LangChain:AI应用开发的Spring Boot
本文介绍了LangChain框架,这是一个专为AI应用开发设计的标准化工具,旨在简化大语言模型应用的构建过程。文章通过对比传统手工开发与使用LangChain的方式,展示了该框架如何将复杂的AI开发流程模块化、标准化。LangChain提供模型交互接口、提示词管理、数据检索、记忆系统等核心组件,支持组件化组合开发。其分层架构设计允许开发者灵活替换组件,同时配套工具链(LangGraph、LangS
书接上回
在上篇文章中,我们从零开始搭建了一个RAG系统,体验了完整的技术流程。但你可能已经感受到,手写代码的复杂性不容小觑——文档加载、文本分割、向量化、检索、生成,每个环节都需要精心处理,代码量大,维护成本高。这就像早期的Java Web开发,需要手动配置各种XML文件,写大量的样板代码。
今天我们来聊聊LangChain——一个专门为大语言模型应用开发而生的框架。如果说Spring Boot解放了Java开发者,那么LangChain就是AI应用开发者的救星。
LangChain是什么?
LangChain是一个用于开发由大型语言模型驱动的应用程序的框架。简单来说,它就像是AI领域的Spring Boot,将复杂的AI应用开发流程封装成了简洁易用的组件。
用一个类比来理解:如果把AI应用开发比作搭积木,那么原生API就像是给你一堆零散的塑料块,你需要自己设计、切割、打磨;而LangChain则像是乐高积木套装,提供了标准化的积木块和详细的搭建指南,让你能够快速组装出想要的作品。
LangChain的核心价值
- 标准化接口:统一了不同AI服务商的API调用方式
- 模块化设计:将复杂功能拆分成可复用的组件
- 链式组合:支持灵活的功能组合和流程编排
- 生态丰富:集成了大量第三方服务和工具
LangChain解决了什么问题?
还记得我们上篇文章手写的RAG系统吗?几百行代码,复杂的异常处理,繁琐的配置管理。使用LangChain,同样的功能可能只需要几十行代码:
传统方式(手写):
# 需要自己实现文档加载
# 需要自己实现文本分割
# 需要自己管理向量数据库
# 需要自己处理检索逻辑
# 需要自己组装提示词
# ...
LangChain方式:
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
# 几行代码搞定
loader = DirectoryLoader('./docs')
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000)
texts = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(texts, embeddings)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
LangChain的生命周期支持
LangChain不仅简化开发,还提供了完整的应用生命周期支持:
- 开发阶段:提供丰富的组件库和模板,快速搭建原型
- 测试阶段:LangSmith提供调试、监控和评估工具
- 部署阶段:LangServe可以将任何链快速转化为REST API
这就像是从手工作坊升级到了现代化工厂流水线。
LangChain的核心组件架构
LangChain的设计哲学是"万物皆可组合"。它将AI应用开发中的各种功能抽象成标准化的组件,这些组件可以像积木一样自由组合。
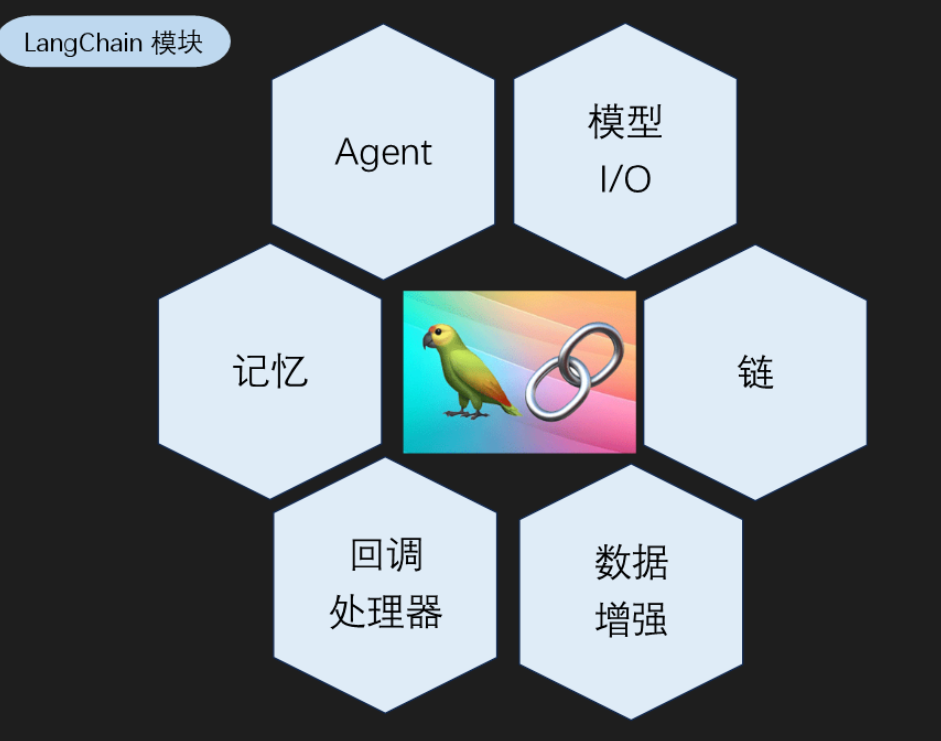
核心组件概览
模型层(Models)
这是与各种AI模型交互的标准接口层,就像JDBC为Java提供了统一的数据库访问接口一样。无论你使用的是OpenAI、百度文心、还是阿里通义千问,都可以通过相同的API来调用。
提示工程(Prompts)
