Kubernetes企业级高可用与资源调度深度解析:从控制平面容灾到调度器内核优化
本文系统阐述了构建高可用Kubernetes集群的关键技术与实践方案,主要内容包括:控制平面组件(etcd、APIServer等)的容灾设计,深入解析多节点集群部署、负载均衡架构等保障措施;资源调度优化策略,涵盖BinPacking算法、拓扑感知调度等性能提升方法;调度器工作原理源码级剖析,展示过滤算法、打分算法的核心实现;以及资源限制机制详解,包括QoS等级分类、cgroups隔离等底层实现。通
目录
1.4 Controller Manager与Scheduler高可用
2.2.2 拓扑感知调度(Topology Manager)
四、资源限制(Requests/Limits):构建公平的资源隔离体系
作者:庸子 | CSDN专栏:Kubernetes架构师之路
用户ID:240186478612
引言:构建坚不可摧的云原生基础设施
在金融、电信等关键业务场景中,Kubernetes集群的可用性直接关系到企业核心服务的连续性。据统计,控制平面故障导致的业务中断占Kubernetes生产事故的47%(CNCF 2023报告),而资源调度不合理引发的性能瓶颈则直接影响用户体验。本文将从架构师视角,系统拆解四大核心主题:
- 控制平面组件容灾设计:构建99.99%可用性的企业级方案
- 资源调度与优化策略:从资源碎片化到QoS保障
- 调度器(Scheduler)工作原理:源码级解析调度决策链
- 资源限制(Requests/Limits)机制:避免“吵闹邻居”的隔离之道
一、控制平面组件容灾:构建永不宕机的集群大脑
1.1 控制平面单点故障风险分析
|
组件 |
故障影响 |
典型恢复时间 |
|
etcd |
集群完全不可用 |
5-30分钟 |
|
API Server |
集群操作中断 |
1-5分钟 |
|
Controller Mgr |
状态同步停滞 |
自动恢复 |
|
Scheduler |
新Pod调度阻塞 |
自动恢复 |
案例:某电商平台因etcd磁盘写满导致集群瘫痪,损失超百万美元。容灾设计需遵循N+2冗余原则(超越常规N+1)。
1.2 etcd高可用架构设计
多节点集群部署
# etcd集群配置示例(3节点跨可用区)
apiVersion: v1
kind: Pod
metadata:
name: etcd-0
spec:
containers:
- name: etcd
image: quay.io/coreos/etcd:v3.5.9
command:
- /bin/sh
- -c
- |
etcd --name etcd-0 \
--data-dir /var/lib/etcd \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://${ETCD_IP}:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://${ETCD_IP}:2380 \
--initial-cluster etcd-0=http://${ETCD_IP}:2380,etcd-1=http://${ETCD_IP_1}:2380,etcd-2=http://${ETCD_IP_2}:2380 \
--initial-cluster-token my-etcd-token \
--initial-cluster-state new
关键容灾机制
- Raft共识算法:Leader选举需多数节点确认(3节点容忍1故障,5节点容忍2故障)
- 快照与WAL:定期快照(默认1小时)+ 预写日志(WAL)防止数据丢失
- 备份策略:
# 定期快照备份脚本 ETCDCTL_API=3 etcdctl snapshot save snapshot.db \ --endpoints=https://127.0.0.1:2379 \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ --cert=/etc/kubernetes/pki/etcd/server.crt \ --key=/etc/kubernetes/pki/etcd/server.key
1.3 API Server多活负载均衡
架构设计
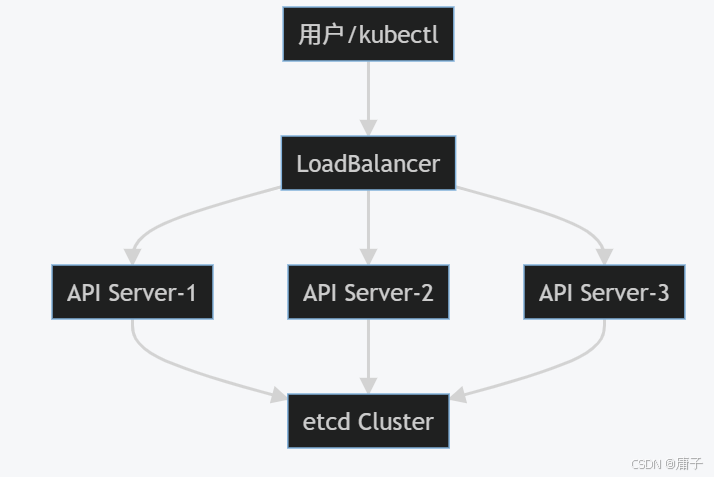
实现方案
- 硬件负载均衡:F5 BIG-IP配置健康检查(端口6443 + /healthz路径)
- 软件负载均衡:Keepalived + HAProxy
frontend k8s-api bind *:6443 mode tcp default_backend k8s-api-backend backend k8s-api-backend mode tcp balance roundrobin option tcp-check server master1 192.168.1.10:6443 check server master2 192.168.1.11:6443 check server master3 192.168.1.12:6443 check
1.4 Controller Manager与Scheduler高可用
Leader选举机制
// Controller Manager Leader选举核心代码(k8s.io/client-go/tools/leaderelection)
func RunLeaderElection(...) {
le, err := leaderelection.NewLeaderElector(leaderelection.LeaderElectionConfig{
