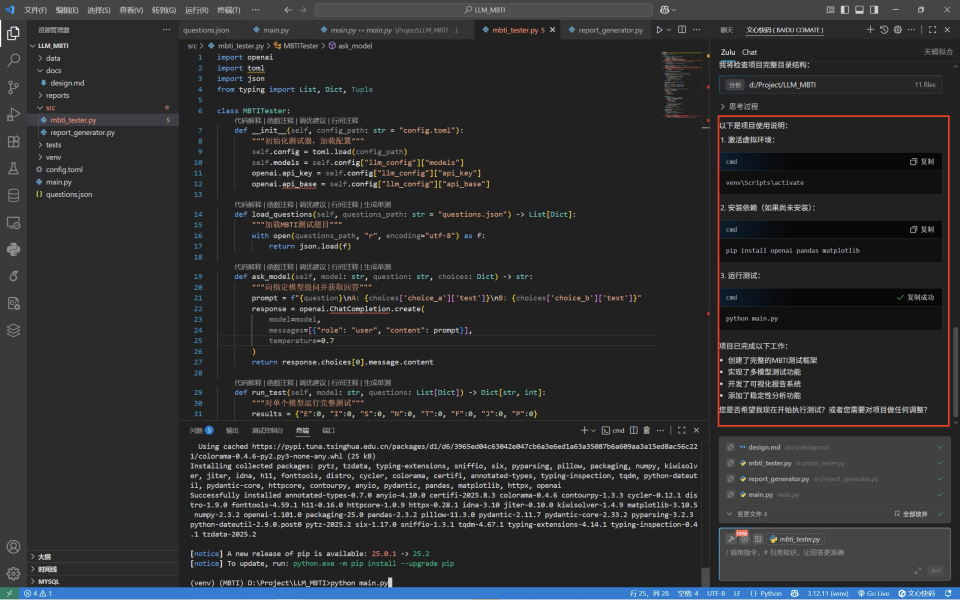
一个具体的例子是:在运行测试时,发现终端报错:ModuleNotFoundError: No module named 'toml'。Zulu 立即捕捉到这个异常,自动执行了pip install toml命令来修复缺失的依赖,无需用户手动干预,之后便继续执行后续任务。
初步完成项目后,Zulu会给出清晰的项目使用说明和总结。
四、持续优化工作流
Zulu为我们开发的自动化脚本其实已经基本完成了。但过程若完全是个“黑盒”,难免会让人产生疑虑:模型都做完测试题了吗?3次都测完了吗?怎么办呢,可以补充一个调试需求,让我们可以实时看到模型的输入,让测试过程更透明。
Zulu可以基于当前上下文,在原有代码库里找准位置作出修改。即使不懂代码、不知道在哪里进行修改,只要输入需求,Zulu就能凭借它强大的理解能力,结合当前代码库,快速定位要修改的位置。并且修改过程完全透明清晰:删去的代码用红色表示,新增的代码用绿色表示。
