《从模板初阶到 vector 实战:解锁 C++ 容器的底层逻辑》
这篇文章主要介绍了C++模板编程的概念和应用。首先解释了模板的作用是解决代码复用和泛型编程问题,通过函数模板和类模板实现。函数模板通过隐式实例化自动推导类型参数,类模板则需要显式实例化。文章详细讲解了vector容器的实现,包括迭代器、构造函数、插入删除等操作,重点分析了迭代器失效问题及解决方法。最后指出对于包含动态资源的类型,必须使用深拷贝而非简单的memcpy复制。全文通过具体代码示例展示了模
目录
简单提一下模板
为什么要有模板?解决 代码复用 和 泛型编程
我们看以下三种交换函数,如果没有模板,需要为不同类型的交换函数各写一个版本
void Swap(int& n1, int& n2)
{
int temp = n1;
n1 = n2;
n2 = temp;
}
void Swap(double& n1, double& n2)
{
double temp = n1;
n1 = n2;
n2 = temp;
}
void Swap(char& n1, char& n2)
{
char temp = n1;
n1 = n2;
n2 = temp;
}且,模板允许我们定义泛型容器,像栈,队列等数据结构,逻辑与存储的数据类型无关,可以定义泛型容器,无需为每种类型进行重复设计。
泛型编程的两种实现:函数模板和类模板
函数模板:类似刚刚的swap函数,定义一个通用的函数框架,适配多种数据类型
//函数模板定义
template<typename T>
void Swap(T& n1, T& n2)
T temp = n1;
n1 = n2;
n2 = temp;
}格式
template < typename T1,typename T2... >
返回值类型 函数名 ( 参数列表 ) {}函数模板的原理
模板本身是一个蓝图,只有在被使用时,编译器才会为特定类型创建具体的函数,这个过程叫做函数模板的实例化。
template<typename T>
void Swap(T& n1, T& n2)
{
T temp = n1;
n1 = n2;
n2 = temp;
}
int main()
{
int a = 1, b = 2;
Swap(a, b);
double c = 1.0, d = 2.0;
Swap(c, d);
return 0;
}这个过程是隐式实例化,编译器会根据使用场景自动推导类型参数并进行函数模板实例化。如,a,b是int类型,自动识别T为int,实例出Swap<int>,单独处理int类型的代码
注意以下场景:
template<typename T>
void Add(const T& n1,const T& n2)
{
return n1 + n2;
}
int main()
{
int a = 1;
double b = 2.0;
Add(a, b);
return 0;
}
//在编译器阶段,编译器看到隐式类型实例化,会自动推导T的类型
//a为int,b为double,但只有一个T类型,无法确定是int还是double
因此出现两中解决方法,1.用户强制类型转换Add(a,<int>b)。2.显式实例化Add<int>(a,b),T被直接实例化成int
显式实例化,手动指定参数类型,函数名<模板参数类型>(a,b)
类型不匹配编译器会进行隐式类型转换,无法转换会编译报错
注意:模板和现成函数先走现成函数,因为模板只是蓝图
类模板
,定义一个通用的类框架,只是存储的数据类型不同,比如栈类,能存储int,couble等不同类型
//类模板
template<typename T>
class Stack
{
public:
Stack(size_t capacity = 4)
{
_arr = new T[capacity];
_size = 0;
_capacity = capacity;
}
private:
T* _arr;
size_t _size;
size_t _capacity;
};格式:
template<typename T1,typename T2...>
class 类模板名
{
//成员
}
类模板的使用必须是显式实例化
因为,类模板创建对象时,Stack sk;,编译器无法知道sk存储的是什么类型
必须显示Stack<int> sk;
