让AI不再胡说八道的利器:RAG
RAG(检索增强生成)技术通过结合检索与生成能力,有效解决大语言模型(LLM)的三大痛点:幻觉问题、知识滞后和专业领域不足。其工作流程包含索引化、检索和生成三阶段,将文档分块并向量化存储,检索时匹配最相关内容辅助LLM生成准确回答。RAG技术经历了朴素RAG、高级RAG到模块化RAG的演进,目前可通过文档分块策略(如递归智能切分)和向量化技术(如阿里百炼平台的Embedding服务)实现,让AI回
书接上回
在我们前面三篇文章中,我们了解了大语言模型的基本原理和应用。今天我们来聊聊一个让AI变得更加靠谱的技术——RAG。
想象一下这样的场景:你问ChatGPT关于你们公司最新的请假制度,它一本正经地给你编了一套看似合理的流程,但实际上完全不符合你们公司的实际情况。或者你询问最新发生的新闻事件,它却告诉你"我的知识截止到某某时间,无法回答"。这些问题的根源在于大语言模型本身存在一些天然的局限性。
为什么我们需要RAG?
LLM的三大"硬伤"
第一个问题:爱"编故事"的幻觉现象
LLM有时候会像一个爱编故事的朋友,说得头头是道,但仔细一查却发现是假的。这种现象叫做"幻觉"。比如你问它某个具体的历史事件,它可能会编造出一个听起来很合理但完全不存在的故事。
为什么会这样?主要有两个原因:
- 训练数据本身有问题:互联网上的信息鱼龙混杂,有真实的新闻报道,也有虚构的小说情节,甚至还有各种谣言。AI在学习时无法区分这些内容的真假,统统当作"知识"记住了。
- 生成方式的局限:LLM本质上是在玩"接龙游戏",它会选择在语法和语义上最符合上下文的词汇,而不是最真实的内容。当遇到不确定的问题时,它倾向于用听起来合理的话来"填空"。
第二个问题:知识更新跟不上时代
技术发展日新月异,但LLM的知识却像是凝固在某个时间点的照片。比如ChatGPT-4的知识截止到2024年10月,DeepSeek V3截止到2024年7月。这意味着它们对之后发生的事情一无所知。在快速变化的技术领域,这个问题尤其突出。
第三个问题:专业领域知识不够深入
LLM虽然博学,但往往是"万金油"式的博学。它对常见话题了解不少,但面对专业领域的深度问题时就显得力不从心了。这就像一个什么都知道一点但没有专业特长的人,在专业讨论中很难提供有价值的见解。
更要命的是,LLM完全不知道你们公司内部的情况——人事关系、工作流程、内部文档等等,这些对你来说最重要的信息,它一概不知。
RAG技术的诞生正是为了解决这些痛点——让AI变得更加事实可靠、知识及时、专业深入。
RAG是什么?
RAG的全称是"Retrieval Augmented Generation",直译过来就是"检索增强生成"。听起来有点拗口,但其实概念很简单——它就像是给AI配了一个"外挂"搜索引擎。
用一个生活化的比喻来理解:普通的LLM就像是一个凭记忆回答问题的学生,而RAG版本的LLM则像是允许开卷考试的学生。当遇到问题时,它可以先翻书查资料,然后基于找到的资料来组织答案。
