Dify 1.8.0采用蜂巢架构实现模块化设计,核心包含API服务、Web前端等模块,并行ID分组解决工作流节点
Dify 1.8.0采用蜂巢架构实现模块化设计,核心包含API服务、Web前端等模块。关键技术包括:1)RAG实现机制,通过递归分块和混合检索优化文档处理;2)Agent决策机制,支持Function Calling和ReAct两种策略。文章还提供了两个实用案例:1)通过并行ID分组解决工作流节点重复执行问题;2)调整分块参数优化RAG检索性能。该架构具有灵活性、可维护性和扩展性优势,支持从原型到
一、Dify 1.8.0整体架构解析₊˚༉‧✰༶🌿
🍃Dify采用蜂巢架构(beehive architecture),实现模块间"独立存在又紧密协作"的设计目标[10这种架构将核心功能拆解为独立模块,每个模块可单独升级或替换。
🍃模块化架构核心优势
灵活性:模块独立部署与升级,支持模型、工具动态扩展
可维护性:核心逻辑与辅助功能目录分离,代码结构清晰
扩展性:支持从无代码原型到企业级部署的全流程扩展
1.1 核心模块划分₊˚༉‧✰༶🌿
🍃按"功能-路径-职责"三维度划分核心模块:
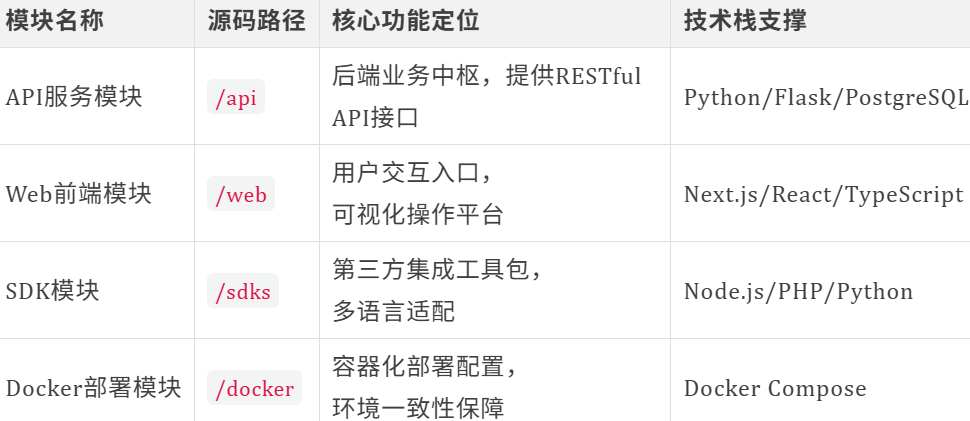
1.2 架构图解析₊˚༉‧✰༶🌿
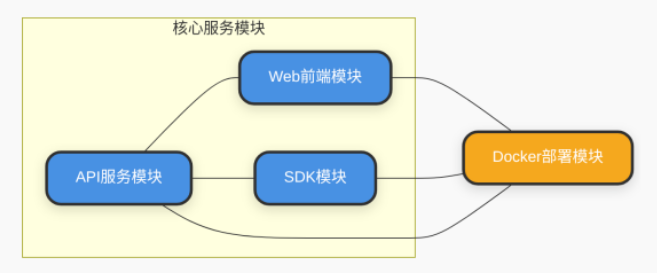
🍃架构图通过蓝色代表业务逻辑模块,橙色代表基础设施模块,直观呈现系统组件与交互逻辑。API服务模块处于中心位置,连接前端交互、后端业务逻辑、外部能力与数据存储,是系统的核心枢纽。
1.3 API服务模块₊˚༉‧✰༶🌿
🍃API服务模块采用经典三层架构设计:
接口层(controllers/):负责HTTP请求接收与响应处理
核心逻辑层(core/):封装系统核心能力,如agent、rag、workflow
业务服务层(services/):承上启下的中间层,封装复杂业务流程
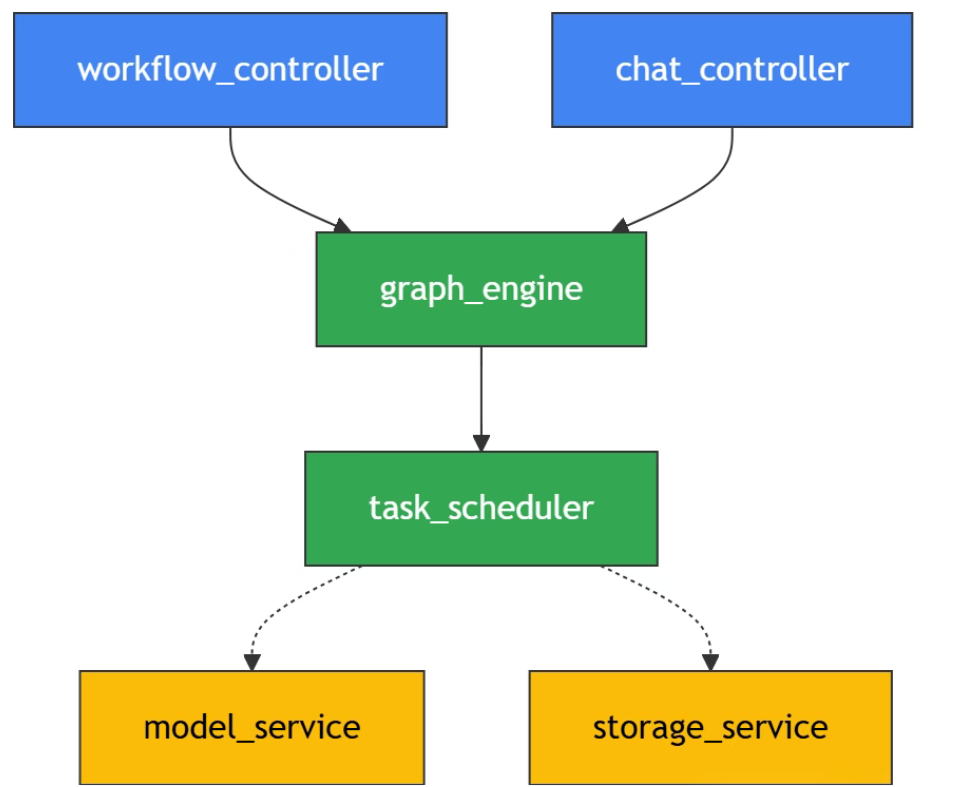
🍃异步工作流引擎的_event_loop方法是实现节点调度的核心:
async def _event_loop(self, dag: dict, context: dict):
execution_tasks = {} # 存储任务状态
# 获取初始节点
start_nodes = [node for node in dag['nodes'] if node['type'] == 'start']
for node in start_nodes:
# 创建节点执行协程
task = asyncio.create_task(self._execute_node(node, context))
execution_tasks[node['id']] = {'task': task, 'status': 'running'}
# 并发执行所有初始节点任务
results = await asyncio.gather(*[t['task'] for t in execution_tasks.values()], return_exceptions=True)
