基于 Amazon Q Developer+Remote MCP 访问 Amazon Redshift
Amazon Q Developer 结合模型上下文协议(MCP)实现了与 Amazon Redshift 的创新集成,使开发者能够通过自然语言直接查询和分析数据仓库中的信息,比如查询数据仓库中的业务表数据,以及自动生成系统表的 SQL 定位 Amazon Redshift 常见问题。

Amazon Q Developer 是亚马逊云科技推出的一款生成式 AI 助手,加速整个软件开发生命周期的构建,从设计、开发、测试和运维,到执行软件升级。同时,它也是亚马逊云科技上的专家,可在亚马逊云科技管理控制台中帮助您优化云成本和资源、提供架构最佳实践指导、调查运营事件以及诊断和解决网络问题。
Amazon Q Developer 中的 Q Developer CLI 是一个在命令行中运行的智能 AI 助手,它能够执行各种任务,理解你的代码库,并通过自然对话加速开发过程。与传统的命令行工具不同,它能够主动采取行动,生成代码、编辑文件、自动化 Git 工作流程,甚至帮助解决合并冲突。这种代理式(agentic)的体验意味着它不仅仅是一个被动的工具,而是能够与你协同工作的伙伴,通过理解上下文和项目需求来提供智能支持。
Amazon Q Developer CLI 通过集成模型上下文协议(Model Context Protocol,简称 MCP)进一步拓展了其功能边界。通过 MCP,开发者可以扩展 Q Developer CLI 的上下文感知能力,使其能够执行更广泛的任务。
Amazon Redshift 是一种在云端运行的全托管、PB 级数据仓库服务。它为企业提供了强大的数据分析能力,能够处理海量数据并提供快速的查询性能。作为亚马逊云科技数据分析生态系统的核心组件,Amazon Redshift 通过列式存储、并行处理和高效的数据压缩算法,使组织能够以经济实惠的方式从其数据中获取洞察。
📢限时插播:Amazon Q Developer 来帮你做应用啦!
🌟10分钟帮你构建智能番茄钟应用,1小时搞定新功能拓展、测试优化、文档注程和部署
⏩快快点击进入《Agentic Al 帮你做应用 -- 从0到1打造自己的智能番茄钟》实验
免费体验企业级 AI 开发工具的真实效果吧
构建无限,探索启程!
本文将以 Amazon Q Developer CLI 为 Agent,开发 Amazon Redshift 的 MCP Server,实现通过自然语言查询 Amazon Redshift 中的数据。