比如,你问LLM关于公司内部的请假流程,普通LLM只能根据它训练时见过的通用信息来猜测,而RAG系统会先在你们公司的员工手册中搜索相关内容,然后基于真实的政策来回答你的问题。
RAG的工作流程
RAG的工作过程可以分为三个核心步骤:
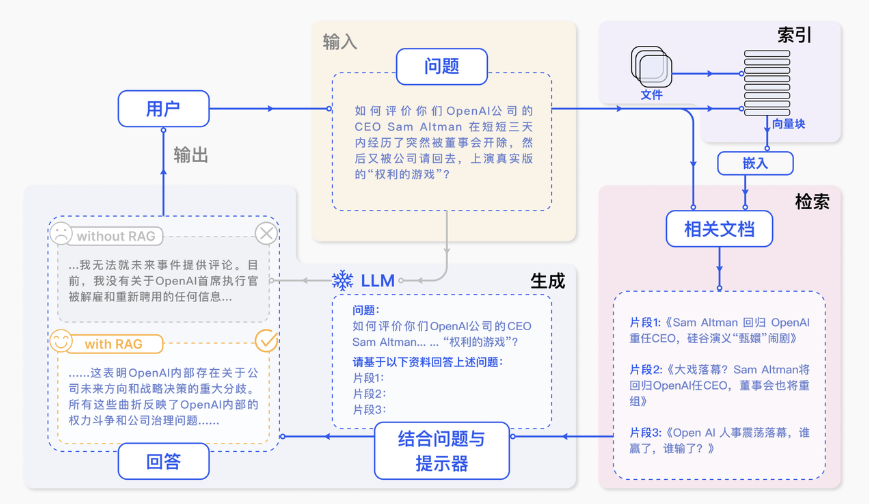
1. 索引化(准备阶段)
就像图书馆需要建立索引一样,RAG系统需要将文档切分成小段落,然后转换成计算机能理解的"向量"形式,存储在专门的向量数据库中。这个过程只需要做一次,就像给图书馆的每本书贴上标签。
2. 检索(查找阶段)
当用户提出问题时,系统会把问题也转换成向量,然后在数据库中找到最相关的几个文档片段。这就像是根据关键词在图书馆中找到最相关的几本书。
3. 生成(回答阶段)
系统将原始问题和检索到的相关文档一起输入给LLM,让它基于这些真实材料来生成答案。这确保了回答既准确又相关。
RAG技术的演进历程
RAG技术从诞生到现在,经历了三个主要的发展阶段:
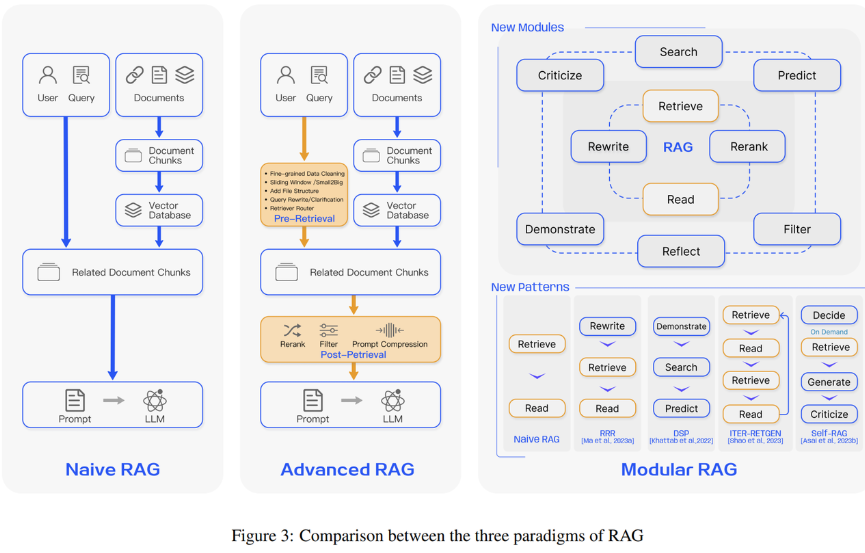
朴素RAG(Naive RAG)
这是最基础的版本,就是我们刚才描述的三步骤流程。虽然简单,但已经能解决很多实际问题。
高级RAG(Advanced RAG)
在实际应用中,人们发现简单的三步骤还不够精准。高级RAG在检索前后都加入了优化策略,比如对查询问题进行改写,对检索结果进行重新排序等,就像是给搜索引擎加上了更智能的算法。
模块化RAG(Modular RAG)
最新的发展方向是将整个流程拆分成可灵活组合的模块,不同的应用场景可以选择不同的模块组合。比如:
- 分层过滤:先粗筛出大概相关的内容,再精筛出最相关的部分,就像是先按类别找书,再按具体主题找章节。
- 动态权重调整:根据不同的应用场景调整搜索策略,法律咨询更看重准确性,创意写作更看重相关性。
动手实践:朴素RAG系统
了解了RAG的基本概念,我们来看看最经典的朴素RAG是如何工作的。虽然叫"朴素",但它已经能解决很多实际问题,就像是RAG技术的"Hello World"。
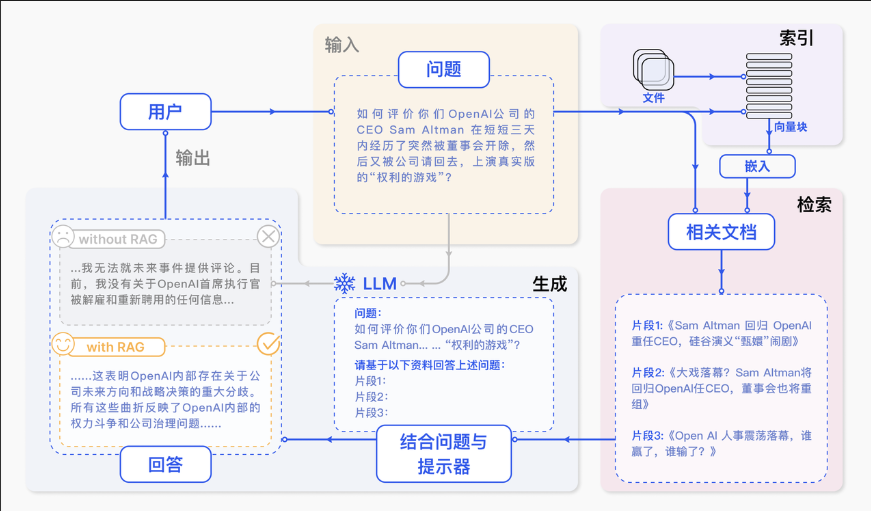
朴素RAG包含我们之前提到的三个核心步骤:索引化、检索和生成。让我们深入了解每个环节的技术细节。
第一步:索引化——为知识建档案
索引化是整个RAG系统的基础,就像是为图书馆的每本书建立详细的档案。这个过程包含两个关键环节:文档分块和向量化。
文档分块:化整为零的艺术
想象一下,如果把一整本《红楼梦》直接喂给AI,它肯定会"消化不良"。所以我们需要把长文档切分成合适大小的小块,这就是文档分块的目的。
常见的分块策略有以下几种:
策略一:按句子切分
这是最自然的方式,按照句号、问号、感叹号等标点符号来划分。
text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。"
# 正则表达式匹配中文句子结束的标点符号
sentences = re.split(r'(。|?|!|\..\..)', text)
