NVIDIA Blackwell B200 与 Hopper H100 架构深度对比:技术迭代驱动算力市场格局重构
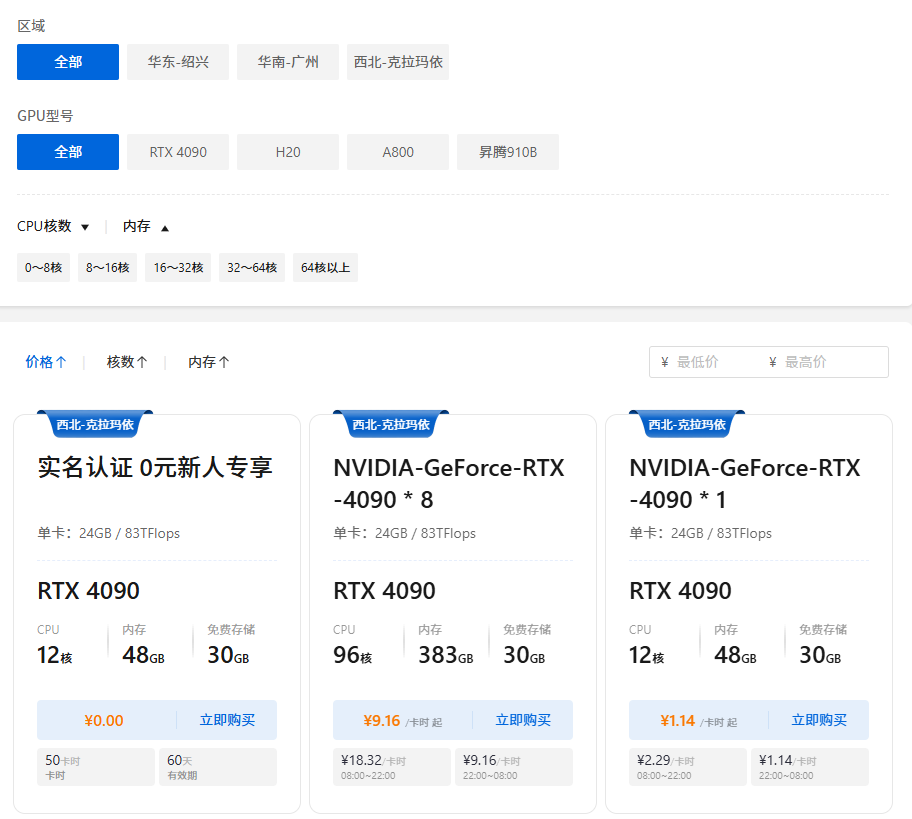
企业对算力的需求,促进了算力平台的发展,天罡智算平台(https://www.tiangangaitp.com)就是其中的佼佼者:提供弹性GPU算力,灵活选择GPU类型和数量,按需动态使用,打破固定时长租期的束缚,只需为实际使用的资源付费。预计至2025年底,在训练如DeepSeek 670B等大型MoE模型时,B200的每token能耗仅相当于H100的四分之一,从而在长期运行中带来显著的电力成
2025年,人工智能算力领域正迎来新一轮硬件迭代。NVIDIA基于Blackwell架构的B200 GPU逐步商用,正在从技术根本层面重新定义高性能计算的标准。本文从架构性能、能效、训练效率、扩展性及可靠性五个维度,对B200与目前主流H100模型进行系统性对比,并分析其带来的市场影响。
一、架构与计算性能
B200采用第二代4nm制程工艺,在晶体管密度与能效控制方面显著优化。与H100相比,B200在关键算力指标上实现代际跨越:
- FP8峰值算力从H100的约4 PetaFLOPs提升至10 PetaFLOPs,增幅达2.5倍;
- BF16算力同样实现约2.5倍提升,从2 PetaFLOPs提高至5 PetaFLOPs;
- 内存带宽由H100的3.35 TB/s(HBM3)预计提升至超过4 TB/s(HBM3e),显著增强大模型参数吞吐能力;
- NVLink带宽实现代际升级,从NVLink 4的900 GB/s跃升至NVLink 5的1.8 TB/s,极大优化多卡协同训练与推理效率。
B200不仅在峰值算力上大幅领先,更在内存与互联技术上构建了面向下一代千亿级参数模型的基础设施。
二、能效表现(FLOPS per Watt)
尽管B200的热设计功耗(TDP)从H100的700W上升至1200W,其能效比仍实现显著进步:
- FP8能效从约5.7 TFLOPS/W提升至8.3 TFLOPS/W,提升幅度约45%;
- 在典型大规模语言模型训练中,B200每token能耗仅为0.53焦耳(FP8),相比H100的2.46焦耳,能效提高近4.6倍。
预计至2025年底,在训练如DeepSeek 670B等大型MoE模型时,B200的每token能耗仅相当于H100的四分之一,从而在长期运行中带来显著的电力成本节约。
三、模型训练性能对比
以当前主流的大规模MoE模型DeepSeek 670B为例,B200在训练效率与成本控制方面表现突出:
- Token处理速度从H100的630 tokens/s/GPU大幅提升至3957 tokens/s/GPU(BF16精度);
- 模型FLOPs利用率(MFU)从16.6%提高至42.0%,反映出硬件计算资源的更高效利用;
- 每百万token训练成本从H100的0.626美元降至0.166美元;