因此,类模板实例化需要在类模板后跟<>,类模板的名字(Stack)不是真正的类型,加类型(Stack<doubel>)才是。
模板声明和定义不支持分离在两个文件里,会链接错误,后面会讲。
Vector
vector的底层就是可以动态申请资源的顺序表
之前的数据结构实现过相关的顺序表功能,这里的成员变量只不过将_size,_capacity,改成了指针
vector容器存储的数据形式可以不同类型,int,double,因此可以定义一个vector模板
namespace sxm
{
template <typename T>
class vector
{
public:
typedef T* iterator;
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};
}_start:指向数组中首元素,_finish:指向数组中最后一个有效元素+1,_end_of_storage:指向数组空间末尾
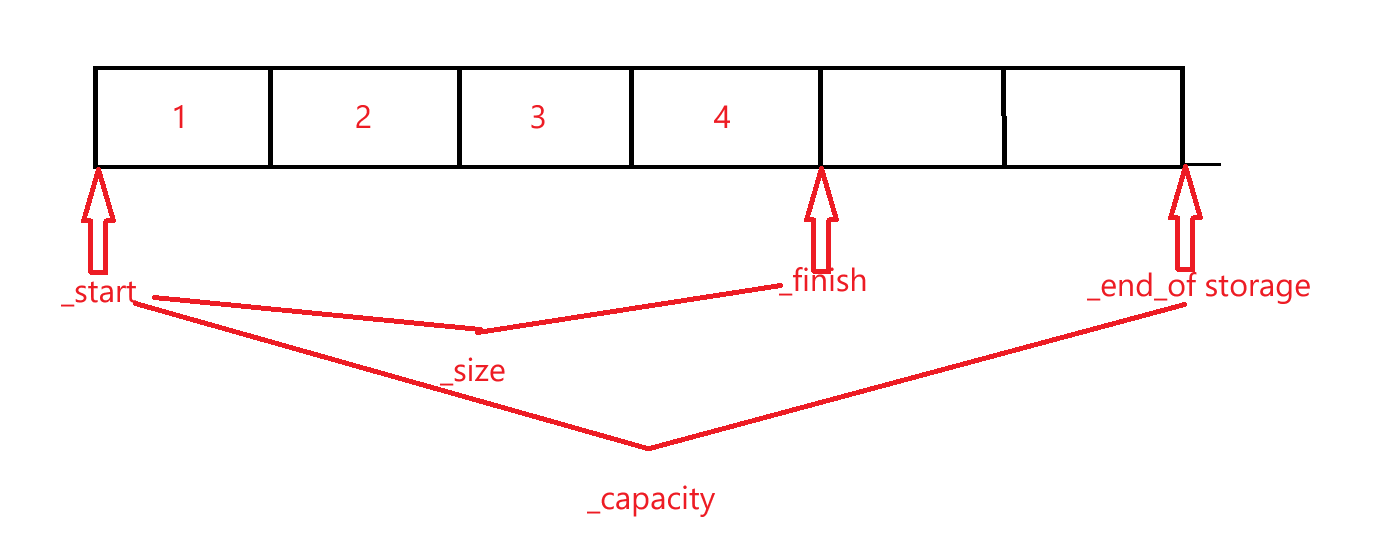
初始化
,直接给类内成员变量一个默认的nullptr
template <typename T>
class vector
{
public:
typedef T* iterator;
private:
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_storage = nullptr;
};析构
~vector<T>()
{
if(_start!=nullptr)
{
delete[] _start;
_start = _finish = _end_of_storage = nullptr;
}
}迭代器
begin直接返回一个迭代器,指向第一个元素
end直接返回 一个past-the-end element 迭代器,不指向任何元素
typedef T* iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}可以修改元素(T*)
vector<int> v = {1, 2, 3};
vector<int>::iterator it = v.begin();
*it = 10; // 合法:可以修改元素const与非const
如果一个vector对象是被const修饰的,返回第一个元素时,不能修改(const T*),那就要引入const迭代器
typedef const T* const_iterator;
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}如,
const vector<int> c = {4, 5, 6}; // const 容器
vector<int>::const_iterator cit = c.begin();
// *cit = 20; // 编译错误:不能修改元素(只读)其他短小的成员函数
size_t size()const
{
return _finish - _start;//return the number of elements in the vector
}
size_t capacity()const
{
return _end_of_storage - _start;//return the size of the storage space
}
bool empty()const
{
return _start == _finish;//returns whether the vector is empty
}reserve
reserve针对capacity,即最多容纳数元素的个数,调整vector容量到n
如果n<capacity,什么也不做
如果n>capacity,将进行扩容,capacity到n
void reserve(size_t n)
{
if (n > capacity())
{
T* temp = new T[n];//已经初始化好的空间,可以直接赋值
memcpy(temp, _start, sizeof(T) * size());
delete[] _start;
_start = temp;
_finish = _start + size();
_end_of_storage = _start + n;//temp临时变量出作用域后,自动调用析构函数
}
}有问题吗?