这种方法的优点是保持了语义的完整性,每个块都是完整的句子。但缺点是块的大小不均匀,有些句子很长,有些很短。
策略二:按固定字符数切分
就像切豆腐一样,按照固定的字符数来划分文档。
text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。"
# 假设我们按照每10个字符来切分文本
chunks = split_by_fixed_char_count(text, 10)
这种方法确保了块的大小一致,但可能会把一个词或句子切断,影响语义理解。
策略三:重叠窗口切分
这是对固定字符数切分的改进,在相邻的块之间保留一些重叠内容,就像拍照时的连拍模式。
text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。"
chunks = sliding_window_chunks(text, 20, 10) # 20个字符的块,重叠10个字符
这样做的好处是,即使一个重要概念被切断了,在下一个块中也能找到完整的内容。
策略四:递归智能切分
这是目前最常用的方法,结合了前面几种策略的优点。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text = """
自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=50, # 目标块大小
chunk_overlap=10, # 重叠字符数
length_function=len,
)
chunks = splitter.split_text(text)
这个方法很聪明:它会先尝试按段落分割,如果段落太长,就按句子分割,如果句子还是太长,就按词语分割。这样既保证了块的大小合适,又尽可能保持了语义的完整性。
向量化:让计算机"理解"文字
完成文档分块后,下一步就是将这些文字转换成计算机能够理解和计算的形式——向量。这个过程叫做Embedding(嵌入),是RAG系统的核心技术之一。
什么是向量?
向量在数学中指具有大小和方向的量,可以想象成一个带箭头的线段。在AI领域,我们用向量来表示文字的"语义特征"。比如"苹果"这个词可能被表示为[0.2, -0.1, 0.8, …]这样一组数字。
为什么要用向量?
因为计算机只认识数字,不认识文字。但更神奇的是,经过训练的模型能够确保语义相近的文字在向量空间中距离也更近。比如"苹果"和"水果"的向量会比"苹果"和"汽车"的向量更接近。
想象一个三维空间,“苹果”、“橙子”、“香蕉"这些水果类词汇会聚集在一个区域,而"汽车”、“飞机”、"火车"这些交通工具会聚集在另一个区域。当你问关于水果的问题时,系统能快速找到水果相关的文档片段。
Embedding的应用范围
不仅是文字可以做Embedding,图像、音频、视频都可以。在不同领域:
- 文本Embedding:捕捉词语间的语义和语法关系
- 图像Embedding:表示图像的视觉特征
- 商品Embedding:用于推荐系统,表示商品特性
如何获得Embedding?
