小白也能变大神,手把手教你LLaMA-Factory 微调医疗问答模型
摘要: 本文介绍如何使用LLaMA-Factory工具微调Qwen3-0.6B-Instruct模型构建中文医疗问答系统。该工具简化了大模型微调流程,提供可视化Web界面,无需编写复杂代码。从环境搭建(Ubuntu+CUDA+PyTorch)、安装LLaMA-Factory,到数据处理(Huatuo-Lite医疗数据集格式化)、参数配置(学习率5e-5、3-5训练轮次等关键参数说明),完整演示了微
是不是很多人有这种坤混,理论学的不错,但是一到实操环节,不少人就犯了难:复杂的 Python 代码要逐行琢磨,繁琐的环境配置总出岔子,还有密密麻麻的参数调优让人无从下手,刚燃起的热情瞬间被 “技术拦路虎” 浇凉。难道就没有一款 “傻瓜式” 工具,能帮咱们把精力聚焦在数据准备和应用场景上,不用再被底层技术细节搞得焦头烂额吗?
这不,今天就给大家介绍一个神器:LLaMA‑Factory!
说白了,它就是一个全自动的"AI专家生产线"。你不需要再手动去写那些复杂的加载模型、配置参数的代码了。LLaMA‑Factory把所有繁琐的步骤都封装成了一个清爽的网页界面——选择模型、选择方法、上传数据、调整参数、一键启动,就像在网上购物一样简单!
今天咱们就以中文医疗问答为例,手把手带你用LLaMA‑Factory微调一个Qwen3‑0.6B‑Instruct模型。为什么选这个组合呢?
- • 硬件友好:0.6B参数的模型,一张RTX 3080就能轻松搞定,不用为显存发愁
- • 中文优化:Qwen系列对中文支持极佳,特别适合咱们的应用场景
- • QLoRA加持:4-bit量化+LoRA适配器,让训练显存需求降到最低,消费级GPU也能玩转大模型微调
准备好了吗?咱们这就从理论走向实践,亲手打造一个能回答医疗问题的"AI医生助手"!
第一步:搭建咱们的"实验室"
硬件要求(别担心,门槛不高)
- • Ubuntu Server 22.04 LTS(当然,其他Linux发行版也行)
- • 安装好NVIDIA驱动(这个必须有)
- • CUDA ≥11.6