但是我接下来进行数据插入,发现出现了问题,_finish=nullptr;
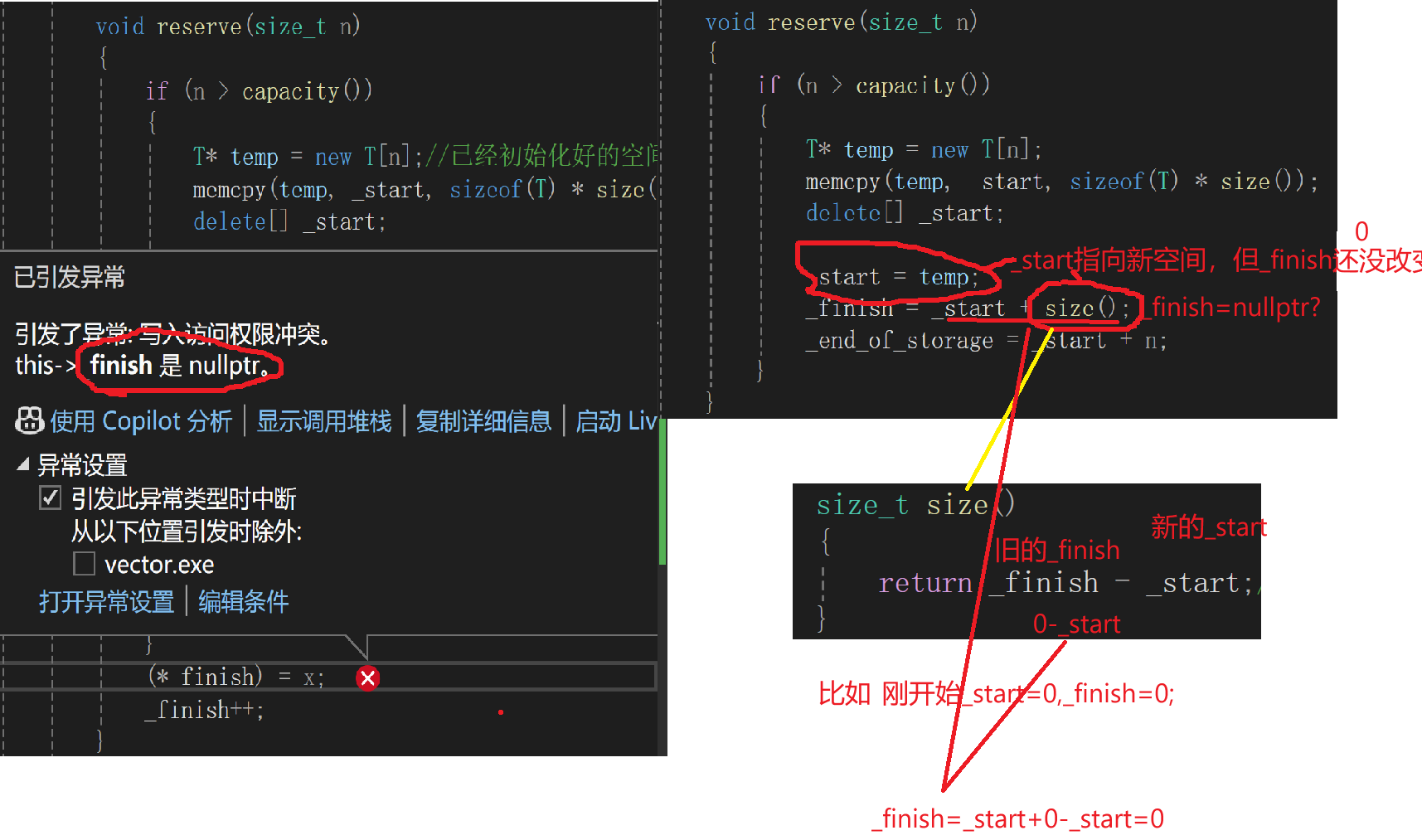
这也是因为size()出现的位置不对,_start已经更新,但_finish没有更新,这样求得的size()就不是有效的数据个数,_finish也就不对了
改正
,在没有更新_start之前求得有效数据个数size(),然后将_finish更新
void reserve(size_t n)
{
if (n > capacity())
{
size_t old_size = size();
T* temp = new T[n];
memcpy(temp, _start, sizeof(T) * size());
delete[] _start;
_start = temp;
_finish = _start + old_size;
_end_of_storage = _start + n;
}
}push_back
增加一个新的元素到vector末尾
void push_back(const T& x)//add a new element at the end of the vector,
{
if (_finish == _end_of_storage)
{
reserve(_end_of_storage == 0 ? 4 : 2 * capacity());
}
(*_finish) = x;
_finish++;
}operator[]访问元素
T& operator[](size_t i)//return a reference to the element at position i
{
assert(i < size());
return _start[i];//返回可以修改的引用
}
T& operator[](size_t i)const
{
assert(i < size());
return _start[i];//不能修改
}const与非const
同end(),begin()类型,需要const和非const
如,
vector<int> v = {1, 2, 3};
v[0]=10; // 正确,v 是非 const 的
const vector<int> cv = {4, 5, 6};
// cv[0] = 20; // 错误!编译报错,const 容器的元素不能修改insert
本质上通过两移动指针指向的元素进行移动和插入数据
void insert (iterator position, const T& val);
pos,是vector中插入新元素位置处的指针,val,待插入元素的值
void insert(iterator pos,T val)
{
if (_finish == _end_of_storage)
{
reserve(_finish == 0 ? 4 : 2 * capacity());
}
iterator end = _finish - 1;//end,pos是指针,指向最后一个有效元素
while (end >= pos)
{
*(end + 1) = (*end);
end--;
}
*pos = val;
_finish++;
}这里会出现一个问题,迭代器失效

当进行insert操作时,由于空间不够会进行扩容,此时会开辟一段新的空间,将旧元素复制到新空间,释放旧内存,此时,所有指向旧内存的迭代器都会失效,因为它们仍然指向旧内存。
如何改正?
