联邦学习论文分享:Federated In-Context LLM Agent Learning
摘录本地数据中掌握工具所需的关键信息。所有客户端的知识摘要汇总形成。
摘要
-
背景问题
-
LLM 已经能做推理、工具使用、当 agent。
-
但是训练 LLM 很缺优质数据,而这些数据往往是敏感的。
-
联邦学习(FL)可以保护隐私,但传统 FL 需要上传/下发模型参数,通信和计算开销大,而且数据分布不一致会影响效果。
-
新兴的 in-context learning(用上下文提示而非更新参数来学习)可以替代参数传输,但如果直接聚合各个客户端的数据样本,容易泄露隐私。
-
-
提出的方法:FICAL
-
创新点 1:Knowledge Compendiums Generation (KCG)
-
客户端不上传参数,而是上传 知识纲要(compendium)。
-
这些知识由 LLM 生成,既减小通信量,又保护隐私。
-
-
创新点 2:Tool Learning and Utilizing (TLU) 模块
-
基于 RAG(Retrieval Augmented Generation),让 agent 学会工具使用。
-
聚合后的全局知识纲要作为“老师”,指导各个 LLM agent 如何用工具。
-
-
-
实验结果
-
FICAL 在多个任务上表现接近或超过 SOTA 方法。
-
通信成本降低了 3.33 × 10^5 倍(相比传统 FL)。
-
引言
1. 研究背景
-
LLMs 的优势
LLMs(大语言模型)和传统小模型不同,因其参数量大、训练数据多,具备“涌现能力”(emergent abilities),能够做逻辑推理、思考、与外部工具交互,因此可以作为智能体(agent)完成复杂任务。 -
现实问题
LLM agents 的下游任务表现受到 高质量数据匮乏 的限制。-
数据大多是私有和本地化的,无法直接集中训练。
-
联邦学习(FL) 提供了可能的解决方案:在保护隐私的前提下让多个客户端协作训练模型。
-
2. 现有 FL 训练 LLM 面临的三大挑战
-
通信带宽开销大
-
大模型参数量动辄上百亿,在普通网络(如 100Mbps)下,单次参数传输就可能超过十小时。
-
每轮 FL 训练都要传输参数,极其消耗带宽。
-
-
计算开销大
-
LLM 参数规模远超传统模型,而硬件算力增长跟不上。
-
训练 LLM 成本高昂,需要大量高性能 GPU。
-
-
数据分布异质性(non-IID)
-
不同客户端的数据来源不同(地区/行业差异),分布差异会影响模型聚合效果,加大训练难度。
-
3. in-context learning 的启发
-
in-context learning 可以通过上下文提示学习新知识,而不用更新参数。
-
优点:可以只传输“自然语言上下文”,不用传输庞大的模型参数,从而极大降低通信成本。
-
但问题:如果直接聚合各客户端的上下文数据,可能导致 隐私泄露(因为上下文里包含了用户的真实数据样本)。
4. 本文提出的解决方案:FICAL
-
核心思想:在联邦学习里利用 in-context learning,但不传输参数,也不直接传输原始数据,而是传输 知识纲要(knowledge compendiums)。
-
由本地 LLM 通过 KCG 模块(Knowledge Compendium Generation) 生成,包含工具使用方法、注意事项等抽象知识。
-
服务器聚合这些知识纲要,得到 全局知识纲要,再下发给各客户端。
-
这样既减少通信量(O(1) 复杂度 vs 传统 O(N) 参数量),又避免泄露私有数据。
-
-
创新点:
-
提出 FICAL,首次将 in-context learning 引入 FL 的 LLM agent 训练。
-
用 KCG 模块 生成隐私保护的知识纲要代替参数传输,实现通信复杂度 O(1)。
-
设计 RAG-based Tool Learning and Utilizing (TLU) 模块,解决知识纲要过长(long-context)带来的性能下降问题,并提升准确率 7.6%。
-
实验表明:FICAL 在不同场景下效果与 SOTA 方法相当,但通信成本降低了 3.33 × 10^5 倍。
-
相关工作
1. Single LLM Agent Learning(单智能体 LLM 学习)
-
研究如何让单个 LLM 作为智能体(agent)更好地学习和改进:
-