专业的提示词管理系统,支持模板化、参数化、版本控制。把提示词从硬编码中解放出来,让AI应用更加灵活和可维护。
数据检索(Retrieval)
完整的RAG技术栈,从文档加载到向量检索,一站式解决方案。想象一下,之前我们手写的几百行代码,现在几行就能搞定。
记忆系统(Memory)
让AI具备"记忆"能力,支持短期对话记忆和长期知识存储。就像给AI装上了"大脑",能记住之前的对话内容。
链式组合(Chains)
这是LangChain的核心创新,通过管道操作符|将不同组件串联起来,形成复杂的处理流程。
智能代理(Agents)
让AI具备自主决策能力,能够根据任务需求自动选择和调用工具,实现真正的智能助手。
组件分层架构
LangChain采用了分层架构设计,每一层都有明确的职责:
1. 模型 I/O 层
- LLMs:纯文本输入输出的语言模型
- ChatModels:基于对话格式的聊天模型
- Prompts:提示词模板管理
- OutputParsers:输出结果解析器
2. 数据检索层
- Document Loaders:支持PDF、Word、Markdown等多种格式
- Text Splitters:智能文本分割器
- Embedding Models:文本向量化模型
- Vector Stores:向量数据库接口
- Retrievers:检索器,负责相似性搜索
3. 智能代理层
- Tools:外部工具接口(搜索、计算、API调用等)
- Toolkits:工具集合(数据库操作、邮件处理等)
- Agents:智能代理,负责任务规划和工具调用
这种分层设计的好处是:你可以只使用需要的组件,也可以替换其中的某个组件而不影响其他部分。比如,你可以轻松地将OpenAI的模型替换为本地部署的模型,而不需要修改其他代码。
LangChain生态系统
LangChain不是一个单体框架,而是一个完整的生态系统。就像Spring不仅仅是一个IoC容器,还包括Spring Boot、Spring Cloud等一系列项目一样。
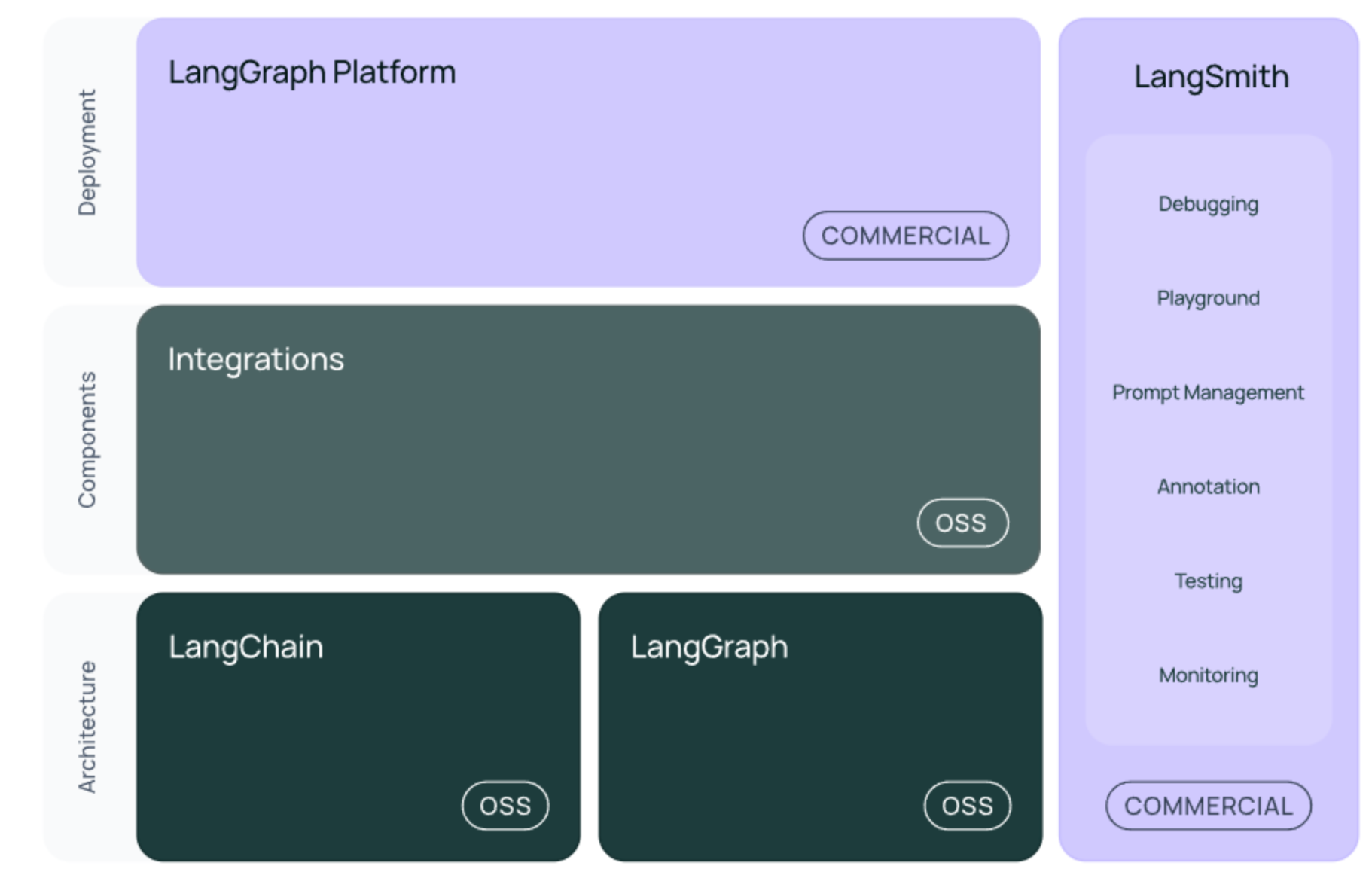
核心包结构
langchain-core:基础核心包
这是整个生态的基石,定义了所有的抽象接口和LangChain表达式语言(LCEL)。就像Java的java.lang包一样,提供最基础的功能。
langchain-community:社区集成包
包含了大量第三方服务的集成,比如各种数据库、向量存储、API服务等。这就像Spring Boot的starter包,让你可以快速集成各种服务。
langchain:主框架包
包含了链、代理、检索策略等高级功能,构成了应用程序的认知架构。这是我们主要使用的包。
扩展工具
LangGraph:复杂工作流编排
当你需要构建复杂的多步骤、多参与者的AI应用时,LangGraph就派上用场了。它通过图的方式来建模复杂的业务流程。
想象一个客服系统的处理流程:
用户问题 → 意图识别 → 路由到专业客服 → 知识库检索 → 生成回答 → 质量检查 → 返回用户
这种复杂的流程用传统的链式调用很难处理,但用LangGraph可以轻松建模。
LangServe:API服务化
开发完成后,你肯定希望把AI应用部署成API服务。LangServe可以将任何LangChain链一键转换为REST API,支持异步调用、流式输出等高级功能。
LangSmith:开发者平台
这是LangChain的"调试利器",提供了完整的可观测性支持:
- 调试:可视化链的执行过程,定位问题环节
- 监控:实时监控应用性能和质量指标
- 评估:自动化测试和评估模型效果
- 优化:基于数据分析优化提示词和参数
Model I/O:与AI模型交互的标准化接口
Model I/O是LangChain的核心模块之一,它将与AI模型的交互过程标准化为三个环节:格式化输入、调用模型、解析输出。这就像是为AI模型交互制定了一套标准的"通信协议"。
为什么需要Model I/O?
