“全国景区活动资讯库”设计与落地计划
本文提出构建AI驱动的全国景区活动资讯库,采用YOLO+OCR+大模型等智能技术进行数据采集处理,规避版权风险并形成数据资产。通过Scrapy、Selenium等工具建立多源数据采集系统,重点抓取文旅局、景区官网及旅游平台信息。商业模式包括运营旅游资讯账号、销售数据报告及技术服务变现。建议采用MVP策略快速验证,初期投入控制在5000元内,通过A/B测试验证市场需求。该方案瞄准中国万亿级旅游市场,
阶段一目标:AI驱动数据收集和分析系统–全国景区活动资讯库
它绝不仅仅是一个数据库,而是你整个项目的数据引擎、流量入口和商业基石。它允许你用最低的成本启动项目,快速验证市场需求,并在过程中积累起最关键的数据资产(用户偏好、活动热度)和行业资源(景区合作)。后续所有的AI推荐、个性化行程、甚至平台生态,都将从这个资讯库里生长出来。
技术栈
-
新型数据爬取技术:YOLO + OCR + 大模型
(1)利用视觉AI(YOLO进行目标检测和定位) + OCR(提取文本信息) + 大语言模型(清洗、重构、理解内容) 来生成全新的、结构化的数据,而不再是直接爬取原始文本,这是一种更智能、更合规、且能产生更高价值的数据沉淀策略。
(2)这个技术闭环完美地规避了直接抓取他人平台内容可能带来的法律风险,因为你沉淀的不再是原始数据,而是经过AI处理、重构和升华后的新数据资产。
(3)源头极其丰富:图像和视频是互联网上最丰富的内容形式。你的“数据源”可以是短视频、直播、官网宣传图、用户分享的截图、甚至监控画面等,来源广泛且多样。
(4)形成竞争壁垒:这套技术栈的搭建需要综合能力(CV、NLP、工程化),一旦跑通,其数据生产和迭代速度是传统人工方式无法比拟的,从而建立起技术和数据层面的双重壁垒。
不再是一个简单的数据搬运工,而是成为了一个利用AI进行数据再加工的“新矿工”。你从公开的“图像矿山”中,用先进的工具(YOLO+OCR+LLM)挖掘、提炼、锻造出高纯度的“数据钻石”,并将其变为自己的资产。这不仅巧妙地规避了版权风险,更开辟了一条价值更高、竞争力更强、前景更广阔的数据获取之路。 -
原始爬虫
(1)Scrapy:Python强大的开源爬虫框架,适合构建复杂、大规模的爬取项目。
(2)Selenuim:模拟浏览器行为,适合处理需要渲染JavaScript的动态网页。
(3)Apifox:如果目标网站提供公开API,这是最规范、最高效的方式。 -
数据库:mysql,mangodb
-
NLP自然语言处理
目标源