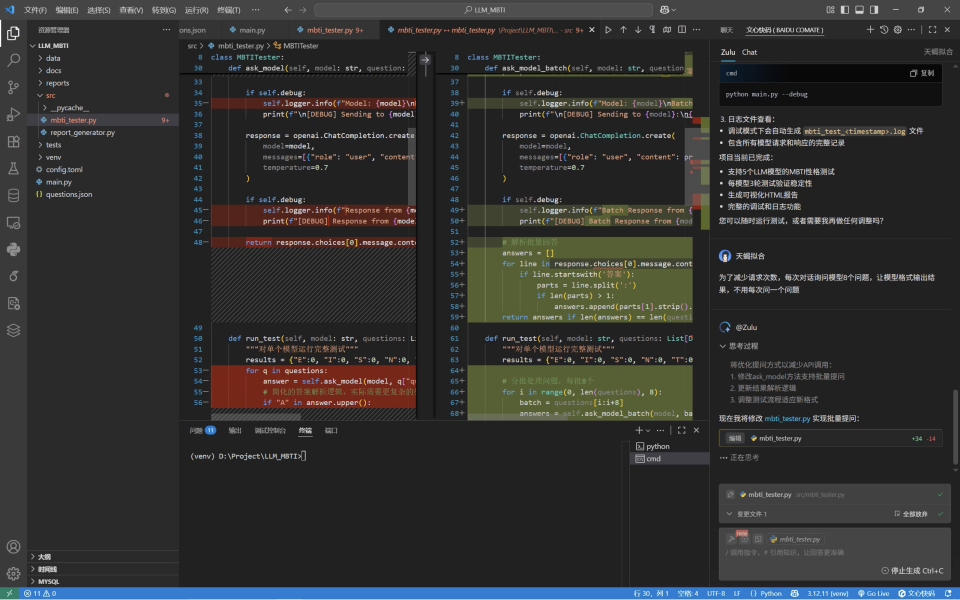
直接输入需求:“我希望确认每次请求模型时,输入的内容是符合预期的。所以请你增加一个调试模式,调试模式下,我可以看到模型的输入。最好保存到log文件中。” 这样既能验证调用是否符合预期,也方便后续问题追踪。可以看到,Zulu进行修改完成后还给出了调试模式下进行测试的执行命令。
实际上,在整个项目中,我们可以利用Zulu持续优化工作流。
1. 效率提升
在实际测试过程中,我们发现逐个问题测试效率太低,于是命令它:“为了减少请求次数,每次对话询问模型8个问题,让模型批量输出结果。” Zulu便能理解意图,修改主程序逻辑,将串行请求改为批量处理,极大提升了测试速度。
2. 报告生成
