大模型数据准备:从传统数据治理到智能时代的全新工程
大模型的数据准备工作不只是一次性的清洗和特征构造,而是一个贯穿模型全生命周期、涵盖采集、解析、合成、增强、评估、反馈的复杂工程体系。本文将对大模型数据准备的基本内容及其与传统数据准备的差异进行介绍。
在人工智能的快速演进中,大模型已经从实验室的研究,成长为支撑多行业应用的核心基础设施。从对话式客服到代码自动生成,从法律检索到多模态创作,这些能力背后的推动力,远不止模型架构的复杂化和算力的增强。数据——尤其是高质量、覆盖面广、结构合理的数据——才是决定模型性能上限的真正关键。
然而,大模型的数据准备工作与传统机器学习或商业智能(BI)的数据准备有着本质不同。它不只是一次性的清洗和特征构造,而是一个贯穿模型全生命周期、涵盖采集、解析、合成、增强、评估、反馈的复杂工程体系。本文将对大模型数据准备的基本内容及其与传统数据准备的差异进行介绍。
从传统数据准备到大模型数据工程
在传统机器学习和商业智能场景中,数据准备的目标往往明确:支持某个固定的预测任务或生成一组稳定的业务报表。数据来源以企业内部系统为主,经过抽取、清洗、转换(ETL)后,用于特征构造或直接分析。这类工作注重字段一致性、数据准确性和处理效率,流程相对可控且周期固定。
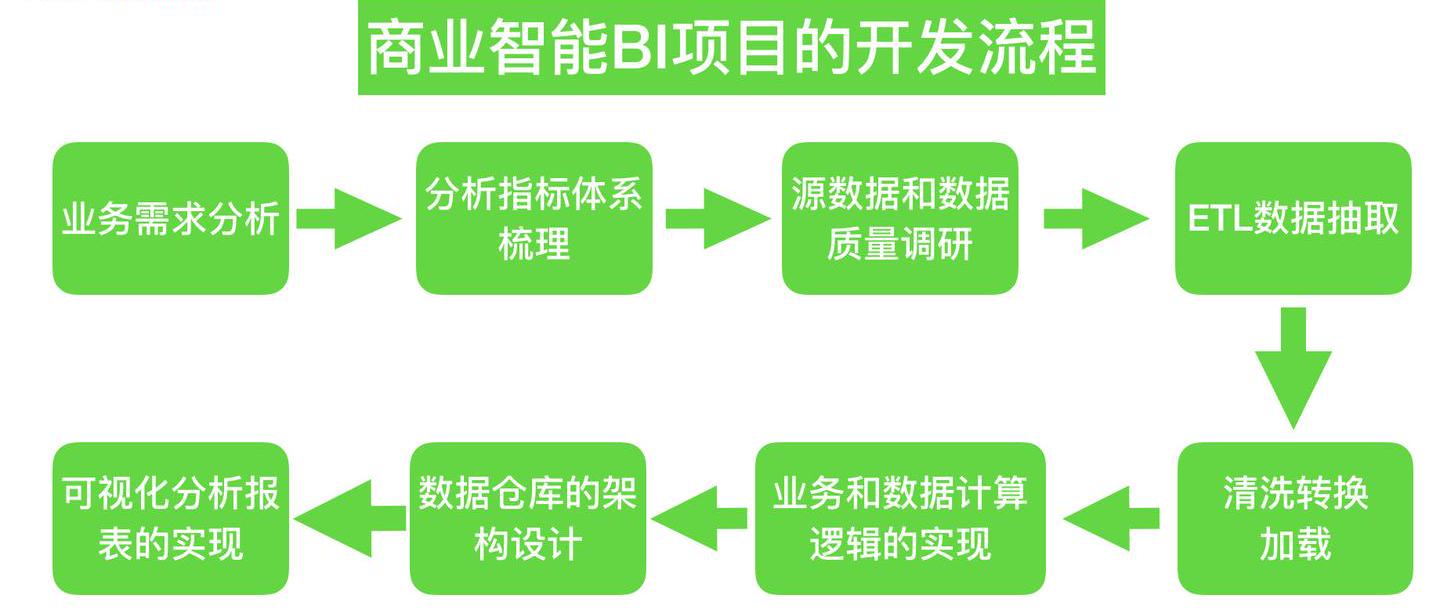
来源:https://zhuanlan.zhihu.com/p/66782423
大模型时代的目标截然不同。一个通用的大模型需要具备跨任务、跨领域的泛化能力,这意味着它必须在训练中接触到尽可能多的语言模式、知识体系和交互场景。数据的来源不再局限于单一领域,而是遍及互联网、开源代码库、科学论文、社交对话、音视频资料等多种模态。数据准备不再是一次性的前处理,而是伴随模型全生命周期的持续工程,涵盖采集、解析、构建、合成、增强、评估和反馈等多个阶段。这种转变,使得大模型数据准备不仅在规模上远超传统项目,更在方法论上形成了全新的体系。
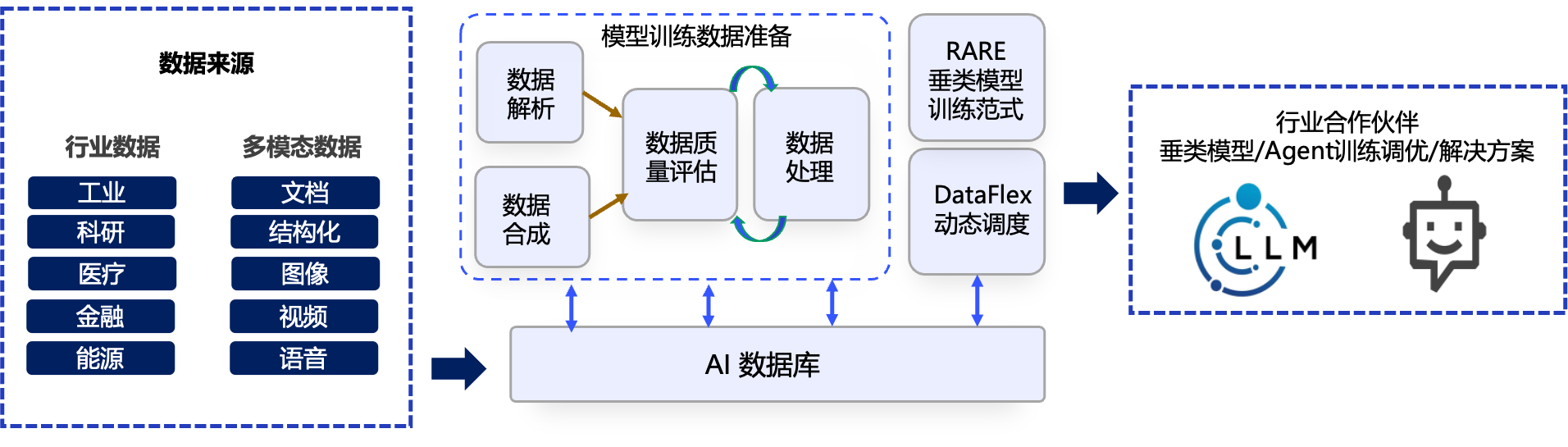
DataFlow 数据准备架构
