RAG技术全面解析:构建商业级AI知识库问答的技术案例
RAG(检索增强生成)技术解析:解决大模型幻觉与知识时效性问题的企业级方案。该技术通过将知识与推理解耦,为LLM提供动态知识库支持,有效降低错误率至2%以下,显著提升专业领域准确率(如医疗诊断从31%提升至89%)。文章详解RAG四大工作流程(查询理解、知识检索、上下文构建、增强生成)及技术栈(向量数据库、Embedding模型等),结合金融合规等案例展示其85%效率提升效果,并给出混合检索、查询
RAG技术全面解析:构建商业级AI知识库问答的技术案例
在过去几年里,大语言模型(LLM)发展迅猛,但一个普遍的痛点依旧没有解决:幻觉(hallucination)与过时知识。企业在落地AI应用时,这个问题尤为突出。RAG(Retrieval-Augmented Generation,检索增强生成)技术正是为了解决这一痛点而生。本文将结合实际案例,从原理到实现、从基础到优化,带你全面解析RAG如何成为企业级AI应用的核心架构。
一、RAG是什么:不只是“检索+生成”
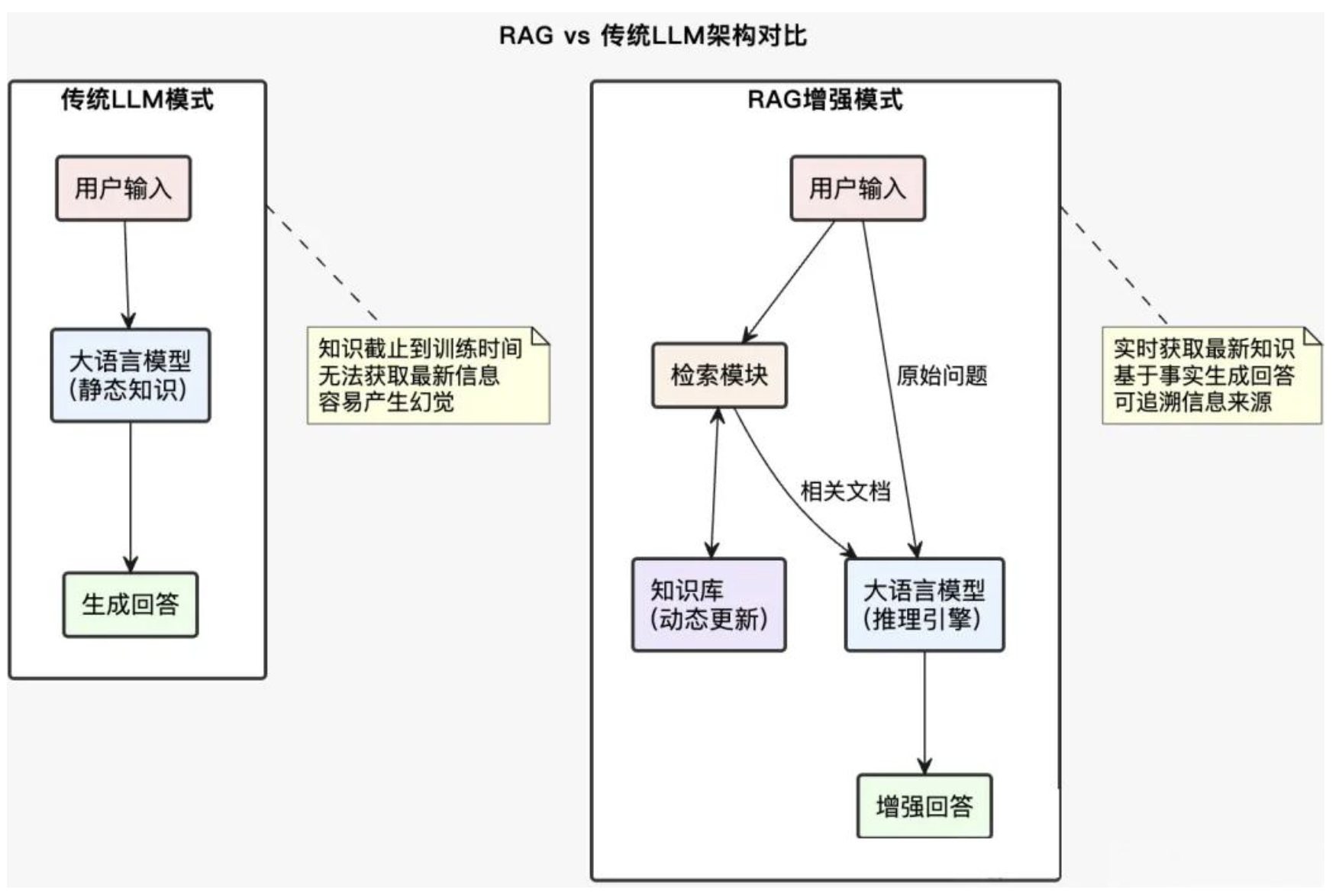
很多人对RAG的理解还停留在“先检索,后生成”,其实这种看法已经过时。RAG真正的本质是:知识与推理的解耦,让大模型具备动态更新知识的能力。
传统大模型就像一个博学的学者,但知识全都存储在大脑里,一旦训练完毕就无法更新。而RAG相当于给学者配备了一个随身图书馆,每次回答问题前都能快速查阅最新资料。这样,模型不再依赖“记忆模糊”,而是能“有理有据”。
实际案例
某金融科技公司在构建合规咨询助手时遇到难题:法规经常更新,纯大模型不仅回答过时,还可能“编造”不存在的法规条款。切换到RAG后,系统具备了以下能力:
-
实时同步最新法规