将pos(指向旧内存的地址)更新到新内存的地址,利用已经更新的_start+len
void insert(iterator pos, const T& val)
{
if (_finish == _end_of_storage)
{
size_t len = pos - _start;
reserve(_finish == 0 ? 4 : 2 * capacity());//_start已经更新
pos = _start + len;//pos指向新空间
}
iterator end = _finish - 1;//pos是指针,指向最后一个有效元素
while (end >= pos)
{
*(end + 1) = (*end);
end--;
}
*pos = val;
_finish++;
}我们再想想还会有什么问题吗?
如果这样调用可以吗?
v.insert(it, 50);
(*it) *= 10;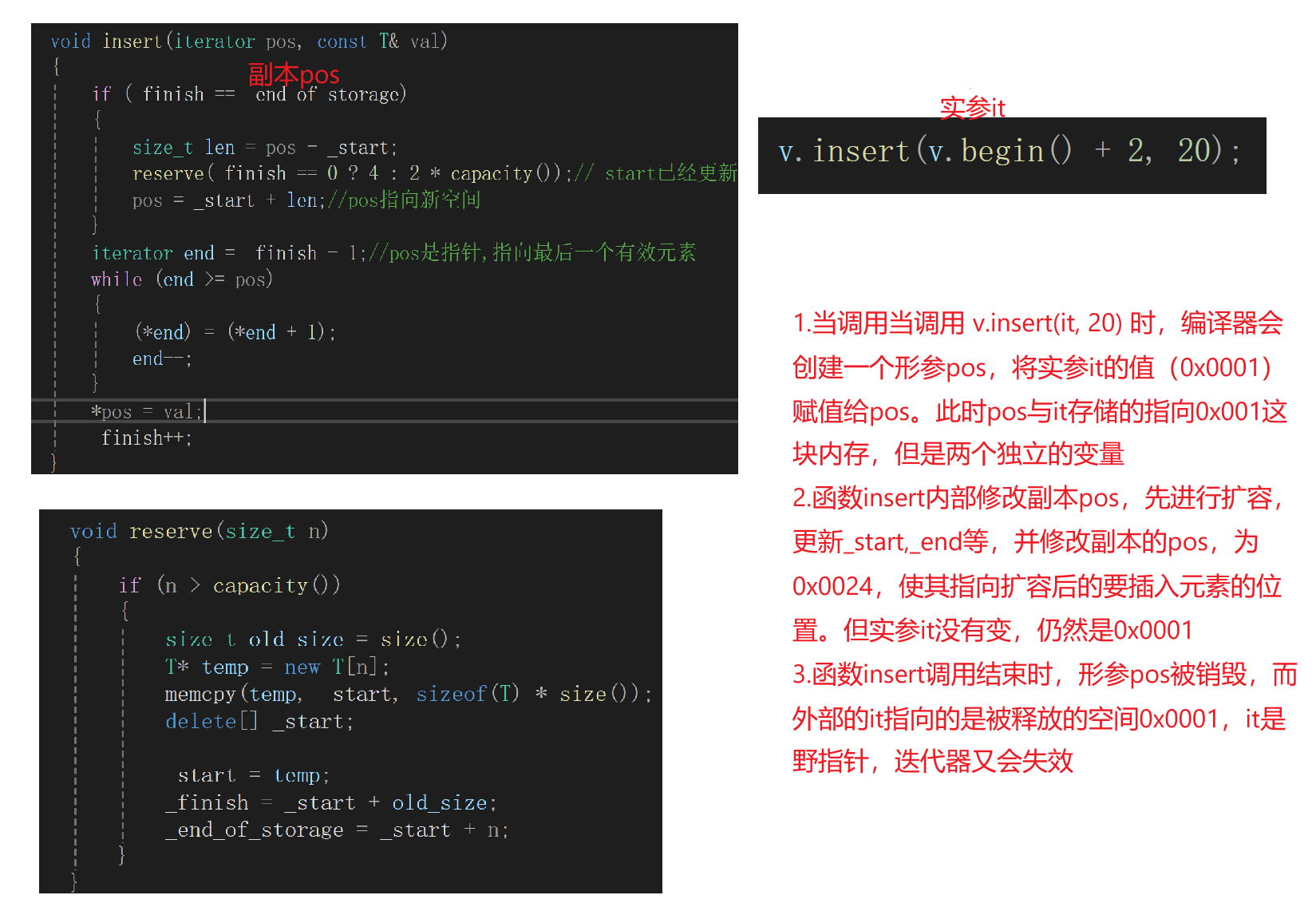
nonono,pos是副本形参,进行扩容时将旧空间释放(it指向的空间),但由于pos是形参,即使pos已经更新了,实参it仍不会指向新的内存空间,it就失效了(野指针),不要访问!