大模型数据准备的阶段与特征
大模型训练的数据准备是一个复杂且关键的过程,通常可以分为以下几个主要阶段,每个阶段都有其独特的特征和要求:
1. 数据采集与构建
大模型的“知识基石”始于大规模数据采集。与传统 ML/BI 主要从结构化数据库中提取记录不同,大模型需要处理各种格式与模态的原始数据,比如百科文章、新闻报道、在线论坛、源代码、多语言文档、图片配文、视频字幕等。
在构建过程中,除了合规性审核(版权、隐私、敏感信息),还需解决格式异构和内容冗余的问题。采集的结果往往是一个庞杂的原始语料池,为后续解析与清理奠定基础。
2. 解析与清洗
解析是大模型数据准备的核心步骤之一,它不仅涉及格式化,更包含对结构与语义的提取。例如,从网页中分离正文和导航信息,从 PDF 中识别表格和公式,从图片中提取对应的描述性文字。多模态数据还需进行对齐,确保不同模态间内容语义一致。
清洗环节则在剔除无用信息的同时,修正错误、去除重复、统一编码和标点风格,并对涉及个人隐私的内容进行脱敏。这些操作直接影响到模型的“语言纯度”和后续训练的稳定性。
3. 数据合成与增强
即使采集了规模庞大的数据,仍会出现数据无法覆盖所有领域与场景。为填补空白并提升多样性,数据团队会利用规则模板、脚本程序或其他模型生成新的样本。例如,将已有的问答对改写成不同表达方式,生成多轮对话,或为稀有语言和专业领域自动扩充语料。在代码、数学、科学等专业任务中,还会设计特定的合成策略,确保模型在这些场景下的表现不会落后。
相比传统数据准备中有限的特征扩充,这里的增强更强调“语义空间的拓展”,让模型在面对不熟悉的问题时依然有参照经验。
4. 质量评估与反馈闭环
在传统 BI/ML 项目中,数据质量多以缺失率、异常值比例等静态指标衡量;而大模型的数据评估必须结合模型表现进行动态判断。自动化指标(如困惑度)、专项测试集和人工评审相结合,既考察数据的语言流畅度、事实准确性,也检验它是否能帮助模型完成复杂任务。
评估结果会直接反哺数据准备流程。例如,发现模型在法律条文问答上表现不佳,就会定向采集法律文档或生成相关指令响应对;如果在某个小语种翻译中频繁出错,则会补充该语言的高质量平行语料。这种持续循环,使数据与模型共同进化。