想象一下,如果没有统一的接口:
- 调用OpenAI需要一套API
- 调用百度文心需要另一套API
- 调用本地模型又是不同的接口
- 输出格式各不相同,解析逻辑到处都是
这就像早期的数据库访问,每个数据库都有自己的连接方式,直到JDBC出现才统一了标准。
Model I/O的三个核心环节
1. 提示模板(Format)
将用户输入转换为模型能理解的格式,支持动态参数、条件逻辑、模板继承等高级功能。
2. 模型调用(Predict)
提供统一的接口来调用不同类型的语言模型,屏蔽底层API的差异。
3. 输出解析(Parse)
将模型的输出转换为结构化数据,方便后续处理。
这三个环节形成了一个完整的处理管道,让AI模型的调用变得标准化和自动化。
提示模板:从硬编码到智能化
提示模板是LangChain最实用的功能之一。在没有模板之前,我们的提示词都是硬编码的,修改和维护非常麻烦。
传统方式的痛点:
# 硬编码,难以维护
prompt = f"你是一个{role},请根据{context}来回答{question}"
# 每次修改都需要找到所有使用的地方
# 难以复用
# 容易出错
LangChain模板的优势:
# 模板化,易于维护
template = "你是一个{role},请根据{context}来回答{question}"
prompt = PromptTemplate.from_template(template)
formatted_prompt = prompt.format(role="专家", context="技术文档", question="什么是RAG?")
LangChain提供了三种主要的提示模板类型,适用于不同的场景:
1. 基础模板(PromptTemplate)
最简单的字符串模板,适用于单轮对话:
from langchain.prompts import PromptTemplate
# 创建一个简单的翻译模板
template = """
请将以下{source_language}文本翻译成{target_language}:
原文:{text}
译文:
"""
prompt = PromptTemplate(
input_variables=["source_language", "target_language", "text"],
template=template
)
# 使用模板
formatted_prompt = prompt.format(
source_language="英文",
target_language="中文",
text="Hello, how are you?"
)
2. 聊天模板(ChatPromptTemplate)
适用于多轮对话和角色扮演场景:
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# 系统角色设定
system_template = "你是一个{expertise}专家,擅长{skill}。请用专业而易懂的方式回答问题。"
system_prompt = SystemMessagePromptTemplate.from_template(system_template)
# 用户消息模板
human_template = "问题:{question}\n\n请提供详细的解答。"
human_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 组合成聊天模板
chat_prompt = ChatPromptTemplate.from_messages([
system_prompt,
human_prompt
])
# 使用模板
messages = chat_prompt.format_prompt(
expertise="Python开发",
skill="web框架和数据库操作",
question="如何优化Django的数据库查询性能?"
).to_messages()
3. 少样本模板(FewShotPromptTemplate)
通过示例来教模型如何回答,特别适用于格式化输出:
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
# 定义示例
examples = [
{
"question": "什么是Spring Boot?",
"answer": "Spring Boot是一个Java框架,用于简化Spring应用的创建和部署。\n\n核心特性:\n- 自动配置\n- 内嵌服务器\n- 生产就绪的监控\n\n使用场景:微服务、Web应用、API开发"
},
{
"question": "什么是Docker?",
"answer": "Docker是一个容器化平台,用于打包和部署应用程序。\n\n核心特性:\n- 容器化技术\n- 镜像管理\n- 跨平台部署\n\n使用场景:CI/CD、微服务、环境一致性"
}
]
# 定义示例模板
example_template = """
问题:{question}
回答:{answer}
"""
example_prompt = PromptTemplate(
input_variables=["question", "answer"],
template=example_template
)
# 创建少样本模板
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="你是一个技术专家,请按照以下格式回答技术问题:",
suffix="问题:{input}\n回答:",
input_variables=["input"]
)
# 使用模板
formatted_prompt = few_shot_prompt.format(input="什么是Kubernetes?")
# 导入聊天消息类模板
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain_openai import ChatOpenAI
import os
from dotenv import load_dotenv
load_dotenv()
# 系统模板的构建
system_template = "你是一个翻译专家,擅长将 {input_language} 语言翻译成 {output_language}语言."
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
# 用户模版的构建
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 组装成最终模版
prompt_template = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# 格式化提示消息生成提示
prompt = prompt_template.format_prompt(input_language="英文", output_language="中文",
text="I love Large Language Model.").to_messages()
# 打印模版
print("prompt:", prompt)
# 创建模型实例
model = ChatOpenAI(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwen-plus')
# 得到模型的输出
result = model.invoke(prompt)
# 打印输出内容
print("result:", result.content)
模型调用:一套接口,多种模型
LangChain的模型层就像是AI世界的"万能适配器",让你可以用同一套代码调用不同厂商的模型。这就像JDBC让你可以用同样的代码操作MySQL、PostgreSQL、Oracle等不同数据库一样。
LangChain支持三大模型类型
1. 文本补全模型(LLM)
这是最基础的模型类型,输入文本,输出文本。适用于文本补全、创意写作等场景:
from langchain_openai import OpenAI
# 初始化文本模型
llm = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model='qwen-turbo'
)
# 简单的文本补全
text = "人工智能的发展历程可以分为以下几个阶段:"
result = llm.invoke(text)
print(result)
# 批量处理
texts = [
"Python的优势是",
"机器学习的核心概念包括",
"区块链技术的应用场景有"
]
results = llm.batch(texts)
for result in results:
print(result)
2. 聊天模型(Chat Model)
基于对话的模型,支持角色设定和多轮对话,这是目前最主流的模型类型:
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, AIMessage
# 初始化聊天模型
chat_model = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus",
temperature=0.7 # 控制创造性
)
# 单轮对话
messages = [HumanMessage(content="解释一下什么是微服务架构")]
response = chat_model.invoke(messages)
print(response.content)
# 多轮对话示例
conversation = [
SystemMessage(content="你是一个资深的软件架构师,擅长分布式系统设计"),
HumanMessage(content="我想了解微服务架构的优缺点"),
AIMessage(content="微服务架构有以下优点..."), # 模拟之前的回答
HumanMessage(content="那在什么情况下不适合使用微服务?")