Chen et al. (2024):用类似梯度下降的方法优化 prompt 里的逐步指令,让 LLM 在特定领域里的规划能力更强。
-
Biderman et al. (2024):研究如何预测哪些序列会在大模型训练中被记住(记忆化),通过小规模试验推测大模型的记忆倾向。
-
Madaan et al. (2024):提出“自我改进”方法,一个 LLM 同时担任生成者、反馈者和改进者,利用迭代反馈来优化输出。
-
2. Resource-efficient LLM Learning(高效利用资源的 LLM 学习)
-
关注如何用更少的资源训练或利用 LLM:
-
Wei et al. (2023):在 in-context learning(上下文学习)中,用任意符号替代自然语言标签(比如用 foo/bar 代替正负情感),提升任务泛化能力和鲁棒性。
-
Liu et al. (2022):提出基于相似度选择 in-context 学习样例的方法,让 prompt 中的例子更有信息量。
-
RAG(Retrieval-Augmented Generation,检索增强生成):
-
Lewis et al. (2020):提出经典 RAG 框架,把外部知识库检索结果与 LLM 结合。
-
Asai et al. (2024):提出 self-RAG,用 LLM 的自我反思避免无关检索内容。
-
Kim et al. (2023):提出 TOC(Tree of Clarification)方法,通过递归澄清歧义 + 自验证剪枝,解决开放领域中的歧义问题。
-
-
3. FL with LLMs(联邦学习 + 大模型)
-
探讨 LLM 在 联邦学习 (Federated Learning, FL) 场景下的应用:
-
Zhang et al. (2023):比较了几种高效参数调优方法(LoRA、adapter、prefix tuning)在 FL 中的表现和资源消耗。
-
Sun et al. (2024b):改进 LoRA,在 FL + 差分隐私 (DP) 场景下固定初始化矩阵,保证隐私。
-
Sun et al. (2024a):通过训练最优 prompt + 无梯度优化方法,减少通信开销。
-
Peng et al. (2024):提出 sub-FM(子模型)构建和对齐模块,提升 FL 的效果。
-
动机
1. 问题背景:LLM 越来越大,资源跟不上
-
现有大语言模型(LLM)参数量通常超过十亿,呈快速增长趋势。
-
图 1 显示:
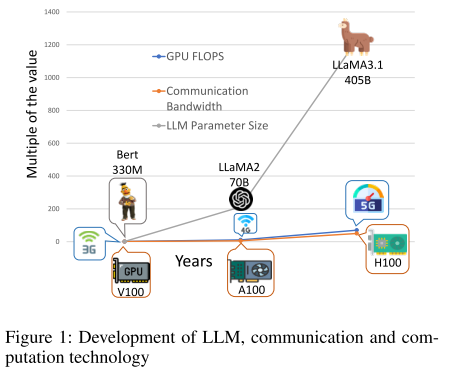
-
灰线:历史上重要 LLM 的参数量;
-
蓝线:通信技术发展;
-
橙线:计算设备发展。
-
-
结论:LLM 参数量增长速度 > 通信带宽增长速度 & 计算能力增长速度
→ 通信和计算资源无法跟上 LLM 训练需求。
2. 训练和传输成本高
-
表 1:列出几个流行 LLM 的参数量和在现代网络下(100 Mbps)传输时间:
-
传输时间:6.4 小时 ~ 36 小时不等。
-
-
LLM 训练需要大量计算资源。
-
在联邦学习(FL)场景下:
-
模型更新和客户端同步依赖快速通信和强大计算能力。
-
现有硬件很难应对这种高负载和大量数据传输。
→ 部署和高效训练大模型在 FL 中非常困难。
-
3. 解决思路:FICAL
-
灵感来源于《道德经》的名言:“授人以鱼不如授人以渔”,强调教会解决问题的方法比直接给结果更重要。
-
在 FL 场景下:
-
问题:直接共享私有数据样本会泄露隐私。
-
方案:每个客户端不传原始数据,而是传 knowledge compendium(知识摘要):
-
摘录本地数据中掌握工具所需的关键信息。
-
所有客户端的知识摘要汇总形成 global compendium(全局知识汇编)。
-
全局知识汇编可以教 LLM 代理如何使用工具,就像“教人钓鱼”一样。
-
-
-
核心思想:用知识传递替代原始数据传递,既保护隐私,又让 LLM 学会“能力”而不是“数据”。
算法
前提
联邦学习场景设定(FL Scenario)
-
有 N 个客户端 和 M 种工具集(toolsets),每种工具集包含若干相似领域的工具。
-
每个客户端 i 有自己的数据集 Di,包含工具使用实例。
-
不同客户端的数据集可能涉及不同工具,因为在实际应用中,不同参与者只可能访问其行业相关的数据(如医疗、教育、体育等)。
-
问题:如何在这种异构数据分布下进行协作学习,同时保证隐私?