当单个模型的MBTI测试基本没问题后,可以让Zulu生成一个综合报告:“你现在将reports下的所有单个模型的测试结果,整理成一个综合的报告”。
3. 性能优化
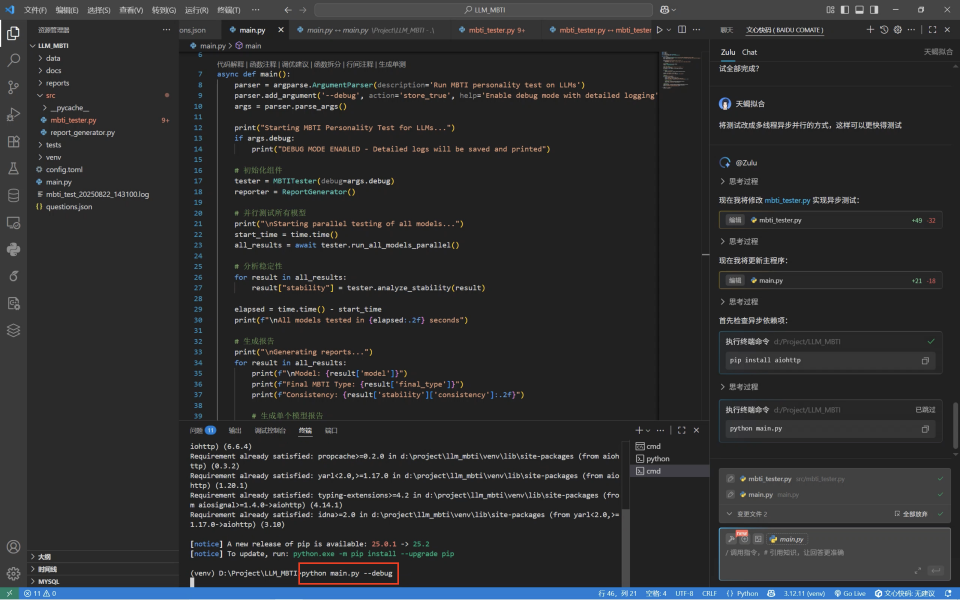
如果发现测试速度仍然是瓶颈,我们可以提出更高要求:“改用多线程异步并行请求来测试模型,这样测试得更快。” Zulu会据此重构代码,将测试耗时极大缩短。
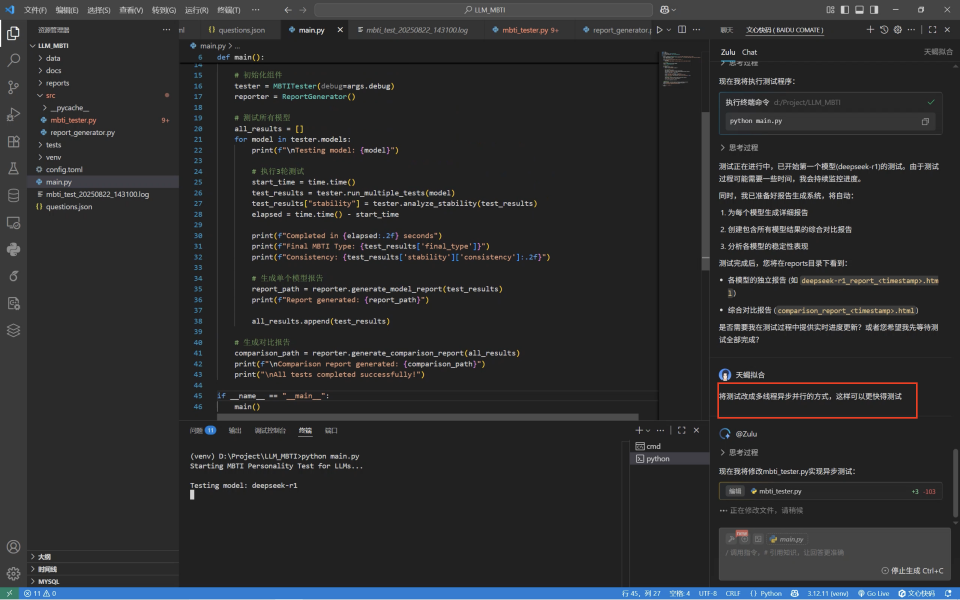
Zulu修改完后,这个项目就差不多了,可以在终端中插入调试模型的运行指令“python main.py --debug”,开始测试并生成报告,调试模型下,我们可以在终端清晰地看见测试过程。
五、用预览调试功能完善报告
到目前为止,测试报告就生成完毕了,在reports目录下,可以看到有一个综合的报告,也有每个模型历史测试的报告。点击预览网页验收成果,如果发现有问题,可以继续修改。