]
response = chat_model.invoke(conversation)
print(response.content)
# 流式响应(实时输出)
for chunk in chat_model.stream([HumanMessage(content="详细介绍Docker容器技术")]):
print(chunk.content, end="", flush=True)
3. 文本嵌入模型(Embedding Model)
将文本转换为向量,是RAG系统的核心组件:
from langchain_community.embeddings import DashScopeEmbeddings
import numpy as np
# 初始化嵌入模型
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv("api_key"),
model='text-embedding-v3'
)
# 单个文本向量化
text = "LangChain是一个强大的AI应用开发框架"
vector = embeddings.embed_query(text)
print(f"向量维度: {len(vector)}")
print(f"向量示例: {vector[:5]}...") # 显示前5个数值
# 批量文档向量化
documents = [
"Spring Boot简化了Java企业级应用开发",
"Docker容器技术实现了应用的标准化部署",
"Kubernetes提供了容器编排和管理能力",
"微服务架构支持大规模分布式系统"
]
doc_vectors = embeddings.embed_documents(documents)
print(f"处理了{len(doc_vectors)}个文档")
# 计算文本相似度
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
query = "Java开发框架"
query_vector = embeddings.embed_query(query)
for i, doc in enumerate(documents):
similarity = cosine_similarity(query_vector, doc_vectors[i])
print(f"'{doc}' 相似度: {similarity:.3f}")
LangChain最大的优势是可以轻松切换不同的模型,而无需修改业务逻辑:
# 定义统一的聊天函数
def chat_with_model(model, question):
messages = [HumanMessage(content=question)]
response = model.invoke(messages)
return response.content
# 可以轻松切换不同模型
openai_model = ChatOpenAI(api_key="sk-...", model="gpt-3.5-turbo")
qwen_model = ChatOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-plus"
)
question = "解释一下RESTful API的设计原则"
# 同样的代码,不同的模型
openai_answer = chat_with_model(openai_model, question)
qwen_answer = chat_with_model(qwen_model, question)
print("OpenAI回答:", openai_answer)
print("通义千问回答:", qwen_answer)
输出解析器:将AI回答结构化
AI模型的输出通常是自然语言文本,但在实际应用中,我们往往需要结构化的数据。输出解析器就是解决这个问题的利器,它可以将模型的文本输出转换为JSON、CSV、XML等格式的结构化数据。
没有解析器的困扰:
# AI输出的原始文本
response = "推荐以下三本书:《Java编程思想》、《Spring实战》、《微服务设计》"
# 需要手动解析
# 容易出错,难以维护
books = response.split(":")[1].split("、") # 这样的代码很脆弱
使用解析器的优雅方式:
# 结构化输出
[
{"title": "Java编程思想", "category": "编程"},
{"title": "Spring实战", "category": "框架"},
{"title": "微服务设计", "category": "架构"}
]
常用输出解析器类型有四种。
1. JSON解析器
最常用的解析器,将输出转换为JSON格式:
from langchain.output_parsers import JsonOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain.schema import OutputParserException
from pydantic import BaseModel, Field
# 定义数据结构
class BookRecommendation(BaseModel):
title: str = Field(description="书籍标题")
author: str = Field(description="作者姓名")
category: str = Field(description="书籍分类")
rating: float = Field(description="评分,1-10分")
reason: str = Field(description="推荐理由")
# 创建JSON解析器
parser = JsonOutputParser(pydantic_object=BookRecommendation)
# 构建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的技术书籍推荐专家。{format_instructions}"),
("user", "请推荐一本关于{topic}的优秀书籍")
])
# 创建链
chain = prompt | model | parser
try:
result = chain.invoke({
"topic": "Spring Boot",
"format_instructions": parser.get_format_instructions()
})
print(f"推荐书籍: {result['title']}")
print(f"作者: {result['author']}")
print(f"评分: {result['rating']}")
print(f"推荐理由: {result['reason']}")
except OutputParserException as e:
print(f"解析失败: {e}")
2. 列表解析器
将输出解析为列表格式:
from langchain.output_parsers import CommaSeparatedListOutputParser
# 创建列表解析器
list_parser = CommaSeparatedListOutputParser()
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个技术专家。{format_instructions}"),
("user", "列出学习{technology}需要掌握的5个核心概念")
])
chain = prompt | model | list_parser
result = chain.invoke({
"technology": "Docker",
"format_instructions": list_parser.get_format_instructions()
})
print("Docker核心概念:")
for i, concept in enumerate(result, 1):
print(f"{i}. {concept}")
3. 枚举解析器
当输出需要限制在特定选项中时:
from langchain.output_parsers import EnumOutputParser
from enum import Enum
class DifficultyLevel(Enum):
BEGINNER = "初级"
INTERMEDIATE = "中级"
ADVANCED = "高级"
EXPERT = "专家级"
# 创建枚举解析器
enum_parser = EnumOutputParser(enum=DifficultyLevel)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个学习规划师。{format_instructions}"),
("user", "评估学习{topic}的难度等级")
])
chain = prompt | model | enum_parser
result = chain.invoke({
"topic": "Kubernetes集群管理",
"format_instructions": enum_parser.get_format_instructions()
})
print(f"学习难度: {result.value}")
4. 结构化解析器
处理复杂的结构化数据:
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# 定义响应结构
response_schemas = [
ResponseSchema(name="concept", description="技术概念名称"),
ResponseSchema(name="definition", description="概念的详细定义"),
ResponseSchema(name="example", description="实际应用示例"),
ResponseSchema(name="difficulty", description="学习难度:简单/中等/困难"),
ResponseSchema(name="prerequisites", description="前置知识要求")
]
# 创建结构化解析器
structured_parser = StructuredOutputParser.from_response_schemas(response_schemas)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个计算机科学教育专家。{format_instructions}"),
("user", "详细解释{concept}这个概念")
])
chain = prompt | model | structured_parser
result = chain.invoke({
"concept": "微服务架构",
"format_instructions": structured_parser.get_format_instructions()
})
print(f"概念: {result['concept']}")
print(f"定义: {result['definition']}")
print(f"示例: {result['example']}")
print(f"难度: {result['difficulty']}")
print(f"前置知识: {result['prerequisites']}")
自定义解析器
当现有解析器不满足需求时,可以自定义:
from langchain.schema import BaseOutputParser
import re
class CodeBlockParser(BaseOutputParser):
"""提取代码块的解析器"""
def parse(self, text: str) -> dict:
# 提取代码块
code_pattern = r'```(\w+)?\n(.*?)\n```'
matches = re.findall(code_pattern, text, re.DOTALL)
result = {
"explanation": re.sub(code_pattern, "", text).strip(),
"code_blocks": []
}
for language, code in matches:
result["code_blocks"].append({
"language": language or "text",
"code": code.strip()
})
return result
# 使用自定义解析器
code_parser = CodeBlockParser()
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个编程导师,请提供代码示例和解释"),
("user", "演示如何在Python中使用{concept}")
])
chain = prompt | model | code_parser
result = chain.invoke({"concept": "装饰器模式"})
print("解释:", result["explanation"])
for i, block in enumerate(result["code_blocks"], 1):
print(f"\n代码示例 {i} ({block['language']}):")
print(block["code"])
输出解析器的强大之处在于它让AI的输出变得可预测和可处理,这对于构建稳定的生产应用至关重要。
数据检索:让AI拥有"外部记忆"
还记得我们在RAG文章中手写的文档加载、文本分割、向量化等功能吗?LangChain将这些复杂的操作封装成了简洁的组件,让RAG应用开发变得像搭积木一样简单。
正如我们之前讨论的,大模型存在三大局限:
- 知识时效性问题:训练数据有截止时间
- 领域知识深度不足:通用模型缺乏专业领域的深度知识
- 私域数据缺失:无法访问企业内部数据
数据检索模块就是解决这些问题的核心,它让AI可以从外部知识库中实时获取最新、最专业的信息。
LangChain的数据检索架构
LangChain提供了完整的RAG技术栈,从数据获取到检索应用,一应俱全:
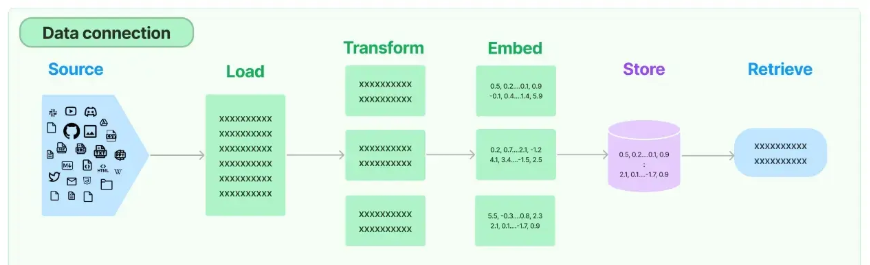
整个流程分为四个核心环节:
- 文档加载:从各种数据源获取信息
- 文档处理:清洗和分割文档
- 向量化存储:将文本转换为向量并存储
- 检索应用:根据查询找到相关信息
文档加载器:支持多种数据源
LangChain提供了丰富的文档加载器,支持几乎所有常见的文件格式和数据源。
1. 本地文件加载
from langchain_community.document_loaders import (
PyPDFLoader, CSVLoader, TextLoader,
UnstructuredMarkdownLoader, DirectoryLoader
)
# PDF文件加载
pdf_loader = PyPDFLoader("./documents/technical_guide.pdf")
pdf_pages = pdf_loader.load_and_split()
print(f"PDF共有{len(pdf_pages)}页")
# CSV文件加载
csv_loader = CSVLoader("./data/products.csv")
csv_docs = csv_loader.load()
print(f"CSV共有{len(csv_docs)}条记录")
# Markdown文件加载
md_loader = UnstructuredMarkdownLoader("./docs/README.md")
md_docs = md_loader.load()
# 批量加载整个目录
dir_loader = DirectoryLoader(
"./documents",
glob="**/*.{txt,md,pdf}", # 支持多种格式
loader_cls=TextLoader
)
all_docs = dir_loader.load()
print(f"目录下共加载{len(all_docs)}个文档")
2. 网络数据加载
from langchain_community.document_loaders import (
WebBaseLoader, WikipediaLoader, ArxivLoader
)
# 网页内容加载
web_loader = WebBaseLoader("https://python.langchain.com/docs/introduction/")
web_docs = web_loader.load()
# Wikipedia文章加载
wiki_loader = WikipediaLoader(query="LangChain", load_max_docs=2)
wiki_docs = wiki_loader.load()
# 学术论文加载
arxiv_loader = ArxivLoader(query="retrieval augmented generation", load_max_docs=3)
papers = arxiv_loader.load()
3. 数据库和API加载
from langchain_community.document_loaders import SQLDatabaseLoader
# 数据库加载
db_loader = SQLDatabaseLoader(
"SELECT title, content FROM articles WHERE category='AI'",
connection_string="sqlite:///knowledge.db"
)
db_docs = db_loader.load()
文档分割器:智能切分文本
文档分割是RAG系统的关键环节,LangChain提供了多种切分策略:
1. 递归字符分割器(推荐)
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 智能分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每块最大字符数
chunk_overlap=200, # 重叠字符数
length_function=len, # 长度计算函数
separators=["\n\n", "\n", " ", ""] # 分割优先级
)
# 分割文档
docs = text_splitter.split_documents(pdf_pages)
print(f"原始{len(pdf_pages)}页文档分割成{len(docs)}个块")
# 分割纯文本
text = "很长的技术文档内容..."
