优化 StarRocks INSERT INTO FILES 的内存超限问题
检查 _writer_stream_pairs 中是否已有该分区的写入器 (Writer) 和流 (Stream),如果当前写入器已写入的数据量超过 _max_file_size,则:调用 writer->commit() 提交当前文件,并触发 callback_on_commit,并从 _writer_stream_pairs 中移除该分区。创建新的写入器和流,初始化新写入器,写入当前数据块,更
问题背景在 StarRocks 中,通过 ETL 处理后的结果数据需导出到 HDFS,使用 INSERT INTO FILES 语句实现。导出过程中遇到以下问题:
-
导出sql 因为 BE 内存超限导致查询失败。
- 由于线上环境采用混部部署,BE 单机配置为 20 核 CPU 和 40GB 内存。怀疑 CPU 和内存配比不足导致内存超载,因此尝试降低并发度(设置 pipeline_dop=1),但内存超限问题仍未解决。

导出 SQL 示例:
INSERT INTO FILES("path"="viewfs://xxx","format"="parquet","hadoop.proxy.user"="xxx","compression"="lz4")SELECT xxx from table_xx;
源码分析(基于 StarRocks-3.4.0)为定位问题,重点分析了Sink 相关代码,尤其是 TableFunctionTableSink 和 ConnectorChunkSink。
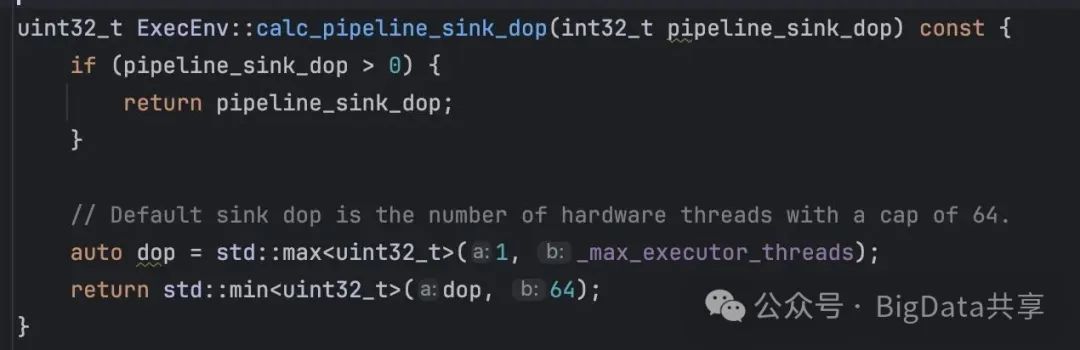
1. TableFunctionTableSinkTableFunctionTableSink 是 StarRocks 查询执行流水线中用于将数据写入目标文件的组件。在构建 Pipeline 时,Sink 的并发度由 pipeline_sink_dop 参数决定:
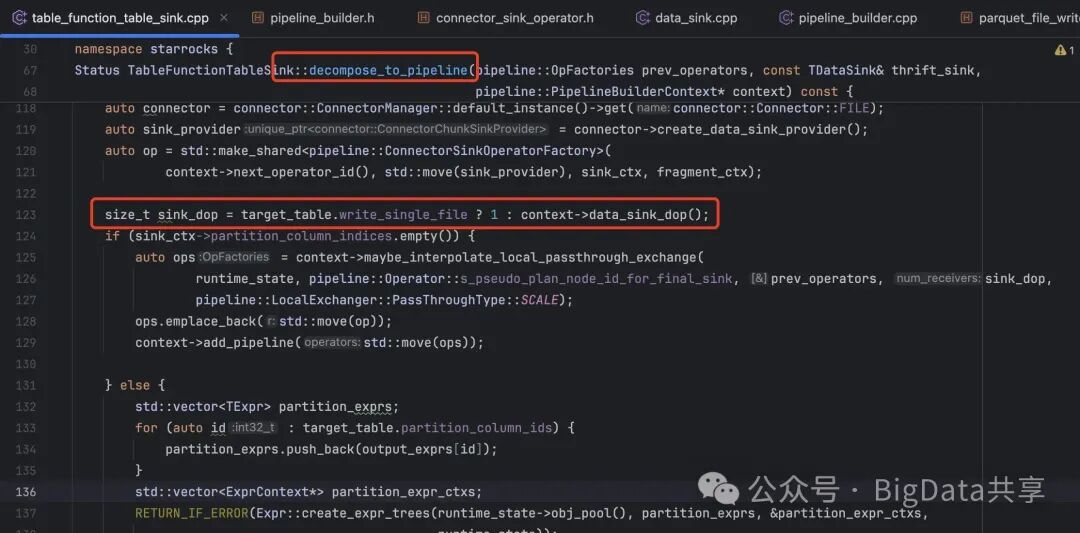
在构建pipeline的时候,如果有设置 pipeline_sink_dop,就取pipeline_sink_dop该值,否则默认并行度=cpu-cores,其中的 _max_executor_threads = CpuInfo::num_cores();
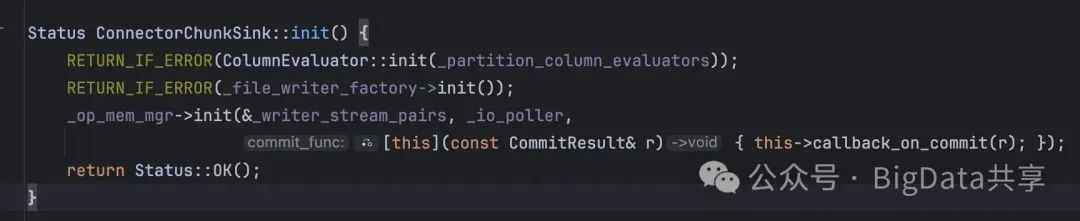
2. ConnectorChunkSink
ConnectorChunkSink 负责将数据块(Chunk)写入 HDFS 文件系统。初始化时,会根据目标文件格式(本例为Parquet)创建对应的 ParquetFileWriter。
实际的写入操作,
