DeepSeek 改用华为芯片训练模型,国产 AI 的真实拐点要来了?
DeepSeek 改用华为芯片训练模型,国产 AI 的真实拐点要来了?
8 月 31 日,科技媒体 The Information 的一篇独家爆料,再次把 DeepSeek 推到了中美 AI “对抗”的聚光灯下。
报道称,DeepSeek 已决定使用华为的昇腾 AI 芯片,训练其部分模型。这意味着这家被寄予厚望的国产 AI 新秀,正在尝试摆脱对英伟达芯片的过度依赖。
这并非空穴来风。
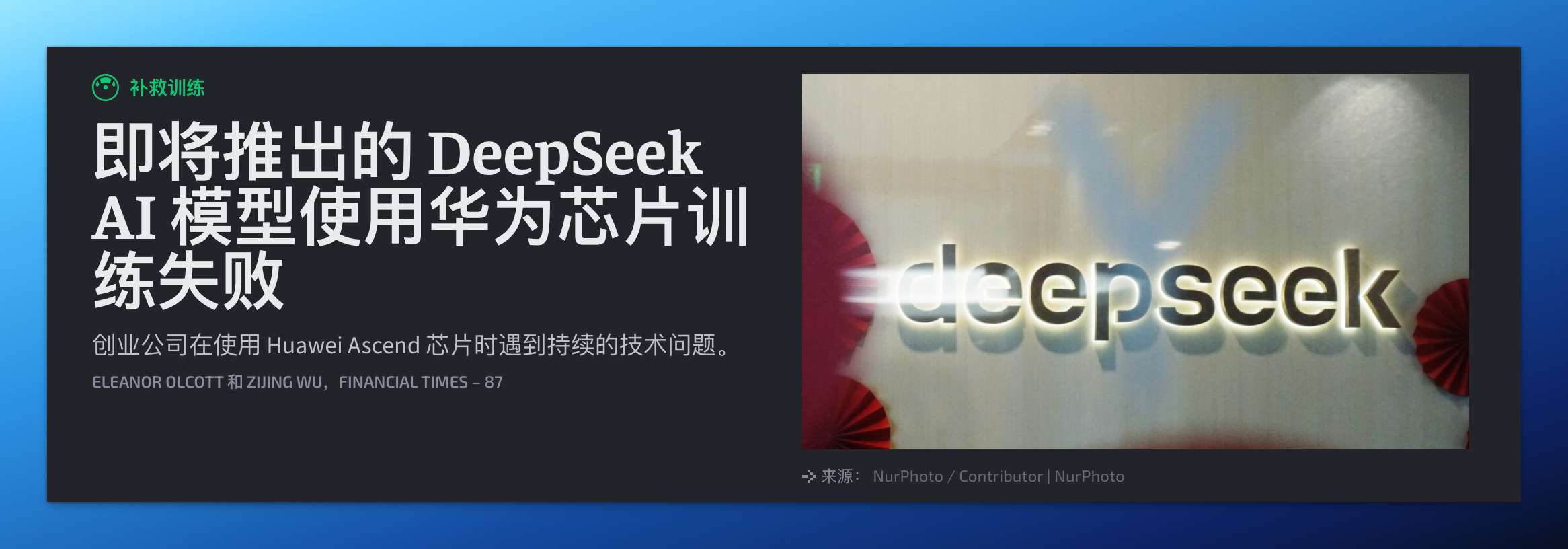
事实上,早在今年 5 月,DeepSeek 就被曝出曾尝试采用华为的昇腾 910C 芯片训练其下一代 R2 模型。但这次“国产替代”尝试并不顺利:模型训练过程中接连遭遇性能不稳定、芯片互联带宽瓶颈、CANN 软件栈兼容性不足等问题,最终导致整个训练计划搁浅,原定于 5 月发布的 R2 模型也被迫延期。
根据《金融时报》、Ars Technica 等媒体的报道,华为甚至派工程师常驻 DeepSeek 办公室协助调优,仍未能成功跑通一次大规模训练。
01|“英伟达训练 + 华为推理”的现实折中
最终,DeepSeek 被迫调整策略,将训练任务继续交由英伟达 H800、H20 等 GPU 完成,而在推理阶段,则尝试引入华为昇腾芯片。
根据公开数据,DeepSeek-R1 模型的训练使用了上万个英伟达 A/H 系列 GPU,而推理环节则率先迁移至华为昇腾 910C。
实测数据显示,该芯片在 FP16 精度下算力可达 320 TFLOPS,在优化手写 CANN 内核后推理性能逼近 Nvidia H100 的 60-80%。

尽管如此,这种“后端切换”依旧无法完全覆盖大模型训练任务对稳定性、生态兼容、跨节点通信等关键能力的需求。
总结来看,推理可以上国产算力,训练还得靠英伟达。
02|为什么 DeepSeek 还要“硬上”?
为什么 DeepSeek 选择“偏向虎山行”?
这是个技术决策,也是一种政治姿态。
在美国持续加强 AI 芯片出口管制的大背景下(2024 年之后 A800/H800/H20 先后被列入出口禁令),我国 AI 厂商已被倒逼出一条“国产化替代”的应激路径。
作为国内大模型浪潮中的明星选手,DeepSeek 在技术上走混合精度(FP8 UE8MO)、算法架构创新(支持非思考模式)等降本路线,在算力供应上也必须有所动作。
而政策层面的信号也非常明确:能用国产的,不要再依赖“别人”。
从这个角度看,哪怕是“试训练失败”,哪怕只是“部分模型”上线,也是一种对政策的回应和表态。正如 CSIS 在分析中指出的:政府希望通过 DeepSeek、阿里、百度等 AI 头部企业带动国产芯片生态的成熟,加速形成自主闭环。
实际上,DeepSeek 的这一选择也早已有迹可循。
就在两周前发布 DeepSeek-V3.1 时,DeepSeek 官方就曾这样高调放话。

03|国产 AI 正在走向“混合现实”
而这也许是未来一段时间国产 AI 产业的常态:
训练靠英伟达,推理上国产芯片;
高级模型继续堆钱堆卡,低功耗小模型交给华为、寒武纪;
主力技术栈还是 CUDA,CANN、Ascend PyTorch 则努力追赶。
DeepSeek 的这次“策略试探”,既不意味着它彻底放弃英伟达,也不意味着华为已能全面接管核心任务。它意味着国产 AI 芯片,正在从边缘任务中逐步获得实战经验与场景锤炼。
去年国产 AI 还只是“没得选”,今年我们终于开始“尝试用”。
结语
先别急着下判断。
正如《金融时报》等外媒评论所说:“华为昇腾训练失败,并不代表国产芯片无用,而是说明其还未准备好承接大模型训练。”
技术路线的演化从不一蹴而就,DeepSeek 这波操作,也许不是结果,而是过程中的一环。
而下一个决定 DeepSeek 是否全面“拥抱”国产芯片的时刻,或许就留给年底要发布的 R2 正式版了。
我是木易,一个专注 AI 领域的技术产品经理,国内 Top2 本科 + 美国 Top10 CS 硕士。
相信 AI 是普通人的“外挂”,致力于分享 AI 全维度知识。这里有最新的 AI 科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用 AI 为你的未来加速。
精选推荐

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)