一、解决方案
本文分两个阶段实现访问 Amazon Redshift 的 MCP Server,第一个阶段使用 STDIO 协议实现 Local MCP Server,第二个阶段使用 Streamable HTTP 实现 Remote MCP Server 。MCP 两种传输协议的区别,可以参考博客《使用 Amazon Lambda 快速部署 Streamable HTTP Github MCP Server》。
1. 前提准备
-
订阅 Amazon Q Developer 服务,并安装 Amazon Q Developer CLI。订阅过程,请参加链接;安装过程请参加链接
-
安装 Amazon Q Developer CLI 的电脑/服务器,准备好 Python 3.12 的环境
-
创建一个 Amazon Redshift 集群,设置允许公网访问并配置安全组,让安装 Amazon Q Developer CLI 的电脑/服务器可以访问 Amazon Redshift,以便测试 Local MCP Server。集群创建过程请参考链接。
2. 集成 Local MCP Server
我们先基于 STDIO 协议,创建 Local MCP Server,具体架构如下图所示。
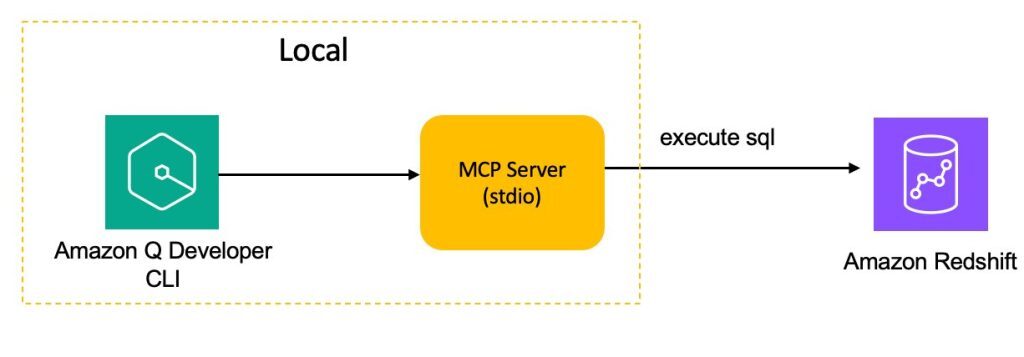
首先,创建 Python 虚拟环境,做好开发 MCP Server 的准备工作。
curl -LsSf https://astral.sh/uv/install.sh | sh
# Create a new directory for your project (you've already done this)
uv init redshift
cd redshift
# Create a Python 3.12 virtual environment
uv venv
# Activate the virtual environment
source .venv/bin/activate
# Install dependencies
uv add mcp fastmcp redshift_connector
# Create our server file
touch redshift.py接下来,准备 Local MCP Server 的 Python 代码 redshift.py,如下所示。
from mcp.server.fastmcp import FastMCP
