【推荐系统】推荐召回算法(一):双塔召回模型训练与推理(Dual Tower Model and Faiss Retrieval)
本文为推荐系统召回算法的第一篇,主要从双塔召回模型原理、网络结构、离线训练、在线Faiss索引、代码实践等方面对双塔模型召回进行描述,期待您的关注。
目录
二、双塔模型(Dual Tower Model,双塔模型 )
一、引言
前几篇通过样本加权、底层硬共享、MoE、MMoE、CGC、PLE等精排多目标方法对复杂精排模型(深度+多任务)进行原理+代码级的讲解,今天开始让我们把注意力挪到召回环节,学习使用pytorch实现双塔召回模型,同时生成训练样本数据及预估测试数据,并建立faiss索引应用示例,能够达到通过用户emb快速召回对应的item物品的目的。
二、双塔模型(Dual Tower Model,双塔模型 )
2.1 双塔模型——离线训练
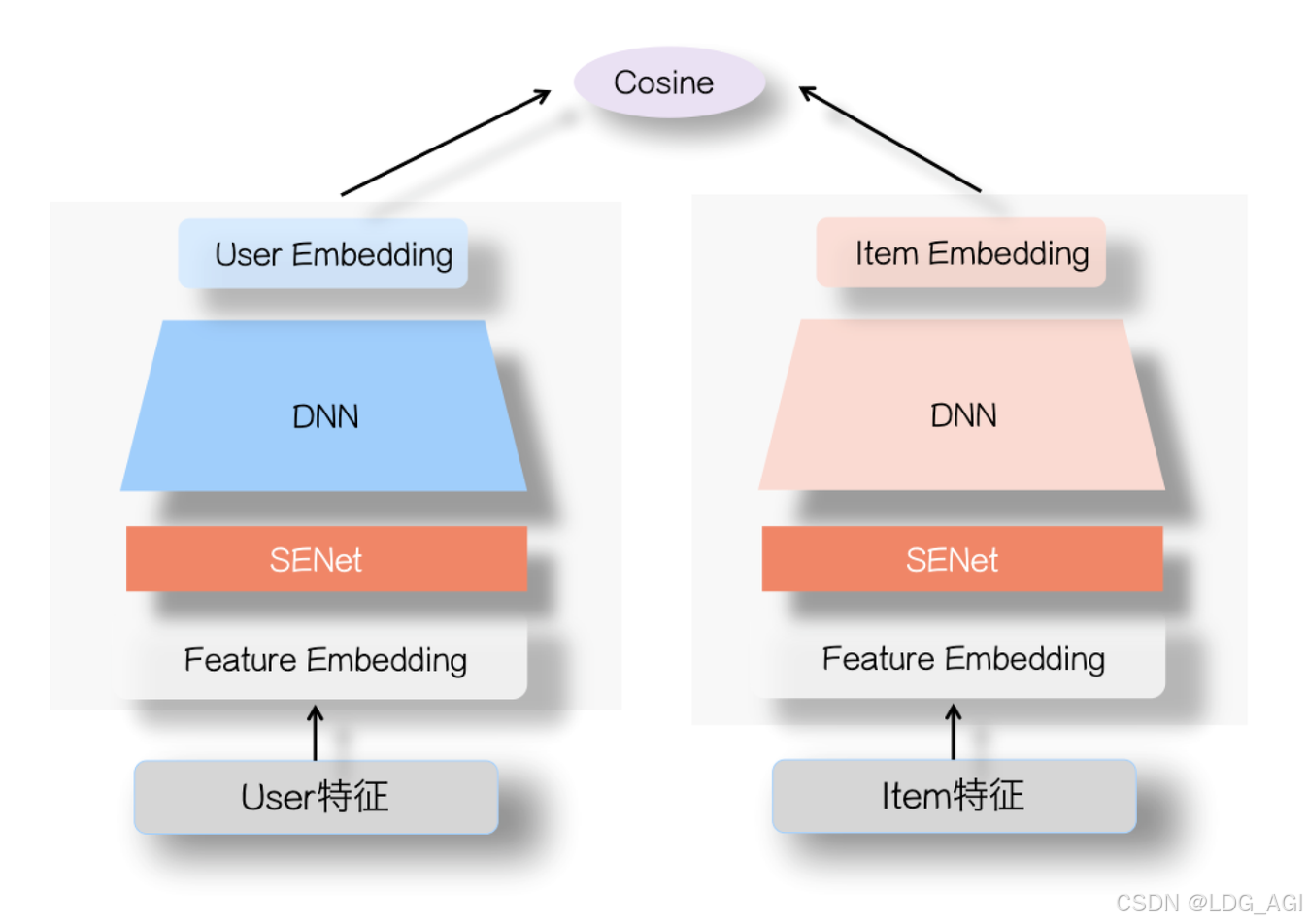
双塔模型结构非常简单,如下图所示,左侧是用户塔,右侧是Item塔,可将特征拆分为两大类:用户相关特征(用户基本信息、群体统计属性以及行为过的Item序列等)与Item相关特征(Item基本信息、属性信息等),原则上,Context上下文特征可以放入用户侧塔。对于这两个塔本身,则是经典的DNN模型,从特征OneHot到特征Embedding,再经过几层MLP隐层,两个塔分别输出用户Embedding和Item Embedding编码。在训练过程中,User Embedding和Item Embedding做内积或者Cosine相似度计算(注:Cosine相当于对User Embedding和Item Embedding内积基础上,进行了两个向量模长归一化,只保留方向一致性不考虑长度),使得用户和正例Item在Embedding空间更接近,和负例Item在Embedding空间距离拉远。损失函数则可用标准交叉熵损失,将问题当作一个分类问题,或者类似DSSM采取BPR或者Hinge Loss,将问题当作一个表示学习问题。
2.2 双塔模型——在线推理(Faiss检索库应用)
一般在推荐的模型召回环节应用双塔结构的时候,分为离线训练和在线应用两个环节。2.1基本已描述了离线训练过程,至于在线应用,主要依赖于Faiss(Facebook AI Similarity Search),一般是这么用的:
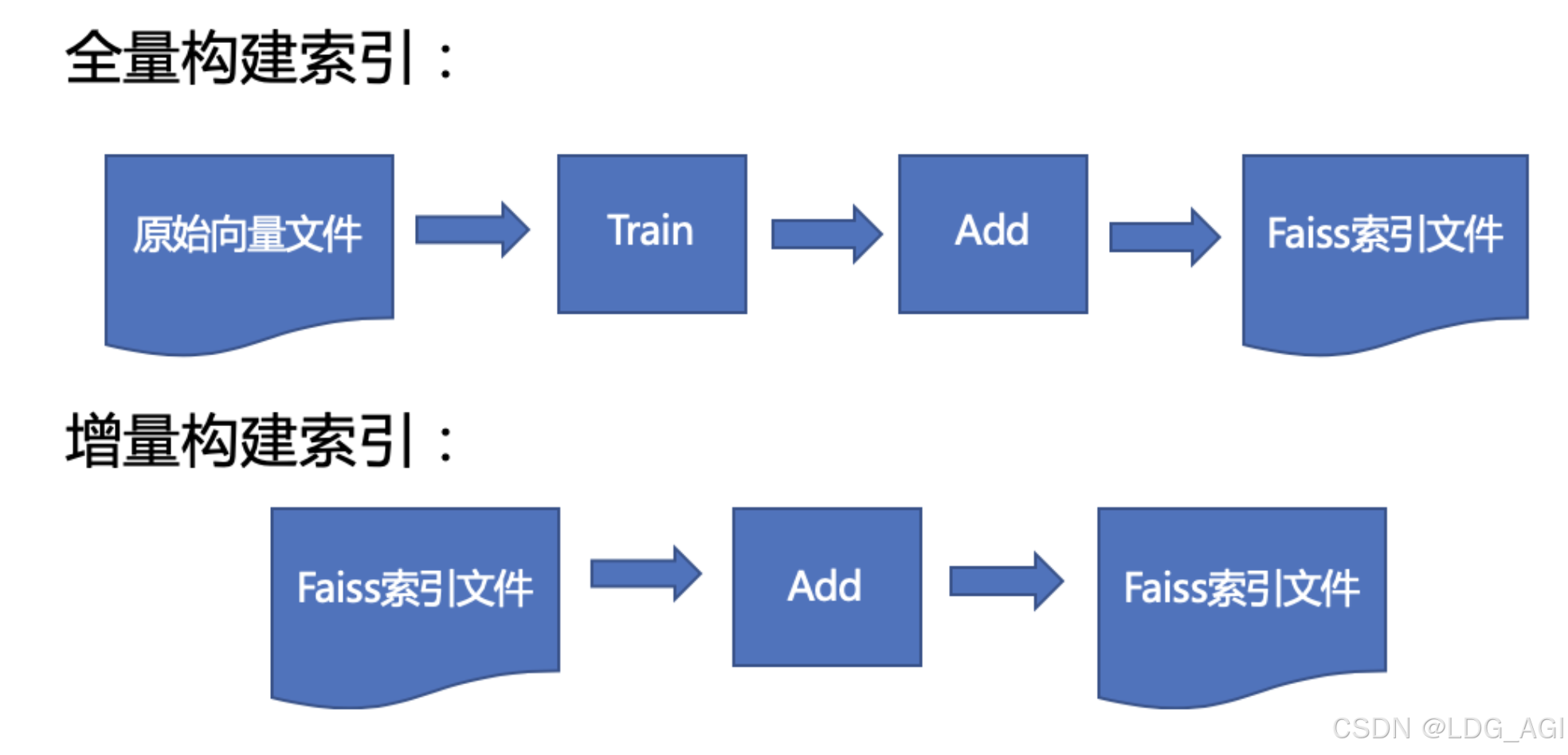
- 首先,通过训练数据,训练好User侧和Item侧两个塔模型,我们要的是训练好后的这两个塔模型,让它们各自接受用户或者Item的特征输入,能够独立打出准确的User Embedding或者Item Embedding。
- 之后,对于海量的候选Item集合,可以通过Item侧塔,离线将所有Item转化成Embedding,并存储进ANN检索系统,比如FAISS,以供查询。为什么双塔结构用起来速度快?主要是类似FAISS这种ANN检索系统对海量数据的查询效率高。
- 再往后,某个用户的User Embedding,一般要求实时更新,以体现用户最新的兴趣。为了达成实时更新的目的,你有几种难度不同的做法:
- 在线学习:比如你可以通过在线模型来实时更新双塔的参数来达成这一点,这是在线模型的路子;
- 特征实时:但是很多情况下,并非一定要采取在线模型,毕竟实施成本高,而可以固定用户侧的塔模型参数,采用在输入端,将用户最新行为过的Item做为用户侧塔的输入,然后通过User侧塔打出User Embedding,这种模式。这样也可以实时地体现用户即时兴趣的变化,这是特征实时的角度,做起来相对简单。
