大模型应用开发基础知识
1.大模型应用开发基础知识
1.1基本概念和原理
基础概念
定义
大模型:大语言模型(Large Language Model,LLM)

gpt和chatgpt的区别
gpt是模型(是一个黑盒)。chatgpt是产品(给模型提供入口)

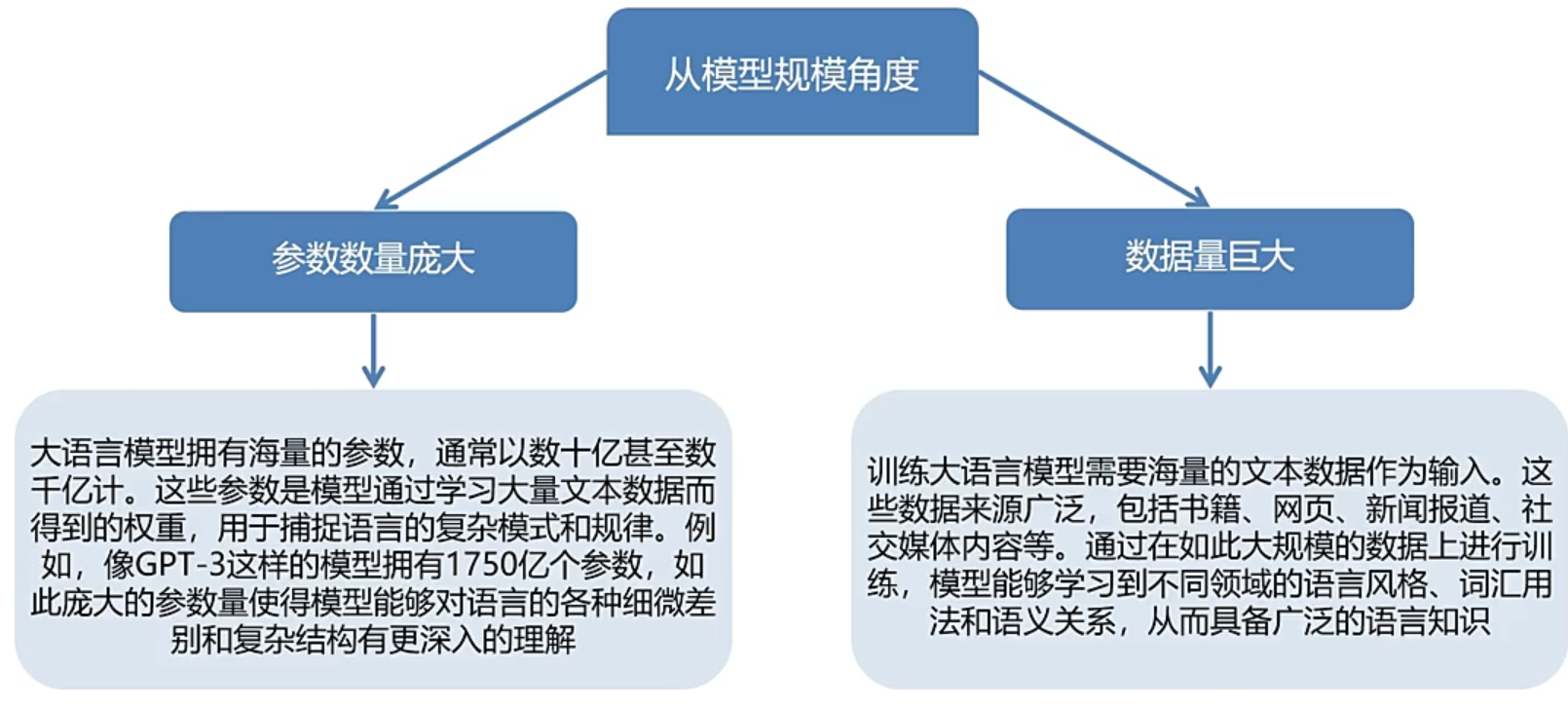
模型规模
利用海量的数据去预训练
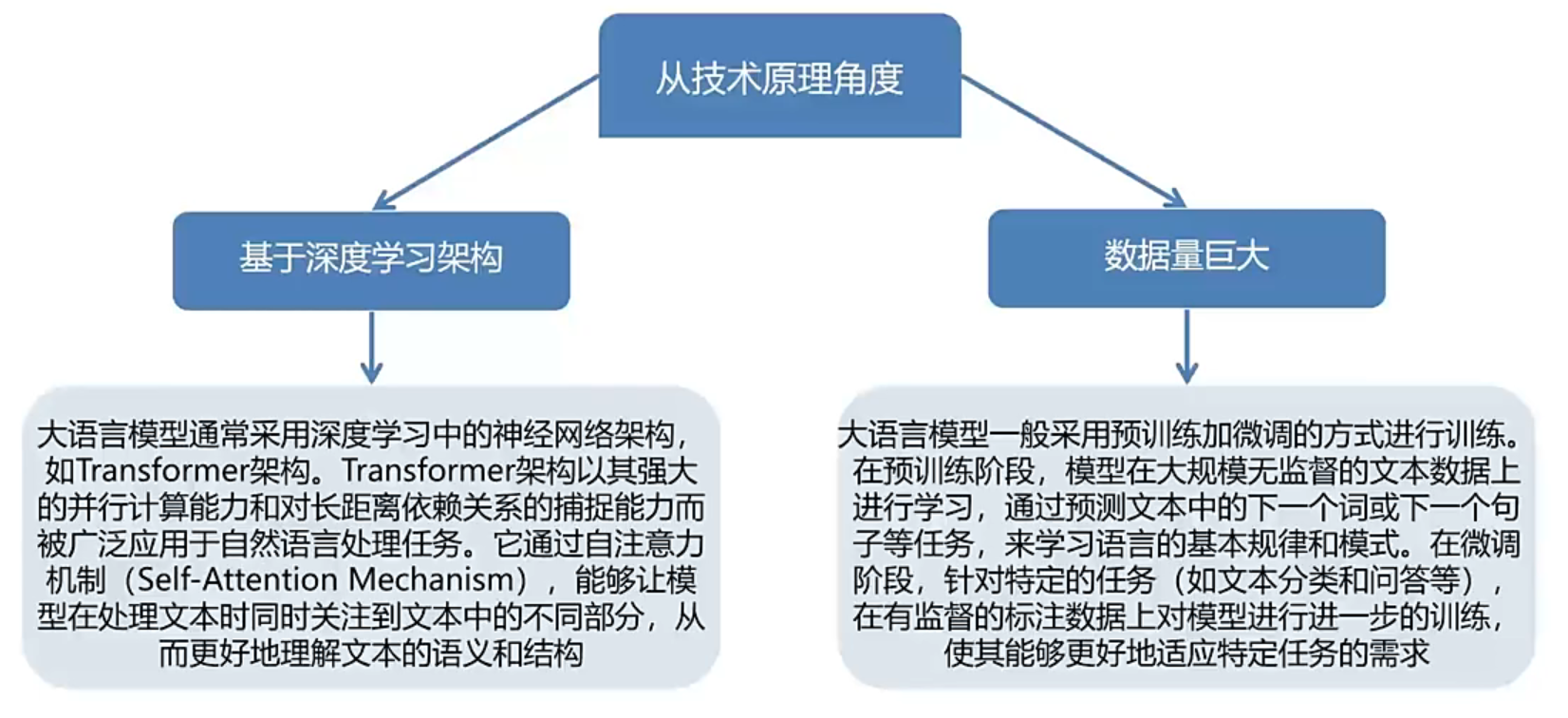
技术原理
GPT的T就是transformer【加入了自注意力机制,能够理解文本】
训练的两个阶段:
预训练:先利用大规模数据,进行无监督(无目标)学习【此时训练完是一个通用的模型】