# 更新任务状态
for i, node_id in enumerate(execution_tasks.keys()):
execution_tasks[node_id]['status'] = 'succeeded' if not isinstance(results[i], Exception) else 'failed'
return execution_tasks1.4 Web前端模块₊˚༉‧✰༶🌿
🍃Web前端基于Next.js构建,核心组件包括:
节点编辑器(Node Editor):负责单个节点的参数配置
画布(Canvas):基于ReactFlow实现,提供节点拖拽、连接关系绘制
🍃前端通过会话(Session)对象维护工作流执行状态,核心是current_step字段:
const session = {
session_id: "abc123",
context: {
current_step: "address_confirmation", // 当前执行步骤
user_prefs: { payment_method: "alipay" }
}
};二、关键技术点₊˚༉‧✰༶🌿
2.1 RAG实现机制₊˚༉‧✰༶🌿
Dify的RAG实现包含文档处理与混合检索两大环节:
分块策略与递归切割逻辑₊˚༉‧✰༶🌿
🍃Dify提供两类分块器:
EnhanceRecursiveCharacterTextSplitter(默认):基于多语言分隔符递归拆分FixedRecursiveCharacterTextSplitter:按用户指定字符切割
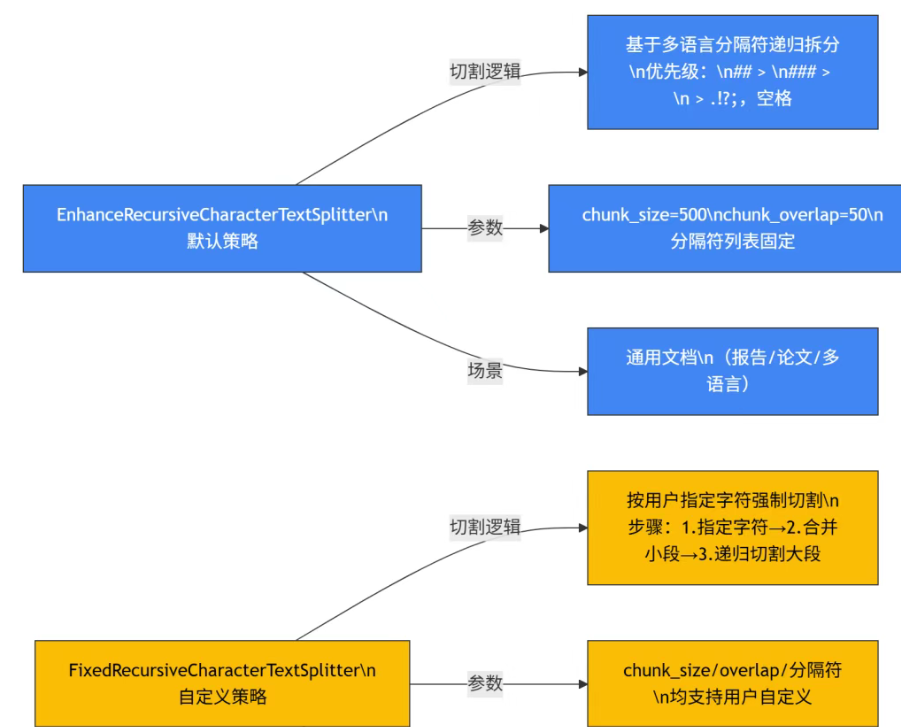
核心递归切割逻辑:
def split_text(text, chunk_size, separators):
if len(text) <= chunk_size:
return [text]
for sep in separators:
parts = text.split(sep)
if len(parts) > 1:
result = []
for part in parts:
result.extend(split_text(part, chunk_size, separators))
return result
# 所有分隔符失败,按字符拆分
return [text[i:i+chunk_size] for i in range(0, len(text), chunk_size)]混合检索:向量与关键词的协同优化₊˚༉‧✰༶🌿
🍃检索环节融合向量检索与关键词检索优势:
def retrieve(self, query, top_k=5):
# 1. 双源召回
vector_results = self.vector_retriever.retrieve(query, top_k * 2)
keyword_results = self.bm25_retriever.retrieve(query, top_k * 2)