- • 搭建Python环境,强烈推荐用Conda,管理包依赖特别方便
- • 安装PyTorch,确保GPU和CUDA配合正常(这是基础中的基础)
安装LLaMA‑Factory(三行命令搞定)
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
conda create -n llama-factory python=3.11
conda activate llama-factory
pip install -e ".[torch,metrics]"
如果遇到环境冲突(这种事儿经常有),试试用 pip install --no-deps -e . 解决。
检查安装是否成功
装完之后,咱们验证一下是不是真的装好了。运行 llamafactory-cli version,如果看到下面这样的输出,就说明大功告成了:
----------------------------------------------------------
| Welcome to LLaMA Factory, version 0.9.3.dev0 |
| |
| Project page: https://github.com/hiyouga/LLaMA-Factory |
----------------------------------------------------------
启动WebUI界面(激动人心的时刻)
运行 llamafactory-cli webui 指令,就能进入可视化界面了。WebUI主要分为四个板块:训练、评估与预测、对话、导出。界面长这样:
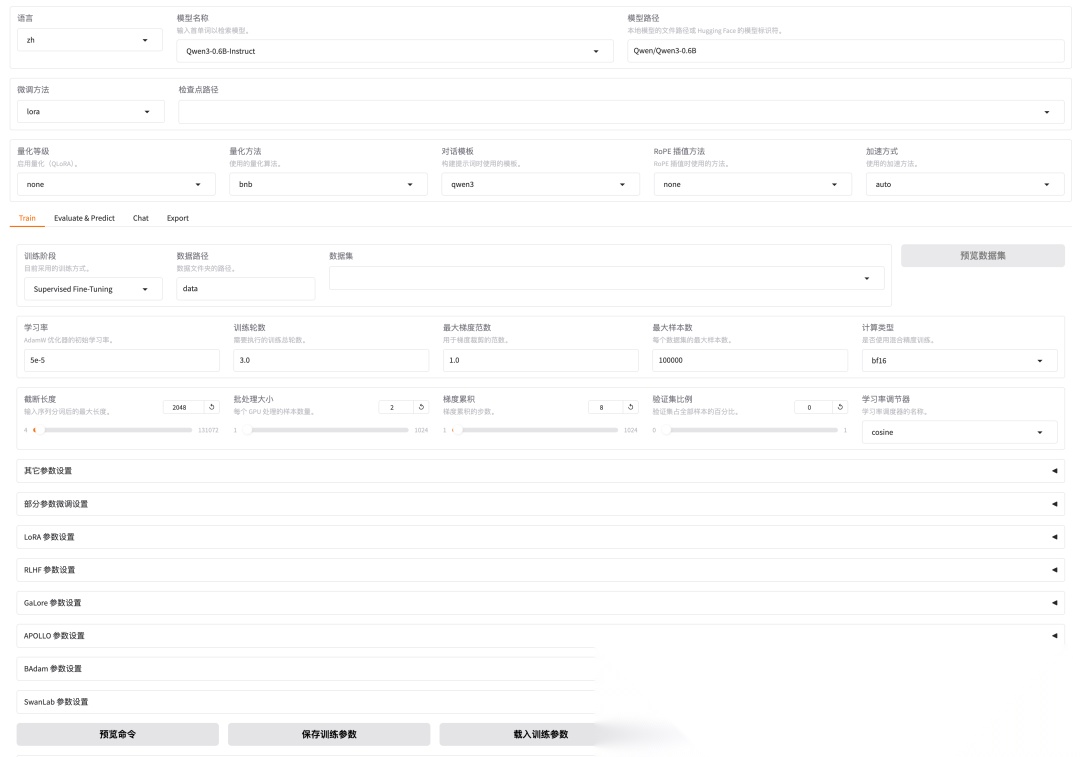
LLaMA-Factory WebUI界面
咱们先加载个模型试试水,选择Qwen3‑0.6B‑Instruct模型,测试下原始的回答效果:
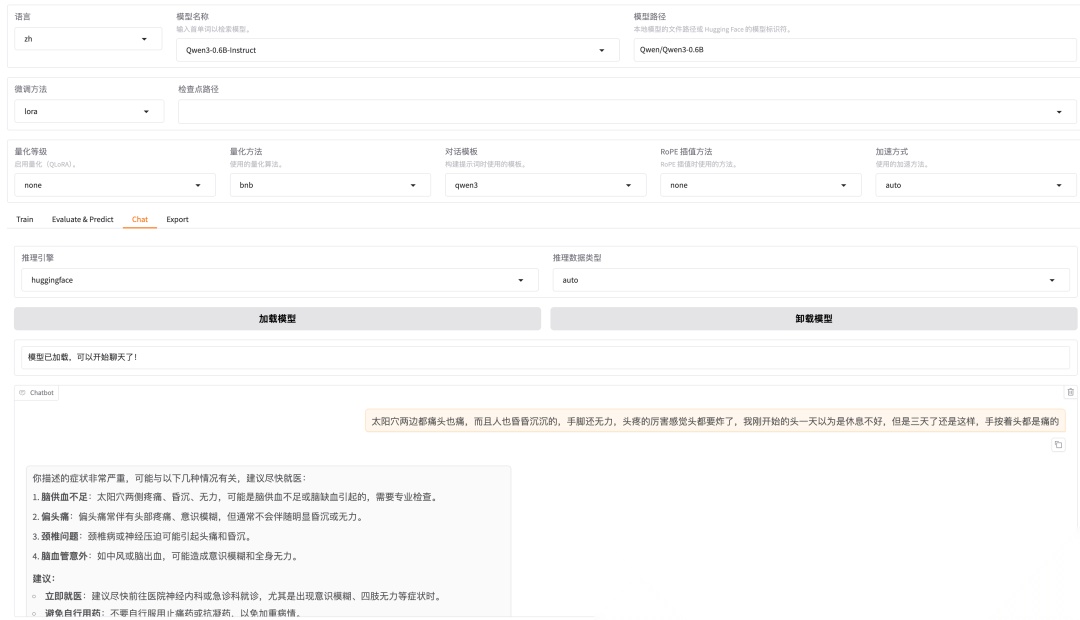
模型原始回答
第二步:准备"教材"(数据就是一切)