好消息是,我们不需要自己训练模型。现在有很多现成的Embedding服务可以直接使用,比如阿里百炼平台提供的向量模型:
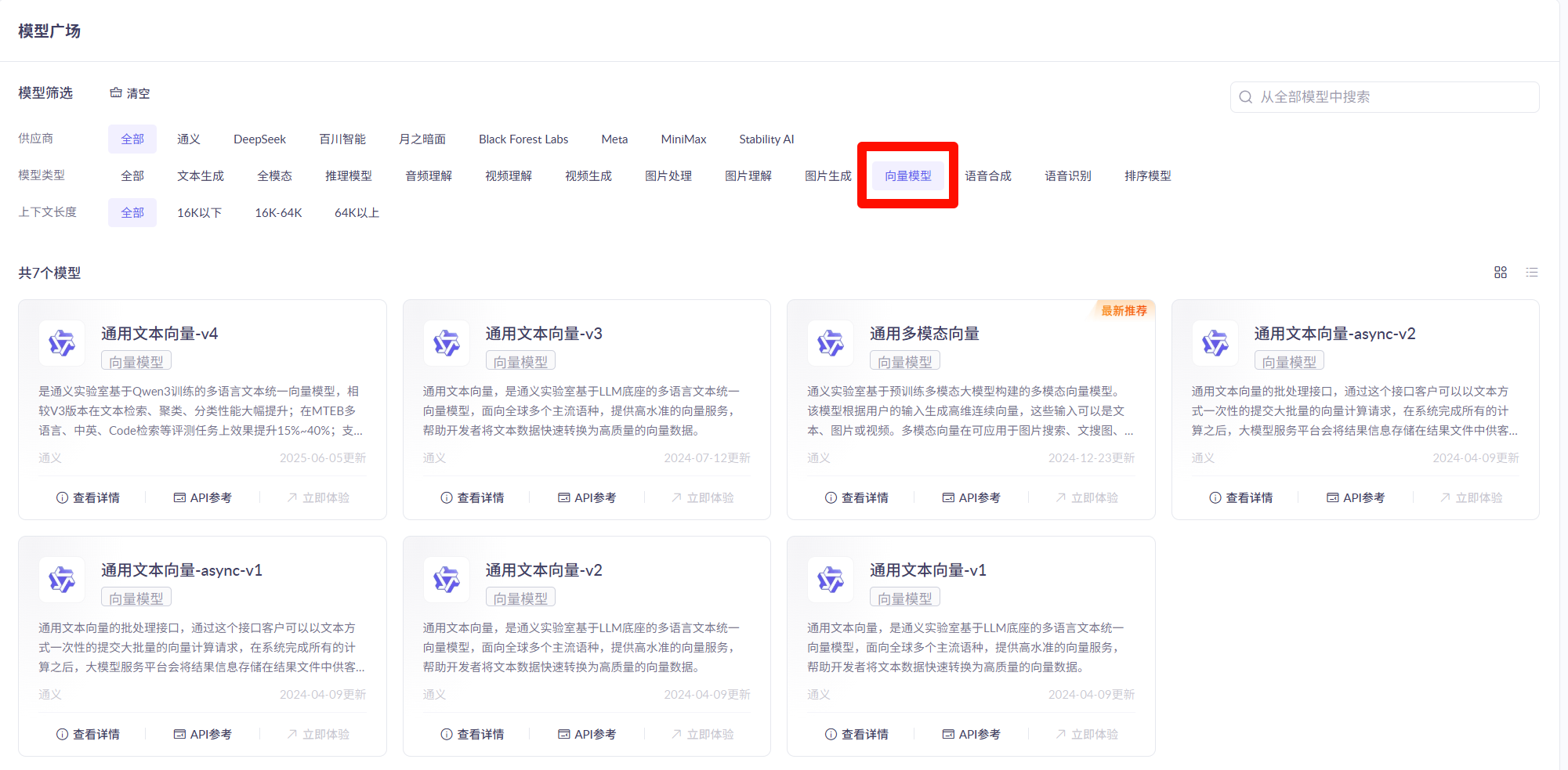
使用起来很简单,只需要几行代码:
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 将文本转换为向量
completion = client.embeddings.create(
model="text-embedding-v4",
input=['风急天高猿啸哀', '渚清沙白鸟飞回', '无边落木萧萧下', '不尽长江滚滚来'],
dimensions=1024, # 向量维度
encoding_format="float"
)
API会返回每句话对应的1024维向量:
{
"data": [
{
"embedding": [0.023456, -0.012345, 0.056789, ..., -0.022334],
"index": 0,
"object": "embedding"
},
// ... 其他句子的向量
],
"model": "text-embedding-v4",
"usage": {
"prompt_tokens": 28,
"total_tokens": 28
}
}
每个embedding数组包含1024个浮点数,这就是文本的向量表示。虽然我们人类看不懂这些数字的含义,但对于计算机来说,这些数字精确地编码了文本的语义信息。
向量相似度计算:找到最匹配的内容
有了向量表示后,下一个问题是:如何判断两个向量是否相似?这就需要用到相似度计算。
想象你在一个巨大的图书馆里找书,你手里有一张纸条写着"我想了解人工智能",图书馆的每本书也都有一张类似的纸条描述内容。你需要找到和你的纸条最相似的那些书。在向量世界里,这个"相似度比较"就是数学计算。
余弦相似度:看方向,不看大小
余弦相似度是RAG系统中最常用的相似度计算方法。它的核心思想是:只关心两个向量的"方向"是否一致,而忽略"长度"差异。
就像两个人都在指向同一个方向,一个人胳膊长一点,一个人胳膊短一点,但他们指向的方向是一样的。在向量空间中,方向相同意味着语义相近。
- 余弦值为1:完全相同的语义
- 余弦值为0:完全无关的内容
- 余弦值为-1:完全相反的语义
欧式距离:看位置,重大小
欧式距离更像是在地图上测量两点之间的直线距离。它不仅考虑方向,还考虑向量的大小(长度)。
这种方法在某些场景下很有用,比如当文档的"重要程度"或"权重"需要考虑在内时。但在大多数文本检索场景中,余弦相似度更常用,因为我们更关心语义相关性而不是文本长度。
向量数据库:为海量向量找个家
传统数据库存储的是结构化数据(如姓名、年龄、地址),而向量数据库专门存储和检索向量数据。你可以把它想象成一个超级智能的仓库管理员,能够在数百万个向量中瞬间找到最相似的那几个。
为什么需要专门的向量数据库?