微调:针对特定的场景和需求,进行微调,类似有监督训练【有目标】
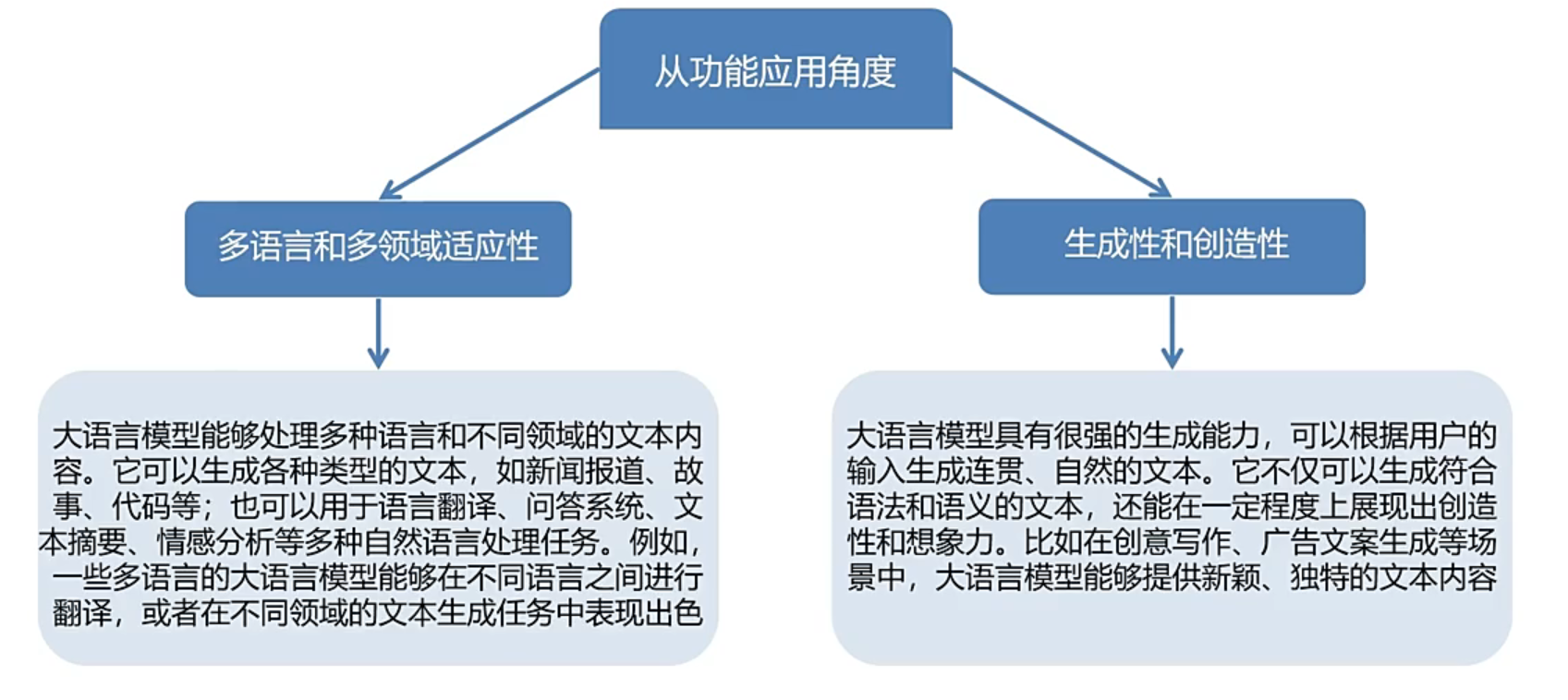
功能应用
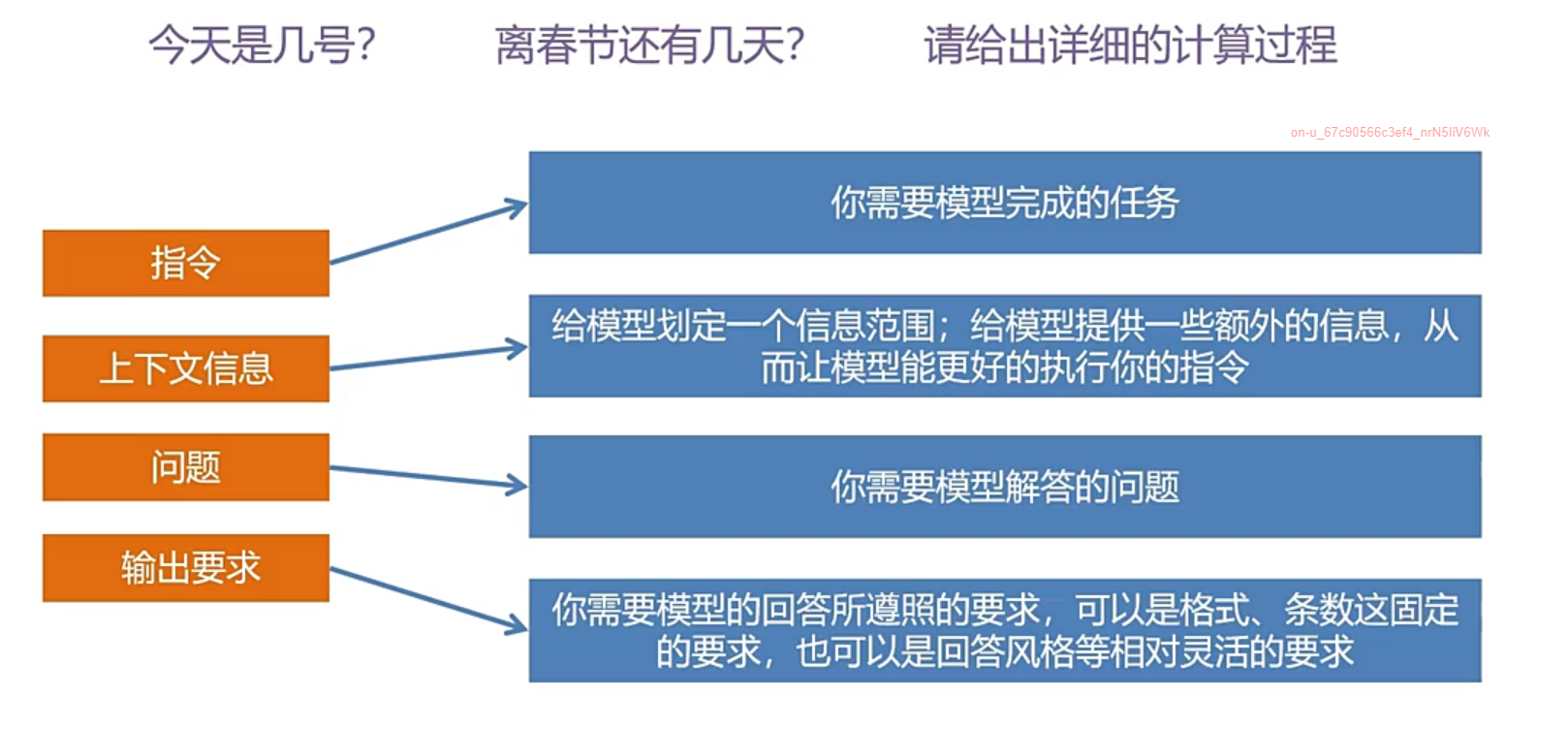
提示词
提示词有一定的要求和规范,可以得到相对满意的回答
一般的提示词的组成是:指令+上下文信息+问题+输出要求,可以明确这些
当然,有时的指令和问题是同一个,也可以缩减成三个要求。
token
token是语言模型处理文本时的一个基本的单元(是一个计量单位)
token的作用:1.文本分割和编码 2.模型训练和推理(通过大量的文本数据进行学习token之间的关系) 3.控制文本的生成长度