咱们这次用的是网上开源的Huatuo-Lite数据集。这可不是随便找的数据,它是在Huatuo26M数据集的基础上经过多次提纯和重写而精炼优化的,包含了18万个高质量的医疗问答对,还带有医院科室和相关疾病两个额外的数据维度。简单说,就是质量很高的医疗问答"教科书"。
数据集下载地址:Huatuo-Lite数据集,从下图可以看出数据集的格式:
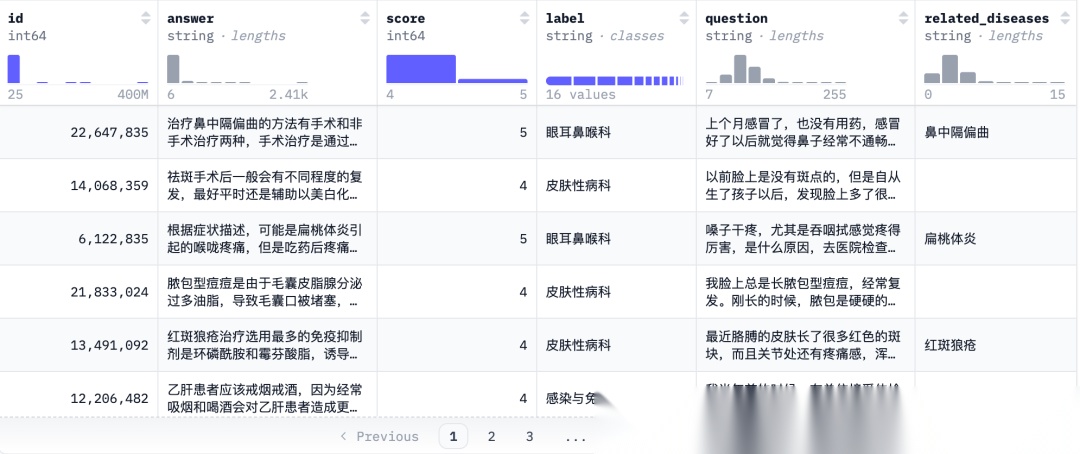
数据样例
数据格式化(让机器能"读懂")
咱们这次使用Alpaca格式的JSON文件,这是目前最流行的微调数据格式之一。数据样例长这样:
[
{
"instruction":"请根据患者的问题给出建议",
"input":"太阳穴两边都痛头也痛,而且人也昏昏沉沉的,手脚还无力,头疼的厉害感觉头都要炸了,我刚开始的头一天以为是休息不好,但是三天了还是这样,手按着头都是痛的",
"output":"需要进一步了解病人的情况,是否有发烧,工作生活学习的压力如何,睡眠如何等等,这些都可能是导致头痛的原因。常见的原因是精神压力过大,没有休息好,也可以见于一些脑部疾病。建议及时就医,以便得到更好的治疗。"
}
]
现在需要写个Python脚本,把原始数据整理成这种格式。代码如下:
from datasets import load_dataset
import os
import json
def process_row(row, i):
"""处理单行数据"""
# 确保row是字典类型
if not isinstance(row, dict):
print(f"Warning: Row {i} is not a dictionary, type: {type(row)}")
return None
if 'label' not in row or row['label'] is None or row['label'] == '': # 如果为空, 则跳过
print(f"Skipping row {i}: empty or missing label")
return None
# 将\n\r 转移为\n,并且转义
question = row['question'].replace('\n\r', '\n').replace('\\n', '\\n')