chunks = text_splitter.split_text(text)
2. 基于代码的分割器
from langchain.text_splitter import (
PythonCodeTextSplitter,
JavaScriptTextSplitter,
MarkdownHeaderTextSplitter
)
# Python代码分割
python_splitter = PythonCodeTextSplitter(chunk_size=2000)
python_chunks = python_splitter.split_text(python_code)
# Markdown按标题分割
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
)
md_chunks = markdown_splitter.split_text(markdown_text)
向量存储:高效相似度搜索
from langchain_community.vectorstores import Chroma, FAISS
from langchain_community.embeddings import DashScopeEmbeddings
# 初始化嵌入模型
embeddings = DashScopeEmbeddings(
dashscope_api_key=os.getenv('api_key'),
model='text-embedding-v3'
)
# 方式1:使用Chroma(适合开发和中小型应用)
vectorstore = Chroma.from_documents(
documents=docs,
embedding=embeddings,
persist_directory="./chroma_db" # 持久化存储
)
# 方式2:使用FAISS(适合大规模应用)
faiss_store = FAISS.from_documents(docs, embeddings)
faiss_store.save_local("./faiss_index")
# 相似度搜索
query = "如何优化深度学习模型的性能?"
similar_docs = vectorstore.similarity_search(query, k=3)
for i, doc in enumerate(similar_docs):
print(f"相关文档 {i+1}: {doc.page_content[:100]}...")
检索器:智能信息检索
检索器是连接向量存储和应用的桥梁,提供了多种检索策略:
1. 基本检索器
# 从向量存储创建检索器
retriever = vectorstore.as_retriever(
search_type="similarity", # 搜索类型
search_kwargs={"k": 3} # 返回前3个相关文档
)
# 检索相关文档
docs = retriever.get_relevant_documents("什么是LangChain?")
2. 多向量检索器
from langchain.retrievers import MultiVectorRetriever
from langchain.storage import InMemoryStore
# 创建多向量检索器(支持文档摘要检索)
store = InMemoryStore()
id_key = "doc_id"
multi_retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
# 可以存储文档的多种表示(原文、摘要、关键词等)
3. 自查询检索器
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
# 定义元数据信息
metadata_field_info = [
AttributeInfo(
name="source",
description="文档来源",
type="string",
),
AttributeInfo(
name="page",
description="页码",
type="integer",
),
]
# 创建自查询检索器
document_content_description = "技术文档和教程"
self_query_retriever = SelfQueryRetriever.from_llm(
llm=model,
vectorstore=vectorstore,
document_contents=document_content_description,
metadata_field_info=metadata_field_info,
)
# 支持自然语言查询
docs = self_query_retriever.get_relevant_documents(
"找一些关于Spring Boot的第一页内容"
)
完整的RAG检索链
将所有组件组合成完整的检索链:
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# 定义提示模板
template = """
基于以下上下文信息回答问题。如果上下文中没有相关信息,请说"我不知道"。
上下文:{context}
问题:{question}
回答:
"""
prompt = PromptTemplate(
template=template,
input_variables=["context", "question"]
)
# 创建检索QA链
qa_chain = RetrievalQA.from_chain_type(
llm=model,
chain_type="stuff",
retriever=retriever,
chain_type_kwargs={"prompt": prompt},
return_source_documents=True
)
# 使用检索链回答问题
result = qa_chain.invoke({"query": "LangChain的主要组件有哪些?"})
print("答案:", result["result"])
print("来源:", result["source_documents"][0].metadata)
这样,我们就用LangChain轻松实现了之前手写的RAG系统功能,而且代码更简洁、更稳定、功能更强大。
Chain链:让AI组件协同工作
Chain(链)是LangChain最核心的概念之一,它让我们可以将多个AI组件串联起来,形成强大的处理流水线。就像工厂的生产线一样,每个环节处理特定的任务,最终产出完整的产品。
还记得我们之前展示的这个例子吗:
# 传统方式:步骤分散,容易出错
prompt_result = prompt.format_prompt(input="LangChain是什么?")
model_result = model.invoke(prompt_result.to_messages())
final_result = xml_parser.parse(model_result.content)
# LangChain方式:链式组合,优雅简洁
chain = prompt | model | xml_parser
result = chain.invoke({"input": "LangChain是什么?"})
使用管道操作符|,我们将提示模板、语言模型和输出解析器串联起来,形成了一个完整的处理链。
Runnable接口:万物皆可链接
LangChain 0.2版本引入了Runnable接口,这是一个统一的抽象层,让所有组件都可以参与链式组合。
Runnable的核心方法:
# 所有组件都实现这些方法
result = component.invoke(input) # 同步调用
result = await component.ainvoke(input) # 异步调用
results = component.batch([input1, input2]) # 批量处理
for chunk in component.stream(input): # 流式处理
print(chunk)
链式调用的实现原理:
class Runnable:
def __or__(self, other):
"""重载 | 操作符,实现链式组合"""
return Chain([self, other])
def invoke(self, input):
"""执行组件逻辑"""
pass
常用Chain类型
1. 基础顺序链
最简单的链,按顺序执行组件:
from langchain.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import StrOutputParser
# 构建翻译链
translate_prompt = ChatPromptTemplate.from_template(
"将以下{source_lang}文本翻译成{target_lang}:\n\n{text}"
)
model = ChatOpenAI(model="qwen-plus")
output_parser = StrOutputParser()
# 组合成链
translate_chain = translate_prompt | model | output_parser
# 使用链
result = translate_chain.invoke({
"source_lang": "英文",
"target_lang": "中文",
"text": "LangChain is a powerful framework for AI applications."