-
精准定位相关条款
-
给出出处,避免幻觉
-
结合企业业务场景做个性化推理
上线后,该助手的咨询效率提升了85%,合规风险降低92%。
二、为什么大多数企业选择RAG
1. 解决大模型的软肋
-
幻觉问题:即使是GPT-5,在没有上下文时仍有15%~20%的错误率。RAG通过检索外部知识,将错误率降低至2%以下。
-
知识时效性:大模型知识固定在训练时点,而RAG可以实时更新。我们公司用RAG同步新车、二手车信息,减少了80%的客服和业务人员的回复。
-
领域专业性:朋友公司做医学实验发现,纯大模型对罕见病诊断的准确率只有31%,但结合专业文献的RAG能提升到89%。
-
可解释性:给用户展示可追溯答案来源,RAG天然支持“答案+引用”。
2. 成本效益
训练一个72B参数的模型,动辄上几十万元的GPU硬件成本,就算租云服务器也得月过万,且难以频繁更新。相比之下,RAG成本更低,知识库可每天更新,开发迭代周期从6个月缩短到1个月。
3. 数据主权与合规
-
数据不出公司:敏感数据存储在企业私有库中,只传递必要片段。
-
细粒度权限控制:不同员工级别,不同业务模块的员工,看到的知识范围不同。
-
审计追踪:答案可追溯,符合公司审计要求。
-
GDPR合规:删除数据无需重新训练。
4. 灵活与可扩展
-
即插即用:新数据源随时接入
-
多模态支持:文本、图像、代码都能检索,支持图文回答场景
-
增量学习:新增知识不影响旧知识
-
场景迁移:HR问答、IT支持、财务咨询都能共用架构
三、RAG的工作流程
一个查询从输入到输出,在RAG系统中大致经历四个阶段。
1. 查询理解与预处理
用户输入往往模糊,比如“最近的置换补贴政策怎么说”。系统需要识别:
-
“最近”指多久?
-
“政策”指什么?
-
用户要原文还是解释?