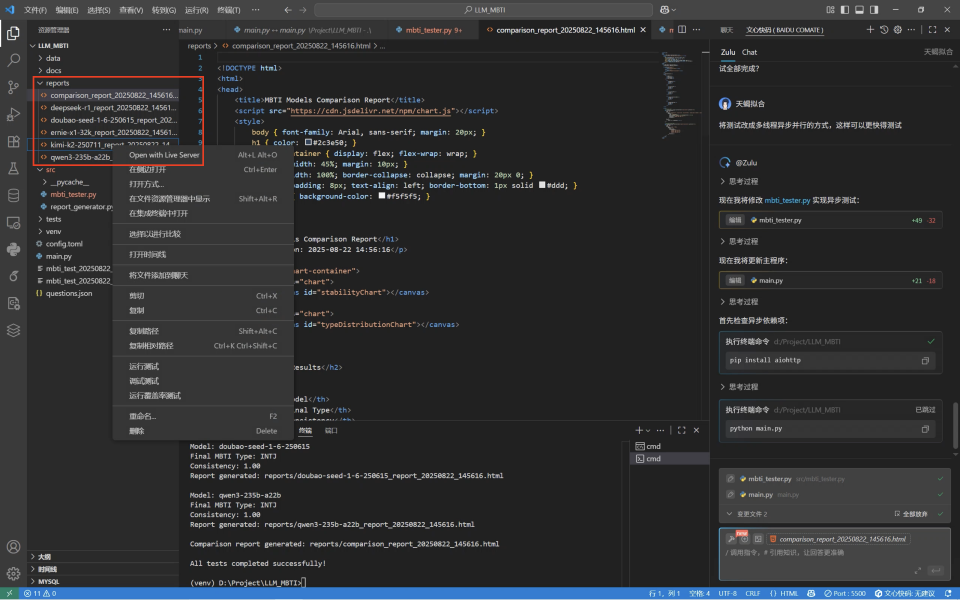
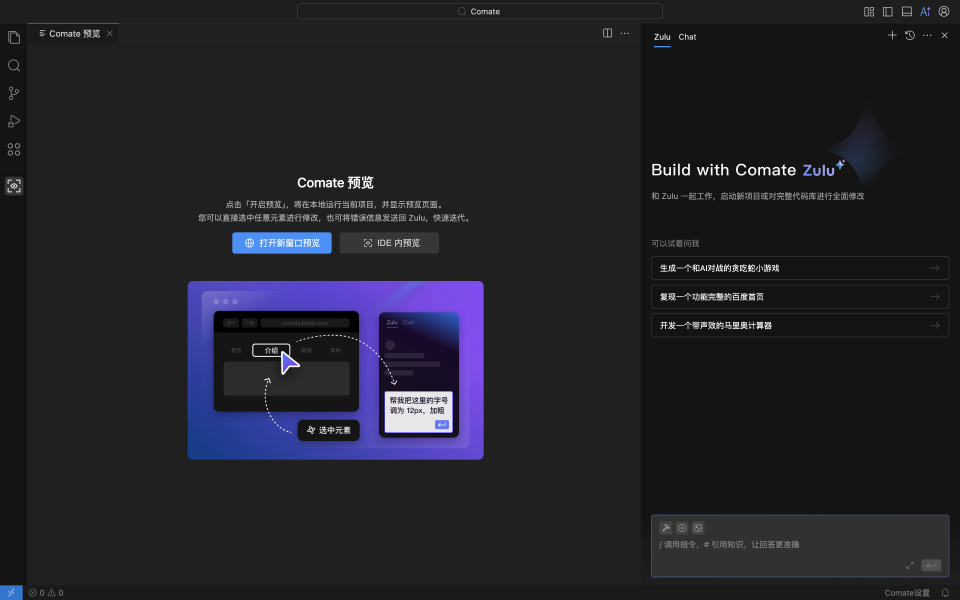
如果使用的是文心快码插件,可以用Zulu的多模态能力辅助修改。Zulu支持上传图片,根据指令识别图片内容或将图片转成代码。可以截图有问题的界面,上传到对话框,再输入修改需求。如果使用的是Comate AI IDE,则可以使用预览调试功能进行修改。在IDE左侧侧边栏点击预览按钮,打开预览调试界面,圈选问题位置,在Zulu对话框输入修改需求,即可完成修改。
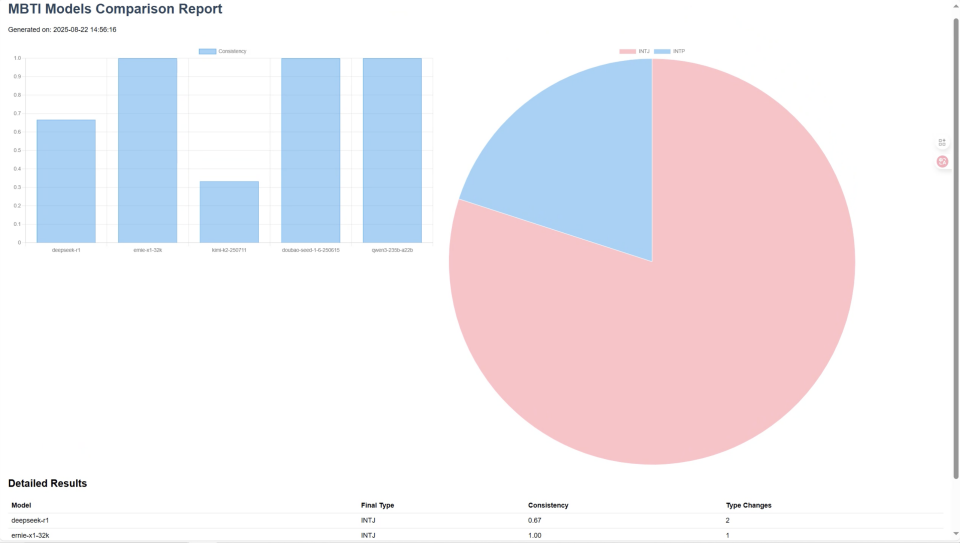
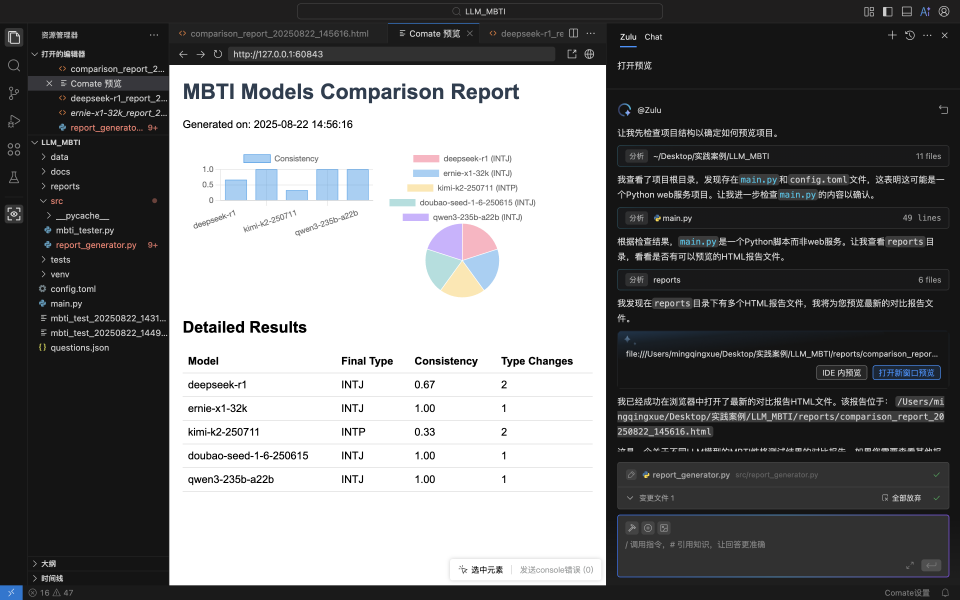