大模型数据准备 VS. 传统数据治理
大模型数据准备与传统 ML/BI 数据治理的区别,不仅体现在规模和多样性上,更在于整个工作逻辑与目标导向的不同:
|
传统数据治理 |
大模型数据准备 |
|
|
目标范围 |
面向单一任务,数据准备是一次性的 |
面向开放任务,数据准备是持续迭代的工程 |
|
数据形态 |
以结构化为主,格式统一 |
以非结构化和多模态为主,格式高度多样化 |
|
处理深度 |
传统数据清洗多停留在字段和数值层面 |
需深入到语义解析、跨模态对齐和语境一致性 |
|
质量评估 |
依赖静态质量指标,如完整性、一致性、及时性等等 |
必须结合任务表现进行动态评估,并基于反馈调整数据策略 |
|
合规风险 |
传统数据多来自内部系统,合规风险可控 |
大模型数据大量来自公共网络,需重点防范版权、隐私和安全问题。 |
以上这些差异意味着,大模型数据准备既是技术工程,也是战略资源管理。它要求团队在数据科学、自然语言处理、多模态理解、法律合规、内容安全等方面形成跨学科协作能力。
未来的挑战与趋势
随着可直接采集的高质量网络数据逐渐趋于饱和,大模型数据准备正面临几个长期挑战。首先是稀缺领域的高质量数据获取,这将促使更多机构投入到人工生产数据和模型生成数据的方向;其次是防止“模型坍缩”——过度使用模型自生成数据可能导致语料分布单一、知识退化;再者,全球范围内的数据合规监管日趋严格,跨境数据流动、版权争议、内容审查都将成为日常议题。
未来,大模型数据准备可能更加自动化,解析、清洗、标注、合成等环节将由 AI 管道驱动,但对数据策略的整体设计和质量把关仍离不开人工主导。随着模型架构与算力水平日趋同质化,只有够长期掌握并持续优化高质量、多样化、可迭代数据资产的组织,才可能在智能时代构筑持久的竞争壁垒。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 39
39 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)