普通数据库在处理向量时会遇到几个问题:
- 效率低下:在百万级向量中找相似向量,传统数据库会很慢
- 功能缺失:缺乏专门的相似度计算和向量索引功能
- 扩展性差:随着数据量增长,性能急剧下降
主流向量数据库对比
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Chroma | 轻量级,易上手,Python友好 | 个人项目、原型开发、学习RAG |
| Pinecone | 云服务,免运维,性能优秀 | 商业项目、快速上线 |
| Milvus | 开源,高性能,支持大规模部署 | 企业级应用、需要自部署 |
| Faiss | Facebook开源,算法丰富 | 研究项目、算法优化 |
对于初学者和中小型项目,我推荐从Chroma开始,它足够简单且功能完整。
第二步和第三步:检索与生成
完成索引化后,RAG系统就具备了"记忆"能力。接下来当用户提问时,系统会:
- 检索阶段:将用户问题转换为向量,在向量数据库中找到最相关的文档片段
- 生成阶段:将问题和检索到的文档一起发送给LLM,生成基于事实的回答
这就像是一个有准备的学生在考试:先翻书找相关内容,然后基于找到的资料组织答案。
让我们通过一个ChromaDB的实际例子来看看这个过程:
import chromadb
from chromadb.config import Settings
from openai import OpenAI
from dotenv import load_dotenv
import os
class VectorDBDemo:
def __init__(self, collection_name="health_qa"):
# 初始化Chroma客户端
self.client = chromadb.Client(Settings(allow_reset=True))
self.collection = self.client.get_or_create_collection(name=collection_name)
# 初始化嵌入模型客户端
load_dotenv()
self.embedding_client = OpenAI(
api_key=os.getenv("api_key"),
base_url=os.getenv("base_url")
)
def get_embeddings(self, texts, model="text-embedding-v3"):
# 生成文本嵌入向量
return [x.embedding for x in self.embedding_client.embeddings.create(input=texts, model=model).data]
def add_sample_data(self):
# 示例健康问答数据
questions = [
"如何预防感冒?",
"高血压的症状有哪些?",
"糖尿病饮食注意事项",
"如何缓解头痛?",
"皮肤过敏怎么办?"
]
answers = [
"预防感冒:勤洗手、适当运动、保证睡眠、均衡饮食、避免接触病毒",
"高血压症状:头晕、头痛、心悸、胸闷、视力模糊等",
"糖尿病饮食:控制总热量、少食多餐、选择低糖食物、增加纤维摄入",
"头痛缓解:充足休息、按摩太阳穴、热敷、避免压力、适量饮水",
"皮肤过敏处理:停用致敏物、冷敷缓解、使用抗过敏药物、就医检查"
]
# 向量化并存储
embeddings = self.get_embeddings(questions)
self.collection.add(
embeddings=embeddings,
documents=answers,
ids=[f"qa_{i}" for i in range(len(questions))]
)
print(f"已添加 {len(questions)} 条健康问答数据")
def search(self, query, n_results=2):
# 检索相似文档
results = self.collection.query(
query_embeddings=self.get_embeddings([query]),
n_results=n_results
)
return results['documents'][0]
# 使用示例
if __name__ == '__main__':
# 初始化向量数据库
vector_db = VectorDBDemo()
# 添加示例数据
vector_db.add_sample_data()
# 测试检索
user_query = "我经常头疼怎么办?"
print(f"\n用户问题:{user_query}")
print("检索结果:")
for i, doc in enumerate(vector_db.search(user_query), 1):
print(f"{i}. {doc}\n")
实战项目:打造你的个人知识助手
理论学完了,是时候动手实践了!我们来搭建一个基于Obsidian笔记的智能问答系统。
项目背景:知识管理的痛点
相信很多程序员都有这样的经历:用Obsidian、Notion或者其他工具记了大量笔记,但过了一段时间就忘记具体写在哪里了。想找某个技术细节,得在一堆文件中翻来翻去,效率很低。
如果有一个AI助手能够"读懂"你所有的笔记,直接回答你的问题该多好!比如:
- “我之前是怎么解决Redis连接超时问题的?”
- “Java中ArrayList和LinkedList的性能对比是什么?”
- “上次学Spring Boot时记的那些注解都有什么用?”