把控token的数量也重要:token数量过大时,计算资源消耗的越多,数量过少时,内容不够有张力,所以平衡token数量也至关重要。
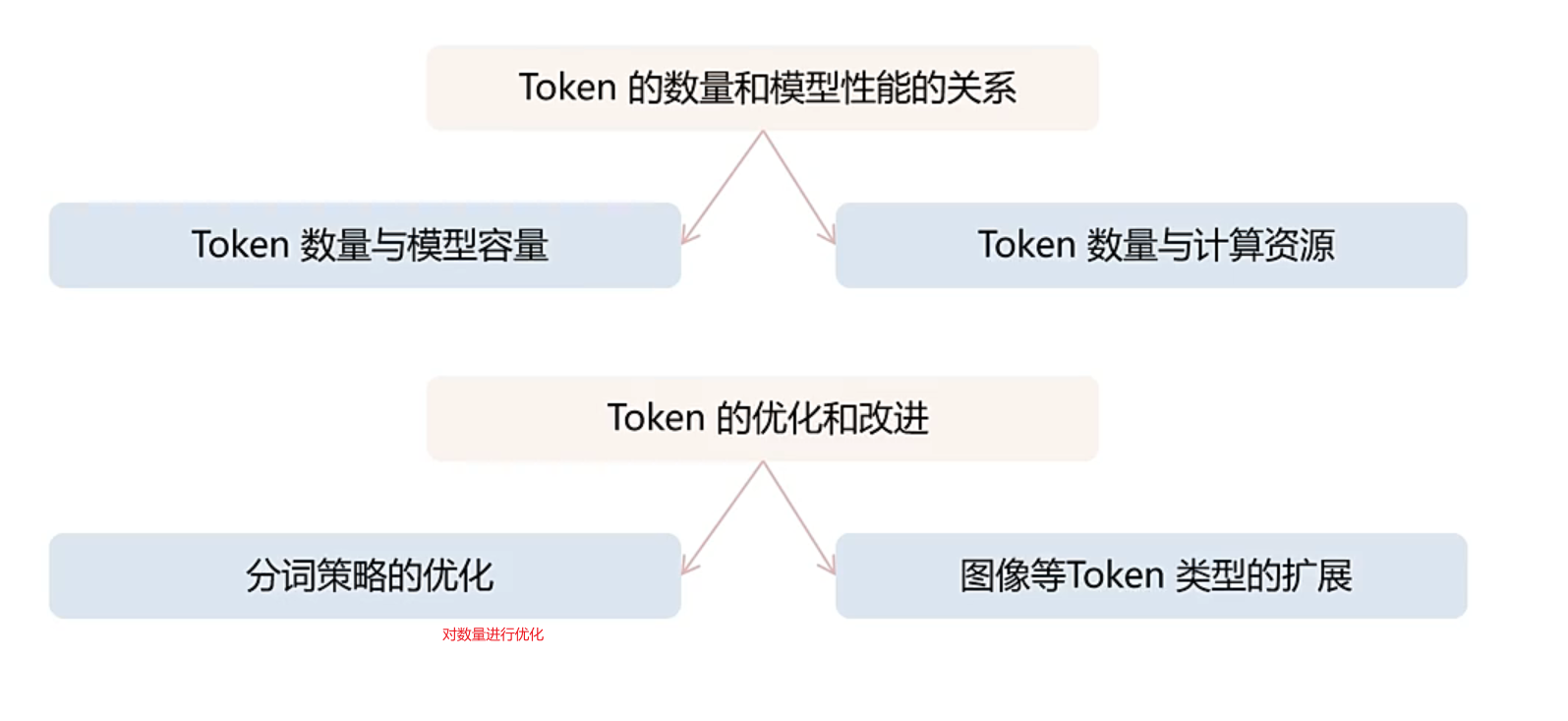
上下文长度
用token数量表示
如果模型的上下文的长度为2048个token,那么用户在做输入时,就得把控这个模型的token的长度。