from mcp.types import TextContent
from mcp.types import Resource, ResourceTemplate, Tool, TextContent
import redshift_connector
import os
mcp = FastMCP(name="redshift", stateless_http=True)
REDSHIFT_CONFIG = {
"host": os.environ['REDSHIFT_HOST'],
"port": int(os.environ['REDSHIFT_PORT']),
"database": os.environ['REDSHIFT_DATABASE'],
"user": os.environ['REDSHIFT_USER'],
"password": os.environ['REDSHIFT_PASSWORD']
}
def _execute_sql(sql:str):
with redshift_connector.connect(**REDSHIFT_CONFIG) as conn:
conn.autocommit = True
with conn.cursor() as cursor:
try:
cursor.execute(sql)
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
result = [",".join(map(str, row)) for row in rows]
return [TextContent(type="text", text="\n".join([",".join(columns)] + result ))]
except Exception as e:
return [TextContent(type="text", text=f"Error executing query: {str(e)}")]
return None
@mcp.tool()
def execute_sql(sql: str) :
"""Execute a SQL Query on the Redshift cluster
Args:
sql: The SQL to Execute
"""
return _execute_sql(sql)
@mcp.tool()
def get_schemas(schema: str) :
"""Get all tables in a schema from redshift database
Args:
schema: the redshift schema
"""
sql = f"""
SELECT table_name FROM information_schema.tables
WHERE table_schema = '{schema}'
GROUP BY table_name
ORDER BY table_name
"""
return _execute_sql(sql)
@mcp.tool()
def get_table_ddl(schema: str, table:str) :
"""Get DDL for a table from redshift database
Args:
schema: the redshift schema name
table: the redshift table name
"""
sql = f"""
show table {schema}.{table}
"""
return _execute_sql(sql)
if __name__ == "__main__":
# Initialize and run the server
mcp.run(transport='stdio')然后在安装了 Amazon Q Developer CLI 的电脑/服务器上,通过 vim .amazonq/mcp.json 编辑 MCP Server 配置:
{
"mcpServers": {
"redshiftserver": {
"timeout": 60,
"command": "uv",
"args": [
"--directory",
"/path/redshift",
"run",
"redshift.py"
],
"env": {
"RS_HOST": "your_redshift_cluster_host",
"RS_DATABASE": "default_is_dev",
"RS_SCHEMA": "default_is_public",
"RS_USER": "your_redshift_user",
"RS_PASSWORD": "your_redshift_password"
},
"transportType": "stdio"
}
}
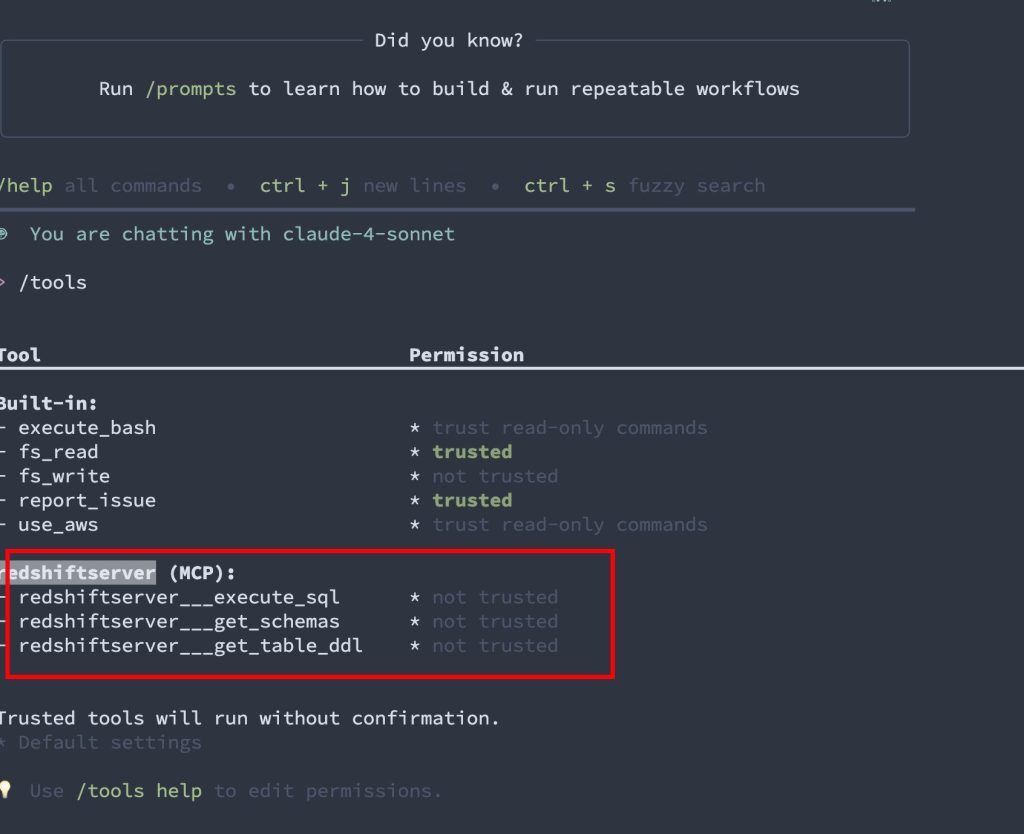
}然后运行 Amazon Q Developer CLI,列出当前的 MCP Tools 。
