Spring AI与RAG技术实战:构建企业级智能文档问答系统
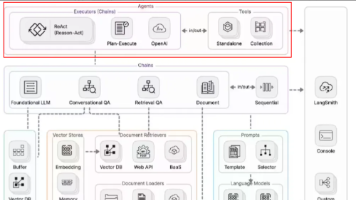
Spring AI: Spring生态系统中的AI集成框架RAG架构: 检索增强生成技术栈向量数据库Embedding模型: OpenAI/Ollama等: 后端服务框架本文详细介绍了基于Spring AI和RAG技术构建企业级智能文档问答系统的完整方案。通过结合先进的AI技术和成熟的Java生态系统,我们能够构建出既强大又稳定的智能问答系统。
·
Spring AI与RAG技术实战:构建企业级智能文档问答系统
引言
随着人工智能技术的快速发展,企业对于智能化文档处理的需求日益增长。传统的文档管理系统往往只能提供基础的检索功能,而无法理解用户的自然语言查询意图。Spring AI结合RAG(检索增强生成)技术,为企业构建智能文档问答系统提供了全新的解决方案。
技术栈概述
核心组件
- Spring AI: Spring生态系统中的AI集成框架
- RAG架构: 检索增强生成技术栈
- 向量数据库: Milvus/Chroma/Redis
- Embedding模型: OpenAI/Ollama等
- Spring Boot: 后端服务框架
系统架构设计
整体架构
用户请求 → API网关 → Spring AI服务 → RAG引擎 → 向量数据库 → 返回结果
核心模块
- 文档预处理模块
- 向量化处理模块
- 语义检索模块
- 答案生成模块
- 会话管理模块
实现步骤详解
1. 环境搭建与依赖配置
首先在Spring Boot项目中添加Spring AI依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-core</artifactId>
<version>0.8.1</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>0.8.1</version>
</dependency>
2. 文档加载与预处理
实现文档加载器,支持多种格式:
@Component
public class DocumentLoader {
@Autowired
private TextSplitter textSplitter;
public List<Document> loadDocuments(String filePath) {
// 支持PDF、Word、TXT等多种格式
List<Document> documents = new ArrayList<>();
// 文件解析逻辑
String content = parseFileContent(filePath);
// 文本分割
List<String> chunks = textSplitter.splitText(content);
for (String chunk : chunks) {
documents.add(new Document(chunk, Map.of("source", filePath)));
}
return documents;
}
private String parseFileContent(String filePath) {
// 具体的文件解析实现
return "";
}
}
3. 向量化处理
使用Embedding模型将文本转换为向量:
@Service
public class EmbeddingService {
@Autowired
private EmbeddingModel embeddingModel;
public List<Double> generateEmbedding(String text) {
return embeddingModel.embed(text);
}
public List<List<Double>> generateEmbeddings(List<String> texts) {
return embeddingModel.embed(texts);
}
}
4. 向量数据库集成
集成Milvus向量数据库:
@Configuration
public class VectorStoreConfig {
@Value("${milvus.host}")
private String milvusHost;
@Value("${milvus.port}")
private int milvusPort;
@Bean
public MilvusService milvusService() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost(milvusHost)
.withPort(milvusPort)
.build();
return new MilvusService(connectParam);
}
@Bean
public VectorStore vectorStore(MilvusService milvusService,
EmbeddingService embeddingService) {
return new MilvusVectorStore(milvusService, embeddingService);
}
}
5. RAG引擎实现
核心的检索增强生成逻辑:
@Service
public class RAGService {
@Autowired
private VectorStore vectorStore;
@Autowired
private ChatClient chatClient;
@Autowired
private EmbeddingService embeddingService;
public String answerQuestion(String question, String conversationId) {
// 1. 生成问题向量
List<Double> questionEmbedding = embeddingService.generateEmbedding(question);
// 2. 向量检索相似文档
List<Document> relevantDocs = vectorStore.similaritySearch(
questionEmbedding, 5, 0.7);
// 3. 构建提示词
String context = buildContext(relevantDocs);
String prompt = buildPrompt(question, context);
// 4. 调用AI模型生成答案
ChatResponse response = chatClient.generate(prompt);
// 5. 保存会话历史
saveConversation(conversationId, question, response.getText());
return response.getText();
}
private String buildContext(List<Document> documents) {
StringBuilder context = new StringBuilder();
for (Document doc : documents) {