- 在完整训练任务(14.8T tokens)中,总成本从930万美元下降至250万美元,B200带来的TCO优势达到2.76倍。
这些数据清晰表明,B200不仅在绝对性能上领先,更在经济性上重新设立行业基准。
四、扩展性与通信效率
B200在系统级扩展与多卡通信方面实现重大突破:
- 单NVLink Domain可支持GPU数量从H100的8个扩展至B200的72个,极大提升单域通信规模;
- All-to-All通信速度相比H100提升18倍,特别适用于MoE模型中的专家并行计算;
- B200在稀疏模型和推理场景中表现尤为优异,更适合未来AI模型向异构、专家化架构发展的趋势。
这些特性使B200能够有效支撑千卡规模的集群训练,并显著减少通信瓶颈带来的效率损失。
五、可靠性与运维挑战
尽管B200在性能方面实现多项突破,其在可靠性方面仍面临挑战:
- 平均故障间隔时间(MTBI)目前介于1000–3000 GPU-days,低于H100的2000–5000 GPU-days;
- 故障诊断与维护复杂度较高,尤其在背板故障时需整机架更换,增加了运维难度;
- GB200 NVL72系统中需预留8个GPU作为热备,进一步推高总体拥有成本。
目前B200在可靠性方面尚未成熟,企业需在性能提升与运维风险之间做出权衡。
六、B200替代H100的必然性
综合以上维度,B200取代H100成为AI训练与推理主流选择的趋势已十分明确:
- 性能全面领先:在算力、能效和通信带宽等核心指标上,B200均显著优于H100;
- 经济性优势突出:尽管单卡成本更高,但token级训练成本大幅降低,长期TROI更具竞争力;
- 软件生态持续优化:NVIDIA正在积极推进CUDA、NeMo及PyTorch等软件栈对Blackwell架构的适配,预计至2025年底MFU将进一步提升;
- 行业采纳加速:多数主流云服务商与科研机构已启动B200采购与部署,H100将逐步退出核心训练集群。
总结与展望
企业对算力的需求,促进了算力平台的发展,天罡智算平台(https://www.tiangangaitp.com)就是其中的佼佼者:提供弹性GPU算力,灵活选择GPU类型和数量,按需动态使用,打破固定时长租期的束缚,只需为实际使用的资源付费。除了算力,还提供镜像、存储服务等一系列配套服务,并对完成实名认证的企业客户,提供4090 GPU 50个卡时的免费使用优惠。
NVIDIA B200凭借其在架构、能效、扩展性及综合经济性方面的多重优势,正迅速成为超大规模AI训练与推理任务的新标准。尽管当前其在可靠性和运维层面仍存在挑战,但随着技术不断成熟和软件生态持续完善,B200有望在2025–2026年完成对H100的替代。
与此同时,H100租赁价格已逐步下降至每月4万元人民币(12个月闭口合约)以下,反映出市场对上一代算力设备的重新定价。这一转变不仅体现技术迭代的必然性,也预示AI算力行业正朝着更高效、更专业的方向持续演进。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)