Dify之插件开发之Crawl4ai 爬虫(简单逻辑实现)
本文介绍了基于Crawl4ai开发的网页爬虫插件实现过程。通过配置CrawlerRunConfig设置爬取深度(2级)、域名限制和最大页面数,使用FilterChain实现URL过滤功能。核心逻辑包括:1) 通过deep_crawl_url函数获取目标网页内容;2) 使用正则表达式提取符合条件的HTML链接;3) 通过关键字参数uRLPatternFilter进行URL过滤。插件支持批量URL爬取
背景:
前面2篇已经大致介绍了Dify插件开发及插件授权校验,这篇我们将基于Crawl4ai实现输入网址和网址路径过滤,输出符合条件的页面URL集合的简单爬虫
材料:
1、完备的开发环境
2、预安装Crawl4ai环境(Installation - Crawl4AI Documentation (v0.7.x))
制作:
编写代码:
1、在 tools 目录下面创建一个Crawl4ai爬虫的实现核心逻辑deep_crawl_example.py
1.1、实现如下逻辑
async def deep_crawl_url(url, uRLPatternFilter):
async with AsyncWebCrawler() as crawler:
# Start crawling and follow links dynamically
results = await crawler.arun(url, config=config)
# 使用正则表达式提取所有链接
def extract_links(results, uRLPatternFilter):
"""从HTML中提取所有链接"""
returnlinks = [
link for link in results[0].links['internal']
if str(link['href']).endswith(('.htm', '.html')) and
any(keyword in str(link).lower()
for keyword in uRLPatternFilter)
]
# return list(set(all_urls)) # 去重
return returnlinks
links = extract_links(results, uRLPatternFilter)
print(f"Discovered and crawled {len(links)} pages")
return links本函数通过输入url,uRLPatternFilter 2个参数简单实现了Cawl4ai 爬取网站页面内容并从众多URL中根据uRLPatternFilter 条件过滤出符合条件的URL。
1.2、await crawler.arun(url, config=config) 中的config 函数的实现如下
# Configure a 2-level deep crawl
config = CrawlerRunConfig(
deep_crawl_strategy=BFSDeepCrawlStrategy(
max_depth=0, # Crawl 2 levels deep
include_external=False, # Stay within domain
max_pages=50, # Limit for efficiency
filter_chain=filter_chain
),
verbose=True
)说明:该参数的配置请参阅官方文档(Browser, Crawler & LLM Config - Crawl4AI Documentation (v0.7.x))
1.3、上面CrawlerRunConfig 配置中涉及到的过滤链函数filter_chain 实现逻辑如下:
# Create a sophisticated filter chain
filter_chain = FilterChain([
# Domain boundaries
DomainFilter(
allowed_domains=["www.mof.gov.cn"],
blocked_domains=["old.docs.example.com"]
),
])1.4、整个实现如下:
# Deep crawling example: Explore a website dynamically
from crawl4ai import AsyncWebCrawler, CrawlerRunConfig
from crawl4ai.deep_crawling import BFSDeepCrawlStrategy
from crawl4ai.markdown_generation_strategy import DefaultMarkdownGenerator
from crawl4ai.deep_crawling.filters import (
FilterChain,
DomainFilter,
)
# Create a sophisticated filter chain
filter_chain = FilterChain([
# Domain boundaries
DomainFilter(
allowed_domains=["www.mof.gov.cn"],
blocked_domains=["old.docs.example.com"]
),
])
# Configure a 2-level deep crawl
config = CrawlerRunConfig(
deep_crawl_strategy=BFSDeepCrawlStrategy(
max_depth=0, # Crawl 2 levels deep
include_external=False, # Stay within domain
max_pages=50, # Limit for efficiency
filter_chain=filter_chain
),
verbose=True
)
md_generator = DefaultMarkdownGenerator(
options={
"ignore_links": True,
"escape_html": True,
"ignore_images": True
}
)
config2 = CrawlerRunConfig(
deep_crawl_strategy=BFSDeepCrawlStrategy(
max_depth=0, # Crawl 2 levels deep
include_external=False, # Stay within domain
max_pages=50, # Limit for efficiency
filter_chain=filter_chain
),
verbose=True,
markdown_generator=md_generator
)
async def deep_crawl_url(url, uRLPatternFilter):
async with AsyncWebCrawler() as crawler:
# Start crawling and follow links dynamically
results = await crawler.arun(url, config=config)