context.append(doc.getContent()).append("\n\n");
}
return context.toString();
}
private String buildPrompt(String question, String context) {
return String.format("""
基于以下上下文信息,请回答用户的问题。
如果上下文信息不足以回答问题,请如实告知。
上下文:
%s
问题:%s
请提供准确、简洁的回答:
""", context, question);
}
}
6. REST API设计
提供问答接口:
@RestController
@RequestMapping("/api/rag")
public class RAGController {
@Autowired
private RAGService ragService;
@PostMapping("/ask")
public ResponseEntity<AnswerResponse> askQuestion(
@RequestBody QuestionRequest request,
@RequestHeader(value = "X-Conversation-Id", required = false) String conversationId) {
if (conversationId == null) {
conversationId = UUID.randomUUID().toString();
}
String answer = ragService.answerQuestion(request.getQuestion(), conversationId);
AnswerResponse response = new AnswerResponse();
response.setAnswer(answer);
response.setConversationId(conversationId);
response.setTimestamp(LocalDateTime.now());
return ResponseEntity.ok(response);
}
@PostMapping("/documents")
public ResponseEntity<String> uploadDocument(@RequestParam("file") MultipartFile file) {
try {
// 文档上传和处理逻辑
String filePath = saveUploadedFile(file);
// 处理文档并存入向量数据库
processDocument(filePath);
return ResponseEntity.ok("文档上传成功");
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body("文档上传失败: " + e.getMessage());
}
}
}
高级特性实现
1. 会话内存管理
实现多轮对话上下文保持:
@Service
public class ConversationService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
private static final String CONVERSATION_PREFIX = "conv:";
private static final long TTL = 3600; // 1小时过期
public void saveConversation(String conversationId, String question, String answer) {
Conversation conversation = getConversation(conversationId);
if (conversation == null) {
conversation = new Conversation(conversationId);
}
conversation.addMessage(new Message("user", question));
conversation.addMessage(new Message("assistant", answer));
redisTemplate.opsForValue().set(
CONVERSATION_PREFIX + conversationId,
conversation,
TTL, TimeUnit.SECONDS
);
}
public Conversation getConversation(String conversationId) {
return (Conversation) redisTemplate.opsForValue()
.get(CONVERSATION_PREFIX + conversationId);
}
}
2. 智能代理(Agent)集成
实现复杂的多步骤任务处理:
@Service
public class AgentService {
@Autowired
private ToolExecutionFramework toolExecutionFramework;
public String executeComplexTask(String taskDescription, String conversationId) {
// 1. 任务分解
List<SubTask> subTasks = decomposeTask(taskDescription);
// 2. 按顺序执行子任务
StringBuilder result = new StringBuilder();
for (SubTask subTask : subTasks) {
String subResult = executeSubTask(subTask, conversationId);
result.append(subResult).append("\n");
}
return result.toString();
}
private List<SubTask> decomposeTask(String task) {
// 使用AI模型进行任务分解
// 返回任务步骤列表
return new ArrayList<>();
}
}
3. 防止AI幻觉(Hallucination)
实现答案验证机制:
@Component
public class HallucinationChecker {
@Autowired
private VectorStore vectorStore;
@Autowired
private EmbeddingService embeddingService;
public boolean checkAnswer(String answer, String originalQuestion) {
// 1. 检查答案是否基于检索到的上下文
double similarityScore = calculateSimilarity(answer, originalQuestion);
// 2. 检查答案中是否包含无法验证的信息