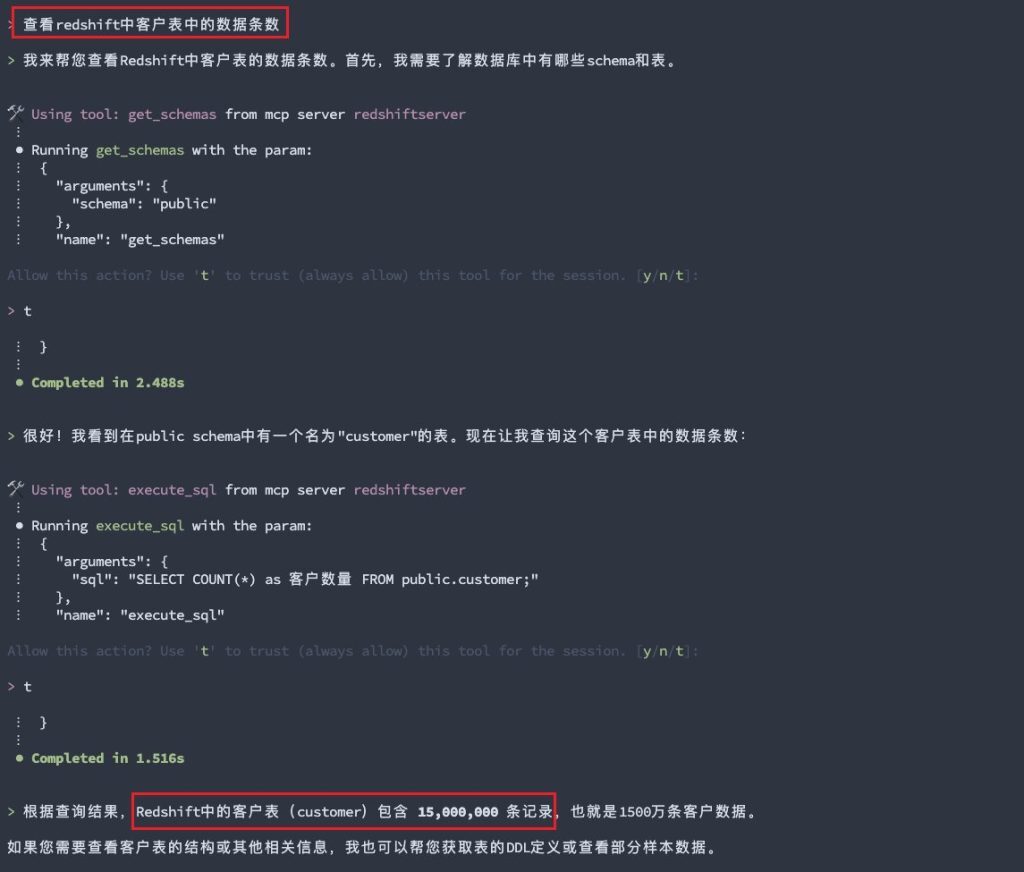
再输入自然语言查询数据:“查看 Redshift 中客户表的数据条数”,Amazon Q Developer CLI 将其转换为 SQL 并执行,最后获取到查询结果。
3. 集成 Remote MCP Server
尽管集成 Local 的 MCP Server,简单直接,但是需要在个人电脑上安装各类依赖、设置 Amazon Redshift 的访问账密,还需要将 Amazon Redshift 开放公网。这种方式,对于数据库类 MCP Server,存在较大的安全隐患。
所以,接下来,我们会基于 Amazon API Gateway 与 Amazon Lambda,使用 Streamable HTTP 协议,开发 Remote MCP Server,整体架构如下图所示。

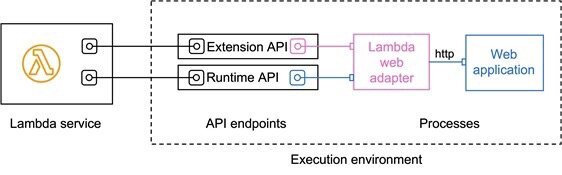
为了能让 Lambda 处理 HTTP 请求,我们需要引入 Lambda Web Adapter,将 Amazon Lambda 接收到的事件转换为 Web Application 的 HTTP 请求,再将 Web Application 的 HTTP 响应转换为 Lambda 的事件响应,如下图所示。
3.1 创建 Amazon Lambda Layer
在开始之前,我们需要为 Amazon Lambda 函数构建 Layer,将相关依赖包放入 Layer 当中。
首先,通过如下脚本构建 zip 包,并上传至 S3 中。
#!/bin/bash
mkdir -p layer_build
cd layer_build
cat > requirements.txt << EOL
fastapi==0.115.12
fastmcp==2.3.0
mcp==1.8.0
pydantic==2.11.4
uvicorn==0.34.2
redshift_connector
EOL
python3.12 -m venv create_layer
source create_layer/bin/activate
pip install -r requirements.txt
mkdir python
cp -r create_layer/lib python/
zip -r layer_content.zip python接下来,创建 Amazon Lambda Layer,如下图所示。
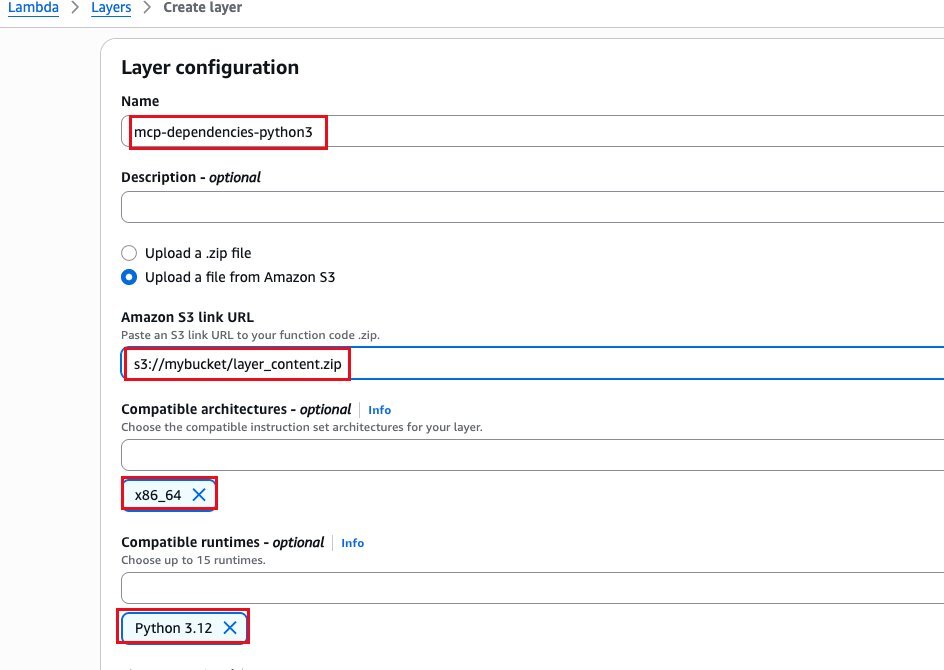
