CoT+MLLM,突破传统单模态推理的局限性!
本文中,提出了一种图像合并的多模态思维链,名为 \textbf{Interleaved-modal Chain-of-Thought (ICoT)},它生成由配对的视觉和文本基本原理组成的顺序推理步骤来推断最终答案。在现有的大规模视觉语言多模态模型中,对被遮挡物体的理解没有得到很好的研究。构建了大规模的多模态思维链数据集:为了支持上述复杂推理流程的训练,作者构建了一个包含11万个样本的大规模数据集
传统CoT局限于文本模态,而MLLM引入了视觉、语音等模态,使得推理不再局限于语言符号,而是融合图像、空间、语义等多维信息,实现了更接近人类认知的推理过程。
所以CoT+MLLM他两结合之后会比较好发顶会,尤其像:动态步数 CoT、模态-步级Routing、无监督 CoT蒸馏、对话式多轮CoT、CoT可解释性评估、多智能体协作CoT等方向,大家可以结合自己的专业和需求参考。
同时,考虑到大家可能分析这些创新点的时候没有资料参考,这里准备了12篇2025年CoT+MLLM的最新顶会论文资料。
 免费获取论文合集和写作资料包,工具包
免费获取论文合集和写作资料包,工具包

OCC-MLLM-CoT-Alpha: Towards Multi-stage Occlusion Recognition Based on Large Language Models via 3D-Aware Supervision and Chain-of-Thoughts Guidance
OCC-MLLM-CoT-Alpha:通过3D感知监督和思维链引导,实现基于大语言模型的多阶段遮挡识别
方法:
在现有的大规模视觉语言多模态模型中,对被遮挡物体的理解没有得到很好的研究。当前最先进的多模态大模型难以通过通用视觉编码器和监督学习策略在理解被遮挡的物体方面提供令人满意的结果。因此,我们提出了OCC-MLLM-CoT-Alpha,这是一个集成了3D感知监督和思维链引导的多模态大视觉语言框架。具体而言,(1)构建了一个多模态视觉语言大模型框架,该框架由多模态视觉语言大模型和三维重建专家模型组成。(2)通过监督训练和强化训练策略相结合的方式学习相应的多模态思维链,使多模态视觉语言模型在学习的多模态思维链引导下增强识别能力。(3)构建了一个大规模的多模态思维链推理数据集,由手中持有的110k$的被遮挡物体样本组成。在评估中,所提出的方法在各种最先进模型的两种设置下,决策得分分别提高了15.75%、15.30%、16.98%、14.62%和4.42%,3.63%,6.94%,10.70%。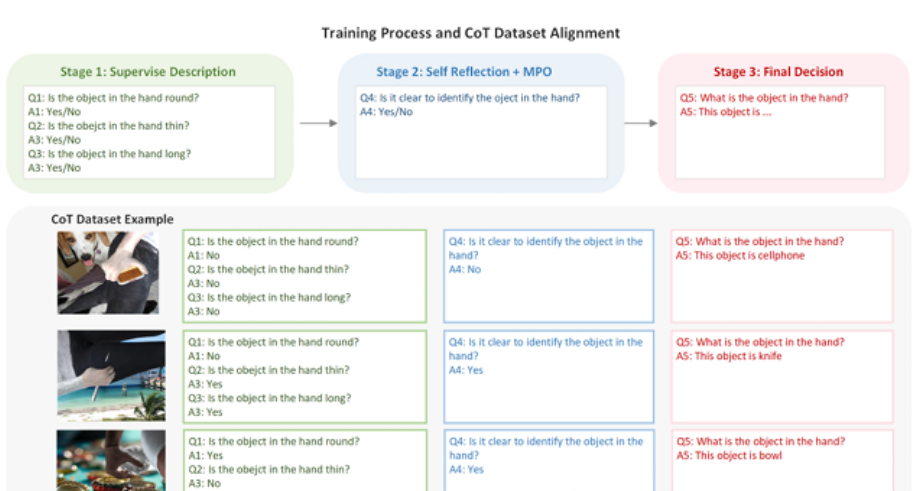
创新点:
首次将多模态思维链(Chain-of-Thought, CoT)推理与3D感知重建技术相结合,构建了一个用于理解严重遮挡物体的全新框架。
具体而言,其核心创新体现在以下三个方面:
-
引入“分阶段”推理机制:论文提出了一个独特的两阶段训练框架。第一阶段训练一个多模态大语言模型(MLLM)和一个独立的3D重建专家模型。第二阶段则通过结合监督学习和强化学习(特别是混合偏好优化MPO),让MLLM学会利用一个结构化的多模态思维链进行自我提问、反思和决策。这个过程将复杂的遮挡理解任务分解为三个循序渐进的子任务:物体属性描述(Description)→ 自我反思是否需要3D信息(Self-Reflection)→ 最终识别(Final Decision)。
-
3D感知的思维链引导(3D-Aware CoT Guidance):这是最关键的突破。该框架并非简单地将3D重建结果作为最终答案,而是将其作为思维链推理过程中的一个可被调用的“工具”。MLLM在“自我反思”阶段学会判断当前视觉信息是否足够,如果不足,则主动触发3D重建专家模型来补充缺失的几何信息,从而极大地提升了对严重遮挡物体的识别准确率。这种动态的、按需的3D信息整合方式是前所未有的。
-
构建了大规模的多模态思维链数据集:为了支持上述复杂推理流程的训练,作者构建了一个包含11万个样本的大规模数据集,其中每个样本都带有详细的多步思维链标注,包括物体属性问答、是否需要3D辅助的判断以及最终识别结果。这个数据集为训练和评估此类复杂模型提供了基础。
Interleaved-Modal Chain-of-Thought
交错模态思维链
方法:
本文中,提出了一种图像合并的多模态思维链,名为 \textbf{Interleaved-modal Chain-of-Thought (ICoT)},它生成由配对的视觉和文本基本原理组成的顺序推理步骤来推断最终答案。直观地讲,新型 ICoT 需要 VLM 能够生成细粒度的交错模态内容,这是当前 VLM 难以实现的。考虑到所需的视觉信息通常是输入图像的一部分,我们提出了 \textbf{Attention-driven Selection (ADS)} 来实现基于现有 VLM 的 ICoT。ADS 智能地插入输入图像的区域以生成交错模态推理步骤,并具有可忽略的额外延迟。ADS 仅依赖于 VLM 的注意力图,无需参数化,因此它是一种即插即用策略,可以推广到一系列 VLM。我们应用ADS在两种不同架构的流行VLM上实现ICoT。对三个基准的广泛评估表明,与现有的多模态 CoT 提示方法相比,ICoT 提示实现了显着的性能(高达 14\%)和可解释性改进。

创新点:
第一次把“跨模态交替推理”显式地拆成了“在每一步先决定用视觉还是语言,再决定用多少”的两级决策问题,并用一个可学习的 Routing Controller + 弹性 Token Budget 机制端到端地实现,从而让 MLLM 的推理链既稀疏又自适应
免费获取论文合集和写作资料包,工具包

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)