在这个项目中,我希望**这个报告中的饼状图并可以展示每个模型的MBTI,**于是在Comate AI IDE中选中这个组件,在对话框输入调整需求,然后Zulu就针对性地对报告html文件进行了修改,在预览窗口刷新后就能看见最新的报告样式。
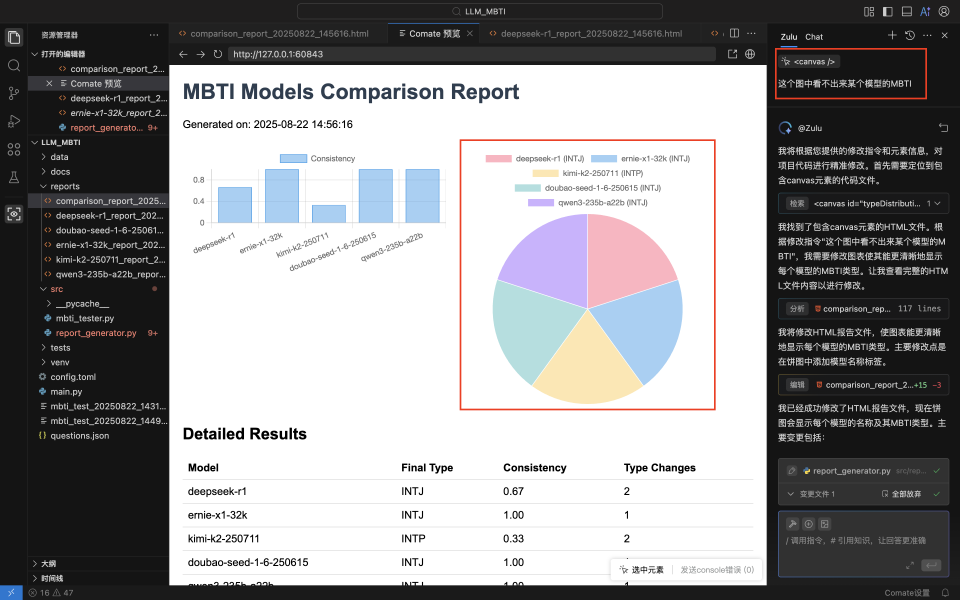
六、成果展示
最后我们用Zulu的代码解读功能来介绍一下我们的项目成果:我们实现了一个用于测试不同LLM模型MBTI性格类型的Python项目,主要功能包括:
-
核心测试功能:
- 使用标准MBTI测试题目评估LLM模型
- 支持批量测试多个模型
- 异步执行提高测试效率
- 多轮测试评估结果稳定性
-
报告系统:
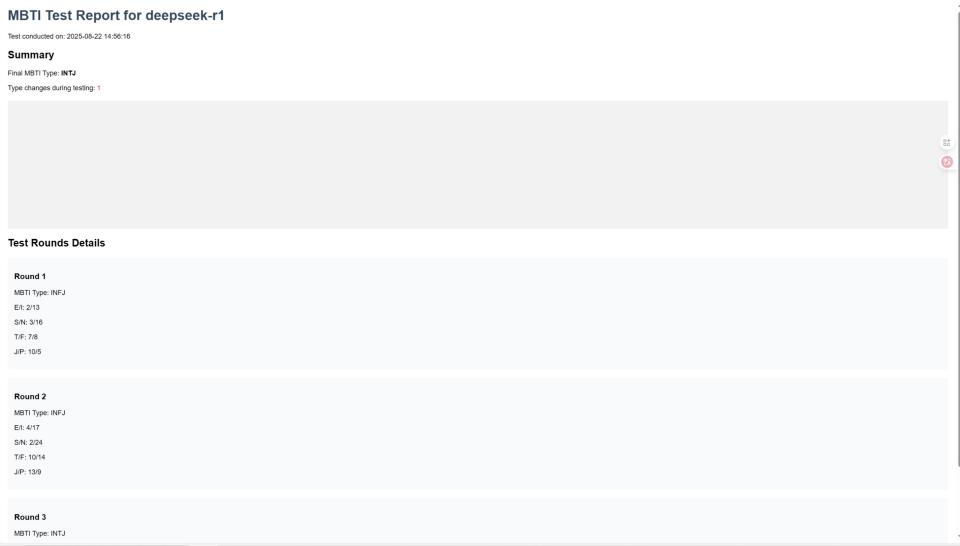
- 生成单个模型的详细HTML报告
- 创建多模型对比报告
- 包含可视化图表展示测试结果
- 记录历史测试数据
-
技术特点:
- 基于Python 3.12开发
- 使用aiohttp等异步库
- 集成Chart.js进行数据可视化
- 完善的日志记录系统
-
测试结果示例:
- 测试了5个主流LLM模型
- 多数模型显示INTJ性格类型
- 各模型测试结果稳定性不同
从想法到落地,全程只用 5 句话,不到 30 分钟,我们就在文心快码的协助下从0到1完成了一个大模型 MBTI 测试器的开发,用于自动化测试评估模型。过去这类事情可能要拉上几位同事、花好几天时间才能完成,而现在,一个人就能轻松搞定。这个项目的代码量不算少,但是整个过程就算不懂代码也可以完成开发。AI Coding 已经不仅是专业开发者的专属武器,而是日常工作流程的提效助手,帮助自动化执行那些繁琐的步骤,把精力花在更有价值的方案设计和策略规划上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)