MySQL SQL优化从入门到精通
SQL优化是提升数据库性能的关键技能。本文系统介绍了MySQL优化方法:首先理解SQL执行顺序,使用EXPLAIN分析查询;其次通过合理创建索引、避免索引失效场景来优化查询;第三采用SELECT字段显式指定、优化分页查询等技巧;最后结合实际案例,演示如何通过添加索引、重写查询语句来优化慢查询。文章强调,随着数据量增长,SQL优化从基础索引使用到高级技巧都至关重要,是开发人员和DBA必须掌握的核心能
引言:为什么SQL优化如此重要?
在日常开发中,我们常常会遇到数据库查询缓慢的问题。随着数据量的增长,一条低效的SQL语句可能从几毫秒的执行时间骤增至数秒甚至数分钟,严重影响系统性能和用户体验。SQL优化不仅是DBA的专业技能,也是开发人员必须掌握的核心能力。
本文将带你全面了解MySQL SQL优化的各种技巧和方法,从基础到高级,从理论到实践,帮助你写出更高效的SQL语句。
一、SQL优化基础篇
1.1 理解SQL执行顺序
在开始优化前,我们需要了解SQL语句的执行顺序:
(8) SELECT (9)DISTINCT<Select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE|ROLLUP}
(7) HAVING <having_condition>
(10) ORDER BY <order_by_list>
(11) LIMIT <limit_number>
了解这个顺序有助于我们理解为什么WHERE条件比HAVING更高效,以及为什么在WHERE条件中使用聚合函数会导致性能问题。
1.2 使用EXPLAIN分析查询
EXPLAIN是SQL优化中最强大的工具,它可以显示MySQL如何处理SQL语句:
EXPLAIN SELECT * FROM users WHERE age > 30;
EXPLAIN结果中的关键字段:
id: 查询标识符
select_type: 查询类型(SIMPLE, PRIMARY, SUBQUERY等)
table: 访问的表
type: 连接类型(ALL, index, range, ref, eq_ref, const)
possible_keys: 可能使用的索引
key: 实际使用的索引
rows: 预估需要检查的行数
Extra: 额外信息(Using where, Using temporary, Using filesort等)
二、索引优化策略
2.1 索引的基本原理
索引就像书籍的目录,可以快速定位到需要的数据。MySQL索引使用B+树数据结构,适合范围查询和排序。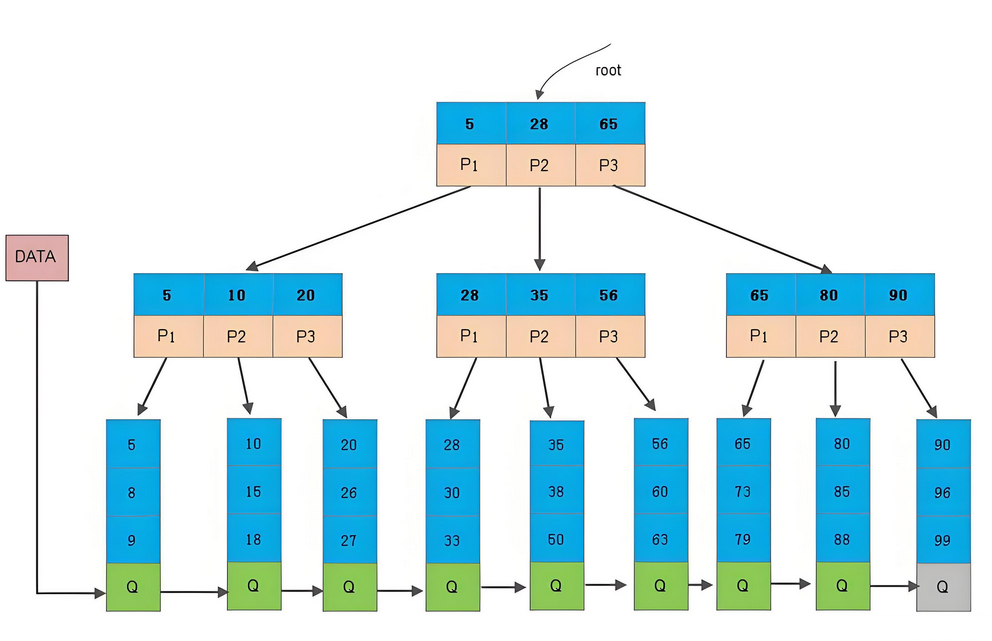
2.2 创建合适的索引
创建索引的原则:
为WHERE子句中的频繁条件字段创建索引
为JOIN操作的关联字段创建索引
为ORDER BY和GROUP BY子句中的字段创建索引
选择区分度高的列建立索引(区分度 = 不重复记录数/总记录数)
示例:
-- 好的索引实践
CREATE INDEX idx_user_age ON users(age);
CREATE INDEX idx_user_email ON users(email);
-- 复合索引(注意字段顺序)
CREATE INDEX idx_user_age_sex ON users(age, sex);
2.3 避免索引失效的常见场景
- 不要在索引列上使用函数或表达式
-- 错误示例
SELECT * FROM users WHERE YEAR(create_time) = 2025;
-- 正确示例
SELECT * FROM users WHERE create_time >= '2024-09-01' AND create_time < '2025-09-03';
- 注意LI查询的前通配符
-- 索引失效
SELECT * FROM users WHERE name LIKE '%张%';
-- 索引有效
SELECT * FROM users WHERE name LIKE '张%';
- 避免对索引列进行运算
-- 索引失效
SELECT * FROM users WHERE age + 1 > 30;
-- 索引有效