# 使用正则表达式提取所有链接
def extract_links(results, uRLPatternFilter):
"""从HTML中提取所有链接"""
returnlinks = [
link for link in results[0].links['internal']
if str(link['href']).endswith(('.htm', '.html')) and
any(keyword in str(link).lower()
for keyword in uRLPatternFilter)
]
# return list(set(all_urls)) # 去重
return returnlinks
links = extract_links(results, uRLPatternFilter)
print(f"Discovered and crawled {len(links)} pages")
return links
2、编辑crawl4ai_api.py
在crawl4ai_api.py 页面添加新的异步函数crawl4ai_get_page_url(self, urls, keywords)
async def crawl4ai_get_page_url(self, urls, keywords):
# TODO 实现系列逻辑,具体内容下一篇讲解
urls = urls.split(',') if urls else []
print("urls:", urls)
uRLPatternFilter = keywords.split(',') if keywords else []
print("uRLPatternFilter:", uRLPatternFilter)
linkobjs = await asyncio.gather(*[crawl.deep_crawl_url(url, uRLPatternFilter) for url in urls])
return linkobjs说明:这里通过python的协程函数asyncio来试下批量异步实现的。
3、编辑tools目录下的crawl4ai.py 函数
3.1 在crawl4ai.py函数_invoke 中添加如下代码片段用于接收参数:
# 2. 获取工具输入参数
p_url = tool_parameters.get("p_url", "") # 使用 .get 提供默认值
p_filter_keyword = tool_parameters.get("p_filter_keyword", "")
if not p_url:
raise Exception("URL参数内容不能为空。")
if not p_filter_keyword:
raise Exception("关键字参数不能为空,负责数据量太大。")3.2、在tools目下的crawl4ai.yaml 中添加p_url、p_filter_keyword 2个字符串参数
- name: p_url
type: string
required: true
label:
en_US: url('url1,url2,url3')
zh_Hans: 网址(网址1,网址2,网址3...)
human_description:
en_US: "A web page URL crawler tool developed based on crawl4ai"
zh_Hans: "一个基于crawl4ai开发的网页URL爬取器工具"
llm_description: "A web page URL crawler tool developed based on crawl4ai"
form: llm
- name: p_filter_keyword
type: string
required: true
label:
en_US: keyword('a,b,c..')
zh_Hans: 关键字(‘a,b,c...’)
human_description:
en_US: "For webpages crawled from URLs, the tool filters URLs based on this keyword."
zh_Hans: "URL爬取的网页,工具依据该关键字对URL进行过滤。"
llm_description: "For webpages crawled from URLs, the tool filters URLs based on this keyword."
form: llm3.3、crawl4ai.yaml 页面全部内容
identity:
name: "crawl4ai"
author: "******"
label:
en_US: "crawl4ai"
zh_Hans: "crawl4ai 爬虫工具"
description:
human:
en_US: "Customized crawler service developed using the crawl4ai tool."
zh_Hans: "采用crawl4ai工具开发的定制化爬虫服务。"
llm: "A tool that takes a url and keyword, then publishes it as a new page on crawl4ai, returning the URL of the published page. Use this when the user wants to publish formatted text content publicly via crawl4ai."
parameters:
- name: p_url
type: string
required: true
label:
en_US: url('url1,url2,url3')
zh_Hans: 网址(网址1,网址2,网址3...)
human_description:
en_US: "A web page URL crawler tool developed based on crawl4ai"
zh_Hans: "一个基于crawl4ai开发的网页URL爬取器工具"
llm_description: "A web page URL crawler tool developed based on crawl4ai"
form: llm
- name: p_filter_keyword
type: string
required: true
label:
en_US: keyword('a,b,c..')
zh_Hans: 关键字(‘a,b,c...’)
human_description:
en_US: "For webpages crawled from URLs, the tool filters URLs based on this keyword."
zh_Hans: "URL爬取的网页,工具依据该关键字对URL进行过滤。"
llm_description: "For webpages crawled from URLs, the tool filters URLs based on this keyword."