上下文学习(In-Context Learning)
-
LLM 可以从 prompt 中的自然语言上下文 学习知识,而不需要修改模型参数。
-
这种学习方式叫做 in-context learning。
-
优势:
-
减少计算和 GPU 内存消耗
-
提升模型在实际应用中的可用性和效率
-
-
核心思想:模型“看”到示例就能推理,无需梯度更新。
增强检索生成(RAG, Retrieval Augmented Generation)
-
LLM 在处理长上下文时会遇到注意力分散问题:
-
Self-Attention 机制可能无法有效聚焦于关键信息
-
信息容易被冗余内容掩盖
-
-
RAG 过程:
-
使用检索模型从大型向量数据库中获取与查询相关的信息
-
将检索到的内容传给 LLM
-
LLM 利用这些信息回答问题
-
-
作用:让 LLM 能够利用大量数据知识,而不受长上下文处理限制。
传统联邦学习(Traditional FL)
-
客户端每轮通信将模型参数传给服务器
-
服务器聚合参数形成全局模型,并返回给客户端
-
重复若干轮通信,得到最终全局模型
-
优化目标公式:
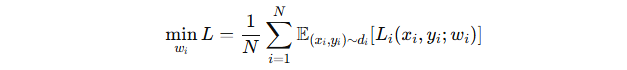
-
Li:客户端 i 的损失函数
-
(xi,yi):客户端 i 的私有数据与对应标签
-
wi:客户端 i 的 LLM 参数
-
di:客户端 i 的数据分布
算法具体流程
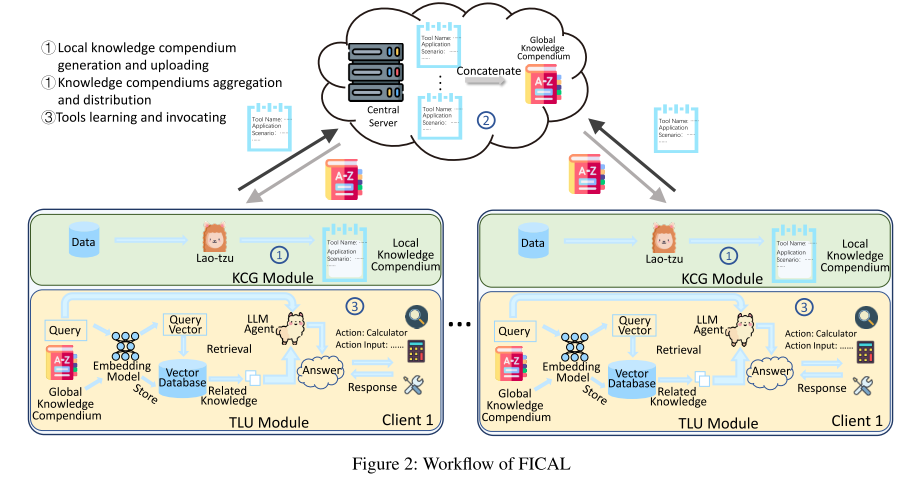
1. 本地知识汇编生成(Local Knowledge Compendium Generation)
-
每个客户端 i 根据自己的本地数据集生成 本地知识汇编 ζi。
-
核心工具是 KCG 模块(Knowledge Compendium Generation),由一个 LLM(这里叫 Lao-tzu)生成。
-
生成流程:
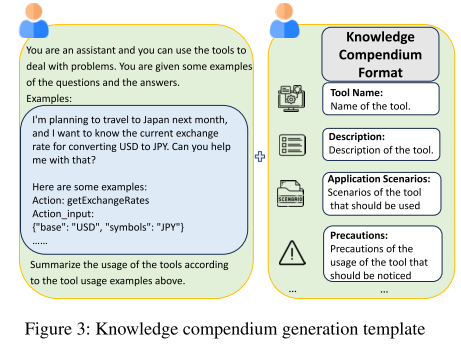
-
输入 本地示例(用户指令 + 对应答案,包括工具名称和参数)
-
LLM 提取 工具使用知识,不会包含用户隐私
-
输出结构化知识汇编:
-
desi:工具功能描述
-
appi:应用场景
-
prei:使用注意事项
-
cooi:不同工具协作使用方法
-
-
-
最终汇编形式:
![]()
核心作用:将本地私有数据转化为安全、可共享的知识形式,避免泄露隐私。
2. 全局知识汇编生成与下发(Global Knowledge Compendium)
-
客户端上传本地知识汇编到 中央服务器
-
服务器将所有客户端的知识汇编拼接成 全局知识汇编 ζg:
![]()
-
全局知识汇编再下发给客户端
-
作用:整合所有客户端的工具使用知识,形成统一的“知识库”,方便所有客户端学习。
3. 工具学习与使用(Tool Learning & Utilization)
-
客户端将全局知识汇编转为向量形式并存入向量数据库(使用 embedding 模型如 bge-large-en-v1.5)
-
使用 RAG-based Tool Learning & Utilizing (TLU) 模块:
-
用户或任务产生查询 → 转为查询向量
-
在向量数据库中检索与查询最相关的知识
-
LLM 利用检索到的信息学习和使用工具
-
-
核心优势:
-
避免 LLM 在长上下文中注意力分散
-
聚焦有用信息,提高工具使用效果
-
保持数据隐私(直接原始数据不上传)
-
实验
实验设置
1. 数据集(Datasets)
-
使用 (Tang et al. 2023) 的方法生成数据集。
-
从 公共 API 中选择 M 个工具集,每个工具集包含同一领域的多个工具(如狗相关工具集:狗品种信息、喂养方法等)。
-
仿真环境:
-
一个外部 LLM 模拟工具的返回结果
-
LLM agent 与工具交互产生 trace
-
用一个 judge LLM(实验中用 DeepSeek-v2)来评估 LLM agent 是否正确使用工具
-
-
默认实验参数:
-
客户端数量:5
-
工具集数量:5
-
使用 4-bit NF4 量化
-
LoRA 参数微调(只微调 LoRA,节省资源)
-
FICAL 在无关数据集上做额外训练以提升 LLM agent 的输出格式能力
-
训练轮次:50 个通信轮,每轮客户端本地训练 5 个 epoch
-
模型:LLaMA3-8B
-
2. 对比基线(Baselines)
为了验证 FICAL 的有效性,比较工具使用成功率,选取以下 SOTA FL 方法:
-
FedACG:通过广播全局模型 + lookahead gradient 提升收敛和稳定性
-
FedDecorr:局部训练加入正则项,促进特征表示维度不相关
-
FedLoRA:研究在联邦场景下微调预训练 LLM 的方法
-
FedAdam:Adam 优化器的联邦版本
-
FedYogi:Yogi 优化器的联邦版本,处理非 IID 数据和客户端能力差异
-
FedProx:在优化目标中加入 proximal 项,稳定训练、提升收敛
实验结果
1. 通信资源消耗(Communication Resource Consumption)

-
FICAL 消耗最少通信资源:
-