这就是我们要实现的——一个基于你个人知识库的RAG系统。
系统设计思路
我们的个人知识助手需要具备以下能力:
核心功能
- 全库索引:一次性读取并索引所有markdown笔记
- 智能检索:根据问题快速找到相关笔记片段
- 上下文回答:基于检索到的内容生成准确答案
- 来源追溯:告诉你答案来自哪个文件,方便进一步查阅
技术架构
- 文档处理:支持markdown格式,自动清理格式标记
- 文本分割:智能切分长文档,保持语义完整
- 向量存储:使用ChromaDB作为向量数据库
- 检索生成:结合向量检索和大语言模型
让我们开始动手实现:
步骤一:环境准备和依赖安装
首先安装必要的依赖包:
pip install chromadb openai python-dotenv
步骤二:文档读取模块
我们需要一个函数来读取Obsidian文件夹中的所有markdown文件:
import os
import re
from pathlib import Path
def read_obsidian_vault(vault_path):
"""
递归读取Obsidian知识库中的所有markdown文件
Args:
vault_path: Obsidian知识库的根目录路径
Returns:
list: 包含文件路径和内容的字典列表
"""
documents = []
vault_path = Path(vault_path)
# 递归查找所有.md文件
for md_file in vault_path.rglob("*.md"):
try:
with open(md_file, 'r', encoding='utf-8') as f:
content = f.read()
# 提取纯文本,去除markdown格式
clean_content = clean_markdown(content)
if clean_content.strip(): # 只保存非空内容
documents.append({
'file_path': str(md_file),
'file_name': md_file.name,
'content': clean_content
})
except Exception as e:
print(f"读取文件 {md_file} 时出错: {e}")
continue
return documents
步骤三:文本清理模块
Markdown文件包含很多格式标记,我们需要提取纯文本:
def clean_markdown(text):
"""
清理markdown格式,提取纯文本内容
Args:
text: 原始markdown文本
Returns:
str: 清理后的纯文本
"""
# 去除代码块
text = re.sub(r'```[\s\S]*?```', '', text)
text = re.sub(r'`[^`]*`', '', text)
# 去除链接,保留链接文本
text = re.sub(r'\[([^\]]*)\]\([^\)]*\)', r'\1', text)
# 去除图片标记
text = re.sub(r'!\[([^\]]*)\]\([^\)]*\)', '', text)
# 去除标题标记,保留标题文本
text = re.sub(r'^#+\s*', '', text, flags=re.MULTILINE)
# 去除列表标记
text = re.sub(r'^\s*[-*+]\s*', '', text, flags=re.MULTILINE)
text = re.sub(r'^\s*\d+\.\s*', '', text, flags=re.MULTILINE)
# 去除粗体和斜体标记
text = re.sub(r'\*\*([^*]*)\*\*', r'\1', text)
text = re.sub(r'\*([^*]*)\*', r'\1', text)
# 清理多余的空白字符
text = re.sub(r'\n\s*\n', '\n\n', text)
text = re.sub(r' +', ' ', text)
return text.strip()
步骤四:文档分块模块
长文档需要分割成小块,便于向量化和检索:
def chunk_documents(documents, chunk_size=800, overlap=100):
"""
将文档分割成固定大小的块
Args:
documents: 文档列表
chunk_size: 每块的字符数
overlap: 块之间的重叠字符数
Returns:
list: 分块后的文档片段
"""
chunks = []
for doc in documents:
content = doc['content']
file_info = {
'file_path': doc['file_path'],
'file_name': doc['file_name']
}
# 如果内容较短,直接作为一个块
if len(content) <= chunk_size:
chunks.append({
**file_info,
'content': content,
'chunk_id': 0
})
else:
# 分割长文档
start = 0
chunk_id = 0
while start < len(content):
end = start + chunk_size
chunk_content = content[start:end]
chunks.append({
**file_info,
'content': chunk_content,
'chunk_id': chunk_id
})
# 下一块的起始位置,考虑重叠
start = end - overlap
chunk_id += 1
return chunks
步骤五:向量数据库模块
使用ChromaDB存储和检索文档向量:
import chromadb
from openai import OpenAI
class ObsidianVectorDB:
"""Obsidian知识库的向量数据库管理器"""
def __init__(self, collection_name="obsidian_knowledge"):
# 初始化ChromaDB客户端
self.client = chromadb.Client()
self.collection = self.client.get_or_create_collection(name=collection_name)
# 初始化嵌入模型客户端
self.embedding_client = OpenAI(
api_key=os.getenv("api_key"),
base_url=os.getenv("base_url")
)
def get_embeddings(self, texts):
"""获取文本的向量表示"""
response = self.embedding_client.embeddings.create(
input=texts,
model="text-embedding-v3"
)
return [item.embedding for item in response.data]
def add_documents(self, chunks):
"""将文档块添加到向量数据库"""
if not chunks:
return
# 准备数据
documents = [chunk['content'] for chunk in chunks]
metadatas = [
{
'file_path': chunk['file_path'],
'file_name': chunk['file_name'],
'chunk_id': chunk['chunk_id']
}
for chunk in chunks
]
ids = [f"{chunk['file_name']}_{chunk['chunk_id']}" for chunk in chunks]
# 获取嵌入向量
embeddings = self.get_embeddings(documents)