form: llm
extra:
python:
source: tools/crawl4ai.py
4、在crawl4ai.py函数_invoke 中继续实现爬虫逻辑--执行爬取操作:
# 3. 调用库执行操作
try:
crawl = asyncio.run(Crawl4aiAPI(access_token).crawl4ai_get_page_url(p_url, p_filter_keyword))
# print(crawl)
except Exception as e:
raise Exception(f"调用 Crawl4ai API 失败: {e}")5、在crawl4ai.py函数_invoke 中继续实现爬虫逻辑--通过生成器函数yield 实现内容的返回
# 4. 返回结果
yield self.create_text_message(str(crawl))6、tools 下crawl4ai.py 完整代码:
from collections.abc import Generator
from typing import Any
from .crawl4ai_api import Crawl4aiAPI
from dify_plugin import Tool
from dify_plugin.entities.tool import ToolInvokeMessage
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
class Crawl4aiTool(Tool):
def _invoke(self, tool_parameters: dict[str, Any]) -> Generator[ToolInvokeMessage]:
"""
根据输入的标题和内容,创建一个新的 Telegraph 页面。
Args:
tool_parameters: 一个包含工具输入参数的字典:
- p_url (str): 带爬取网页URL。
- p_filter_keyword (str): 带爬取网页中URL过滤关键字。
Yields:
ToolInvokeMessage: 包含成功爬取URL列表。
Raises:
Exception: 如果页面创建失败,则抛出包含错误信息的异常。
"""
# 1. 从运行时获取凭证
try:
access_token = self.runtime.credentials["crawl4ai_access_token"]
# 我们可以在这里进行access_token更为复杂的校验,也许是进行远程服务端的校验.
print('access_token', access_token)
except KeyError:
raise Exception("Crawl4ai Access Token 未配置或无效。请在插件设置中提供。")
# 2. 获取工具输入参数
p_url = tool_parameters.get("p_url", "") # 使用 .get 提供默认值
p_filter_keyword = tool_parameters.get("p_filter_keyword", "")
if not p_url:
raise Exception("URL参数内容不能为空。")
if not p_filter_keyword:
raise Exception("关键字参数不能为空,负责数据量太大。")
# 3. 调用库执行操作
try:
crawl = asyncio.run(Crawl4aiAPI(access_token).crawl4ai_get_page_url(p_url, p_filter_keyword))
# print(crawl)
except Exception as e:
raise Exception(f"调用 Crawl4ai API 失败: {e}")
# 4. 返回结果
yield self.create_text_message(str(crawl))
# yield crawl6、至此,插件爬虫逻辑开发完成
调试代码:
1、运行main.py函数

2、进入DIfy 页面的工作室,
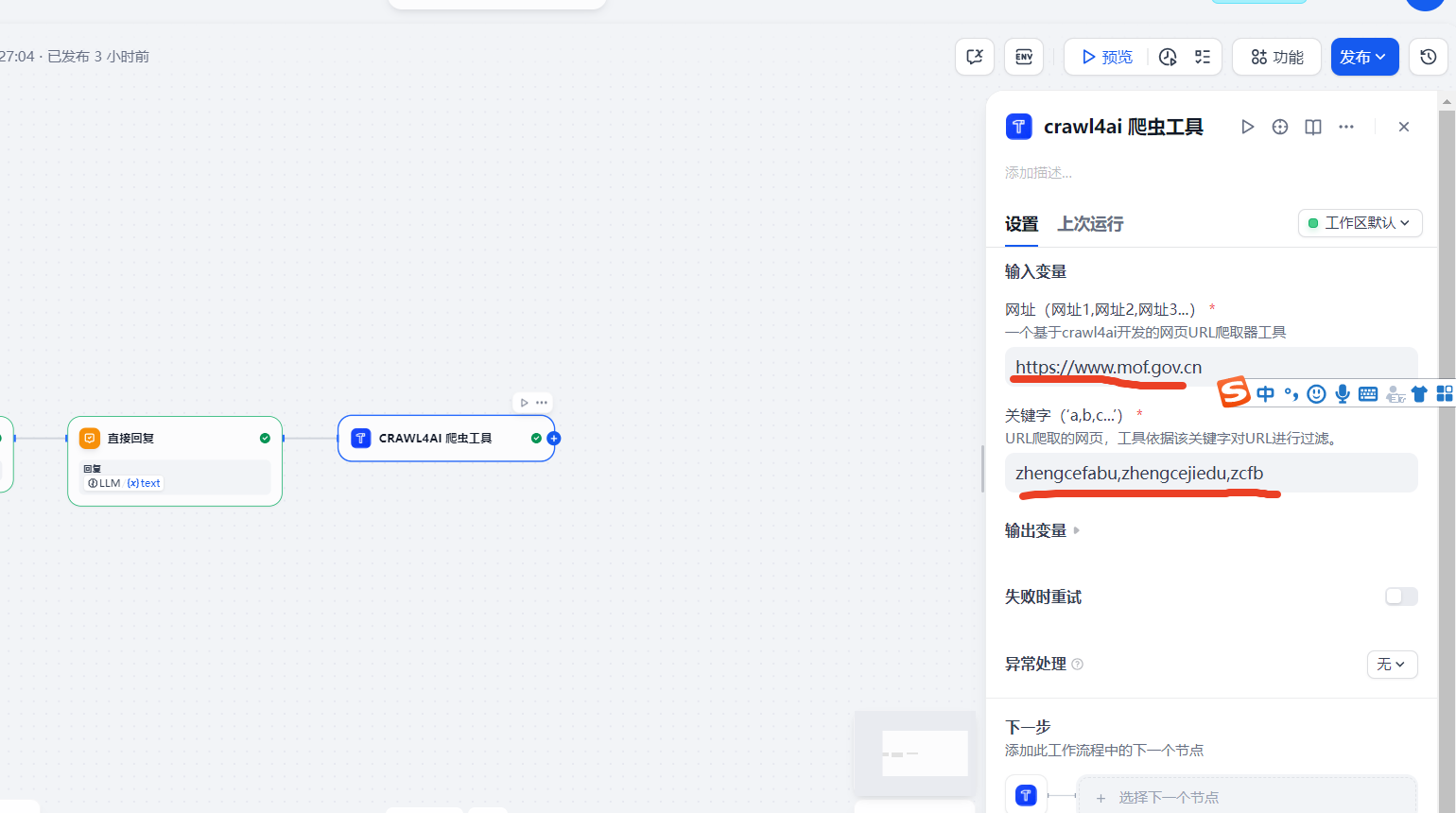
3、修改插件的参数值方便测试
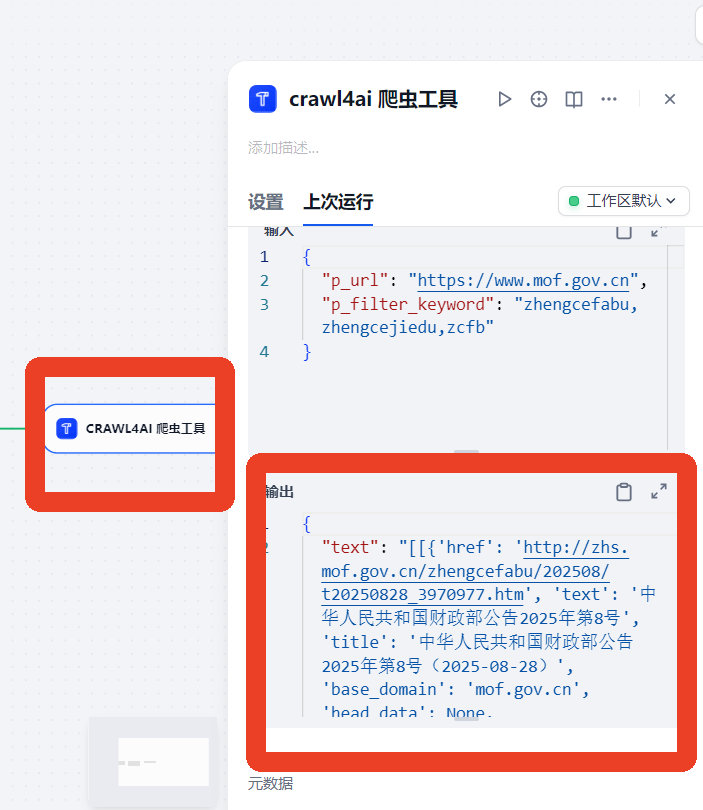
4、预览即可进行测试
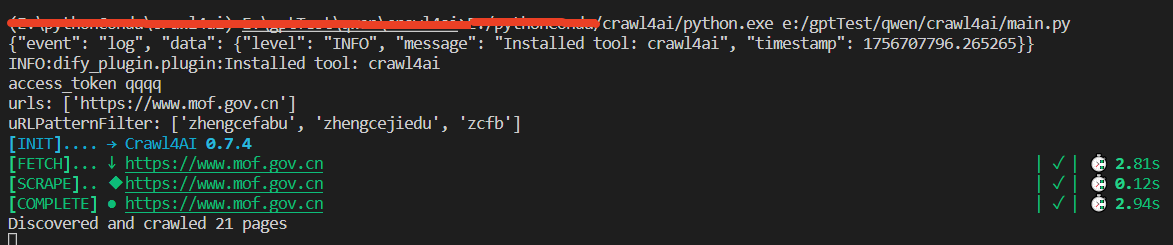
5、编译器后台:
6、至此,整个插件的开发与测试环节完成
插件打包:
鉴于篇幅因素考虑下篇继续

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)