微调
通过无监督的学习后,对模型进行微调,可以得到特定场景的大模型,更加适合特定任务

应用场景介绍
这个可以在学完大模型的开发后,可以根据不同的现实场景,去思考是否适合,如果不是直接适合的,那么应该如何做才能适合这个场景。

自然语言处理
传统领域




应用开发基础知识
NLP(自然语言处理)
NLP:能够让计算机理解、生成和处理人类的自然语言。

历史发展阶段

语言理解
:让计算机读得懂句子

语言生成
:使得生成的句子让人读得懂

如何表示文本内容(文本嵌入与相似度)
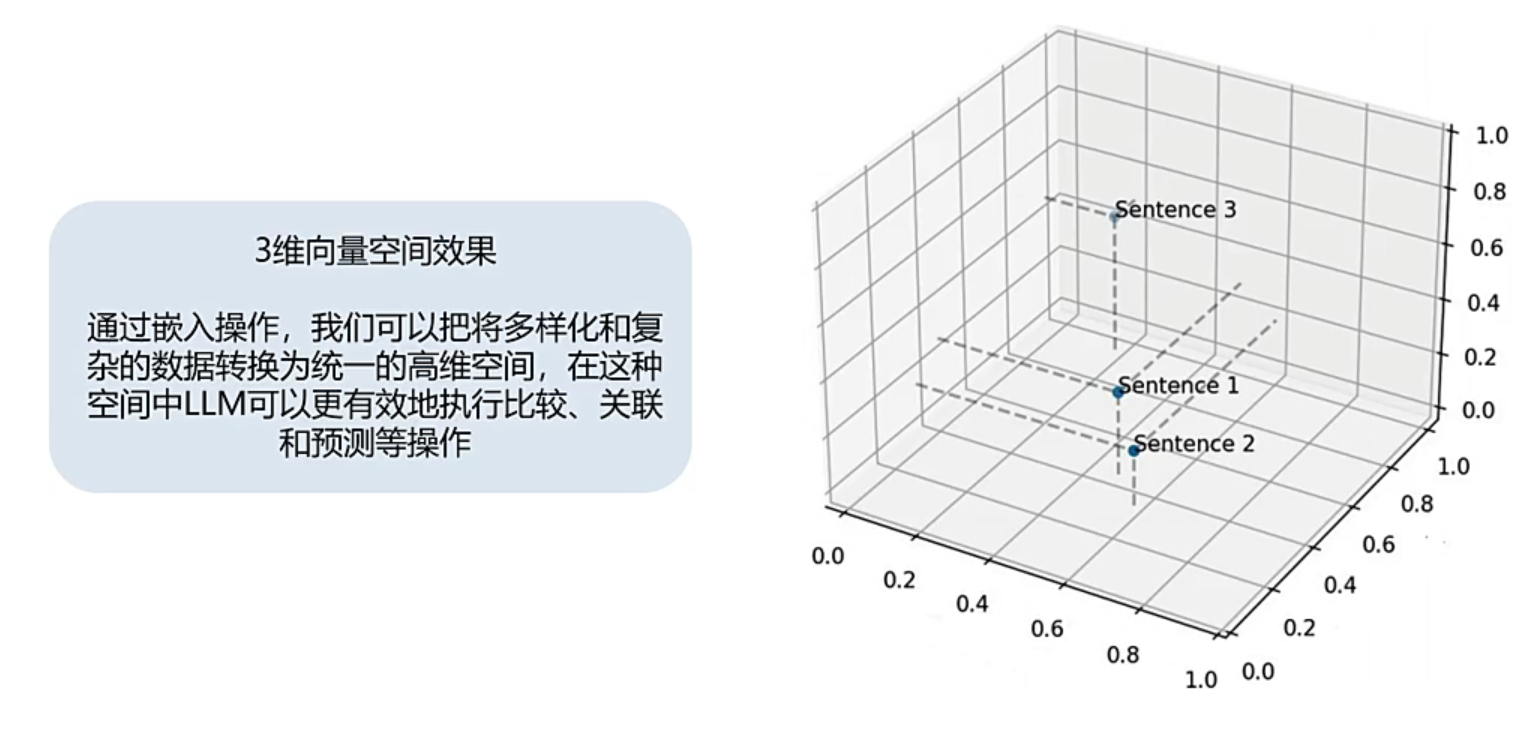
:文本向量化【文本向量表示方法/文本嵌入】
使用离散/分布式的表示方法(向量化):使得将自然语言(人类的文本) 向量化为机器语言(方便计算机读懂的语言),从而可以去训练