- 最后,有了最新的User Embedding,就可以从FAISS库里拉取相似性得分Top K的Item,做为个性化召回结果。
2.3 双塔模型——优缺点
2.3.1 优点
快!
在面临海量候选数据进行粗筛的场景下,它的速度太快了,效果说不上极端好,但是毕竟是个有监督学习过程,一般而言也不差,实战价值很高,这个是根本。若一个应用场景有如下需求:应用面临大量的候选集合,首先需要从这个集合里面筛选出一部分满足条件的子集合,缩小筛查范围。那么,这种应用场景就比较适合用双塔模型。
2.3.2 缺点
第一个问题,匹配特征缺失,影响效果:我们一般在做推荐模型的时候,会有些特征工程方面的工作,比如设计一些User侧特征和Item侧特征的组合特征,一般而言,这种来自User和Item两侧的组合特征是非常有效的判断信号。但是,如果我们采用双塔结构,这种人工筛选的,来自两侧的特征组合就不能用了,因为它既不能放在User侧,也不能放在Item侧,这是特征工程方面带来的效果损失。当然,这个问题不是最突出的,应该有办法绕过去,或者模型能力强,把组合特征拆成两个分离的特征,各自放在对应的两侧,可以让模型去捕获这种组合特征。
第二个问题,特征交叉过晚,影响效果:如果是精排阶段的DNN模型,来自User侧和Item侧的特征,在很早的阶段,比如第一层MLP隐层,两者之间就可以做细粒度的特征交互。但是,对于双塔模型,两侧特征什么时候才能发生交互?只有在User Embedding和Item Embedding发生内积的时候,两者才发生交互,而此时的User Embedding和Item Embedding,已经是两侧特征经过多次非线性变换,糅合出的一个表征用户或者Item的整体Embedding了,细粒度的特征此时估计已经面目模糊了,就是说,两侧特征交互的时机太晚了。我们知道,User侧和Item侧特征之间的交互,是非常有效的判断信号。而很多领域的实验已经证明,双塔这种过晚的两侧特征交互,相对在网络结构浅层就进行特征交互,会带来效果的损失。这个问题比较严重。
为了速度快,必须对user和Item进行特征分离,而特征分离,又必然导致上述两个原因产生的效果损失。
2.4 业务代码实践
2.4.1 模型代码实现
基于PyTorch实现一个双塔召回模型。双塔模型由两个神经网络(用户塔和物品塔)组成,分别生成用户和物品的嵌入向量。然后,我们通过计算用户嵌入和物品嵌入的点积(或余弦相似度)来预测用户对物品的偏好,如下:
import torch
import torch.nn as nn
import numpy as np
import faiss
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, Dataset
# 配置参数
EMBEDDING_DIM = 64
NUM_USERS = 10000
NUM_ITEMS = 5000
BATCH_SIZE = 1024
EPOCHS = 10
# ======================
# 1. 生成模拟数据
# ======================
class InteractionDataset(Dataset):
def __init__(self, user_ids, item_ids, labels):
self.user_ids = user_ids
self.item_ids = item_ids
self.labels = labels
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
return {
"user_id": self.user_ids[idx],
"item_id": self.item_ids[idx],