SELECT * FROM users WHERE age > 29;
- 注意OR条件的使用
-- 索引可能失效
SELECT * FROM users WHERE age > 30 OR name = '张三';
-- 可改为UNION方式
SELECT * FROM users WHERE age > 30
UNION
SELECT * FROM users WHERE name = '张三';
三、查询优化技巧
3.1 避免SELECT *
使用SELECT * 会返回所有字段,包括不需要的字段,增加I/O负担和网络传输开销。
-- 不推荐
SELECT * FROM users WHERE age > 30;
-- 推荐
SELECT id, name, email FROM users WHERE age > 30;
3.2 优化LIMIT分页
大数据量下的分页查询性能问题是一个常见痛点:
-- 低效的分页(偏移量大时)
SELECT * FROM users ORDER BY id LIMIT 1000000, 20;
-- 高效的分页(使用索引覆盖+子查询)
SELECT * FROM users
WHERE id >= (SELECT id FROM users ORDER BY id LIMIT 1000000, 1)
ORDER BY id LIMIT 20;
3.3 使用连接代替子查询
在大多数情况下,JOIN比子查询更高效:
-- 不推荐
SELECT * FROM users
WHERE department_id IN (SELECT id FROM departments WHERE type = '技术');
-- 推荐
SELECT u.* FROM users u
JOIN departments d ON u.department_id = d.id
WHERE d.type = '技术';
3.4 避免全表扫描
全表扫描(type=ALL)是性能杀手,应尽量避免:
-- 检查是否使用了索引
EXPLAIN SELECT * FROM users WHERE name = '张三';
-- 如果没有使用索引,考虑添加索引
CREATE INDEX idx_users_name ON users(name);
四、数据库设计优化
4.1 选择合适的数据类型
选择最合适的数据类型可以节省空间并提高性能:
使用INT而不是VARCHAR存储数字
使用DATETIME而不是VARCHAR存储时间
字段宽度尽量小,但要预留足够空间
4.2 规范化与反规范化的平衡
规范化减少了数据冗余,但可能导致多表连接:
优点:数据一致性高,更新容易
缺点:查询可能需要多次连接
反规范化增加了数据冗余,但减少了连接:
优点:查询性能高
缺点:数据一致性维护困难
在实际应用中,需要根据读写比例做出权衡。
4.3 合理使用分区表
对于非常大的表,可以考虑使用分区表:
-- 按范围分区
CREATE TABLE logs (
id INT NOT NULL,
log_date DATE NOT NULL,
message TEXT
)
PARTITION BY RANGE (YEAR(log_date)) (
PARTITION p0 VALUES LESS THAN (2020),
PARTITION p1 VALUES LESS THAN (2021),
PARTITION p2 VALUES LESS THAN (2022),
PARTITION p3 VALUES LESS THAN MAXVALUE
);
五、高级优化技巧
5.1 使用覆盖索引
覆盖索引是指查询只需要通过索引就可以获取所需数据,无需回表:
-- 创建复合索引
CREATE INDEX idx_users_age_sex ON users(age, sex, name);
-- 使用覆盖索引(Extra: Using index)
EXPLAIN SELECT age, sex, name FROM users WHERE age > 30;
5.2 优化大批量数据插入
插入大量数据时,使用以下技巧提高性能:
-- 1. 禁用索引(插入完成后重新启用)
ALTER TABLE users DISABLE KEYS;
-- 批量插入操作...