例子:
这里使用的是TF-IDF模型,将对应的文本转为词频(加权后的)
即存储的并不是文本,而是计算后的向量

通过潜入操作,可以将向量化后的数据转换为到一个三维空间上,这样子根据距离的远近等等,可以计算相似度
评估两个向量的相似度:
1.通过两个向量之间的角度去计算,角度越小则内容越相似
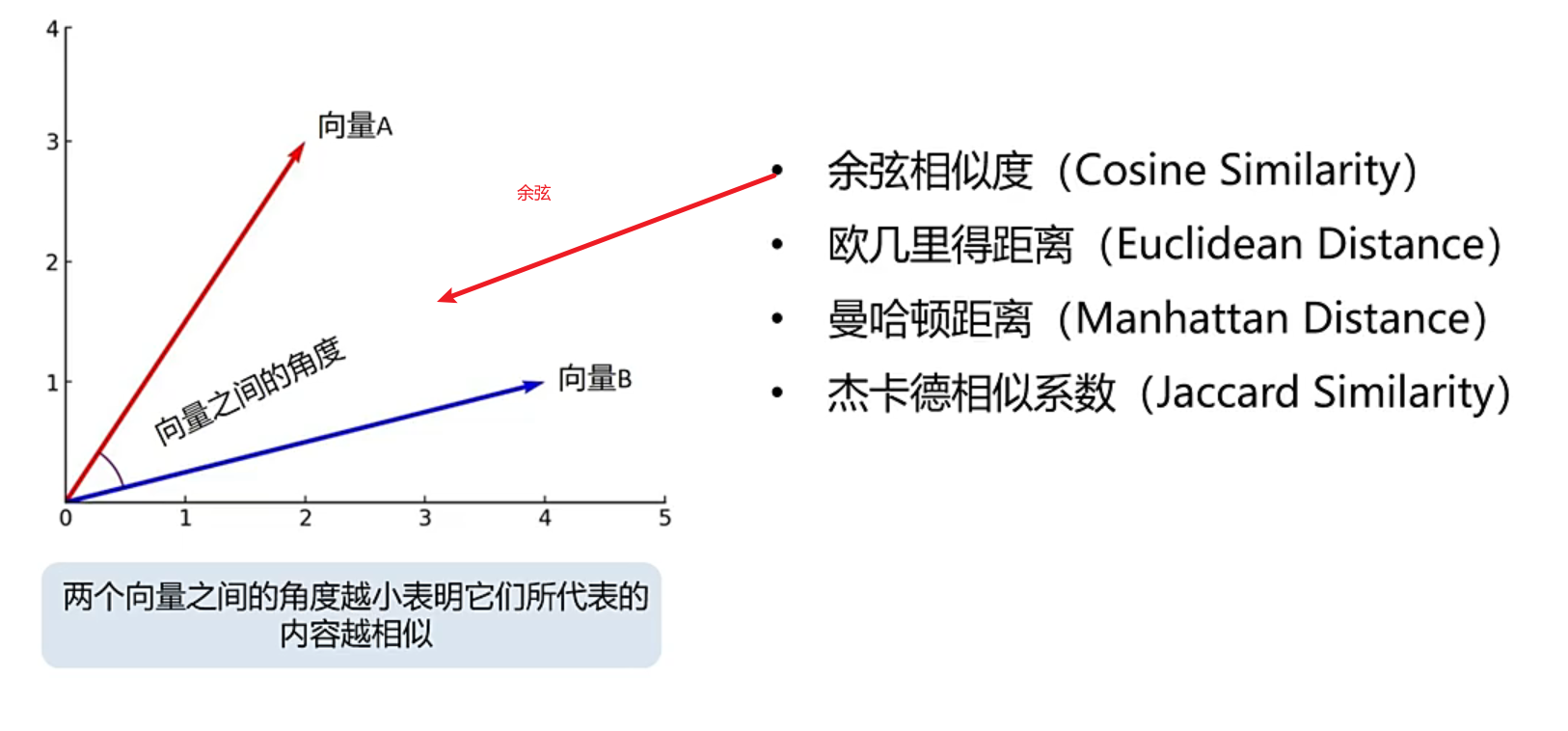
相似度和向量化构成了文本处理的两个核心【NLP自然语言处理的核心】:利用相似度和向量化评估文本的相似度有多高等
语义搜索
:就是通过计算文本相似度,找到意思内容相近的文本内容。【】
语义搜索(Semantic Search)是一种基于自然语言处理(NLP)和人工智能技术的搜索方式,它不仅仅依赖于关键词的简单匹配,而是试图理解用户查询背后的含义、上下文以及意图,从而返回更精准、更相关的搜索结果。相比传统的关键词搜索,语义搜索更注重内容的深层意义,能够处理自然语言的复杂性和模糊性。
语义搜索的核心特点
- 理解意图:语义搜索会分析用户的查询,试图弄清楚用户真正想要的是什么。例如,如果用户搜索“苹果”,语义搜索会根据上下文判断是想找水果、公司,还是其他含义。
- 上下文相关性:它会考虑查询的背景信息,比如用户的搜索历史、地理位置或当前的语境,来提供更贴合需求的结果。
- 自然语言处理:语义搜索能够理解同义词、词语间的关系,甚至是句子的语法结构。比如“如何提升脑力”和“怎样提高思维能力”可能会被识别为同一个意图。
- 知识图谱的运用:许多语义搜索系统会利用知识图谱(Knowledge Graph),将实体(如人、地点、事物)及其关系整合起来,从而提供更丰富的结果。
- 模糊匹配:即使用户的表述不够精确,语义搜索也能通过语义分析推测出可能的意图,而不仅仅依赖字面匹配。
语义搜索的工作原理
语义搜索通常依赖以下技术:
- 词嵌入(Word Embeddings):将词语转化为向量表示,使得机器能够理解词语之间的语义相似性。例如,“猫”和“狗”在向量空间中会比“猫”和“桌子”更接近。
- 深度学习模型:像BERT、Transformer等模型可以理解句子的整体含义,而不仅仅是单个词。
- 语义分析:通过解析句法和语义,提取关键概念和关系。
- 用户行为数据:结合用户的历史交互数据,优化搜索结果的个性化。
语义搜索的实际应用
从你的背景来看,你开发过一个退休人员信息管理系统,支持模糊查询,这与语义搜索有一定的相似之处。假设你的系统中用户输入“张三退休时间”,传统搜索可能只匹配“张三”和“退休时间”这两个词,而语义搜索可能会理解用户想查询“张三的退休日期”,并直接从数据库中提取相关信息,甚至还能处理类似“张三什么时候退休”这样的自然语言输入。这种能力在你的系统中如果结合PyQt5和MySQL,可以通过NLP模块进一步增强用户体验。
再比如,搜索引擎(如Google)、电商平台(如Amazon推荐系统)、智能助手(如Siri)都在广泛使用语义搜索技术,提供更智能的交互体验。
与传统搜索的对比
- 传统搜索:基于关键词匹配,可能返回大量无关结果。比如搜索“Java”,可能同时返回编程语言和咖啡的相关内容。
- 语义搜索:会根据上下文推测用户想要的是“Java编程语言”,并优先返回相关教程或文档。
总结
简单来说,语义搜索就像一个“会思考”的搜索工具,它不仅看你输入了什么,更关心你想表达什么。它通过理解语言的深层含义,让搜索结果更智能、更人性化。如果你对如何在你的项目中实现类似功能感兴趣,可以告诉我,我可以进一步帮你探讨技术细节!