3.2 创建 Amazon Lambda 函数
接下来,我们创建用于部署 MCP Server 的 Amazon Lambda 函数。
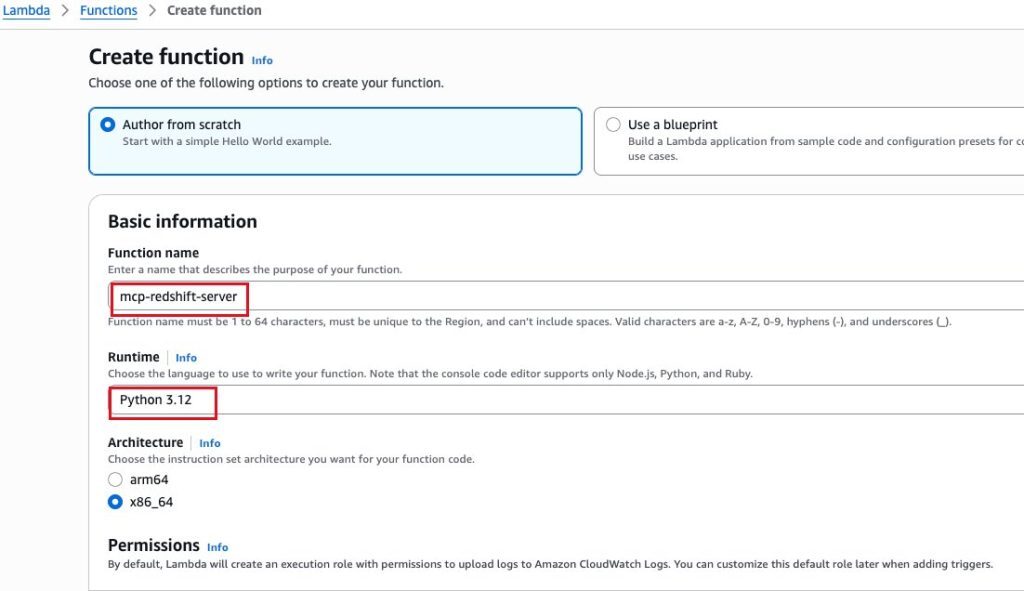
为了让 Amazon Lambda 函数通过内网访问 Amazon Redshift 集群,需要设置 Amazon Lambda 函数的 VPC 、子网和安全组,并配置 Amazon Redshift 集群的安全组入站规则,允许来自 Amazon Lambda 函数安全组的访问。
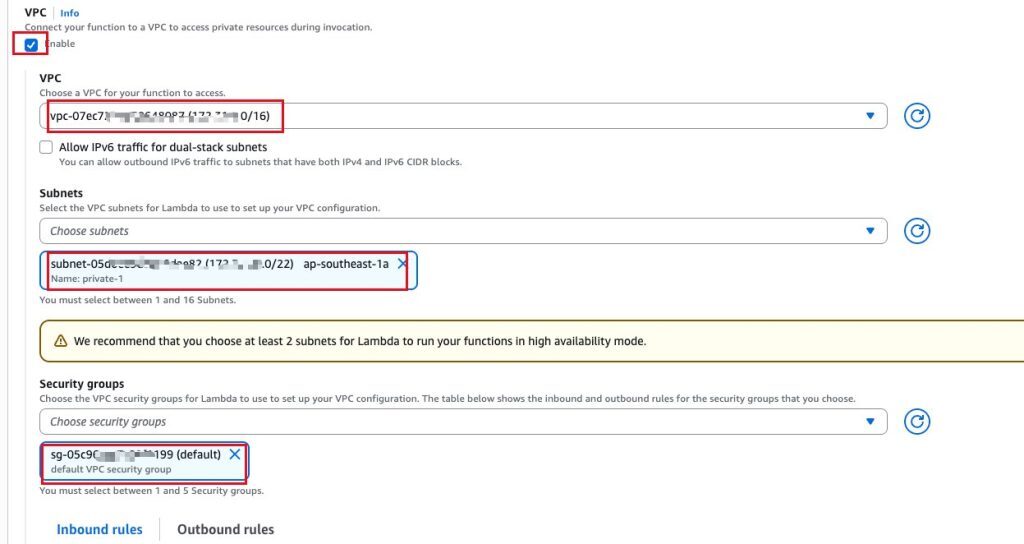
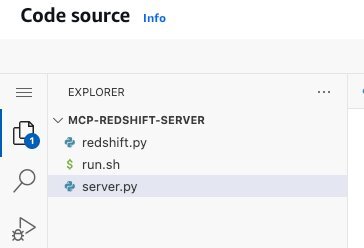
接下来,设置 Amazon Lambda 函数的代码,总共三个代码文件。具体代码,请通过 github 地址获取。
-
redshift.py:Redshift MCP Server 的核心实现,包含数据库连接配置和 SQL 执行工具函数
-
run.sh:Amazon Lambda 函数的启动脚本,配置环境变量并使用 uvicorn 启动 FastAPI 服务
-
server.py:FastAPI 应用入口,创建 Web 服务并挂载 MCP 功能到指定路径
然后,需要完成 Lambda Runtime 的修改以及 Layers 的添加。这里除了添加 mcp-dependencies-python3 以外,还需要通过 ARN 添加“arn:aws:lambda:ap-southeast-1:580247275435:layer:LambdaInsightsExtension:55”、“arn:aws:lambda:ap-southeast-1:753240598075:layer:LambdaAdapterLayerX86:25”。 ARN 中的 region code 需要根据实际情况调整。
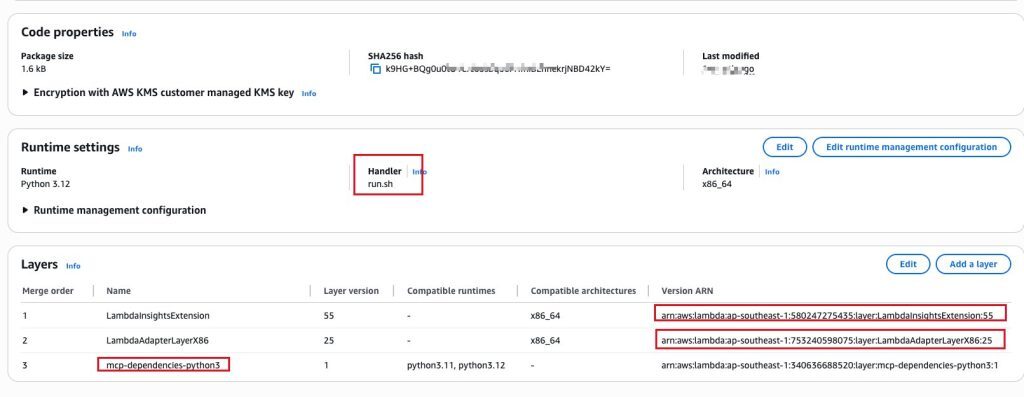
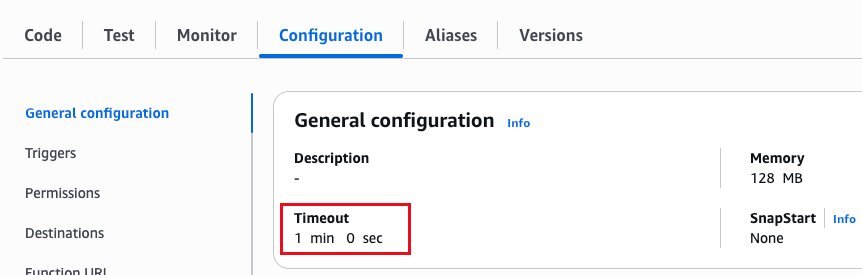
最后是设置超时时间与环境变量,如下图所示。
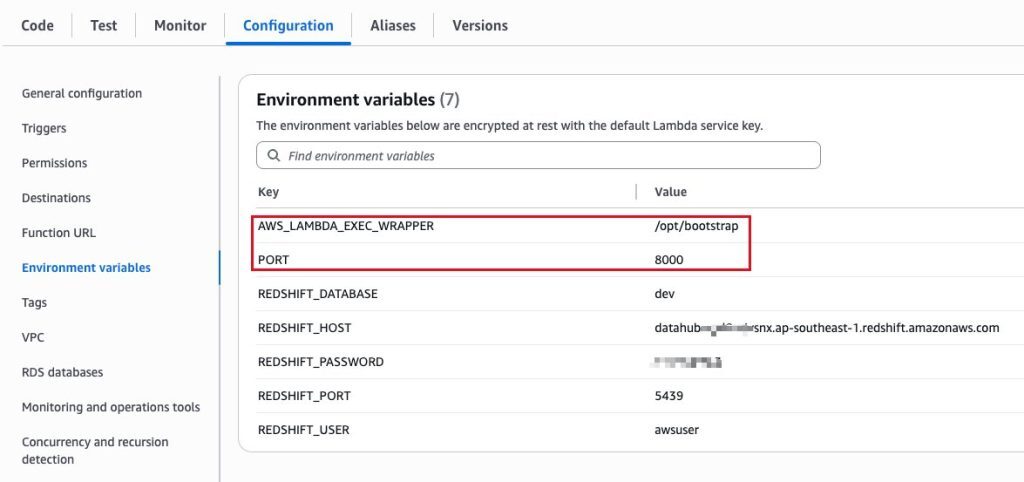
环境变量列表,如下所示:
-
AWS_LAMBDA_EXEC_WRAPPER:指定 Lambda Web Adapter 的启动脚本路径
-
PORT:指定 Web 应用程序应该监听的端口号
-
REDSHIFT_HOST:Redshift 集群的连接地址