"label": self.labels[idx]
}
# 生成用户和物品的模拟特征(实际应用中替换为真实特征)
user_features = torch.randn(NUM_USERS, EMBEDDING_DIM)
item_features = torch.randn(NUM_ITEMS, EMBEDDING_DIM)
# 创建模拟交互数据(1:交互过,0:未交互)
user_ids = torch.randint(0, NUM_USERS, (NUM_USERS * 10,))
item_ids = torch.randint(0, NUM_ITEMS, (NUM_USERS * 10,))
labels = torch.ones(NUM_USERS * 10)
# 添加负样本(实际应用中采用更复杂的负采样策略)
neg_item_ids = torch.randint(0, NUM_ITEMS, (NUM_USERS * 10,))
user_ids = torch.cat([user_ids, user_ids])
item_ids = torch.cat([item_ids, neg_item_ids])
labels = torch.cat([labels, torch.zeros(NUM_USERS * 10)])
# 分割数据集
train_u, test_u, train_i, test_i, train_l, test_l = train_test_split(
user_ids.numpy(), item_ids.numpy(), labels.numpy(), test_size=0.2
)
# 创建数据加载器
train_dataset = InteractionDataset(train_u, train_i, train_l)
test_dataset = InteractionDataset(test_u, test_i, test_l)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE)
# ======================
# 2. 双塔模型定义
# ======================
class TwoTowerModel(nn.Module):
def __init__(self, embedding_dim, num_users, num_items):
super().__init__()
# 用户塔
self.user_embedding = nn.Embedding(num_users, embedding_dim)
self.user_fc = nn.Sequential(
nn.Linear(embedding_dim, embedding_dim),
nn.ReLU(),
nn.Linear(embedding_dim, embedding_dim)
)
# 物品塔
self.item_embedding = nn.Embedding(num_items, embedding_dim)
self.item_fc = nn.Sequential(
nn.Linear(embedding_dim, embedding_dim),
nn.ReLU(),
nn.Linear(embedding_dim, embedding_dim)
)
def forward_user(self, user_ids):
embeds = self.user_embedding(user_ids)
return self.user_fc(embeds)
def forward_item(self, item_ids):