- 各地文旅局、景区的官方网站和公众号:这是最权威、最核心的信息来源。
- 大型旅游平台(马蜂窝、穷游等)的官方活动板块:收集用户发布的游记和活动信息。
- 未来平台的客户所留存下的内容。
注意:务必遵守网站的robots.txt协议,控制抓取频率,避免对对方服务器造成压力。
产出与变现
- 基于 “全国景区活动资讯库” 运营一批(图文、视频)账号,小黄车挂资讯产品链接、数字化直播打赏;
- 实时更新的资讯报告的产品化、服务化;
- 新型数据爬取技术(YOLO + OCR + 大模型),经实践检验后的产品化、服务化。
如何最快实现商业模式验证
为加速验证,采用最小可行产品(MVP)策略,总时长控制在1-2个月:
原型开发(2-3周):使用Scrapy和Selenium构建基本爬虫,集成YOLO+OCR测试小规模数据(如10个省市景区)。部署到云服务器,生成初步资讯报告。
用户测试与变现试点(1-2周):在小红书或抖音运营账号,发布免费样品报告,挂链接销售付费版(20-50元/份)。邀请50-100名旅游爱好者测试,收集反馈。
数据迭代与监控(持续1周):使用Google Analytics跟踪流量,自动化脚本优化爬取。快速调整基于用户偏好,实现首笔收入验证。
风险最小化:仅用公开API(如Apifox)和合规来源启动,避免法律隐患。通过A/B测试评估报告需求,若转化率>10%,视为验证成功。
此路径低成本(<5000元),聚焦快速反馈,若初期收入覆盖开发费,即可扩展。
预期的市场规模
中国旅游市场2025年预计国内旅游收入达6.8万亿元,整体出境游人数达1.3亿人次。 全球旅游总收入突破6.1万亿美元。 AI子市场增长强劲,特别是在个性化服务和数据分析领域,预计到2030年文旅产业突破10万亿元。 小众旅游和AI资讯细分市场潜力巨大,银发游规模超1万亿元,研学游达2422亿元。 该目标若定位精准,可占据1%-5%的AI旅游数据服务份额,潜在年营收数亿元。
toC
C的痛点是信息差、人流预测、天气、交通、饮食、住宿;价格、安全性、便捷性、体验感价值;
toB
B的痛点是引流,是闲时忙时差异太大;引流和均衡客源;数字化;
任务3个月落地计划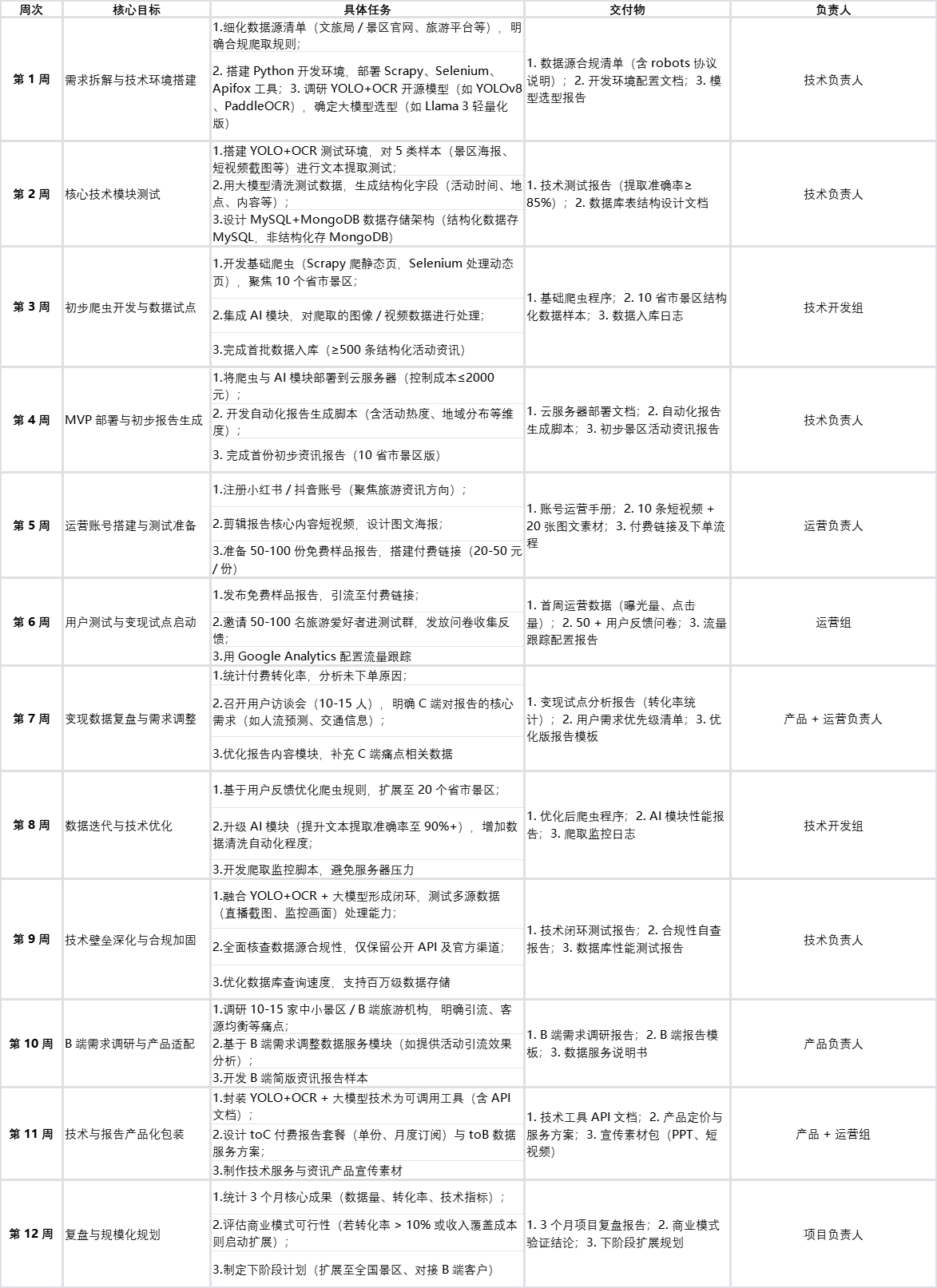

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 46
46 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)