可以加引用吗?iterator& pos;不可以,因为不支持v.insert(v.begin() + 2, 20);这种写法了。因为v.begin() + 2返回的是临时变量(表达式计算的中间结果),具有常性。不能给给到普通的引用(非const),因为权限会放大。
那可以将普通的引用改为const引用来接收吗?const iterator& pos;不可以,因为pos=pos = _start + len;就不能改变了
怎么办?---加返回值
如果要访问的话,需要重新获取新的内存空间,此时我们可以返回新插入元素的内存空间(iterator=T*),it接收后就可以访问了!
iterator insert(iterator pos, const T& val)
{
if (_finish == _end_of_storage)
{
size_t len = pos - _start;
reserve(_finish == 0 ? 4 : 2 * capacity());//_start已经更新
pos = _start + len;//pos指向新空间
}
iterator end = _finish - 1;//pos是指针,指向最后一个有效元素
while (end >= pos)
{
*(end + 1) = (*end);
end--;
}
*pos = val;
_finish++;
return pos;
}这样就可以修改vector中的元素了
it = v.insert(it, 40);//更新一下it
(*it) *= 10;erase
void erase(iterator pos)//remove from the vector a single element
{
iterator it = pos + 1;
while (it != end())
{
*(it - 1) = *it;//*(end()),无效元素
it++;
}
_finish--;
}
//void erase(iterator pos)//remove from the vector a single element
//{
// while (pos < end())
// {
// *pos = *(pos + 1);//*(end()),无效元素
// pos++;
// }
// _finish--;
//}看这样一个场景,给出一串数字,要求删除奇数,会有什么问题?
auto v1 = v.begin();
while (v1 != v.end())
{
if (*v1 % 2 == 0)
{
v.erase(v1);
}
v1++;
}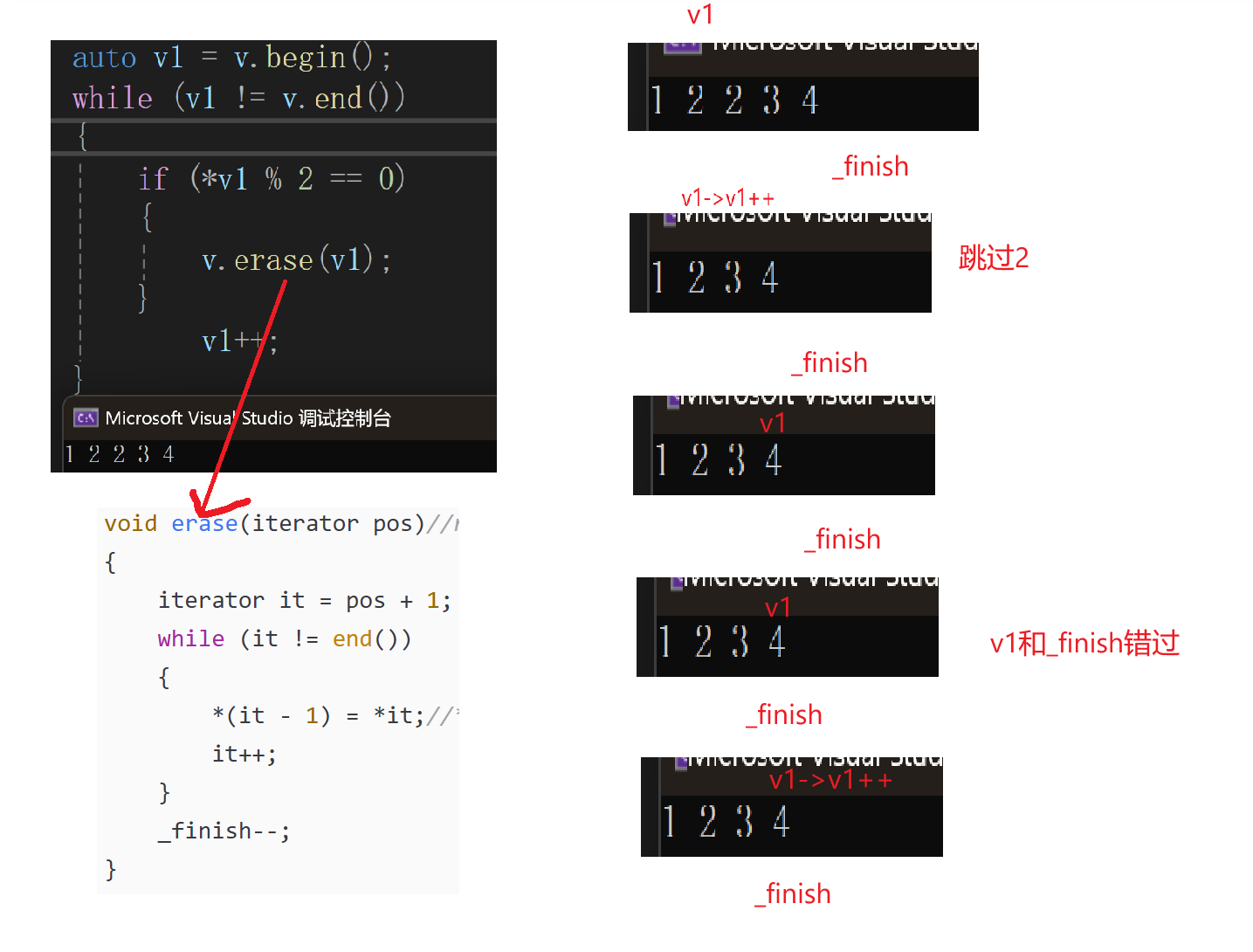
第一个坑,it已经挪动,将原本要删除的地方覆盖(消消乐),此时it就已经是下一个要判断的数据了,但是it++,将下一个带判断的元素跳过.