检查 _writer_stream_pairs 中是否已有该分区的写入器 (Writer) 和流 (Stream),如果当前写入器已写入的数据量超过 _max_file_size,则:调用 writer->commit() 提交当前文件,并触发 callback_on_commit,并从 _writer_stream_pairs 中移除该分区。创建新的写入器和流,初始化新写入器,写入当前数据块,更新 _writer_stream_pairs,并将新流加入 _io_poller 进行异步处理。
如果未超过文件大小限制,直接将数据块写入现有写入器。
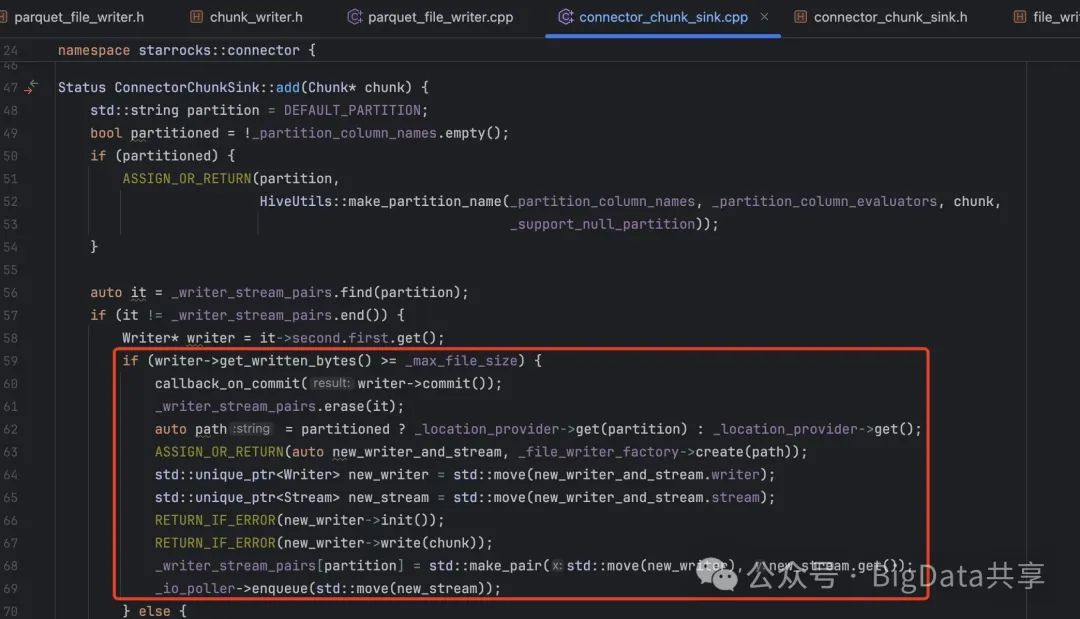
从代码中看到如果超出 _max_file_size 大小,就会提交 commit,这里的 _max_file_size 其实就是 target_max_file_size 这个参数,用来设置写入 hdfs 目标文件大小。默认值大小是 1GB。
继续查看ParquetFileWriter的写入,ParquetFileWriter下封装着一个 _rowgroup_writer,并且超过阈值后flush。
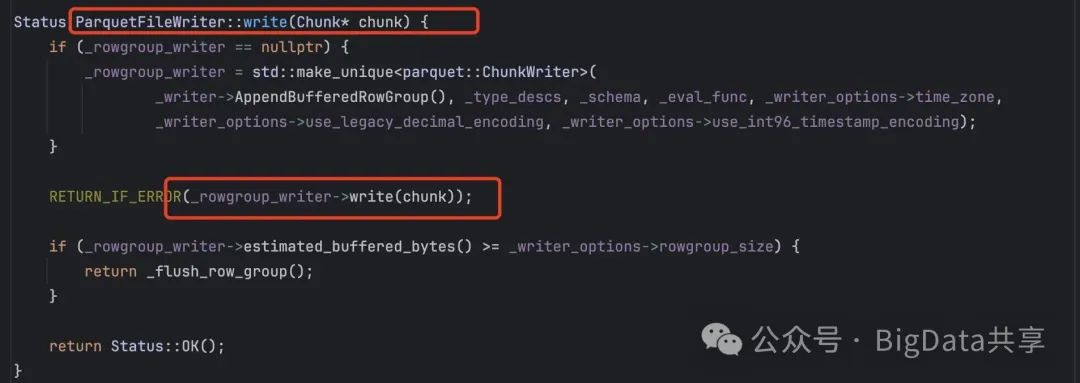
这个阈值大小是 128MB
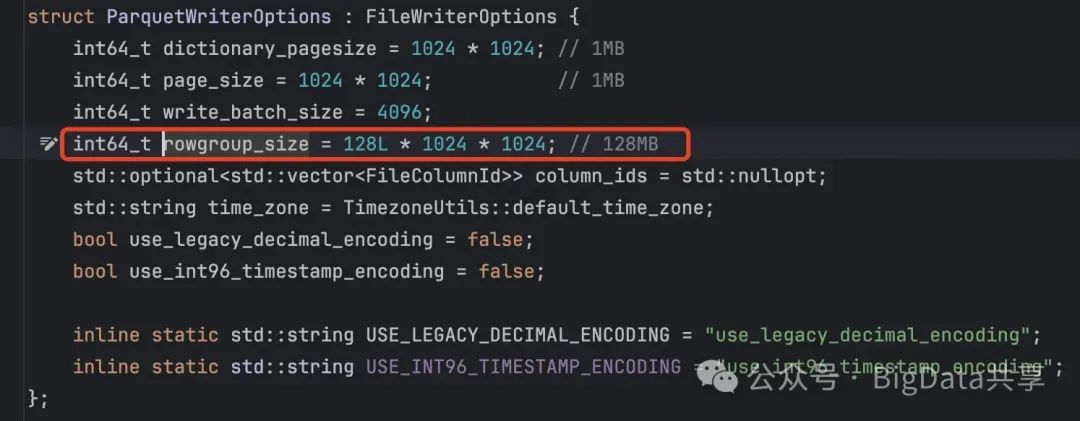
