颠覆认知:提示工程未死,反而重生为计算科学,一篇讲透 Prompt 设计的科学内核
大模型多步推理能力的突破与提示设计理论框架 摘要:本文揭示了Transformer架构在数学证明、棋类推理等多步推理任务中的固有缺陷——其注意力机制的固定计算步数限制(TC⁰复杂度)无法适应动态深度的推理需求。研究提出Chain-of-Thought(CoT)通过文本外化隐状态实现虚拟循环计算,并首次建立提示设计的理论框架,证明提示作为"信息选择器"可优化推理性能超50%。实验
大型语言模型(LLM)在知识问答、文本生成等任务中表现亮眼,但面对数学证明、棋类推演这类多步推理任务时,却常显乏力、频频出错。
深究根本,问题源于Transformer架构固有的计算深度限制:其核心的注意力机制,本质上只能执行固定步数的序列计算(属于TC⁰复杂度类),无法适配多步推理任务对“动态深度”的需求。以棋类推演为例,每一步落子后棋局状态都会变化,后续推理需基于更新后的状态持续迭代——这种需要随任务进程动态调整计算步数的场景,恰好是Transformer架构的短板,最终导致LLM难以胜任复杂的多步推理。
Chain-of-Thought(CoT)提示通过生成中间推理步骤,将计算扩展到文本空间,理论上可使Transformer实现图灵完备性。但现有方法依赖"逐步思考"等通用提示,迫使模型在庞大的提示空间中盲目搜索。

- 论文:Why Prompt Design Matters and Works: A Complexity Analysis of Prompt Search Space in LLMs
- 链接:https://arxiv.org/pdf/2503.10084v2
本文首次建立提示设计的理论框架,揭示提示作为"信息选择器"的核心作用,并通过复杂度分析证明:优化提示可使推理性能提升超50%,为提示工程从经验技巧走向系统科学奠定基石。
理论基础:CoT如何突破Transformer限制
Transformer的先天缺陷
- 计算深度固化:Transformer的隐状态 h 仅在层间传递(垂直方向),而非时间步传递(水平方向)。如图2d所示,其最大序列计算步数等于层数(O(1)),无法随输入长度增长。
- 答案模式的局限:仅输出最终答案时(如"Q: 棋局状态? A: 将军"),模型需将多步计算压缩到固定深度,丢失中间状态信息。