应用方式和类型
文本生成

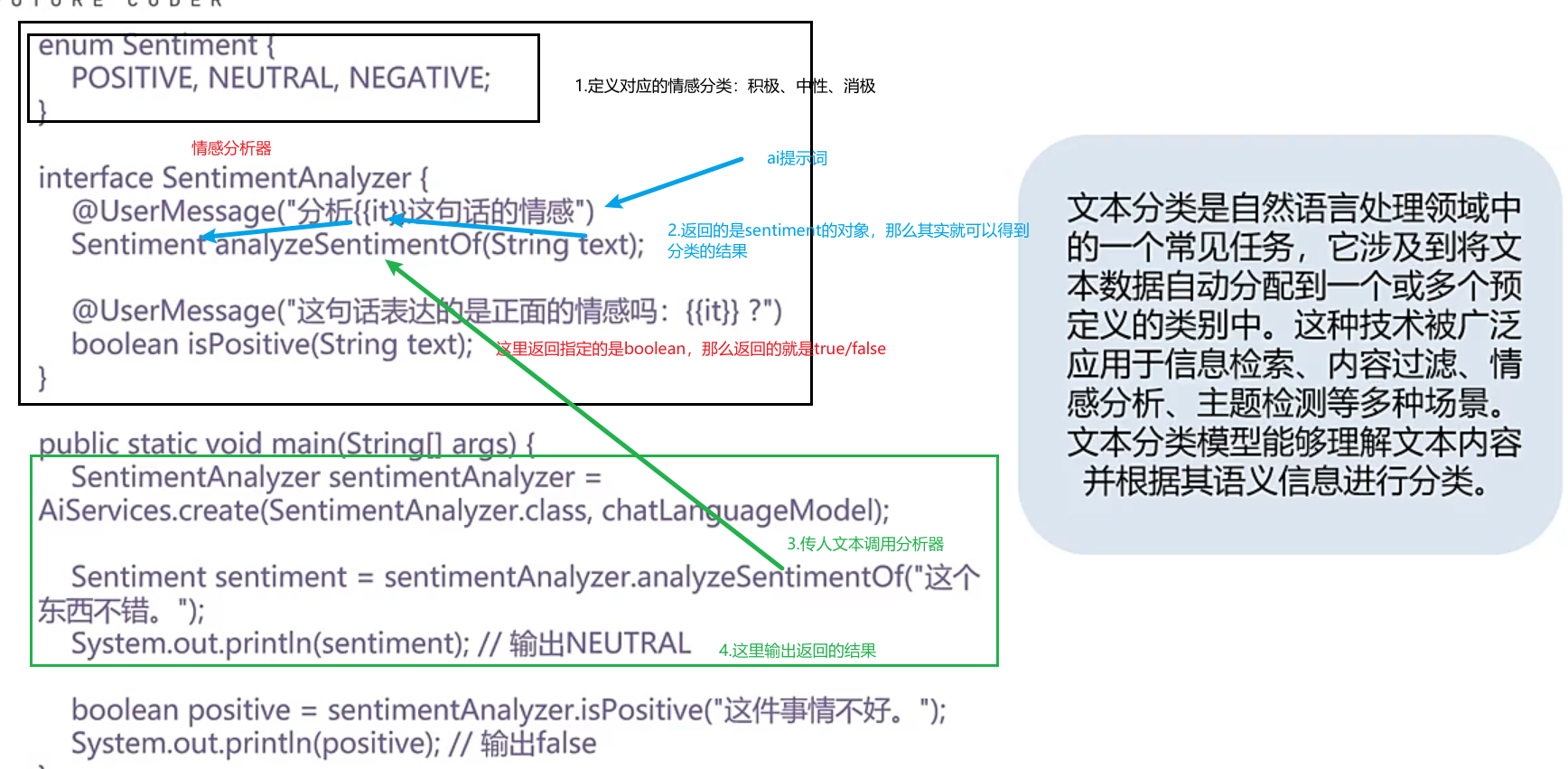
文本结构化数据提取
让ai将一段文本结构化为对象【注意:前提是对象的属性名有含义才不会出错 】