embeds = self.item_embedding(item_ids)
return self.item_fc(embeds)
def forward(self, user_ids, item_ids):
user_emb = self.forward_user(user_ids)
item_emb = self.forward_item(item_ids)
return (user_emb * item_emb).sum(dim=1) # 点积相似度
model = TwoTowerModel(EMBEDDING_DIM, NUM_USERS, NUM_ITEMS)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.BCEWithLogitsLoss()
# ======================
# 3. 模型训练
# ======================
def train_epoch(model, loader, optimizer):
model.train()
total_loss = 0
for batch in loader:
optimizer.zero_grad()
user_ids = batch["user_id"].long()
item_ids = batch["item_id"].long()
labels = batch["label"].float()
preds = model(user_ids, item_ids)
loss = loss_fn(preds, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
for epoch in range(EPOCHS):
train_loss = train_epoch(model, train_loader, optimizer)
print(f"Epoch {epoch+1}/{EPOCHS}, Train Loss: {train_loss:.4f}")
# ======================
# 4. 生成物品嵌入索引
# ======================
def get_all_item_embeddings(model):
model.eval()
all_items = torch.arange(NUM_ITEMS).long()
with torch.no_grad():
item_embeddings = model.forward_item(all_items).numpy()
return item_embeddings
item_embeddings = get_all_item_embeddings(model)
# 构建FAISS索引
index = faiss.IndexFlatIP(EMBEDDING_DIM) # 内积索引
index.add(item_embeddings) # 添加物品嵌入
faiss.write_index(index, "item_index.faiss")
# ======================
# 5. 快速召回测试
# ======================
def recommend_items(user_id, top_k=10):
# 获取用户嵌入
model.eval()
with torch.no_grad():
user_embedding = model.forward_user(torch.tensor([user_id])).numpy()
# 归一化(余弦相似度需要归一化)
faiss.normalize_L2(user_embedding)