传统Transformer(d)、无引导CoT(a)、有监督CoT(b)的对比
CoT的循环计算本质
CoT通过文本外化隐状态构建虚拟循环:
- 离散化:从隐状态 hₜ 提取关键信息 → 文本符号 (o₁…oₖ)
- 向量化:文本经嵌入层重建为下一时刻隐状态 hₜ₊₁
公式意义:
- o 是自然语言描述的中间步骤(如"白王在e4")
- 嵌入层将文本重新编码为向量,实现隐状态迭代更新
此过程模拟了RNN的 hₜ → hₜ₊₁ 循环(图3c),使Transformer获得动态计算深度。
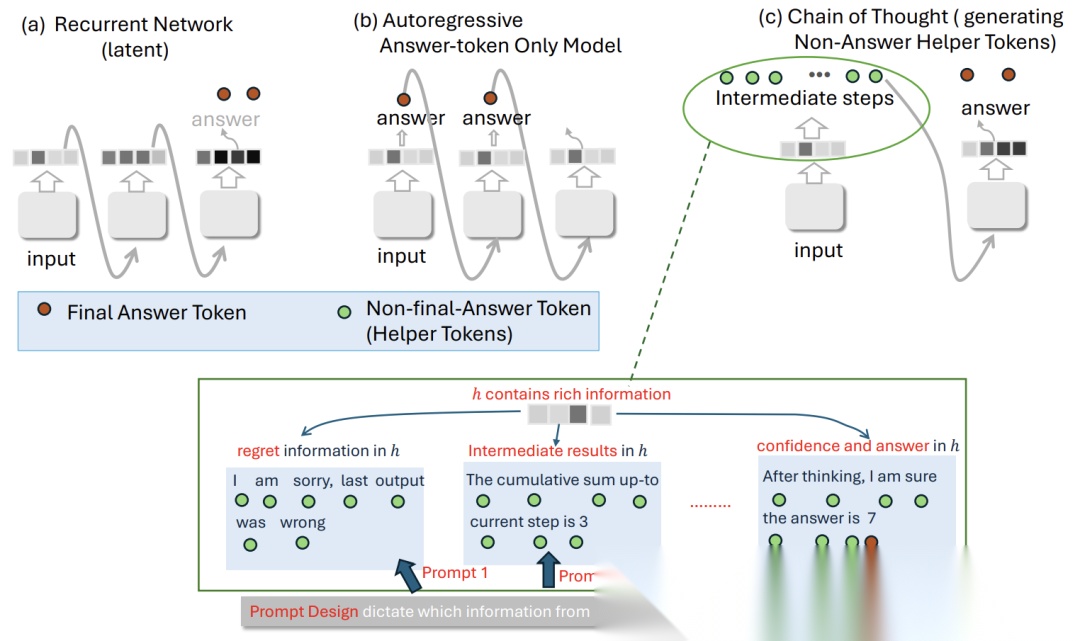
CoT(c)如何通过文本桥接模拟RNN(a)的循环计算
核心发现:提示是信息选择器
提示定义信息轨迹
隐状态 h 包含丰富信息(棋盘布局、计数器等),但单步CoT只能提取s比特(受文本长度限制)。提示模板决定提取哪些信息:
- 最优提示:如"输出当前棋盘配置",提取任务关键信息
- 次优提示:如"输出棋盘棋子数",遗漏位置关系导致推理失败
提示空间复杂度公式
符号含义:
- n:隐状态 h 的信息总量(正比于模型维度d)
- s:单步CoT可提取的信息量(正比于生成文本长度)
核心思想:
该组合数量化了从n比特中选择s比特的所有可能方式。例如: - 若 h 包含10种棋局信息(n=10),每步提取3项(s=3)→ 提示空间达120种
- 实际搜索需启发式策略,但次优提示仍导致性能崩塌(实验见Table 1)
答案空间复杂度优化
提示模板 p 直接决定答案空间结构:
意义解读:
- 𝒮:全部可能解的集合(如所有棋局路径)
- 𝒞ℛ:正确解的子集
- 最优p:缩小搜索空间(如提示"按棋盘状态推理" → 合法路径占比↑)
- 劣质p:𝒞ℛ/𝒮 趋近于0(如提示"统计棋子数" → 路径随机选择)
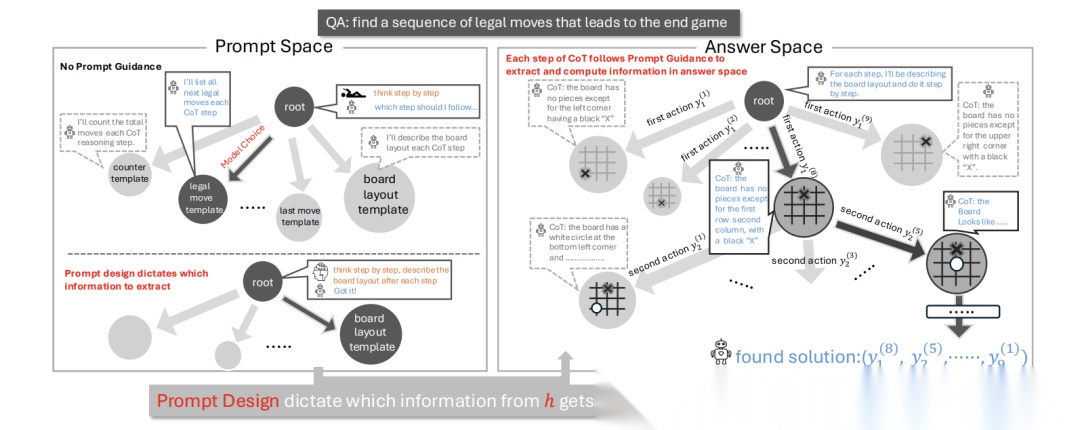
提示空间(左)与答案空间(右)的耦合关系
实验验证:监督提示的压倒性优势
任务设计精髓
- 三级计算复杂度:
- 正则语言(R):奇偶校验、循环导航
- 上下文无关(CF):栈操作、列表反转
- 上下文敏感(CS):排序、字符串复制
- 控制变量:
- 列表化输入消除tokenization干扰
- 对比监督提示/无监督提示/次优提示

列表化输入使排序任务准确率提升40%