第二个坑,当最后一个元素是偶数时,最后一个元素+1=_finish,_finish--,此时_finish指向最后一个元素,接下来,v1++,此时v1指向最后一个元素的下一个元素。至此,v1的下一个元素!=_finish,一直在移动。
怎么改?
每次只能走一步,如果是偶数,调用erase删除后,不必v1++,因为数据已经挪动,此时v1指向的元素就是下一个元素。如果是奇数,v1++。
auto v1 = v.begin();
while (v1 != v.end())
{
if (*v1 % 2 == 0)
{
v.erase(v1);
}
else
{
v1++;
}
}以上也称为迭代器失效,元素被删除,pos指向的位置被覆盖。
如,
vector<int> v = {1,2,3,4};
auto it = v.begin() + 1; // 指向2
v.erase(it); // 删除2后,it已失效
// 此时用户不知道下一个有效元素是3,继续使用it会导致未定义行为
++it; // 错误:it已失效如何从根本上解决?
在此基础上,如果返回 “被删除元素的下一个元素” 的迭代器,可以解决上述问题。
iterator erase(iterator pos)//return an iterator pointing to the new location of the element that followed the last element erased
{
iterator it = pos + 1;
while (it != end())
{
*(it - 1) = *it;
it++;
}
_finish--;
return pos;// 此时pos已指向原pos+1的元素(下一个有效位置)
}auto v1 = v.begin();
while (v1 != v.end())
{
if (*v1 % 2 == 0)
{
v1 = v.erase(v1);
}
else
{
v1++;//偶数走过了erase,不必++,返回值已经是下一个位置,间接++
}
}迭代器失效如果要访问的话一定要更新!
resize
针对vector中有效的元素,调整为n个元素
如果n<size,将删除多余的元素
如果n>size,将在尾部添加新增加的元素,如果capacity不够,会扩容
void resize(size_t n,const T& val=T())
{
if (n < size())//删除多余的元素
{
_finish = _start + n;
}
else
{
reserve(n);
while(_finish <= _start + n)//将指针_start向后移动 n 个元素的位置
{
*_finish = val;
_finish++;
}
}
}如果调用resize时不提供第二个参数,val会默认初始化为T()类型的值
内置类型也会调用构造函数吗?
