大模型微调与LoRA/QLoRA方法解析
大模型在垂直领域应用时需进行微调以提升专业性,但全量微调成本过高。参数高效微调通过冻结大部分参数、仅训练少量新增参数实现轻量适配,其中LoRA是最流行的方法,它通过低秩矩阵分解更新权重,显著降低训练参数。针对更大模型,QLoRA结合4/8-bit量化进一步降低显存占用,使单卡微调百亿级模型成为可能,精度损失可控。
目录
1.为什么需要微调?
大模型在通用语料上训练,具备广泛的语言与知识能力。但当模型应用到垂直领域(如医疗问答、法律咨询、金融风控等)时,往往需要:
-
对齐领域知识:让模型掌握专业术语、知识体系。
-
对齐任务风格:如客服回复需要更礼貌,技术文档生成需要更精准。
-
提升效果稳定性:降低幻觉,提高准确率。
如果直接对一个百亿、千亿参数的模型做全量微调,训练开销极大,对硬件要求高,难以在企业内部快速落地。因此需要更轻量的解决方案。
2. 参数高效微调(PEFT)
PEFT 的核心思想是:冻结模型大部分参数,只在部分位置引入额外可训练参数,以较小的计算代价完成领域适配。常见 PEFT 方法包括:
-
Prompt Tuning/ Prefix-Tuning / P-Tuning:在输入序列前注入可学习的向量,引导模型关注任务。
-
LoRA/ QLoRA:通过低秩矩阵分解替代部分权重更新,训练效率高且效果突出。
Peft库:https://github.com/huggingface/peft 很方便地实现将普通的HF模型变成用于支持轻量级fine tune的模型。
其中,LoRA是目前最流行,最通用的方法。
3.LoRA 的核心原理
Transformer 中大量参数集中在权重矩阵(W) 上。LoRA 的做法是:
不调整原始权重,而是加一个小的”旁路“(增量矩阵),通过训练这个增量矩阵来间接影响原始权重。在关键位置(如 Attention 的投影矩阵)引入低秩分解矩阵 A、B,使得参数更新部分为:
-
W′=W+ΔW, ΔW=A×B
其中,A负责降维,B负责升维,合在一起就构成了对原始权充的更新ΔW。
初始化时,A采用高斯分布初始化,B初始化全为0。
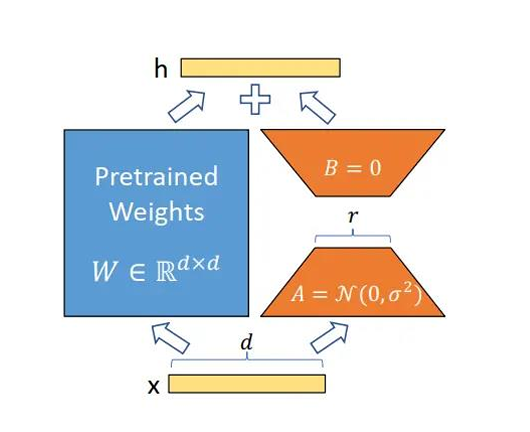
例如,一个 10000×10000 的权重矩阵,全量微调需要 1 亿参数;而 LoRA 若取 rank=8,仅需 1.6 万参数即可完成训练。对于一般任务,通常秩的选取2,4,8,16,如果任务较大,可以增加rank值。
4. LoRA 的优势
-
训练高效:显著降低参数规模,单机即可完成。
-
存储友好:只需保存 LoRA 权重,文件往往仅几十 MB。
-
灵活组合:不同领域的 LoRA 模型可在同一基础模型上加载,快速切换任务。加载不同的LoRA文件模块即可。
-
推理兼容:推理时只需将 LoRA 权重与原始模型合并,不影响原有部署。保留原始大模型的其他能力。
5.QLoRA
LoRA 已经很高效了,但在应对更大规模模型(如 65B 参数的 LLaMA)时,单卡显存仍可能不够。QLoRA 是一种结合了 量化 (Quantization) 与 LoRA 的进一步优化方案,可以在资源受限的场景,微调大模型时考虑。
QLoRA 的关键点:
-
模型量化:将原始大模型参数(通常是 FP16 或 BF16)压缩到 4-bit 或 8-bit 存储,大幅减少显存占用。
-
在量化后的权重上添加 LoRA 模块,仅更新少量低秩参数。
这样做的好处是:
-
极低显存占用:QLoRA 可以在单张消费级 GPU(如 24GB 显存)上微调百亿级参数模型。
-
性能保持良好:通过量化校正和 LoRA 插件,QLoRA 在精度损失上可控,效果接近甚至媲美全量微调。
-
适配更大模型:QLoRA 的出现,让“在家用 GPU 上微调超大模型”成为可能。
| 方法 | 显存占用 | 微调效率 | 支持模型规模 | 精度保留 |
|---|---|---|---|---|
| LoRA | 中等 | 高 | 中等规模模型 | 高 |
| QLoRA | 更低 | 更高 | 百亿级以上 | 较高(轻微下降) |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)