# 2. 合并去重
merged = {}
for doc in vector_results + keyword_results:
if doc.id not in merged:
merged[doc.id] = doc
merged_list = list(merged.values())
# 3. 重排序
if self.reranker:
merged_list = self._rerank(query, merged_list)
return merged_list[:top_k]
2.2 Agent机制详解₊˚༉‧✰༶🌿
🍃Dify的Agent机制将Agent节点定位为工作流的"决策中心",支持两种经典决策策略:
Function Calling:精确映射的工具调用策略₊˚༉‧✰༶🌿
def invoke(self, user_id: str, tool_parameters: dict[str, any]):
# 参数类型转换
tool_parameters = self._transform_tool_parameters_type(tool_parameters)
# 执行工具逻辑
return self._invoke(user_id=user_id, tool_parameters=tool_parameters)ReAct:动态迭代的推理-行动循环₊˚༉‧✰༶🌿
🍃"思考-行动-观察"循环处理:
def _agent_loop(self, query, max_iterations=5):
iterations = 0
context = {"query": query, "history": []}
while iterations < max_iterations:
# 1. 思考:生成推理过程
thought = self._generate_thought(context)
# 2. 行动:决定调用工具
action = self._parse_action(thought)
# 3. 观察:执行工具并获取结果
observation = self._execute_tool(action)
context["history"].append({
"thought": thought,
"action": action,
"observation": observation
})
# 检查是否需要继续
if self._should_terminate(thought):
break
iterations += 1
return self._generate_final_answer(context)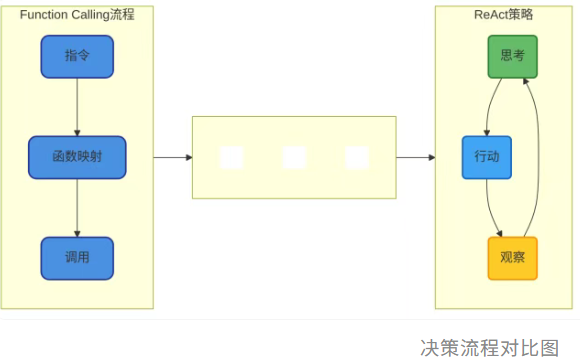
三、实用案例₊˚༉‧✰༶🌿
3.1 、解决工作流并行执行节点重复问题₊˚༉‧✰༶🌿
问题场景:两个并行模板节点连接到同一代码节点时,目标节点被多次触发。
🍃从现象(重复触发)出发,通过源码分析定位到拓扑排序的入度计算缺陷,再通过分组优化入度计算逻辑,最终实现节点仅执行一次
添加并行ID标识,确保同一并行分支的节点入度只计算一次:
parallel_groups = defaultdict(set)
for edge in edges:
parallel_groups[edge.parallel_id].add(edge.target)
for group in parallel_groups.values():
for node in group:
in_degree[node] += 1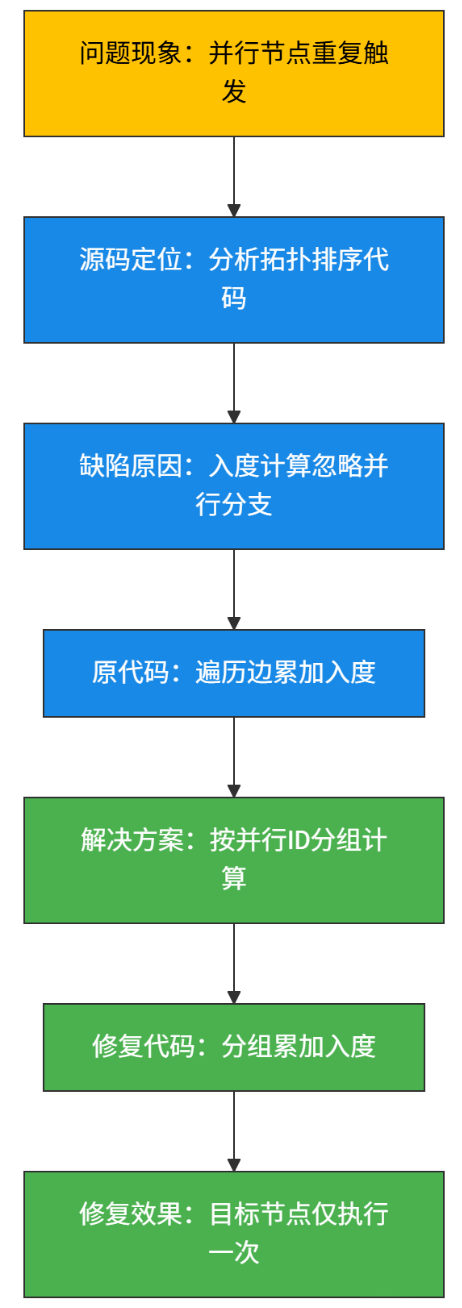
1. 问题现象:并行节点重复触发₊˚༉‧✰༶🌿
- 实现原理:在基于有向无环图(DAG)的任务调度、工作流引擎等场景中,“并行节点” 指的是可以同时执行的多个任务节点。正常情况下,每个节点应仅执行一次,但出现了同一并行节点被多次触发执行的异常现象。
2. 源码定位:分析拓扑排序代码₊˚༉‧✰༶🌿
- 实现原理:拓扑排序是处理有向无环图(DAG)依赖关系的核心算法,用于确定节点的执行顺序(确保所有依赖满足后再执行节点)。
- “入度”(节点的前置依赖数量)是拓扑排序的关键指标:入度为
0的节点可执行。 - 实现细节:需要定位到系统中负责拓扑排序计算和入度管理的代码模块,重点关注 “如何计算节点入度”“如何根据入度触发节点执行”
3. 缺陷原因:入度计算忽略并行分支₊˚༉‧✰༶🌿
- 实现原理:在并行分支场景下,多个分支的节点可能共享同一个 “后续节点”。原入度计算逻辑没有考虑 “并行分支” 的特殊性,导致后续节点的入度被重复累加。
- 假设存在两个并行分支
A→C和B→C(C是共享的后续节点),原逻辑可能会将C的入度计算为2(A和B各贡献 1),但如果A和B属于同一并行组,C的入度应只在 “并行组全部完成后” 才减为0。原逻辑错误地重复计算了入度,导致C被多次触发。
4. 原代码:遍历边累加入度₊˚༉‧✰༶🌿
- 实现原理:原代码通过遍历图中所有的边(如从节点
X到节点Y的边表示X是Y的前置依赖),对每个边的终点(Y)执行 “入度 + 1” 操作。 -
in_degree = defaultdict(int) for edge in all_edges: start, end = edge in_degree[end] += 1 # 每条边都让终点入度+1 - 这种方式在并行分支中会重复累加同一节点的入度(如
C的入度被A→C和B→C各加 1),导致入度计算错误。 -
5. 解决方案:按并行 ID 分组计算₊˚༉‧✰༶🌿
- 实现原理:为并行分支引入 “并行 ID” 标识,确保同一并行组内的多个分支在计算入度时,仅对后续节点的入度 “贡献一次”(而非每条边都贡献一次)。
- 实现细节:
- 为每个并行分支分配相同的
parallel_id。 - 计算入度时,按
parallel_id分组,同一组内的多条边(如A→C和B→C若属于同一parallel_id),仅对C的入度加1(而非加2)
- 为每个并行分支分配相同的
- 实现原理:通过 “并行 ID 分组”,将同一并行组的边合并计算入度,避免重复累加
-
6. 修复代码:分组累加入度₊˚༉‧✰༶🌿