T val=T(),意思是用默认构造构造了一个匿名对象,再拷贝构造。为什么不给0(T val=0),因为T是什么类型我们不知道。如果是string,vector等类类型会调用无参的那个构造。如果T是int,double等内置类型(没有默认构造函数的概念),编译器会处理,为了兼容这些场景,内置类型也有了这些概念int i=int();int i=int(1);int j(2);等,会生成零值(int()是 0 ,double() 是 0.0)。
拷贝构造
,默认是浅拷贝,我们要手动实现深拷贝
如,v1=v3,先对v1进行开空间,然后将v3中的元素添加到v1中
vector(const vector<T>& v)
{
if (this != &v)
{
reserve(v.size());//为v1开空间
for (const auto& e : v)
{
push_back(e);
}
}
}为什么这里是auto&?这里e是v的别名,减少不必要的临时拷贝,直接通过引用操作v中的元素。
且const引用确保不会改变原vector中的元素。
但此时如果我尝试
vector<int> v;编译会报错,因为虽然类内成员有默认值(如_start=nullptr),但是类内默认值需要通过"构造函数的初始化阶段"才能生效,当成员变量在构造函数的初始化列表中 未被显示初始化时,会自动使用这个默认值。(初始化列表优先于函数体内赋值)
但是默认构造生成的原则是:当没有自己定义构造函数时,编译器会自动生成一个无参的默认构造;但当自己定义了构造函数时,如当前的拷贝构造,编译器就不会生成默认构造。
这意味着,当我们自己写了拷贝构造,而没手动定义默认构造时,就无法通过vector<int> v;这样的代码创建对象,因为找不到构造函数。
接下来我们手动定义构造函数,
vector()
{}也可以这样定义,意思是,显示要求编译器生成默认构造
vector() = default;赋值
,v1=v3,两个对象已经创建,不用为v1开辟空间,
可以先清除v1中的内容,再将v2中的内容给给到v1
先实现清除操作
void clear()
{
_start = _finish;
}再实现赋值操作
vector<T>& operator=(const vector<T>& v)//
{
if(this!= &v)
{
clear();//清除v1内容
reserve(v.size());//提前扩容,防止push_back频繁扩容导致效率低
for (auto& e : v)
{
push_back(e);
}
return *this;
}
}这里的返回值为什么不用传值返回 vector<T> operator=呢?
传值返回会产生一个临时副本,会调用拷贝构造,效率低且逻辑不直观
如,v1=v2=v3
当返回引用(vector<T>&)时,v2 = v3 执行后,返回的是 v2 本身的引用,因此 v1 =( v2 = v3 ) 等价于 v1 = v2 ,正确将 v2 的值赋给 v1 。(注意不要返回局部域的引用)