技术点:
-
意图识别:what/why/how 三类
-
实体链接:统一“保时捷卡宴”和“保时捷品牌”
-
查询扩展:将“摇号”扩展成“汽车指标”等
-
时间归一化:将“上个月”转为具体时间区间
2. 知识检索
检索不仅是关键词匹配,更是语义计算。
-
向量检索:利用Embedding计算语义相似度
-
关键词检索:BM25等传统算法
-
混合检索:综合两者,效果提升25%~30%
优化技巧:
-
分块策略:300字到600字,20%重叠
-
元数据过滤:按时间、模块筛选
-
查询改写:模糊查询改写成更清晰的表达
3. 上下文构建
检索到的结果并不是简单拼接,而是:
-
相关性排序:Cross-Encoder精排
-
窗口管理:128k上下文需精挑细选
-
去重与合并:避免冗余
-
结构化组织:帮助模型理解
# 上下文构建示例
def build_context(retrieved_docs, query, max_tokens=4000):
"""
构建优化的上下文
"""
# 1. 重排序
reranked_docs = rerank_model.sort(query, retrieved_docs)
# 2. 去重
unique_docs = remove_duplicates(reranked_docs)
# 3. 构建结构化上下文
context = {
"核心信息": extract_key_points(unique_docs[:3]),
"支撑细节": extract_details(unique_docs[3:6]),
"相关背景": extract_background(unique_docs[6:])
}
# 4. 压缩到窗口限制
compressed = compress_to_limit(context, max_tokens)
# 5. 格式化prompt
prompt = f"""
基于以下信息回答用户问题:
【核心信息】
{compressed['核心信息']}
【支撑细节】
{compressed['支撑细节']}
【相关背景】
{compressed['相关背景']}
用户问题:{query}
"""
return prompt4. 增强生成
在生成阶段,核心是通过Prompt工程约束模型:
-
明确指令:只基于提供的信息
-
行为限制:禁止编造
-
格式要求:答案以列表或表格输出
-
引用标注:输出信息来源
四、RAG技术栈全景
1. 向量数据库
负责存储和检索高维向量,常见选择:Faiss、Milvus、Pinecone。
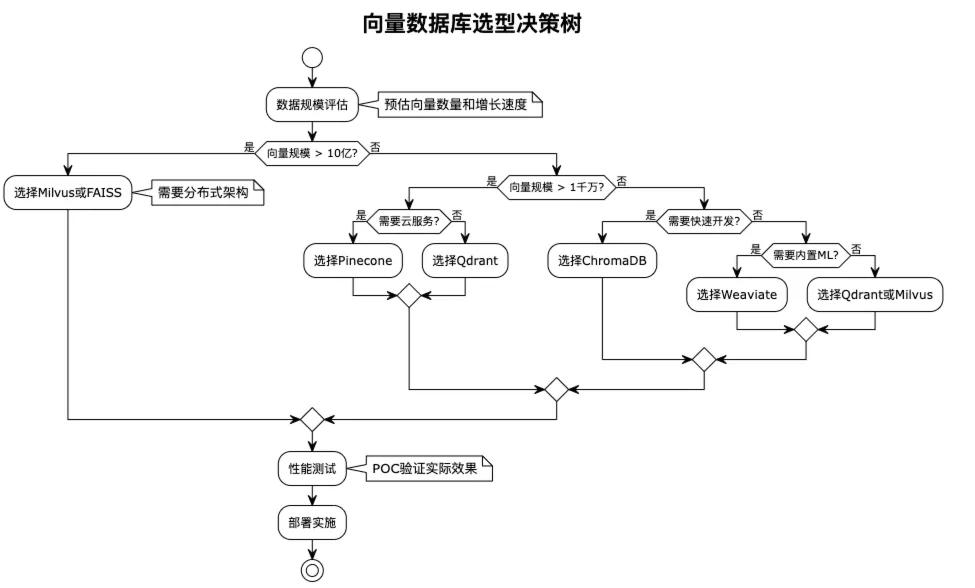
索引算法:
-
HNSW:高精度但占内存
-
IVF:适合大规模场景
-
LSH:适合流式数据
2. Embedding模型
将文本转化为向量的“翻译官”。常见有 OpenAI text-embedding-ada-002 或 BGE-large。优化方式:
-
领域适配:对行业数据做对比学习
-
多粒度:词、句、段混合Embedding
-
负采样优化:区分“苹果手机”和“苹果水果”
3. 知识库构建
知识库的质量决定系统上限。核心是智能分块:
def semantic_chunking(text, max_tokens=512, overlap=50):
"""
基于语义的智能分块
"""
sentences = sent_tokenize(text)
embeddings = model.encode(sentences)
chunks, current_chunk, current_tokens = [], [], 0
for i, sent in enumerate(sentences):