output = row['answer'].replace('\n\r', '\n').replace('\\n', '\\n')
# 构建JSON对象
row_data = {
"instruction": "请根据患者的问题给出建议",
"input": question,
"output": output
}
return row_data
# 配置环境变量, 使用镜像源
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
max_rows = 5000
valid_count = 0
with open('data/alpaca_huotuo_rows-5k.json', 'w', encoding='utf-8') as f:
f.write('[\n')
for i in range(min(max_rows, len(data_dataset['train']))):
row = data_dataset['train'][i]
processed_row = process_row(row, i)
if processed_row is not None:
json_str = json.dumps(processed_row, ensure_ascii=False, indent=4)
# 为每行添加 4 个空格的缩进
indented_json = '\n'.join(' ' + line for line in json_str.split('\n'))
f.write(indented_json + ',\n')
valid_count += 1
f.write(']\n')
数据上传(把"教材"放到指定位置)
把生成的 alpaca_huotuo_rows-5k.json 文件上传到数据目录 data/ 下,然后在 data/dataset_info.json 中新增如下配置:
"alpaca_huotuo_rows-5k":{
"file_name":"alpaca_huotuo_rows-5k.json"
},
第三步:调参数(这里有门道)
切换到微调页面,基础模型选择Qwen3‑0.6B‑Instruct,微调数据集选择 alpaca_huotuo_rows-5k。接下来就是调参数的环节了,这几个参数特别重要:
- • 学习率: 决定了模型每次参数更新的幅度大小,一般在0-1之间。学习率太大,模型容易"学疯了"不收敛;太小呢,又学得太慢。这次咱们按默认设置5e-5(也就是0.00005)。
- • 训练轮数: 就是模型完整过一遍数据集的次数。轮数太多容易过拟合(就是死记硬背,不会举一反三),太少又学不够。一般3-5轮就差不多了。
- • 最大样本数:限制参与训练的数据量。完整数据集可能有几万条,调试阶段用不着那么多,只从训练集中抽取前N条样本参与训练就行。
- • 批量大小: 每次更新模型参数时用的样本数量。就像补习功课,批量大一次学很多知识点但学得粗糙,批量小一次学得少但精细。LLamaFactory中通过"批处理大小"和"梯度累积"两个参数控制。实际批次大小 = 批处理大小 × 梯度累积步数。
- • 验证集比例: 从训练数据中划分出一部分作为验证集,用来评估模型在没见过的数据上表现如何。一般设置10%到20%。
咱们这次微调的配置参数如下图:
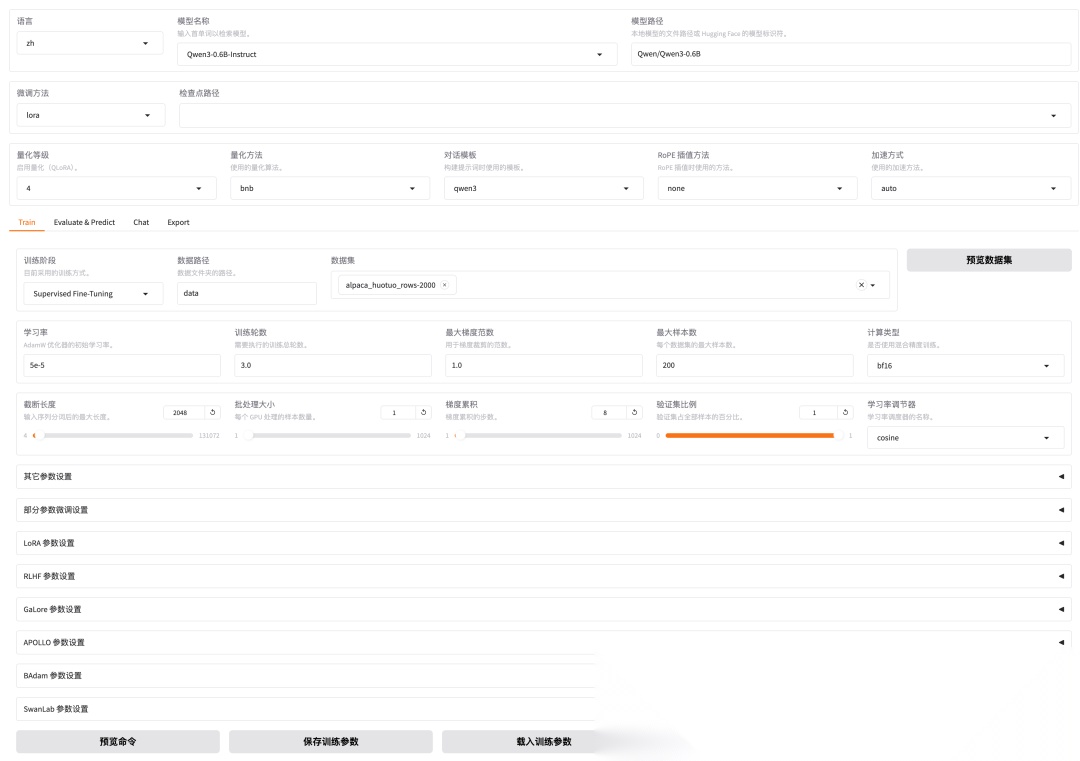
参数配置
第四步:开始训练(见证奇迹的时刻)
参数配置好了,点击"开始"按钮,模型就开始训练了。训练过程中可以看到实时的损失值变化,就像看股票走势图一样,损失值越来越小说明模型学得越来越好。
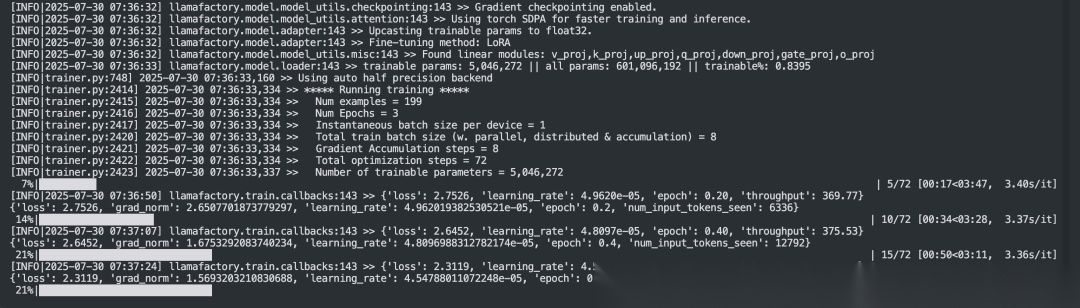
训练过程
训练过程中可以在 WebUI 中查看训练进度,Loss 收敛效果,一般低于 1 即可达到不错的效果,如下图所示:
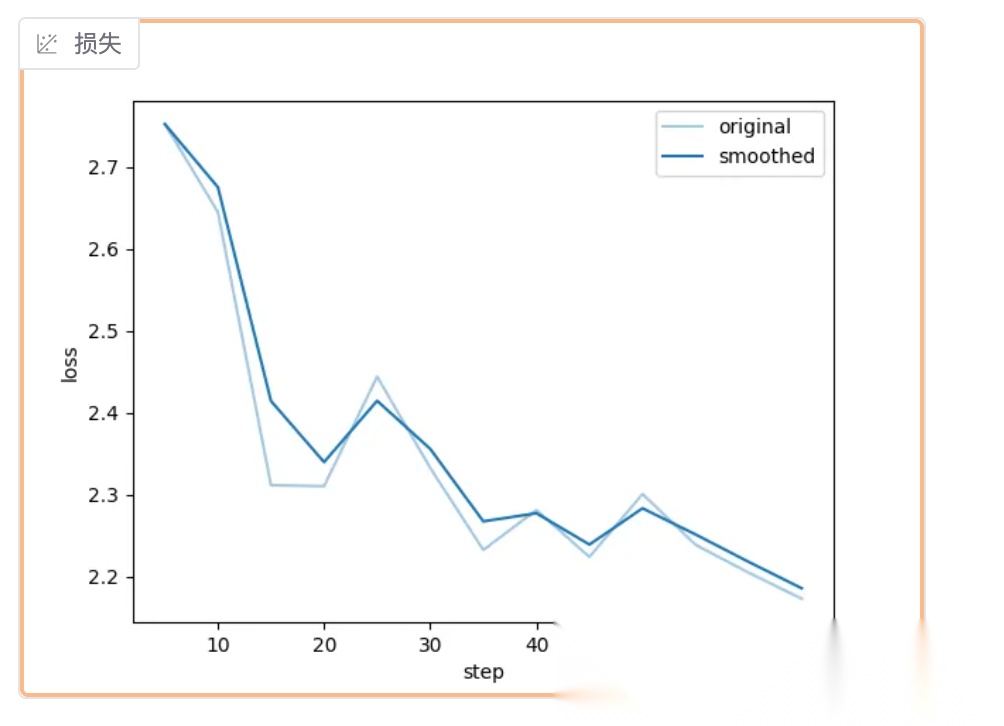
训练进度
如果训练过程中 Loss 不收敛,或者收敛速度很慢,可以根据步骤三种的参数说明尝试调整参数,重新训练。训练完成后,模型会自动保存到指定目录。这时候你就拥有了一个专门回答医疗问题的AI助手了!