当返回值(vector<T>)时,v2 = v3 执行后,返回的是通过拷贝构造得到的 v2 的临时副本,因此 v1 =( v2 = v3 )等价于 v1 = 临时副本,最终 v1 复制的是临时副本的值,而非 v2 的值。
迭代器区间构造,
//可以在类模板中继续定义函数模板,为了突破类模板参数的限制(如vector<int>)
template <typename InputIterator>
vector(InputIterator first, InputIterator last);first,last是迭代器,拷贝[first,last)之间的数据到新的vector中
这里使用模板参数 InputIterator 而非具体迭代器类型iterator(T*),是为了支持任意输入迭代器(包括其他容器的迭代器、原生数组指针等)
如,
int arr[] = {1, 2, 3, 4};
vector<int> v1(arr, arr + 4); // 用数组指针(迭代器)构造
vector<int> v2 = {10, 20, 30};
vector<int> v3(v2.begin(), v2.end()); // 用其他vector的迭代器构造可以处理指向int,double等类型的迭代器,只要能转化为T
template<typename IntputIterator>
vector(IntputIterator first, IntputIterator last)
{
while (first != last)
{
push_back(*first);
first++;
}
}还有最后一个小问题(修改reserve)
,如果vector中的元素是string类型,在vector中插入string类类型的元素,会出现BUG
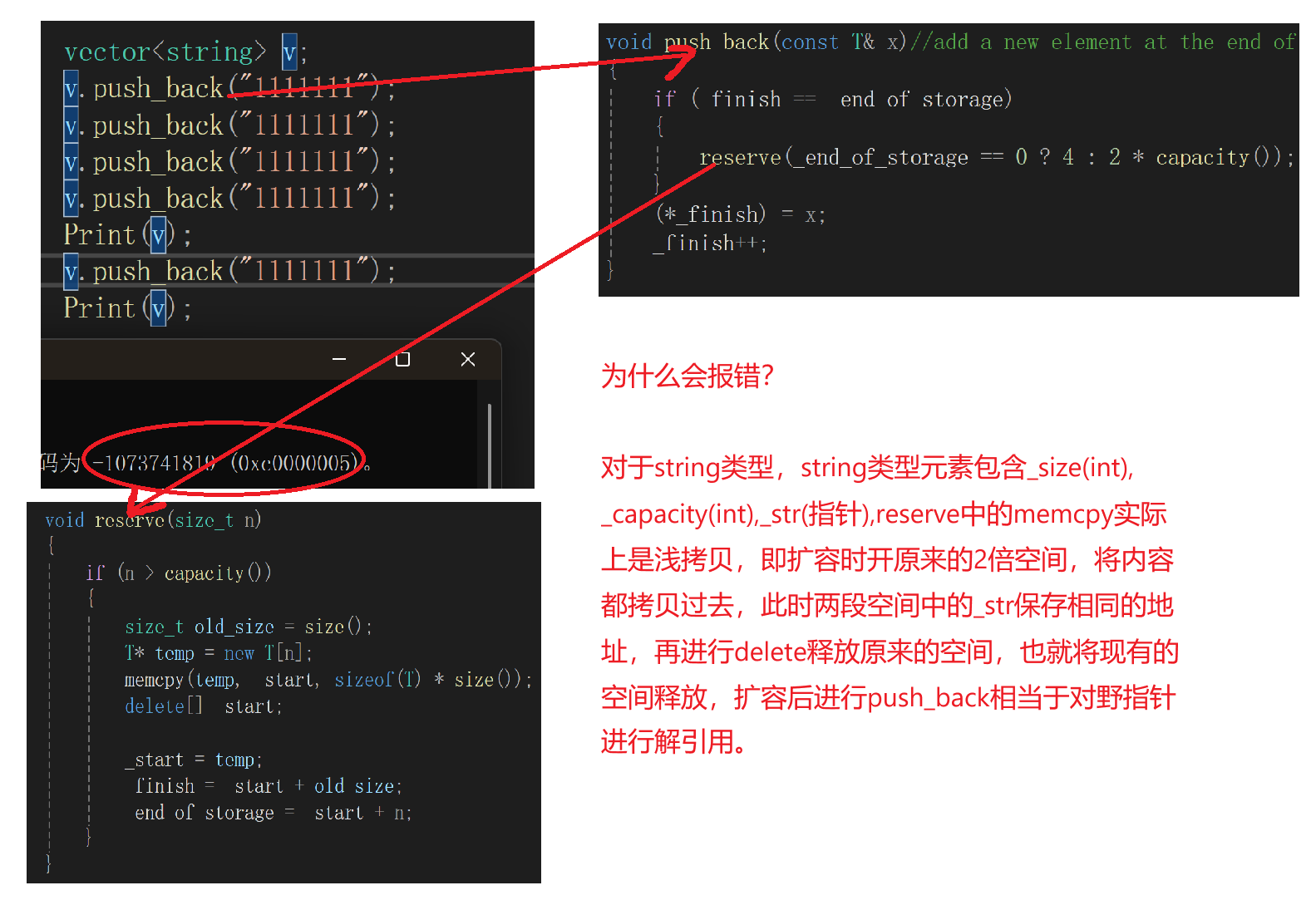
新内存 temp 中的 string 对象与旧内存 _start 中的 string 对象共享同一个字符数组指针(因为只复制了指针地址)。

那该怎么改呢?
不用memcpy,而是利用元素赋值(赋值运算符,实现深拷贝)
//赋值来进行深拷贝
void reserve(size_t n)
{
if (n > capacity())
{
size_t old_size = size();
T* temp = new T[n];
//memcpy(temp, _start, sizeof(T) * size());
for (size_t i = 0; i < old_size; i++)
{
temp[i] = _start[i];
}
delete[] _start;
_start = temp;
_finish = _start + old_size;
_end_of_storage = _start + n;
}
}总结
,memcpy 仅适用于无指针成员的类型;对于包含指针或动态资源的类型(如string),必须利用元素自身的拷贝构造 / 赋值运算符实现深拷贝,否则会出现对野指针解引用、重复释放等错误。
vector<vector<int>>

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)