sent_tokens = len(tokenizer.encode(sent))
if i > 0:
similarity = cosine_similarity(embeddings[i-1], embeddings[i])
if similarity < 0.7 or current_tokens + sent_tokens > max_tokens:
chunks.append(' '.join(current_chunk))
current_chunk = [sentences[max(0, i-2):i]] # 保留重叠
current_tokens = sum(len(tokenizer.encode(s)) for s in current_chunk)
current_chunk.append(sent)
current_tokens += sent_tokens
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks质量保障:去重机制、版本控制、增量更新。
4. 系统评估与优化
指标体系:准确率、延迟、用户满意度。常用方法:A/B测试。
class RAGExperiment:
def __init__(self):
self.control_config = {"embedding_model": "ada-002", "chunk_size": 512, "top_k": 5}
self.treatment_config = {"embedding_model": "bge-large", "chunk_size": 768, "top_k": 8}
def run_experiment(self, queries):
results = {"control": [], "treatment": []}
for query in queries:
group = random.choice(["control", "treatment"])
config = self.control_config if group == "control" else self.treatment_config
response = self.execute_rag(query, config)
metrics = {"latency": response.latency, "relevance": self.evaluate_relevance(response)}
results[group].append(metrics)
return self.analyze_results(results)五、RAG优化进阶
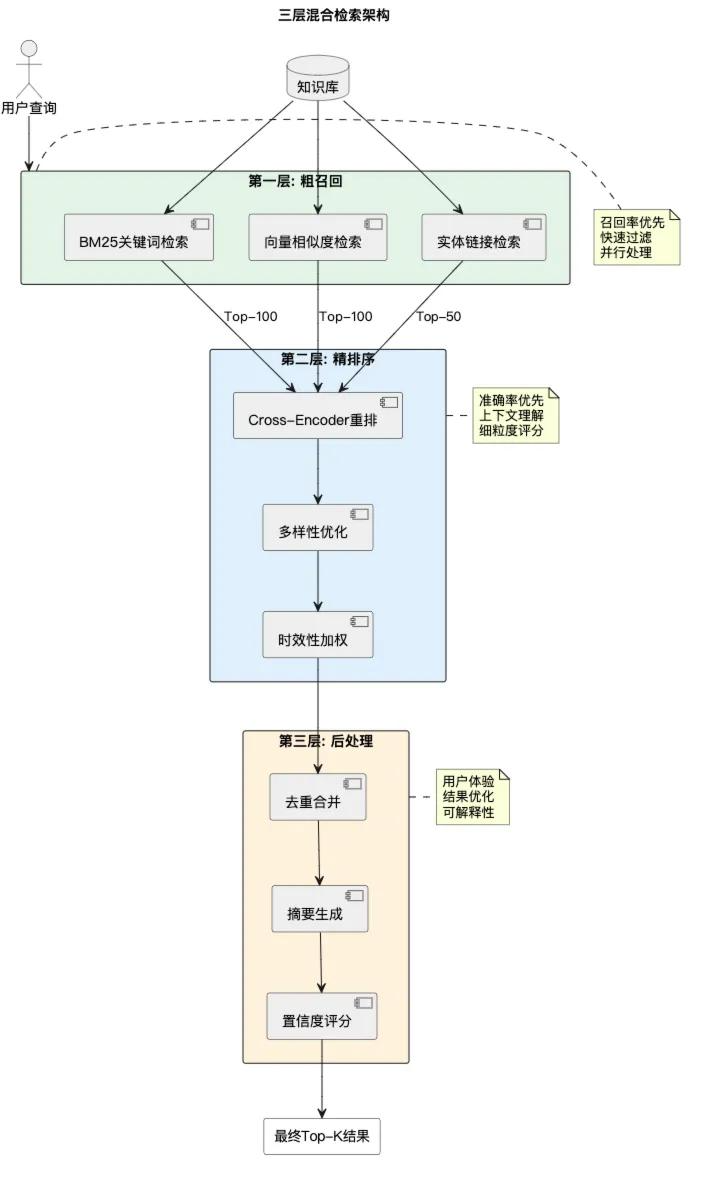
1. 混合检索
结合向量检索和关键词检索,根据查询类型动态调整权重。例如:事实型查询强调关键词,解释型查询强调语义。
2. 查询改写
通过同义词扩展、缩写展开、错别字纠正、中英文转换、LLM生成改写,大幅提升召回率。
3. 动态知识更新
采用蓝绿部署和版本控制,确保知识库可快速更新且可回滚。
4. 性能优化
-
多级缓存
-
批处理与异步IO
-
向量量化(Float32 → Int8,内存减75%)
-
GPU加速(FAISS-GPU可提速10倍)
六、总结
RAG不仅解决了大模型的固有缺陷,更为企业级AI应用提供了一条可行道路。现在落地的从金融、医疗到制造、教育,RAG已经成为落地AI的核心技术。
对企业的建议:
-
从小场景开始试点
-
注重数据治理
-
持续迭代优化
-
把用户体验放在首位

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)