ALTER TABLE users ENABLE KEYS;
-- 2. 使用批量INSERT
INSERT INTO users (name, age) VALUES
('张三', 25),
('李四', 30),
('王五', 28);
-- ...
-- 3. 按主键顺序插入(对于InnoDB尤其重要)
5.3 使用延迟关联优化深度分页
对于极其深度的分页,可以使用延迟关联技巧:
SELECT * FROM users u
INNER JOIN (
SELECT id FROM users
WHERE age > 30
ORDER BY id
LIMIT 1000000, 20
) AS t ON u.id = t.id;
六、实战案例:优化慢查询
案例背景
有一个用户订单查询系统,发现以下查询越来越慢:
SELECT * FROM orders o
LEFT JOIN users u ON o.user_id = u.id
LEFT JOIN products p ON o.product_id = p.id
WHERE o.create_time BETWEEN '2024-01-01' AND '2025-09-02'
AND u.age > 30
ORDER BY o.create_time DESC
LIMIT 0, 20;
优化步骤
1. 使用EXPLAIN分析
发现orders表进行了全表扫描,users表使用了临时表和文件排序
2 添加索引
ALTER TABLE orders ADD INDEX idx_orders_create_time (create_time);
ALTER TABLE users ADD INDEX idx_users_age (age);
ALTER TABLE orders ADD INDEX idx_orders_user_id (user_id);
3 重写查询
SELECT o.*, u.name, u.email, p.product_name
FROM orders o
FORCE INDEX (idx_orders_create_time)
STRAIGHT_JOIN users u ON o.user_id = u.id
JOIN products p ON o.product_id = p.id
WHERE o.create_time BETWEEN '2024-01-01' AND '2025-09-02'
AND u.id IN (SELECT id FROM users WHERE age > 30)
ORDER BY o.create_time DESC
LIMIT 0, 20;
4 进一步优化
考虑在orders表上创建复合索引(create_time, user_id)
考虑使用覆盖索引
对于历史数据,使用分区表或归档策略
七、常用优化工具
1 慢查询日志
-- 启用慢查询日志
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 2; -- 超过2秒的查询
2 Performance Schema
MySQL性能模式,提供详细的性能监控数据
3 Percona Toolkit
第三方工具集,包含pt-query-digest等强大工具
总结
SQL优化是一个持续的过程,需要结合实际情况不断调整。记住以下核心原则:
测量,不要猜测:使用EXPLAIN和慢查询日志找出真正的问题
索引是关键:合理创建和使用索引
避免全表扫描:确保查询使用了合适的索引
优化数据库设计:好的设计是高性能的基础
考虑查询重构:有时候重写查询比添加索引更有效
SQL优化既是一门科学,也是一门艺术。希望通过本文的介绍,你能更好地理解和掌握MySQL SQL优化的各种技巧,写出更高效的SQL语句。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)