节省通信资源约 3.33×1053.33 \times 10^53.33×105 倍,相比传统 FL 方法大幅度降低开销。
-
-
原因:
-
传统 FL 需要多轮传递大模型参数(LLM 参数量巨大,通信开销线性增加)。
-
FICAL 只传输 知识汇编(Knowledge Compendium),只需 一轮通信,通信开销不会随模型参数增长而增加。
-
2. 客户端数据持有不同工具集的实验

-
每个客户端只有一个工具集数据:
-
FICAL 准确率最高:57.61%
-
其他 baselines:26.09%~43.48%
-
FICAL 提升:14.13%~31.52%
-
-
每个客户端有多个工具集数据(2 个工具集):
-
FICAL 相比 baselines 提升 9.35%~16.82%
-
说明 FICAL 在 异构数据环境下 依然鲁棒。
-
3. 不同量化等级下的性能
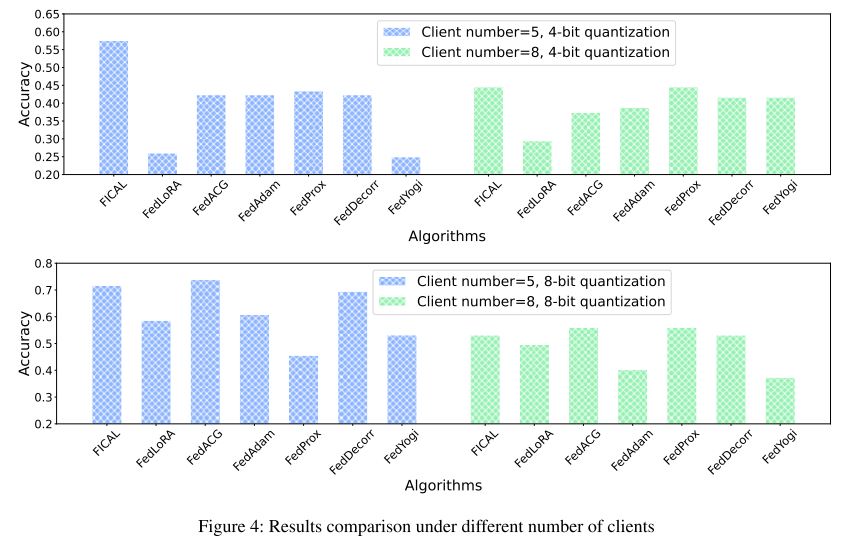
-
测试 4-bit (NF4) 与 8-bit (NF8) 量化:
-
4-bit:FICAL 准确率 57.61%(5 客户端),44.60%(8 客户端)
-
8-bit:FICAL 准确率 71.74%(5 客户端),53.24%(8 客户端)
-
-
发现:
-
8-bit 精度更高,性能优于 4-bit
-
量化虽然节省内存,但低位量化可能造成精度下降或梯度问题。
-
4. 客户端数量影响
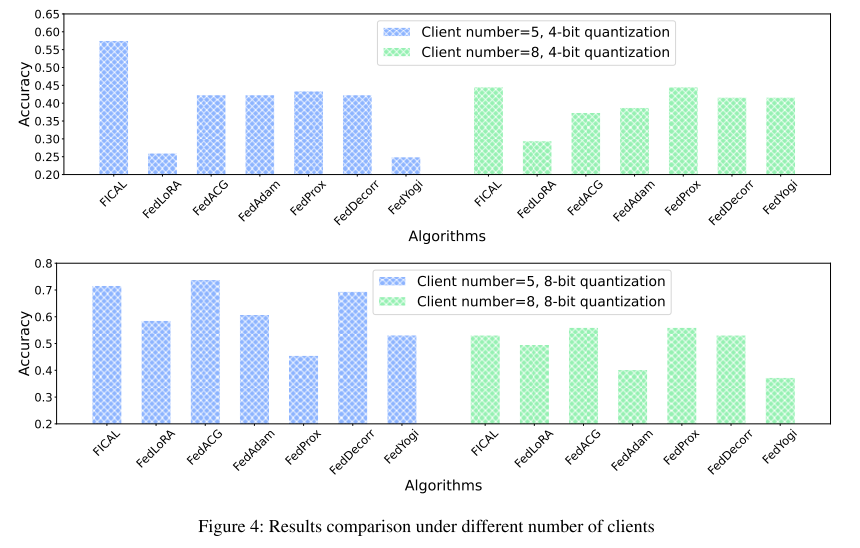
-
测试不同客户端数量(5 和 8):
-
FICAL 在不同规模下仍能保持 竞争力的准确率,说明算法可扩展。
-
5. 是否使用 RAG(Retrieval-Augmented Generation)对性能的影响

-
FICAL + RAG vs FICAL without RAG:
-
使用 RAG 提升准确率 7.6%
-
说明 TLU 模块(RAG-enhanced Tool Learning)设计有效,能从全球知识汇编中提取有用信息,避免注意力分散。
-
补充
1. 本地知识汇编生成(Local Knowledge Compendium)
假设每个客户端都有自己的文本分类数据集,任务是把新闻分成 体育、科技、娱乐。
-
客户端 1 的本地数据:
| 文本 | 标签 |
|---|---|
| “梅西进球帮助球队获胜” | 体育 |
| “新 iPhone 发布,性能提升” | 科技 |
-
KCG 模块提炼出的知识汇编 ζ1:
des1(工具功能描述): - classifySportsNews(text) -> 判断是否体育新闻 - classifyTechNews(text) -> 判断是否科技新闻