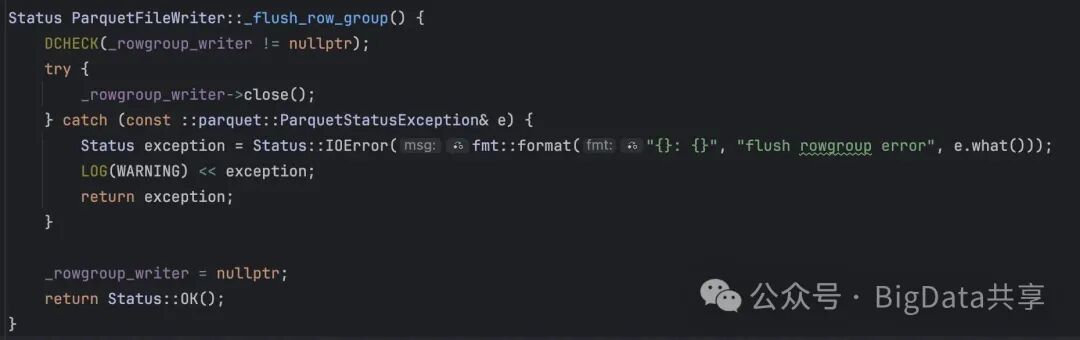
到这里大概就能知道 ParquetWriter 的写行为,当 _rowgroup_writer 满足大于128MB 进行刷盘,就会关闭当前的 _rowgroup_writer,但整个 parquetWriter 及其对应的 _output_stream 并未关闭。也就是说如果 _max_file_size 较大,当前文件的写入会持续更长时间,缓冲区中的数据会累积更多,从而占用更多的内存。
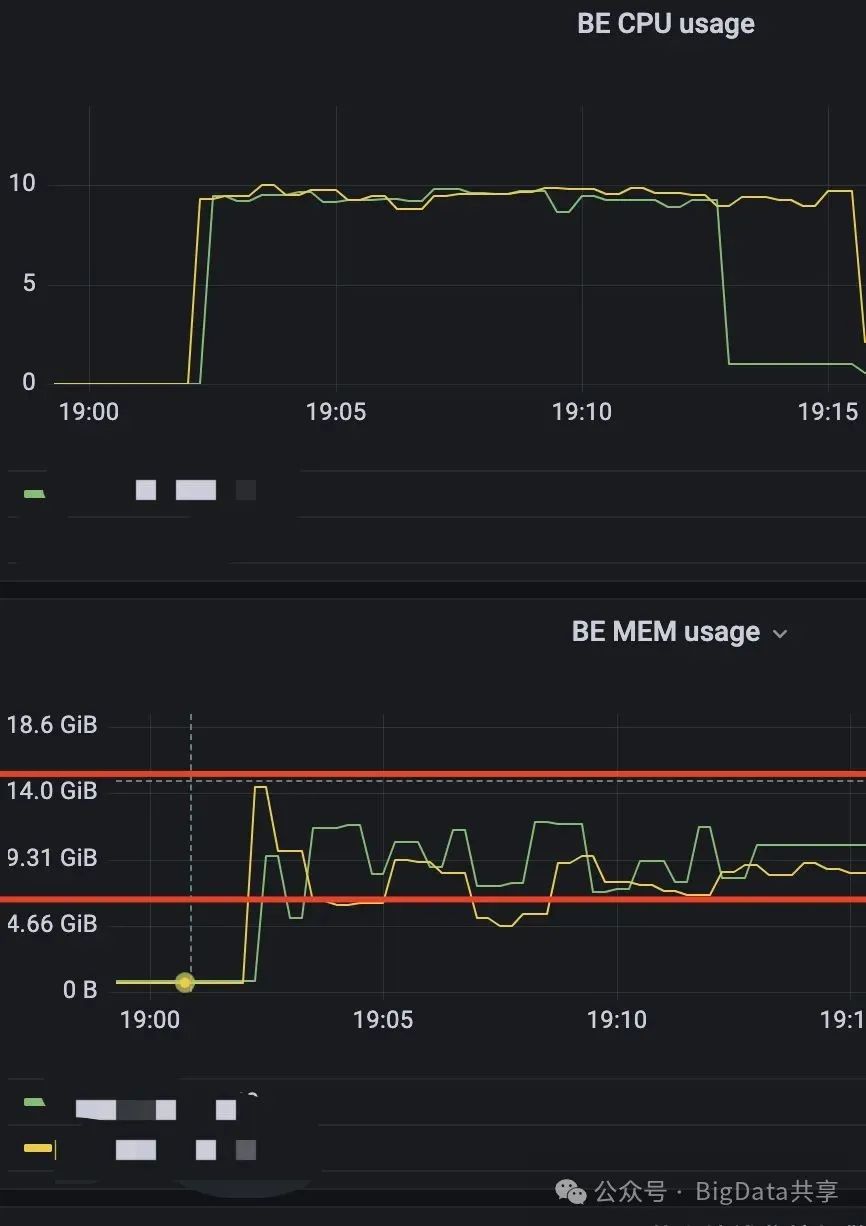
于是尝试把 target_max_file_size 往小的调,设置为 128MB,让 parquetWriter 进行更快的刷盘,BE的内存使用明显减少。
解决方案
通过分析源码,最终通过减小writer实例并发(pipeline_sink_dop),减小单个writer的目标文件大小(target_max_file_size,实际上也决定了writer的内存使用),解决insert into files 因为 BE 内存超限导致的导出失败问题。
更多大数据干货,欢迎关注我的微信公众号—BigData共享

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)