-
REDSHIFT_PORT:Redshift 集群的连接端口
-
REDSHIFT_DATABASE:Redshift 集群的数据库名称
-
REDSHIFT_USER:Redshift 集群的用户名
-
REDSHIFT_PASSWORD:Redshift 集群的密码
注:本文仅为简化演示,所以使用环境变量配置 Redshift 集群的用户名与密码。实际生产中,建议使用 Amazon Secrets Manager 来存储 Amazon Redshift 集群的用户名与密码,Amazon Lambda 代码中再从 Amazon Secrets Manager 获取用户名与密码。
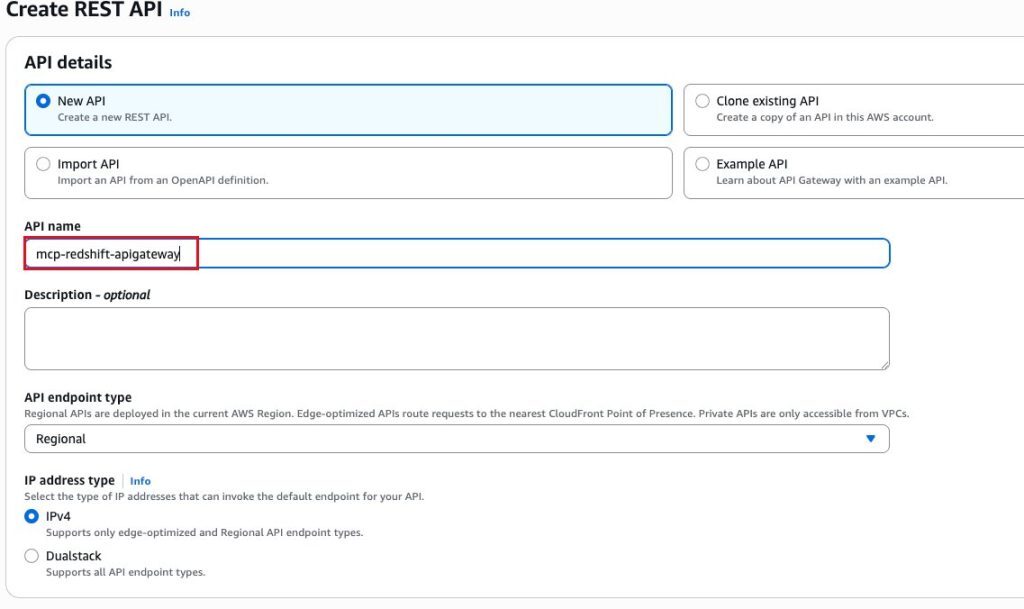
3.3 创建 Amazon API Gateway
在 Amazon API Gateway 中创建一个 Rest API,如下图所示。
创建 /redshift/mcp 下的 Post 方法,并关联 Amazon Lambda 函数,设置 Lambda Proxy Integration 为 True。
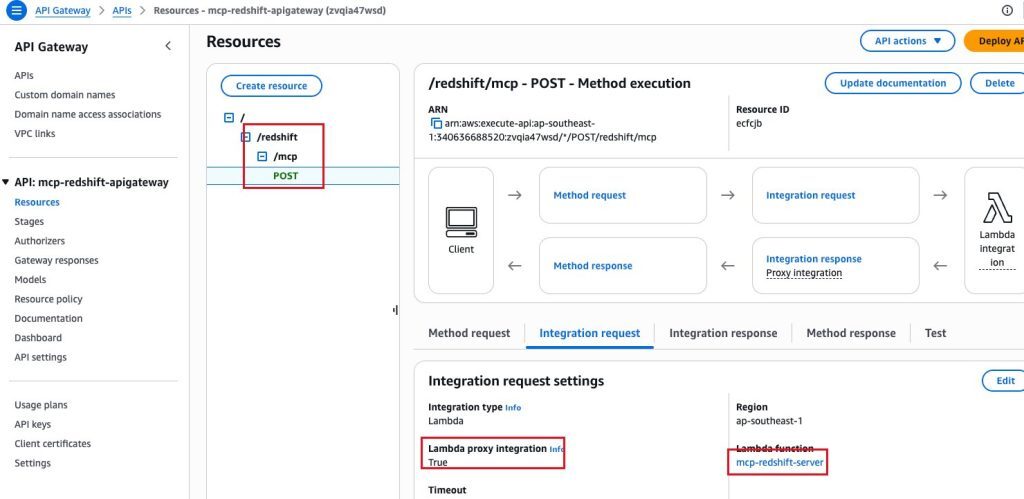
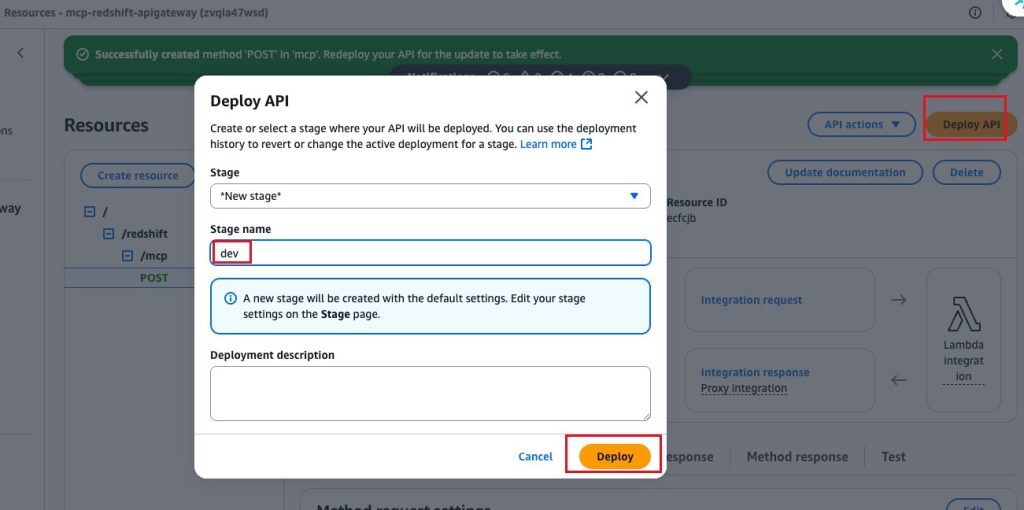
部署 API 至 dev 阶段。
配置 Amazon API Gateway 的认证授权。Amazon API Gateway 支持多种方式的认证授权,这里为演示方便,使用 API Key 来认证。
先创建一个 API Key,如下所示。

再创建一个使用计划(Usage plans),分别关联 API 的阶段(stage)与 API Key,再设置 Post 方法的“需要 API 密钥”为是。
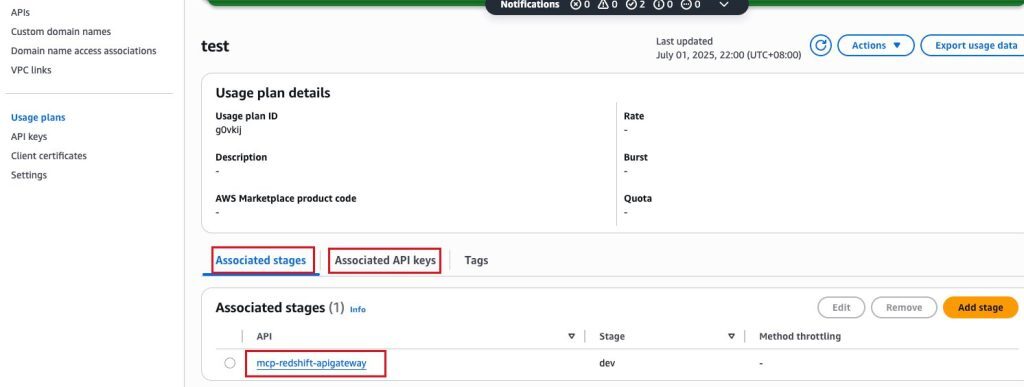
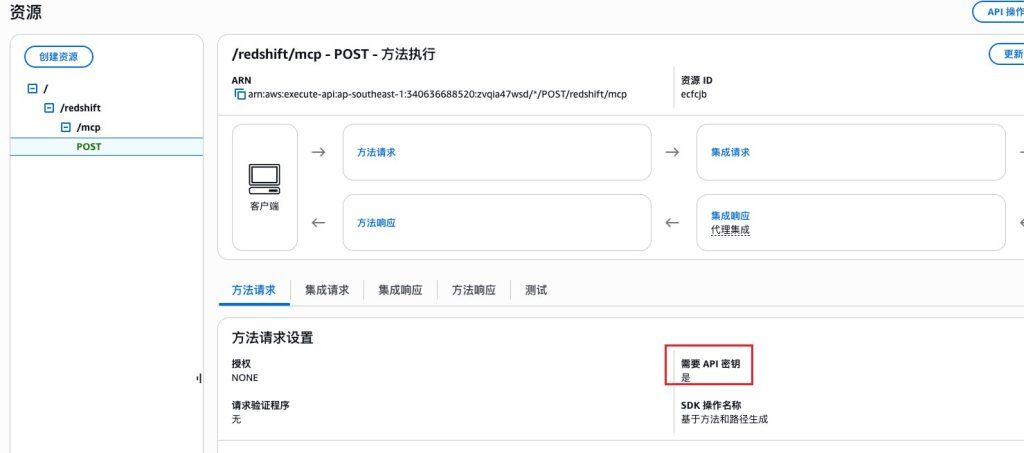
至此,基于 Amazon API Gateway + Amazon Lambda 的 MCP Server 就部署好了。
3.4 使用 Amazon Q Developer CLI 进行测试
配置 .amazonq/mcp.json,如下面的 Json 内容所示。
{
"mcpServers":
{
"redshift-remote-server":
{
"command": "npx",
"args":
[
"mcp-remote",