- 实现原理:通过 “并行 ID 分组”,将同一并行组的边合并计算入度,避免重复累加。
-
in_degree = defaultdict(int) parallel_groups = defaultdict(set) # 按parallel_id分组边的终点 # 步骤1:按parallel_id分组边的终点 for edge in all_edges: start, end, parallel_id = edge # 边包含并行ID信息 parallel_groups[parallel_id].add(end) # 步骤2:每组仅对终点入度+1 for group in parallel_groups.values(): for node in group: in_degree[node] += 1 - 这样,同一并行组内的多个边(如
A→C和B→C),只会让C的入度加1,而非原逻辑的加2。
7. 修复效果:目标节点仅执行一次₊˚༉‧✰༶🌿
- 实现原理:入度计算正确后,拓扑排序能准确判断节点的 “可执行时机”:当且仅当所有前置依赖(并行组全部完成)满足时,节点入度才会减为
0,从而触发一次执行。 - 实现细节:修复后,共享的后续节点(如
C)会在 “所属并行组的所有前置节点都完成” 后,入度变为0,仅被触发执行一次,解决了重复执行的问题。
3.2 优化RAG检索性能的分块策略调整₊˚༉‧✰༶🌿
原分块策略(chunk_size=500)导致文档分块过多,检索效率低下,通过修改splitter.py中的参数:
splitter = EnhanceRecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
# 修改后
splitter = EnhanceRecursiveCharacterTextSplitter(
chunk_size=1000, # 增大分块大小
chunk_overlap=100 # 调整重叠比例
)四、技术栈解析₊˚༉‧✰༶🌿
后端架构:Flask + Celery 构建异步服务体系₊˚༉‧✰༶🌿
Dify 后端采用 Flask + Celery 核心架构,配合 NGINX 反向代理形成完整服务链路。整体微服务流程为:NGINX → API Server(Flask)→ Task Queue(Celery)→ Worker Cluster → VectorDB/Model Gateway,实现请求分发、任务调度与资源隔离的全链路管理
Flask 路由设计:作为 API 入口,Flask 通过模块化路由管理核心业务接口,例如模型调用、插件集成等请求。相较于早期版本使用的 FastAPI,Flask 更适合 Dify 复杂业务逻辑的灵活适配,尤其在插件扩展场景中,可通过动态注册路由支持 Python 插件的热加载(需 Python 3.12+ 环境)
Celery 异步任务处理:通过 Task Queue 解耦同步请求与耗时操作,典型如 dify-plus 中的异步额度计算逻辑——当用户触发多轮对话或批量知识库导入时,Celery Worker 会异步执行额度扣减、资源分配等任务,避免阻塞主流程。Worker Cluster 则通过水平扩展支持高并发场景,确保任务处理效率