boolean containsUnverifiableInfo = containsUnverifiableInformation(answer);
return similarityScore > 0.6 && !containsUnverifiableInfo;
}
private double calculateSimilarity(String text1, String text2) {
List<Double> embedding1 = embeddingService.generateEmbedding(text1);
List<Double> embedding2 = embeddingService.generateEmbedding(text2);
return cosineSimilarity(embedding1, embedding2);
}
}
性能优化策略
1. 向量检索优化
@Configuration
public class PerformanceConfig {
@Bean
public HikariDataSource dataSource() {
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/rag_system");
config.setUsername("username");
config.setPassword("password");
config.setMaximumPoolSize(20);
config.setMinimumIdle(5);
config.setConnectionTimeout(30000);
config.setIdleTimeout(600000);
config.setMaxLifetime(1800000);
return new HikariDataSource(config);
}
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(1000));
return cacheManager;
}
}
2. 异步处理优化
使用Spring的异步处理提高响应速度:
@Service
public class AsyncDocumentProcessor {
@Async
public CompletableFuture<Void> processDocumentAsync(String filePath) {
return CompletableFuture.runAsync(() -> {
try {
// 耗时的文档处理操作
processDocument(filePath);
} catch (Exception e) {
log.error("文档处理失败: {}", filePath, e);
}
});
}
}
监控与运维
1. 集成Prometheus监控
@Configuration
public class MonitoringConfig {
@Bean
public MeterRegistryCustomizer<MeterRegistry> metricsCommonTags() {
return registry -> registry.config().commonTags(
"application", "rag-system",
"environment", "production"
);
}
@Bean
public TimedAspect timedAspect(MeterRegistry registry) {
return new TimedAspect(registry);
}
}
2. 日志记录策略
@Aspect
@Component
@Slf4j
public class LoggingAspect {
@Around("execution(* com.example.rag.service.*.*(..))")
public Object logServiceMethods(ProceedingJoinPoint joinPoint) throws Throwable {
String methodName = joinPoint.getSignature().getName();
Object[] args = joinPoint.getArgs();
log.info("方法调用: {} 参数: {}", methodName, Arrays.toString(args));
long startTime = System.currentTimeMillis();
Object result = joinPoint.proceed();
long endTime = System.currentTimeMillis();
log.info("方法完成: {} 耗时: {}ms", methodName, (endTime - startTime));
return result;
}
}
部署与扩展
Docker容器化部署
FROM openjdk:17-jdk-slim
WORKDIR /app
COPY target/rag-system.jar app.jar
EXPOSE 8080
ENV JAVA_OPTS="-Xms512m -Xmx1024m"
ENTRYPOINT ["java", "-jar", "app.jar"]
Kubernetes部署配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: rag-system
spec:
replicas: 3
selector:
matchLabels:
app: rag-system
template:
metadata:
labels:
app: rag-system
spec:
containers:
- name: rag-app
image: rag-system:latest
ports:
- containerPort: 8080
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1"
---
apiVersion: v1
kind: Service
metadata:
name: rag-service
spec:
selector:
app: rag-system
ports:
- port: 80
targetPort: 8080
总结与展望
本文详细介绍了基于Spring AI和RAG技术构建企业级智能文档问答系统的完整方案。通过结合先进的AI技术和成熟的Java生态系统,我们能够构建出既强大又稳定的智能问答系统。
关键优势
- 准确性高: RAG架构确保答案基于真实文档内容
- 扩展性强: 微服务架构支持水平扩展
- 维护简单: Spring生态提供完善的工具链
- 成本可控: 开源技术栈降低总体拥有成本
未来发展方向
- 多模态文档支持(图片、表格等)
- 实时文档更新与增量索引
- 多语言支持与跨语言检索
- 个性化答案生成与用户偏好学习
通过本文的实践指南,开发者可以快速构建属于自己的智能文档问答系统,为企业数字化转型提供强有力的技术支撑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献87条内容
已为社区贡献87条内容

所有评论(0)