Lock: rl, // 租约锁(如configmap/endpoint)
LeaseDuration: 15 * time.Second,
RenewDeadline: 10 * time.Second,
RetryPeriod: 2 * time.Second,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) { runController(ctx) },
OnStoppedLeading: func() { log.Fatalf("lost leadership") },
},
})
le.Run(ctx)
}
部署建议
- 多副本部署:每个组件至少3个副本
- 反亲和性调度:避免同节点部署
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: component
operator: In
values: ["kube-controller-manager"]
topologyKey: "kubernetes.io/hostname"
二、资源调度与优化:从资源碎片到极致性能
2.1 资源调度核心挑战
|
问题类型 |
现象 |
优化方向 |
|
资源碎片化 |
节点CPU利用率40%但无法调度大Pod |
Bin Packing算法优化 |
|
QoS冲突 |
Burstable Pod抢占Guaranteed资源 |
优先级与抢占机制 |
|
拓扑感知缺失 |
GPU Pod跨NUMA节点导致性能下降 |
拓扑管理策略 |
2.2 调度优化策略矩阵
2.2.1 资源Bin Packing优化
算法对比:
|
算法 |
原理 |
适用场景 |
|
BestFit |
选择资源最匹配节点 |
资源敏感型业务 |
|
WorstFit |
选择资源最空闲节点 |
弹性扩缩容场景 |
|
Spread |
均匀分布Pod |
高可用要求场景 |
实战配置:
# 启用资源Bin Packing插件
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
plugins:
score:
disabled:
- name: NodeResourcesBalancedAllocation
enabled:
- name: NodeResourcesMostAllocated # 启用BestFit策略
2.2.2 拓扑感知调度(Topology Manager)
NUMA对齐优化:
# 启用拓扑管理策略(kubelet参数) --topology-manager-policy=best-effort # 可选:none/best-effort/restricted/single-numa-node
GPU资源调度案例:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: cuda-container
image: nvidia/cuda:11.4.0-base
resources:
limits:
nvidia.com/gpu: 2
memory: "16Gi"
requests:
cpu: "4"
memory: "16Gi"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nvidia.com/gpu.count
operator: Gt
values: ["1"]
2.3 调度性能优化实践
调度器扩展点
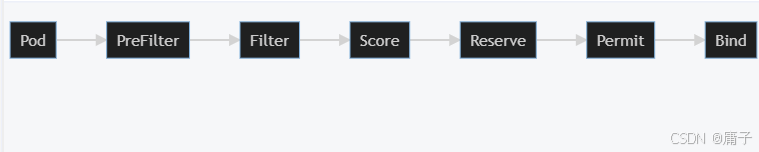
自定义调度器开发:
// 实现自定义Score插件
type CustomScore struct{}
func (cs *CustomScore) Score(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := state.NodeInfoSnapshot().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(err)
}
// 自定义评分逻辑(如基于网络延迟)
score := calculateNetworkScore(nodeInfo.Node())
return score, nil
}
大规模集群优化
- 调度器分片:按Namespace/Label分片调度
- 缓存优化:
# 调度器缓存配置 percentageOfNodesToScore: 0.5 # 只评分50%节点(默认100%)
三、调度器(Scheduler)工作原理:源码级深度剖析
3.1 调度决策全流程
核心调度循环
// pkg/scheduler/scheduler.go
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 1. 获取待调度Pod
podInfo := sched.NextPod()
// 2. 执行调度算法
result, err := sched.Algorithm.Schedule(sched.getContext(), pod)
// 3. 绑定到节点
assumed, err := sched.assume(pod, result.SuggestedHost)
// 4. 异步绑定
go func() {
err := sched.bind(assumed, result.SuggestedHost)
}()
}
调度算法三阶段
|
阶段 |
作用 |
关键插件 |
|
PreFilter |
预处理Pod/节点信息 |