文本分类
调用大模型,将传入的文本进行分析,得出其分类【如果不用ai的话,就得用机器学习了,但是现在不需要】
只要有分类的场景就可以使用**【这里可以定义需要返回的数据格式】**

对话系统
以前的rasa对话系统,实现的就是类似的,具体实现就是:通过写一系列的算法/模型去定义用户输入的内容是属于哪个分支的,从而进入对应的分类去输出对话。现在只需要使用大模型即可。

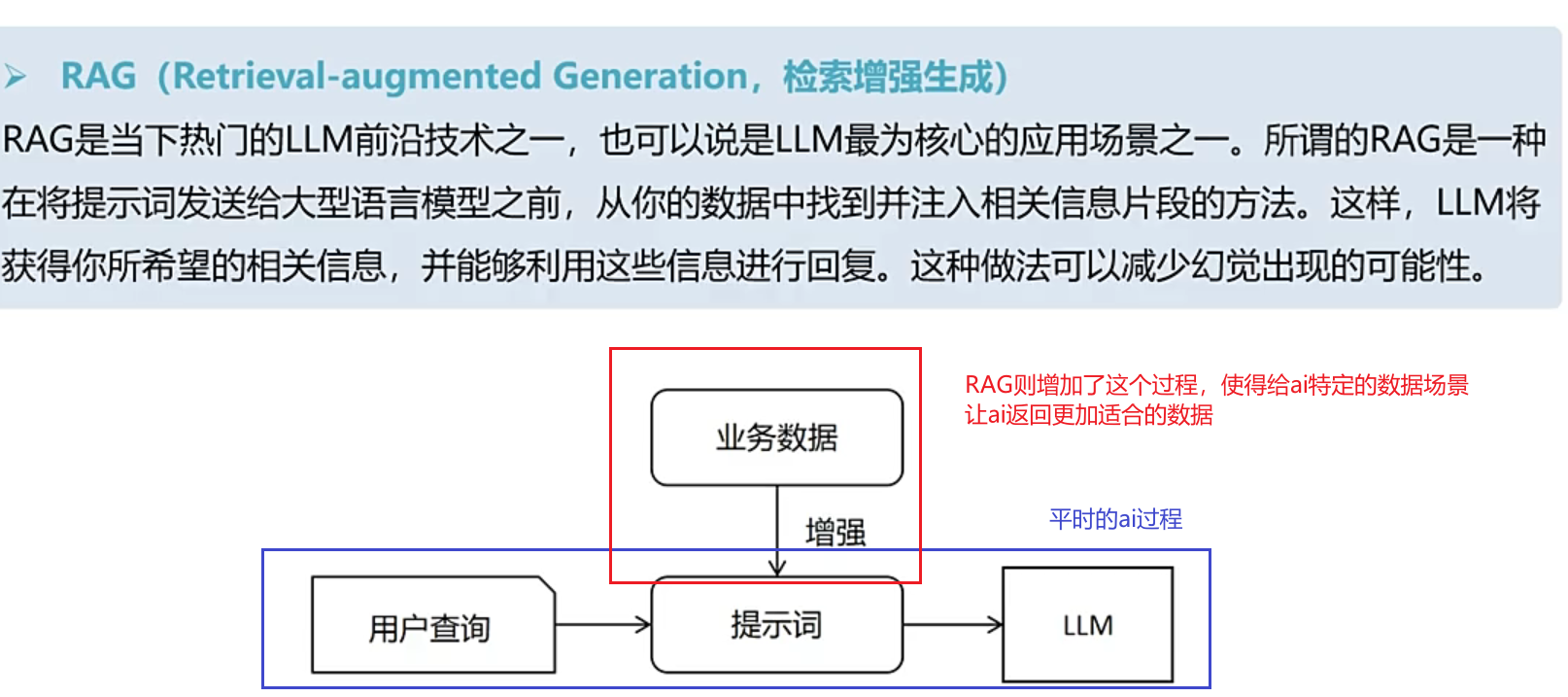
RAG(检索增强)
其实就是:根据用户的输入内容+增加了特定的外部数据融入给到ai==让ai返回更加准确的内容。
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索和生成式模型的自然语言处理技术,旨在提升生成内容的准确性和相关性。它通过从外部知识库检索相关信息,再将这些信息融入到生成模型中,从而生成更高质量、更贴合上下文的回答。
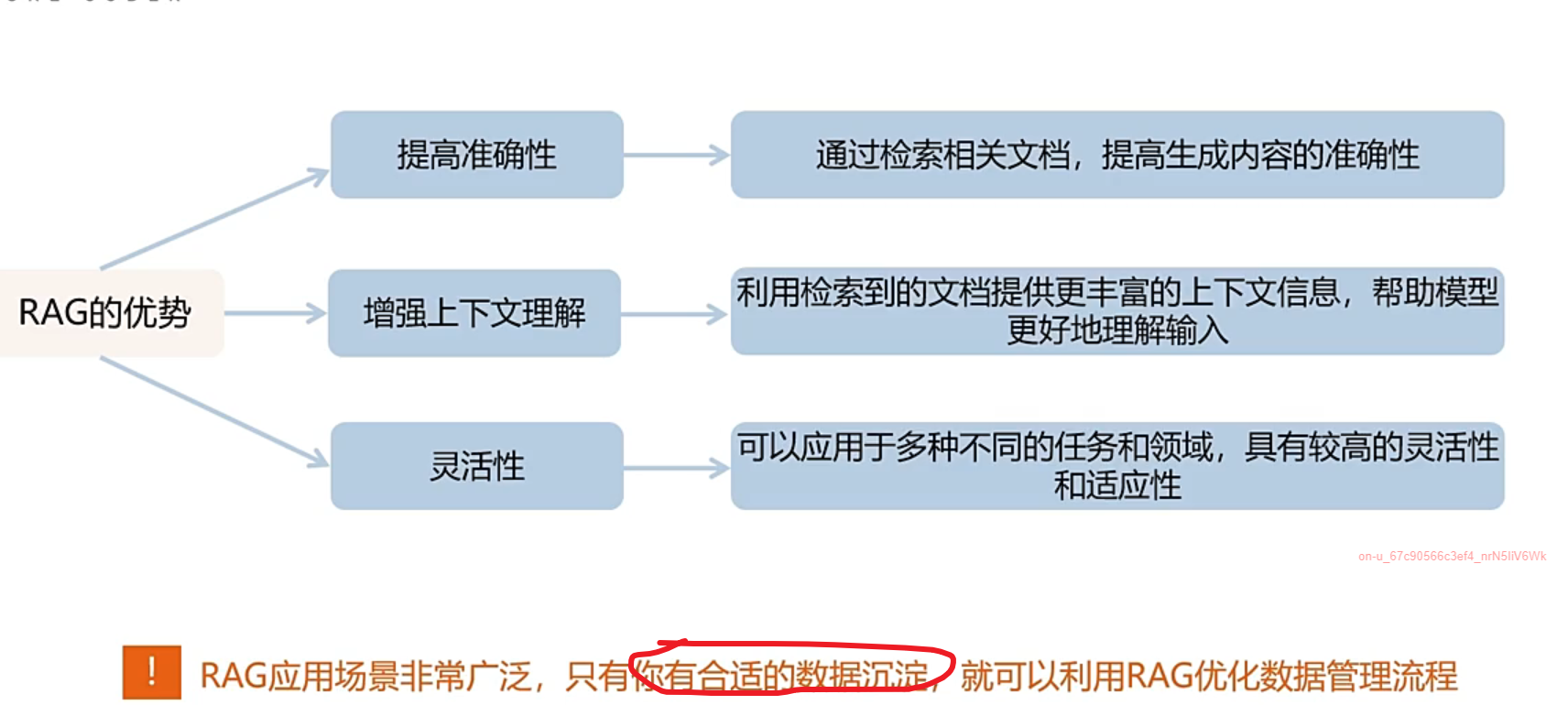
RAG的核心特点
- 检索与生成结合:RAG分为两步:
- 检索:从一个大型知识库(如文档、数据库或网页)中提取与用户查询相关的片段。
- 生成:利用大语言模型(如Transformer)结合检索到的信息生成自然、准确的回答。
- 动态知识获取:不像传统语言模型仅依赖预训练数据,RAG可以实时检索外部最新信息,减少“知识截止”问题。
- 上下文增强:通过检索到的信息为生成模型提供更丰富的上下文,避免生成脱离事实或过于泛化的内容。
- 高效性:相比完全依赖大规模模型推理,RAG通过检索缩小信息范围,降低计算成本。
RAG的工作原理
RAG通常包括以下组件:
- 检索器(Retriever):通常基于向量搜索技术(如DPR,Dense Passage Retrieval),将用户查询转化为向量,并在知识库中找到语义最相似的文档或片段。
- 生成器(Generator):基于预训练语言模型(如BERT、T5或GPT),接收检索到的文档和用户查询,生成最终输出。
- 知识库:可以是结构化的数据库(如MySQL)、非结构化的文档集合,或外部API(如网页搜索结果)。
工作流程:
- 用户输入查询。
- 检索器将查询编码为向量,在知识库中搜索相关内容。
- 检索到的文档与查询一起输入生成器。
- 生成器综合信息,输出自然语言回答。
RAG的实际应用