关键协议栈支撑:
模型通信:遵循 OpenAI 兼容 API 规范,确保第三方模型无缝接入
向量计算:采用 HNSW/PQ 混合索引策略,平衡检索速度与精度
流式传输:通过 Server-Sent Events(SSE)实现对话内容实时推送[5]
前端框架:Next.js 驱动服务端渲染体验₊˚༉‧✰༶🌿
前端基于 Next.js 构建,融合 React + TypeScript 实现组件化开发,核心优势在于服务端渲染(SSR) 能力。相较于传统客户端渲染,SSR 可在服务端完成页面初始渲染,显著提升首屏加载速度(实测优化 30%+ 加载时间),同时改善动态交互场景下的用户体验,例如知识库检索结果的实时更新[8]。
在代码组织层面,web 目录下的页面组件(如 pages/chat/[id].tsx)通过 Next.js 的文件路由系统映射 URL,结合 getServerSideProps 函数在服务端预获取对话历史、用户配置等数据,减少客户端请求次数。TypeScript 的强类型约束则降低了大型组件协作时的类型错误风险,尤其在复杂工作流引擎界面开发中提升代码可维护性[7]。
数据存储:PostgreSQL 双重角色与架构选型
Dify 采用 PostgreSQL 作为核心数据存储,承担主数据库与向量存储基础的双重职责:
主数据库功能:存储用户信息、对话历史、插件配置等结构化数据,支持事务一致性与复杂 SQL 查询,满足业务数据的高可靠性需求[9]。
向量存储基础:通过 pgvector 扩展支持向量数据类型,实现知识库文档的向量化存储与相似度检索。例如,文档片段经 Embedding 模型转换为向量后,直接存入 PostgreSQL 并创建 HNSW 索引,简化部署架构[7]。
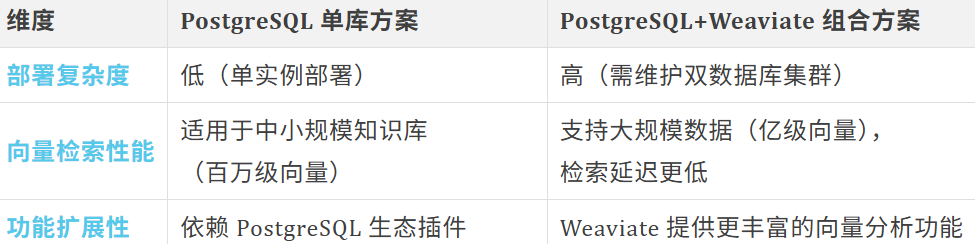
与官方“PostgreSQL+Weaviate”方案对比:
五、核心概念₊˚༉‧✰༶🌿
工作流引擎₊˚༉‧✰༶🌿
定义:Dify 的工作流引擎是可视化构建 AI 应用流程的核心组件,通过有向图模型实现节点间的数据流转与逻辑控制
核心功能:
多节点支持:集成 LLM 调用、工具集成、数据处理等节点类型,例如代码执行节点支持变量引用和输出类型定义,条件分支节点需注意执行顺序控制
可视化编排:通过画布界面拖拽节点,支持实时调试和版本控制,可在 dify-plus 的“应用中心”直观查看节点串联逻辑
数据流转机制:基于有向图模型传递变量,支持变量聚合节点的分组配置,避免数据丢失
实战价值:无需编写复杂代码即可搭建企业级 AI 应用,例如通过条件分支节点实现多轮对话逻辑,或结合工具节点调用外部 API,大幅降低开发门槛。
模型适配器₊˚༉‧✰༶🌿
定义:连接外部模型与 Dify 系统的标准化接口层,实现多模型提供商的兼容与统一调用[11]。
核心功能:
多模型类型支持:覆盖 LLM、text_embedding、rerank 等类型,按模型类型(如 llm、text_embedding)组织代码文件,实现符合系统接口规范的调用逻辑类
-
灵活配置方式:
-
预定义模型(如 OpenAI 的 gpt-3.5-turbo-0125):仅需统一凭证,无需额外配置
-
自定义模型:需通过 YAML 配置文件定义 provider、label、icon 等信息,以及 server_url、model_uid 等 credential schema
-
错误处理机制:内置请求重试与参数验证逻辑,确保模型调用稳定性。
实战价值:可按需集成私有部署模型(如 Xinference)或商业模型(如 Claude),例如通过 customizable-model 配置企业内部 LLM,实现数据不出域的安全调用。
模型调用差异对比
OpenAI(预定义模型):仅需配置 API Key,系统自动处理调用逻辑,适合快速接入成熟服务。
自定义模型:需手动配置 YAML 文件与 model_uid,支持私有部署场景,但需自行处理模型版本兼容问题。
RAG Pipeline₊˚༉‧✰༶🌿
定义:检索增强生成的全流程处理管道,通过检索外部知识增强模型生成能力,是 Dify 核心功能之一
核心功能:
文档处理:支持多格式文档解析(如 PDF、Markdown)与智能分块,优化文本片段长度以适配模型上下文窗口。
向量生成:将文档片段转换为向量嵌入(text_embedding),支持自定义嵌入模型配置
混合检索:结合关键词检索与向量检索,通过 rerank 模型重排序结果,提升上下文相关性
实战价值:解决模型“知识过时”问题,例如企业可上传产品手册构建知识库,用户提问时系统自动检索相关片段生成精准回答,降低幻觉风险。
Agent 能力₊˚༉‧✰༶🌿
定义:基于 LLM Function Calling 与 ReAct 推理逻辑的智能体框架,支持工具调用与复杂任务执行
核心功能:
工具调用:集成 50+ 内置工具(如搜索、数据库查询),支持通过 API 扩展自定义工具(需遵循请求规范:Content-Type: application/json,Authorization: Bearer {api_key})
ReAct 推理:通过“思考-行动-观察”循环实现任务拆解,例如调用钉钉登录的 OAuth2 流程时,Agent 会先分析需获取 access_token,再执行 API 请求并处理响应结果。
对话管理:支持多轮对话状态跟踪与长上下文记忆,维持对话连贯性。
实战价值:赋能 AI 执行复杂业务流程,例如自动查询 CRM 数据生成销售报告,或通过外部工具调用实现跨系统数据同步,替代人工重复操作。
致谢₊˚༉‧✰༶🌿
谢谢大家的阅读,很多不足支出,欢迎大家在评论区指出,如果我的内容对你有帮助,
可以点赞 , 收藏 ,大家的支持就是我坚持下去的动力!
做一个浪漫的现实主义者!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 51
51 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)