震撼性结果
- 监督提示统治性能:
- 栈操作任务:监督提示96% vs 无监督提示0%
- 奇偶校验:监督提示100% vs 次优提示42%
- X-of-Thought的局限:
- GoT/ToT仅优化答案空间搜索,无法修复错误提示模板
- 当提示本身错误时,多路径探索反而降低效率(如栈操作任务中ToT准确率仅36%)
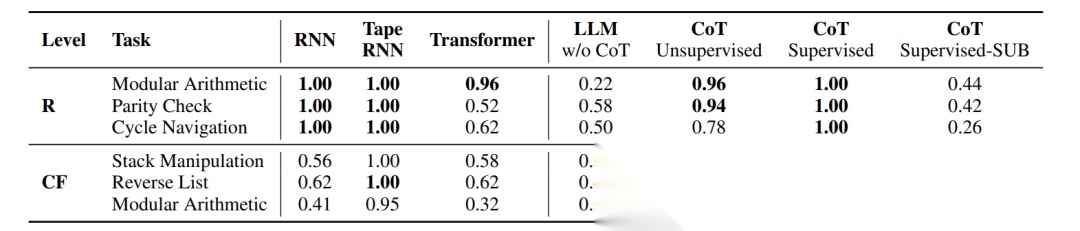
核心结论:监督提示在9类任务全面领先
典型失败模式
- 冗余生成:次优提示要求输出无关信息(如"每步输出是否吃子"),导致上下文溢出
- 递归陷阱:中间步骤本身需CoT才能解决(如计数子任务),形成死循环
Case:EP任务中次优提示要求逐步输出"ab/ba判断",模型错误计数
创新方法论:提示工程科学化
最优提示设计原则
- 核心思想:提示是信息瓶颈,需选择top-s关键信息
- 操作指南:
- 显式定义每步输出内容(如"输出当前计数器值")
- 拒绝模糊指令(如"详细思考"→改为"每步更新棋盘坐标")
实用决策框架
| 场景 | 策略 |
|---|---|
| 任务结构清晰 | 提供监督提示(如排序步骤) |
| 任务复杂不确定 | 信任模型启发式搜索 |
| 输出错误中间信息 | 立即停止人工干预 |
对X-of-Thought的重新定位
- 本质:在固定提示模板下优化答案空间搜索
- 局限:无法解决提示空间选择错误
示例:若提示要求"广度优先搜索",ToT会并行低效路径,而非切换为深度优先
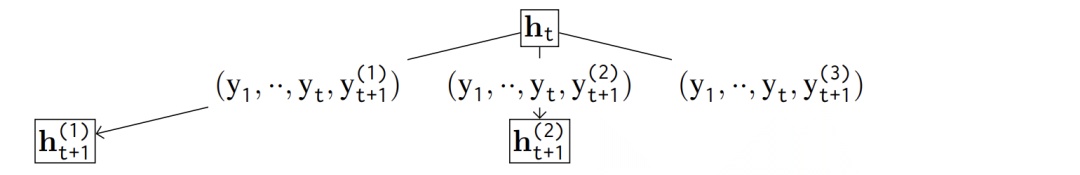
ToT在固定提示下探索答案空间的多路径
结论:从经验技巧到计算理论
本文颠覆了"提示工程是玄学"的认知,通过严谨的理论与实验揭示:
- 提示即算法:定义信息提取轨迹,控制答案空间结构
- 复杂度可量化:提示空间大小由组合数公式刻画,答案空间效率由len(CR)/len(S)|p度量
- 监督提示必要性:在结构化任务中带来50%+性能提升
这项工作将提示设计从试错艺术转变为可计算科学,为LLM在复杂推理、自主决策等场景的应用提供理论引擎。未来需探索复杂任务的提示泛化规律,并开发人机协作的提示优化框架。
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)