VolumeBinding, InterPodAffinity |
|
Filter |
硬约束过滤 |
NodeName, NodePorts, TaintToleration |
|
Score |
软约束打分 |
NodeResources, ImageLocality |
3.2 关键算法源码解析
3.2.1 过滤算法(Filter)
TaintToleration实现:
// pkg/scheduler/framework/plugins/tainttoleration/taint_toleration.go
func (pl *TaintToleration) Filter(...) *framework.Status {
taints := nodeInfo.Node().Spec.Taints
tolerations := pod.Spec.Tolerations
for _, taint := range taints {
if !tolerations.ToleratesTaint(&taint) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, taint.Message)
}
}
return nil
}
3.2.2 打分算法(Score)
NodeResources打分逻辑:
// pkg/scheduler/framework/plugins/noderesources/resource_allocation.go
func (r *ResourceAllocationScorer) Score(...) (int64, *framework.Status) {
requested := calculateRequestedResources(pod)
allocatable := nodeInfo.Allocatable()
// 计算资源分配率
cpuScore := calculateScore(requested.MilliCPU, allocatable.MilliCPU)
memScore := calculateScore(requested.Memory, allocatable.Memory)
// 加权求和
return (cpuScore * r.cpuWeight + memScore * r.memoryWeight) / (r.cpuWeight + r.memoryWeight), nil
}
3.3 调度框架扩展机制
插件注册流程
// pkg/scheduler/framework/runtime/framework.go
func (f *frameworkImpl) Register(pluginName string, pluginFactory PluginFactory) {
if _, exists := f.pluginMap[pluginName]; exists {
panic(fmt.Sprintf("plugin %q already registered", pluginName))
}
f.pluginMap[pluginName] = pluginFactory
}
自定义调度策略示例
# 自定义调度策略配置
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: custom-scheduler
plugins:
filter:
enabled:
- name: CustomFilterPlugin
score:
enabled:
- name: CustomScorePlugin
weight: 100
pluginConfig:
- name: CustomScorePlugin
args:
preferredRegions:
- cn-east-1
- cn-north-1
四、资源限制(Requests/Limits):构建公平的资源隔离体系
4.1 资源模型核心概念
QoS等级分类
|
QoS Class |
Requests/Limits规则 |
OOM处理优先级 |
|
Guaranteed |
Requests == Limits |
最低(最后被杀) |
|
Burstable |
Requests < Limits |
中等 |
|
BestEffort |
未设置Requests/Limits |
最高(最先被杀) |
资源计算示例
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
spec:
containers:
- name: app
image: nginx
resources:
requests:
cpu: "500m" # 0.5 CPU核心
memory: "256Mi" # 256 MiB
limits:
cpu: "1000m" # 1 CPU核心
memory: "512Mi" # 512 MiB
4.2 资源限制底层实现
cgroups资源隔离
# 查看Pod的cgroup配置 crictl inspect <container-id> | grep -A 10 "cgroupsPath" # 输出示例:kubepods/burstable/pod123456/6789abcdef # 查看CPU限制 cat /sys/fs/cgroup/kubepods/burstable/pod123456/6789abcdef/cpu.cfs_quota_us # 100000 (1 core) cat /sys/fs/cgroup/kubepods/burstable/pod123456/6789abcdef/cpu.cfs_period_us # 100000
内存OOM机制