})
print(result)
2. 分支链(并行处理)
同时执行多个处理分支:
from langchain.schema.runnable import RunnableParallel
# 定义多个分析链
sentiment_prompt = ChatPromptTemplate.from_template("分析这段文本的情感倾向:{text}")
summary_prompt = ChatPromptTemplate.from_template("总结这段文本的要点:{text}")
keywords_prompt = ChatPromptTemplate.from_template("提取这段文本的关键词:{text}")
sentiment_chain = sentiment_prompt | model | StrOutputParser()
summary_chain = summary_prompt | model | StrOutputParser()
keywords_chain = keywords_prompt | model | StrOutputParser()
# 并行执行多个分析
analysis_chain = RunnableParallel({
"sentiment": sentiment_chain,
"summary": summary_chain,
"keywords": keywords_chain
})
result = analysis_chain.invoke({
"text": "今天学习LangChain框架,感觉非常强大和实用,特别是链式组合的设计理念。"
})
print("情感分析:", result["sentiment"])
print("内容总结:", result["summary"])
print("关键词:", result["keywords"])
3. 条件链(动态路由)
根据输入条件选择不同的处理路径:
from langchain.schema.runnable import RunnableBranch
def route_question(input_dict):
"""根据问题类型路由到不同处理链"""
question = input_dict["question"].lower()
if "代码" in question or "编程" in question:
return "code"
elif "理论" in question or "概念" in question:
return "theory"
else:
return "general"
# 定义不同类型的处理链
code_prompt = ChatPromptTemplate.from_template(
"你是一个编程专家,请提供代码示例回答:{question}"
)
theory_prompt = ChatPromptTemplate.from_template(
"你是一个理论专家,请从概念角度详细解释:{question}"
)
general_prompt = ChatPromptTemplate.from_template(
"请简洁明了地回答:{question}"
)
code_chain = code_prompt | model | StrOutputParser()
theory_chain = theory_prompt | model | StrOutputParser()
general_chain = general_prompt | model | StrOutputParser()
# 创建条件分支链
conditional_chain = RunnableBranch(
(lambda x: route_question(x) == "code", code_chain),
(lambda x: route_question(x) == "theory", theory_chain),
general_chain # 默认分支
)
# 测试不同类型的问题
questions = [
"如何用Python实现快速排序算法?",
"什么是微服务架构的理论基础?",
"今天天气怎么样?"
]
for q in questions:
result = conditional_chain.invoke({"question": q})
print(f"问题: {q}")
print(f"回答: {result[:100]}...")
print("-" * 50)
4. 记忆链(状态保持)
保持对话历史和上下文:
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain
# 创建带记忆的对话链
memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=model,
memory=memory,
prompt=ChatPromptTemplate.from_template(
"以下是人类和AI助手的对话历史:\n{history}\n\n人类:{input}\nAI助手:"
)
)
# 多轮对话
print("AI:", conversation.predict(input="我想学习Python编程"))
print("AI:", conversation.predict(input="从哪里开始比较好?"))
print("AI:", conversation.predict(input="我之前提到想学什么来着?"))
自定义Chain组件
当现有组件不满足需求时,可以自定义:
from langchain.schema.runnable import Runnable
import asyncio
class CodeAnalyzer(Runnable):
"""自定义代码分析组件"""
def invoke(self, input_dict):
code = input_dict["code"]
language = input_dict.get("language", "python")
# 简单的代码分析逻辑
lines = len(code.split('\n'))
functions = code.count('def ')
classes = code.count('class ')
return {
"lines": lines,
"functions": functions,
"classes": classes,
"language": language,
"complexity": "简单" if lines < 50 else "复杂"
}
# 创建代码分析链
code_analyzer = CodeAnalyzer()
analysis_prompt = ChatPromptTemplate.from_template(
"""
基于以下代码分析结果,提供改进建议:
代码统计:
- 行数:{lines}
- 函数数:{functions}
- 类数:{classes}
- 复杂度:{complexity}
请提供具体的优化建议。
"""
)
# 组合分析链
code_review_chain = code_analyzer | analysis_prompt | model | StrOutputParser()
# 使用自定义链
python_code = """
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
class Calculator:
def add(self, a, b):
return a + b
"""
suggestion = code_review_chain.invoke({
"code": python_code,
"language": "python"
})
print("优化建议:", suggestion)
链的调试和监控
LangChain提供了丰富的调试工具:
# 启用详细日志
import langchain
langchain.debug = True
# 使用回调函数监控执行过程
from langchain.callbacks import StdOutCallbackHandler
callback = StdOutCallbackHandler()
result = chain.invoke({"input": "测试"}, config={"callbacks": [callback]})
# 查看链的执行图
print(chain.get_graph().print_ascii())
Chain的设计让复杂的AI应用开发变得模块化和可维护,你可以像搭积木一样组合不同的功能,创造出强大的AI应用。
Agent代理:赋予AI自主决策能力
如果说Chain是预定义的流水线,那么Agent就是具备自主决策能力的智能助手。Agent可以根据用户的问题自动选择合适的工具,制定执行计划,并动态调整策略。
Chain的限制:
# 链的执行流程是固定的
chain = prompt | model | parser
# 总是按照这个顺序执行,无法动态调整
Agent的优势:
# Agent可以根据需要动态选择工具
agent = Agent(tools=[search_tool, calculator_tool, code_tool])
# 根据问题类型自动选择合适的工具组合
Agent类型详解
1. ReAct Agent(推荐)
最常用和最强大的Agent类型,支持推理和行动的循环:
from langchain.agents import create_react_agent, AgentExecutor
from langchain.tools import Tool
from langchain.prompts import PromptTemplate
import requests
# 定义工具
def search_web(query: str) -> str:
"""搜索网络信息"""
# 这里使用模拟搜索,实际项目中可以接入真实搜索API
return f"搜索'{query}'的结果:相关信息已找到"
def calculate(expression: str) -> str:
"""计算数学表达式"""
try:
result = eval(expression)
return f"计算结果:{result}"
except:
return "计算出错,请检查表达式"
def get_weather(city: str) -> str:
"""获取天气信息"""
# 模拟天气API
return f"{city}今天天气晴朗,气温25°C"
# 创建工具列表
tools = [
Tool(
name="Search",
func=search_web,
description="用于搜索网络信息,输入搜索关键词"
),
Tool(
name="Calculator",
func=calculate,
description="用于数学计算,输入数学表达式"
),
Tool(
name="Weather",
func=get_weather,
description="获取城市天气信息,输入城市名称"
)
]
# 创建ReAct Agent
react_prompt = PromptTemplate.from_template("""
你是一个智能助手,可以使用以下工具来回答问题:
{tools}
使用以下格式:
问题:输入的问题
思考:我需要如何解决这个问题
行动:使用的工具
行动输入:工具的输入参数
观察:工具的输出结果
... (重复思考/行动/观察的循环)
思考:我现在知道最终答案了
最终答案:对原始问题的回答
开始!