# 添加到数据库
self.collection.add(
embeddings=embeddings,
documents=documents,
metadatas=metadatas,
ids=ids
)
print(f"成功添加 {len(chunks)} 个文档块到向量数据库")
def search(self, query, top_k=3):
"""根据查询检索相关文档"""
query_embedding = self.get_embeddings([query])[0]
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
return {
'documents': results['documents'][0],
'metadatas': results['metadatas'][0]
}
步骤六:RAG问答系统
整合检索和生成功能:
class ObsidianRAGBot:
"""基于Obsidian知识库的RAG问答机器人"""
def __init__(self, vector_db):
self.vector_db = vector_db
self.llm_client = OpenAI(
api_key=os.getenv("api_key"),
base_url=os.getenv("base_url")
)
# 定义提示模板
self.prompt_template = """
你是一个基于知识库的智能助手。请根据以下提供的知识片段来回答用户的问题。
知识片段:
{context}
用户问题:{question}
回答要求:
1. 优先使用提供的知识片段中的信息
2. 如果知识片段不足以回答问题,请明确说明
3. 保持回答的准确性和相关性
4. 用中文回答
回答:
"""
def chat(self, question, top_k=3):
"""
回答用户问题
Args:
question: 用户问题
top_k: 检索的文档数量
Returns:
str: 回答内容
"""
# 1. 检索相关文档
search_results = self.vector_db.search(question, top_k)
# 2. 构建上下文
context_parts = []
for i, (doc, metadata) in enumerate(zip(search_results['documents'],
search_results['metadatas'])):
context_parts.append(f"片段{i+1}(来源:{metadata['file_name']}):\n{doc}")
context = "\n\n".join(context_parts)
# 3. 构建提示
prompt = self.prompt_template.format(
context=context,
question=question
)
# 4. 调用大语言模型
response = self.llm_client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}],
temperature=0.1
)
return response.choices[0].message.content
完整的使用示例
将所有模块整合在一起:
import os
import re
from pathlib import Path
import chromadb
from openai import OpenAI
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
def read_obsidian_vault(vault_path):
"""递归读取Obsidian知识库中的所有markdown文件"""
documents = []
vault_path = Path(vault_path)
for md_file in vault_path.rglob("*.md"):
try:
with open(md_file, 'r', encoding='utf-8') as f:
content = f.read()
clean_content = clean_markdown(content)
if clean_content.strip():
documents.append({
'file_path': str(md_file),
'file_name': md_file.name,
'content': clean_content
})
except Exception as e:
print(f"读取文件 {md_file} 时出错: {e}")
continue
return documents
def clean_markdown(text):
"""清理markdown格式,提取纯文本内容"""
# 去除代码块
text = re.sub(r'```[\s\S]*?```', '', text)
text = re.sub(r'`[^`]*`', '', text)
# 去除链接,保留链接文本
text = re.sub(r'\[([^\]]*)\]\([^\)]*\)', r'\1', text)
# 去除图片标记
text = re.sub(r'!\[([^\]]*)\]\([^\)]*\)', '', text)
# 去除标题标记,保留标题文本
text = re.sub(r'^#+\s*', '', text, flags=re.MULTILINE)
# 去除列表标记
text = re.sub(r'^\s*[-*+]\s*', '', text, flags=re.MULTILINE)
text = re.sub(r'^\s*\d+\.\s*', '', text, flags=re.MULTILINE)
# 去除粗体和斜体标记
text = re.sub(r'\*\*([^*]*)\*\*', r'\1', text)
text = re.sub(r'\*([^*]*)\*', r'\1', text)
# 清理多余的空白字符
text = re.sub(r'\n\s*\n', '\n\n', text)
text = re.sub(r' +', ' ', text)
return text.strip()
def chunk_documents(documents, chunk_size=800, overlap=100):
"""将文档分割成固定大小的块"""
chunks = []
for doc in documents:
content = doc['content']
file_info = {
'file_path': doc['file_path'],
'file_name': doc['file_name']
}
if len(content) <= chunk_size:
chunks.append({
**file_info,
'content': content,
'chunk_id': 0
})
else:
start = 0
chunk_id = 0
while start < len(content):
end = start + chunk_size
chunk_content = content[start:end]
chunks.append({
**file_info,
'content': chunk_content,
'chunk_id': chunk_id
})
start = end - overlap
chunk_id += 1
return chunks
class ObsidianVectorDB:
"""Obsidian知识库的向量数据库管理器"""
def __init__(self, collection_name="obsidian_knowledge"):
self.client = chromadb.Client()