# 检索相似物品
distances, indices = index.search(user_embedding, top_k)
return indices[0], distances[0]
# 测试召回
test_user = np.random.randint(0, NUM_USERS)
recommended, scores = recommend_items(test_user)
print(f"\nTest User ID: {test_user}")
print("Top 10 Recommended Items:")
print(recommended)
print("Similarity Scores:")
print(scores)以上代码较为简单,在各位实际使用时,可以进一步优化
- 特征工程
- 替换随机特征为真实的用户/物品特征
- 加入类别特征处理(如Embedding层)
- 结合历史交互特征
- 负采样优化
- 使用困难负采样(Hard Negative Sampling)
- 采用曝光未点击样本作为负样本
- 动态负采样策略
- 模型优化
- 添加Batch Normalization/Layer Normalization
- 使用更复杂的网络结构(如ResNet块)
- 尝试其他损失函数(如Margin Loss)
- 索引更新
- 定期重新生成物品索引(小时级)
- 增量更新新物品的嵌入(在线学习)
2.4.2 模型训练与推理测试
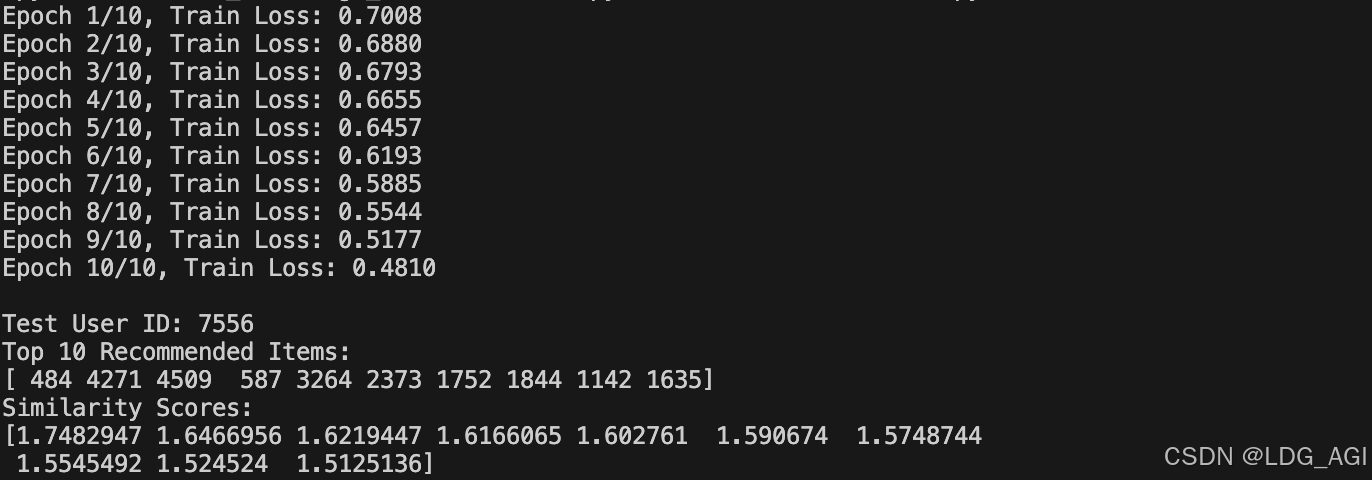
运行上述代码,模型启动训练,Loss逐渐收敛,之后将所有item的emb加载至faiss检索库,并随机抽取user id,提取user emb检索最相关的top10个item并打印相关性得分。
2.4.3 打印模型结构
TwoTowerModel(
(user_embedding): Embedding(10000, 64)
(user_fc): Sequential(
(0): Linear(in_features=64, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=64, bias=True)
)
(item_embedding): Embedding(5000, 64)
(item_fc): Sequential(
(0): Linear(in_features=64, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=64, bias=True)
)
)三、总结
本文为推荐系统召回算法的第一篇,主要从双塔召回模型原理、网络结构、离线训练、在线Faiss索引、代码实践等方面对双塔模型召回进行描述,后面还会继续对标签召回、协同过滤、u2x2i等经典召回算法进行代码级阐述,期待您的关注。
如果您还有时间,欢迎阅读本专栏的其他文章:
【深度学习】多目标融合算法(一):样本Loss加权(Sample Loss Reweight)
【深度学习】多目标融合算法(二):底部共享多任务模型(Shared-Bottom Multi-task Model)
【深度学习】多目标融合算法(三):混合专家网络MOE(Mixture-of-Experts)
【深度学习】多目标融合算法(四):多门混合专家网络MMOE(Multi-gate Mixture-of-Experts)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 56
56 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)