"https://xxxxx.execute-api.ap-southeast-1.amazonaws.com/dev/redshift/mcp/",
"--header",
"x-api-key: you api key of api gateway"
]
}
}
}输入“q”命令,进入 Amazon Q Developer CLI 页面。通过“/tools” 命令查看集成的 MCP Server 与 MCP Tool 。然后输入提示词:“查询 Redshift 的客户表中订单数据最多的 Top 3 客户信息”,如下面几张截图所示。
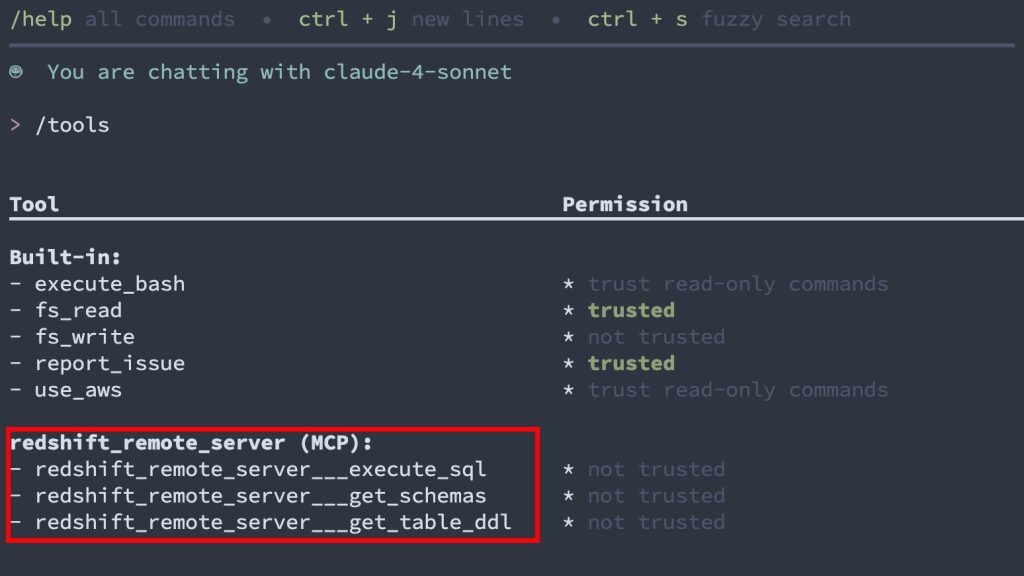
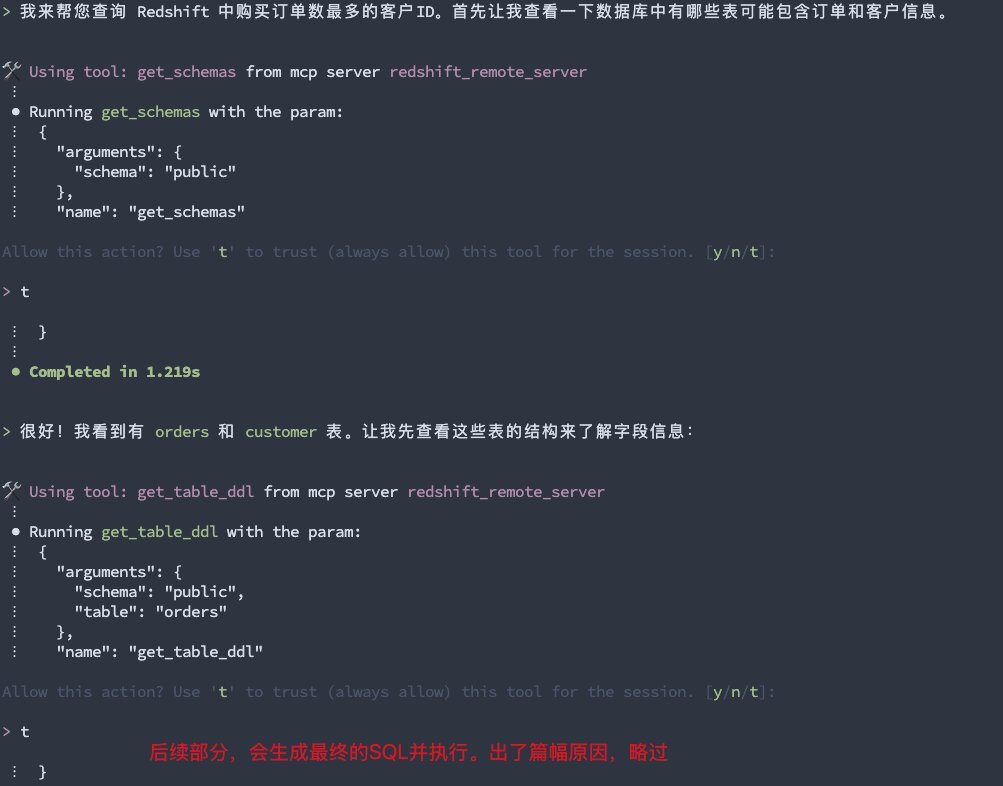

使用 Amazon Q Developer CLI+MCP,除了可以基于 Text2SQL,使用自然语言查询业务表数据,还可以使用自然语言查询系统表,进行常见问题的定位,比如:
-
某张表是否存在数据倾斜
-
当前是否存在死锁
-
针对某次耗时的查询,给出诊断意见和优化建议
-
……
二、总结&综述
Amazon Q Developer 结合模型上下文协议(MCP)实现了与 Amazon Redshift 的创新集成,使开发者能够通过自然语言直接查询和分析数据仓库中的信息,比如查询数据仓库中的业务表数据,以及自动生成系统表的 SQL 定位 Amazon Redshift 常见问题。本文强调了生产环境下使用 Local MCP Server 的一些隐患,提出了基于 Remote MCP Server 的最佳实践,通过 Amazon API Gateway 与 Amazon Lambda 函数的组合,将 MCP Server 部署在云上,让 Amazon Q Developer CLI 通过 Streamable HTTP 调用 MCP Tool。
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
参考文档
本篇作者

本期最新实验为《Agentic AI 帮你做应用 —— 从0到1打造自己的智能番茄钟》
✨ 自然语言玩转命令行,10分钟帮你构建应用,1小时搞定新功能拓展、测试优化、文档注释和部署
💪 免费体验企业级 AI 开发工具,质量+安全全掌控
⏩️[点击进入实验] 即刻开启 AI 开发之旅
构建无限, 探索启程!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)