结合你之前问过的“语义搜索”,RAG可以看作是语义搜索的一种高级应用。语义搜索注重理解查询意图并返回相关结果,而RAG在此基础上进一步生成流畅的回答。例如:
- 在你的退休人员信息管理系统中,假设用户输入“张三的退休信息”,RAG可以先从MySQL数据库检索张三的相关记录(如退休日期、养老金),然后生成一句完整的回答:“张三于2020年5月退休,养老金为每月3000元。”
- 在智能客服、问答系统(如医疗咨询、法律查询)中,RAG能检索专业文档并生成通俗易懂的解答。
- 在搜索引擎或内容创作工具中,RAG可用于生成基于最新信息的文章摘要或答案。
RAG与传统生成模型的对比
- 传统生成模型:仅依赖预训练数据,可能生成“幻觉”(hallucination),即捏造不存在的事实。
- RAG:通过检索外部知识,减少错误信息,提高回答的可信度。例如,传统模型可能无法回答2025年的最新事件,而RAG可以检索实时数据。
技术细节
- 检索技术:常用Faiss、ElasticSearch或Sentence-BERT等工具,将文本编码为高维向量,计算余弦相似度进行匹配。
- 生成技术:基于Transformer架构,常见模型包括BART、T5或LLaMA。
- 优化方向:RAG的性能依赖于检索的质量和知识库的覆盖率,需定期更新知识库并优化向量表示。
与语义搜索的联系
你之前问过语义搜索,它是RAG的检索部分的基础。语义搜索专注于理解查询并找到相关内容,而RAG在此基础上加入了生成步骤。比如,语义搜索可能返回“张三的退休记录”,而RAG会进一步生成“张三在2020年退休,以下是详情……”。如果你想在你的PyQt5+MySQL系统中实现RAG,可以考虑集成一个轻量级向量数据库(如Chroma)来支持检索,再用开源模型(如MiniLM)做生成。
总结
RAG是一个强大的技术框架,通过检索外部知识增强生成模型的表现,特别适合需要高准确性和实时性的场景。相比单纯的语义搜索,RAG更进一步,能生成自然语言回答,应用场景更广。如果你对在项目中实现RAG的具体方法感兴趣(比如代码示例或架构设计),可以告诉我,我可以深入探讨!
多模态内容处理
图片
类似将图片转为文本一样去处理


音频

视频
生成一个作业帮的视频教学。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 39
39 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)