问题:{input}
思考:{agent_scratchpad}
""")
agent = create_react_agent(
llm=model,
tools=tools,
prompt=react_prompt
)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 显示推理过程
max_iterations=5 # 最大迭代次数
)
# 测试复杂问题
result = agent_executor.invoke({
"input": "北京今天天气如何?另外帮我计算一下25*4+18的结果"
})
print("最终答案:", result["output"])
2. OpenAI Functions Agent
专门为支持函数调用的模型设计:
from langchain.agents import create_openai_functions_agent
from langchain.tools import tool
# 使用装饰器定义工具
@tool
def get_stock_price(symbol: str) -> str:
"""获取股票价格信息"""
# 模拟股票API
prices = {"AAPL": 150.25, "GOOGL": 2800.50, "MSFT": 300.75}
return f"{symbol}当前价格:${prices.get(symbol, 'N/A')}"
@tool
def analyze_sentiment(text: str) -> str:
"""分析文本情感倾向"""
positive_words = ["好", "棒", "优秀", "喜欢"]
negative_words = ["差", "糟糕", "失望", "讨厌"]
pos_count = sum(1 for word in positive_words if word in text)
neg_count = sum(1 for word in negative_words if word in text)
if pos_count > neg_count:
return "积极情感"
elif neg_count > pos_count:
return "消极情感"
else:
return "中性情感"
tools = [get_stock_price, analyze_sentiment]
# 创建Functions Agent
functions_agent = create_openai_functions_agent(
llm=model,
tools=tools,
prompt=ChatPromptTemplate.from_messages([
("system", "你是一个专业的投资分析师"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")
])
)
functions_executor = AgentExecutor(
agent=functions_agent,
tools=tools,
verbose=True
)
# 测试
result = functions_executor.invoke({
"input": "帮我查看AAPL的股价,并分析一下'这支股票表现很棒'这句话的情感"
})
3. 自定义Agent
创建具有特定逻辑的Agent:
from langchain.agents import BaseSingleActionAgent
from langchain.schema import AgentAction, AgentFinish
class CustomCodeAgent(BaseSingleActionAgent):
"""专门处理编程问题的自定义Agent"""
def __init__(self, tools, llm):
self.tools = tools
self.llm = llm
def plan(self, intermediate_steps, **kwargs):
user_input = kwargs["input"]
# 简单的问题分类逻辑
if "计算" in user_input or "数学" in user_input:
return AgentAction(
tool="Calculator",
tool_input=user_input,
log="用户需要数学计算"
)
elif "搜索" in user_input or "查找" in user_input:
return AgentAction(
tool="Search",
tool_input=user_input,
log="用户需要搜索信息"
)
else:
return AgentFinish(
return_values={"output": "我可以帮您进行计算或搜索"},
log="没有找到合适的工具"
)
@property
def input_keys(self):
return ["input"]
# 使用自定义Agent
custom_agent = CustomCodeAgent(tools=tools, llm=model)
custom_executor = AgentExecutor(agent=custom_agent, tools=tools)
Tools工具:Agent的能力扩展
Tools是Agent的"手脚",让AI能够与外部世界交互:
1. 内置工具
from langchain.tools import (
DuckDuckGoSearchRun,
ShellTool,
PythonREPLTool
)
# 搜索工具
search_tool = DuckDuckGoSearchRun()
# Python执行工具
python_tool = PythonREPLTool()
# Shell命令工具(需谨慎使用)
shell_tool = ShellTool()
tools = [search_tool, python_tool]
2. 自定义工具
from langchain.tools import BaseTool
from typing import Optional
class DatabaseQueryTool(BaseTool):
"""数据库查询工具"""
name = "database_query"
description = "执行SQL查询并返回结果"
def _run(self, query: str) -> str:
# 这里连接实际数据库
# 为了安全,实际应用中需要SQL注入防护
try:
# 模拟数据库查询
if "SELECT" in query.upper():
return "查询成功:返回了5条记录"
else:
return "只支持SELECT查询"
except Exception as e:
return f"查询错误:{str(e)}"
async def _arun(self, query: str) -> str:
"""异步版本"""
return self._run(query)
# 创建工具实例
db_tool = DatabaseQueryTool()
也可以使用 @tool 注解来快速将一个方法变成工具。
Agent的实际应用
数据分析助手
@tool
def load_csv_data(file_path: str) -> str:
"""加载CSV数据文件"""
import pandas as pd
try:
df = pd.read_csv(file_path)
return f"成功加载数据,共{len(df)}行{len(df.columns)}列"
except Exception as e:
return f"加载失败:{str(e)}"
@tool
def analyze_data(analysis_type: str) -> str:
"""分析数据"""
analyses = {
"统计": "数据统计分析:平均值、中位数、标准差等",
"可视化": "生成数据可视化图表:柱状图、折线图等",
"相关性": "分析变量间相关性:相关系数矩阵"
}
return analyses.get(analysis_type, "不支持的分析类型")
# 创建数据分析Agent
data_tools = [load_csv_data, analyze_data]
data_agent = create_react_agent(model, data_tools, react_prompt)
data_executor = AgentExecutor(agent=data_agent, tools=data_tools)
# 使用
result = data_executor.invoke({
"input": "请帮我加载sales.csv文件并进行统计分析"
})
Memory记忆系统:让Agent记住历史
对话记忆
from langchain.memory import ConversationBufferWindowMemory
# 创建带记忆的Agent
memory = ConversationBufferWindowMemory(
memory_key="chat_history",
k=5, # 保留最近5轮对话
return_messages=True
)
agent_with_memory = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True
)
# 多轮对话测试
print(agent_with_memory.invoke({"input": "我想学Python"}))
print(agent_with_memory.invoke({"input": "刚才我说想学什么?"}))
Agent代理的出现让AI应用从简单的问答工具进化为真正的智能助手,能够自主规划、使用工具、解决复杂问题。这是LangChain最激动人心的功能之一。
LangChain的出现标志着AI应用开发正在从"手工时代"进入"工业化时代"。就像Spring Boot让Java开发变得简单一样,LangChain让AI应用开发变得触手可及。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)