app1(应用场景): - 如果新闻内容涉及比赛、球员、球队 -> 用 classifySportsNews - 如果新闻内容涉及科技产品、公司发布 -> 用 classifyTechNews
pre1(使用注意事项): - classifySportsNews 需包含运动相关关键词 - classifyTechNews 需包含科技相关词汇
coo1(工具协作方法): - 先用 classifyTechNews 判断是否科技新闻,如果不是,再用 classifySportsNews 判断是否体育新闻
核心:把原始文本数据变成 可操作工具/规则知识,没有上传任何具体文本本身。
2. 全局知识汇编生成与下发(Global Knowledge Compendium)
-
客户端 2 的数据(娱乐新闻):
| 文本 | 标签 |
|---|---|
| “最新电影票房破亿” | 娱乐 |
| “明星发布新单曲” | 娱乐 |
-
提炼出的 ζ2:
des2: - classifyEntertainment(text) -> 判断是否娱乐新闻
app2: - 新闻涉及电影、音乐、明星 -> 用 classifyEntertainment
pre2: - 需包含娱乐相关关键词
coo2: - 如果 classifySportsNews 和 classifyTechNews 都不匹配,再用 classifyEntertainment
-
服务器合并所有客户端的知识汇编:
ζg = { ζ1, ζ2 }
-
下发给每个客户端,形成全局知识库,包含体育、科技、娱乐分类工具知识。
3. 工具学习与使用(Tool Learning & Utilization)
当客户端收到新文本需要分类:
-
新文本:
“苹果发布新款 MacBook,性能大幅提升” -
RAG 检索过程:
-
文本转为向量query
-
query在向量数据库中检索相关知识
-
发现ζg 中 classifyTechNews 的知识(判断是否有关科技新闻)与query最相关
-
-
LLM 使用 classifyTechNews 判断新闻类别为科技
-
-
好处:
-
LLM 不用看 ζg 中所有规则,只关注最相关部分
-
所有客户端都能用到科技、体育、娱乐的规则
-
不需要访问其他客户端的原始新闻数据,保护隐私
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 40
40 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)