// kubelet OOM处理逻辑
func (m *manager) applyOOMMemoryPressure(pod *v1.Pod, memoryOOM bool) {
if memoryOOM {
// 记录OOM事件
m.recorder.Eventf(pod, v1.EventTypeWarning, events.OOMKilling, "Container %q in pod %q was OOM killed", container.Name, pod.Name)
// 根据QoS等级决定是否重启容器
if qos.GetPodQOS(pod) == v1.PodQOSBestEffort {
m.killContainer(pod, container, "OOMKilled")
}
}
}
4.3 资源限制最佳实践
4.3.1 避免资源碎片化
策略:
- Request设置:建议设置为Pod峰值的70%-80%
- Limit设置:不超过Request的1.5-2倍
监控指标:
# CPU Throttling率(超过10%需优化)
sum(rate(container_cpu_cfs_throttled_seconds_total{container!="POD"}[5m])) by (pod) /
sum(rate(container_cpu_usage_seconds_total{container!="POD"}[5m])) by (pod) * 100 > 10
# 内存OOM事件
count(kube_pod_container_status_restarts_total{reason="OOMKilled"}) by (pod) > 0
4.3.2 垂直Pod自动扩缩容(VPA)
# VPA配置示例
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto" # 自动更新Pod资源
resourcePolicy:
containerPolicies:
- containerName: "*"
minAllowed:
cpu: "100m"
memory: "50Mi"
maxAllowed:
cpu: "1"
memory: "500Mi"
五、企业级容灾与调度实战案例
5.1 某银行核心系统容灾改造
背景:
- 原架构:单控制平面 + 本地etcd
- 要求:RPO<5分钟,RTO<2分钟
解决方案:
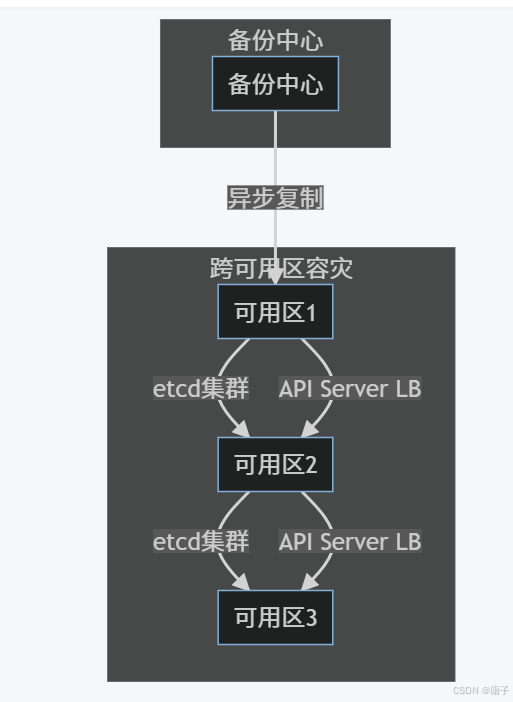
关键措施:
- etcd跨3AZ部署(5节点集群)
- API Server多活LB(F5全局负载均衡)
- 定时备份:每5分钟快照备份到对象存储
- 故障自愈:基于Operator的自动重建
5.2 视频平台资源调度优化
挑战:
- 转码任务CPU密集型,导致普通业务响应延迟
- GPU资源利用率仅30%
优化方案:
- 专用节点池:
# 标注GPU节点 kubectl label nodes node-1 gpu=true
- 调度策略:
# 转码任务Pod配置
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: In
values: ["true"]
tolerations:
- key: "dedicated"
operator: "Equal"
value: "transcoding"
effect: "NoSchedule"
- 效果:
- 转码任务延迟降低40%
- GPU利用率提升至75%
六、演进趋势与架构师建议
6.1 技术演进方向
|
领域 |
趋势 |
代表技术 |
|
控制平面 |
去中心化 |
Karmada, KubeFed |
|
调度优化 |
AI驱动调度 |
Descheduler, KubeAI |
|
资源隔离 |
轻量级虚拟化 |
Kata Containers, gVisor |
6.2 架构师行动清单
- 容灾设计:
- 执行年度容灾演练(模拟etcd/API Server故障)
- 建立跨区域备份机制(如Velero + Restic)
- 调度优化:
- 部署Descheduler定期驱逐低效Pod
- 启用Topology Manager优化硬件亲和性
- 资源治理:
- 推广VPA+HPA混合自动扩缩容
- 建立资源配额体系(ResourceQuota)
结语:构建弹性高效的云原生操作系统
Kubernetes的控制平面容灾与资源调度能力,直接决定了企业云原生基础设施的健壮性。通过本文的深度解析,您已掌握:
- 容灾架构设计:从etcd集群到API Server多活的完整方案
- 调度内核机制:源码级理解调度决策链与扩展点
- 资源隔离之道:通过Requests/Limits实现公平QoS保障
在后续专栏中,我们将继续深入探索安全体系(RBAC/NetworkPolicy)、存储架构(CSI/快照)、可观测性(OpenTelemetry) 等核心主题。请持续关注《Kubernetes架构师之路》,系统化构建您的云原生技术领导力!
在Kubernetes的世界里,每个设计决策都承载着对大规模分布式系统的深刻洞察。愿您在实践中不断精进,成为驾驭云原生浪潮的领航者!
立即订阅专栏,解锁完整技术体系!
专栏链接:Kubernetes架构师之路:系统化学习与实践_庸子的博客-CSDN博客
版权声明:本文为CSDN专栏原创内容,转载请注明出处及作者信息。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)