第五步:测试效果(检验学习成果)
训练完成后,切换到聊天页面,选择刚才训练好的模型,试试问几个医疗相关的问题:
问题1: 感冒了应该怎么办?
回答: 感冒是常见的上呼吸道感染,建议多休息、多喝水,可以适当服用感冒药缓解症状。如果症状持续加重或出现高热,建议及时就医。
问题2: 高血压患者饮食需要注意什么?
回答: 高血压患者应该低盐饮食,每天盐摄入量控制在6克以下,多吃新鲜蔬菜水果,少吃高脂肪食物,戒烟限酒,保持适当运动。
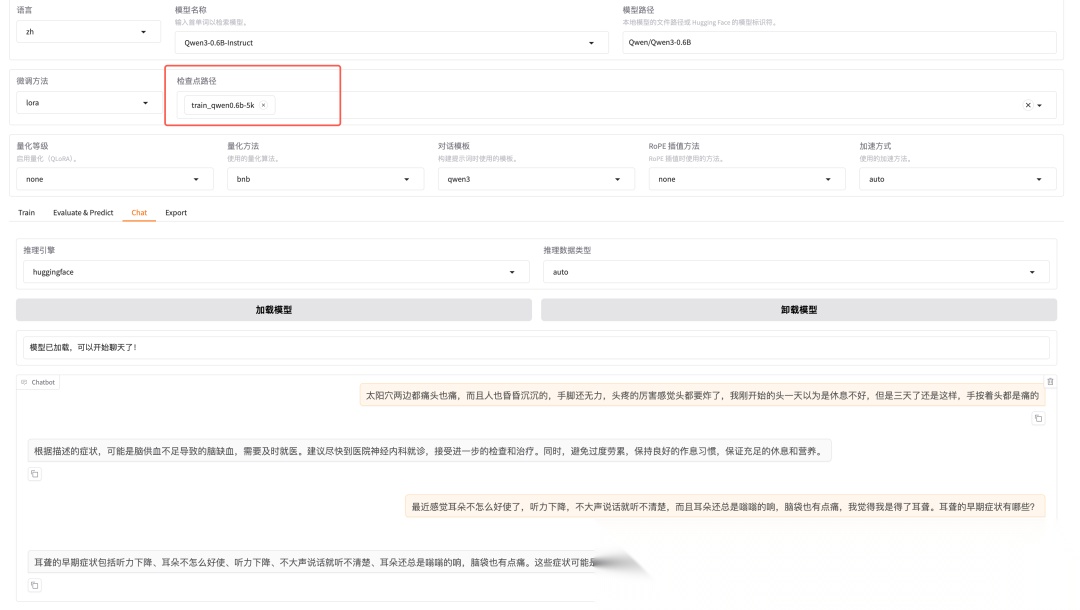
推理过程
看到没?经过微调的模型回答医疗问题明显更专业、更准确了。这就是微调的魅力所在!
第六步:打包模型(把成果带走)
如果你想把训练好的模型部署到其他地方,或者分享给别人,就需要把模型"打包"起来。LLaMA‑Factory提供了很方便的导出功能。
切换到导出页面,选择刚才训练的检查点,设置导出路径,点击开始导出。这样就能得到一个完整的、可以独立运行的模型了。
导出完成后,你就可以把这个模型拿到任何支持的平台上运行,比如部署成API服务,或者集成到你的应用中。
写在最后
通过LLaMA‑Factory微调模型,我们成功把一个通用的AI模型变成了医疗问答专家。整个过程其实并不复杂:准备数据→配置参数→开始训练→测试效果→导出模型。
当然,这只是入门级的操作。想要训练出更好的模型,还需要在数据质量、参数调优、模型评估等方面下更多功夫。但不管怎么说,你已经迈出了AI模型微调的第一步,这就是一个很好的开始!
记住,AI的世界没有标准答案,只有不断的尝试和优化。今天你学会了用LLaMA‑Factory微调模型,明天说不定就能训练出下一个ChatGPT呢!
最后给个小建议:刚开始别追求完美,先把流程跑通,然后再慢慢优化。就像学开车一样,先学会开,再学会开得好。AI模型微调也是这个道理。
加油,未来的AI工程师!🚀
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)