self.collection = self.client.get_or_create_collection(name=collection_name)
self.embedding_client = OpenAI(
api_key=os.getenv("api_key"),
base_url=os.getenv("base_url")
)
def get_embeddings(self, texts):
"""获取文本的向量表示"""
response = self.embedding_client.embeddings.create(
input=texts,
model="text-embedding-v3"
)
return [item.embedding for item in response.data]
def add_documents(self, chunks):
"""将文档块添加到向量数据库"""
if not chunks:
return
documents = [chunk['content'] for chunk in chunks]
metadatas = [
{
'file_path': chunk['file_path'],
'file_name': chunk['file_name'],
'chunk_id': chunk['chunk_id']
}
for chunk in chunks
]
ids = [f"{chunk['file_name']}_{chunk['chunk_id']}" for chunk in chunks]
embeddings = self.get_embeddings(documents)
self.collection.add(
embeddings=embeddings,
documents=documents,
metadatas=metadatas,
ids=ids
)
print(f"成功添加 {len(chunks)} 个文档块到向量数据库")
def search(self, query, top_k=3):
"""根据查询检索相关文档"""
query_embedding = self.get_embeddings([query])[0]
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
return {
'documents': results['documents'][0],
'metadatas': results['metadatas'][0]
}
class ObsidianRAGBot:
"""基于Obsidian知识库的RAG问答机器人"""
def __init__(self, vector_db):
self.vector_db = vector_db
self.llm_client = OpenAI(
api_key=os.getenv("api_key"),
base_url=os.getenv("base_url")
)
self.prompt_template = """
你是一个基于知识库的智能助手。请根据以下提供的知识片段来回答用户的问题。
知识片段:
{context}
用户问题:{question}
回答要求:
1. 优先使用提供的知识片段中的信息
2. 如果知识片段不足以回答问题,请明确说明
3. 保持回答的准确性和相关性
4. 用中文回答
回答:
"""
def chat(self, question, top_k=3):
"""回答用户问题"""
# 1. 检索相关文档
search_results = self.vector_db.search(question, top_k)
# 2. 构建上下文
context_parts = []
for i, (doc, metadata) in enumerate(zip(search_results['documents'],
search_results['metadatas'])):
context_parts.append(f"片段{i+1}(来源:{metadata['file_name']}):\n{doc}")
context = "\n\n".join(context_parts)
# 3. 构建提示
prompt = self.prompt_template.format(
context=context,
question=question
)
# 4. 调用大语言模型
response = self.llm_client.chat.completions.create(
model="qwen-plus",
messages=[{"role": "user", "content": prompt}],
temperature=0.1
)
return response.choices[0].message.content
def build_obsidian_rag_system(vault_path):
"""构建Obsidian RAG系统的主函数"""
print("开始构建Obsidian知识库问答系统...")
# 1. 读取文档
print("正在读取markdown文件...")
documents = read_obsidian_vault(vault_path)
print(f"共读取到 {len(documents)} 个文件")
# 2. 文档分块
print("正在分割文档...")
chunks = chunk_documents(documents)
print(f"共生成 {len(chunks)} 个文档块")
# 3. 构建向量数据库
print("正在构建向量数据库...")
vector_db = ObsidianVectorDB()
vector_db.add_documents(chunks)
# 4. 创建RAG机器人
print("正在初始化问答系统...")
rag_bot = ObsidianRAGBot(vector_db)
print("系统构建完成!")
return rag_bot
# 使用示例
if __name__ == "__main__":
# 设置你的Obsidian知识库路径
obsidian_vault_path = "C:/Users/Administrator/Documents/Obsidian"
# 构建RAG系统
rag_system = build_obsidian_rag_system(obsidian_vault_path)
# 进行问答测试
test_questions = [
"什么是RAG?",
"LangChain有哪些核心组件?",
"如何选择向量数据库?"
]
for question in test_questions:
print(f"\n问题:{question}")
answer = rag_system.chat(question)
print(f"回答:{answer}")
print("-" * 50)
项目成果与思考
通过这个实战项目,我们成功打造了一个基于个人知识库的智能问答系统。现在你可以:
- 直接问问题,无需记住具体文件位置
- 获得基于真实笔记内容的准确答案
- 快速定位答案来源,便于深入学习
实际应用效果
想象一下这样的使用场景:
场景一:技术问题回忆
问题:我之前学Redis时记录的持久化方式有哪些?
系统:根据你的笔记《Redis学习笔记.md》,Redis主要有两种持久化方式:
1. RDB快照:定期保存数据集快照到磁盘
2. AOF日志:记录每个写操作,可以完整恢复数据
场景二:知识点对比
问题:MySQL和PostgreSQL的区别是什么?
系统:基于你的《数据库对比.md》笔记,主要区别包括:
- MySQL更适合高并发读取,PostgreSQL更适合复杂查询
- PostgreSQL支持更丰富的数据类型和SQL标准
进一步优化方向
当前系统还有很多可以改进的地方:
功能扩展
- 支持更多文件格式(PDF、Word、网页等)
- 添加Web界面,提供更友好的交互体验
- 支持多轮对话,记住上下文
- 增加知识图谱功能,展示知识之间的关联
性能优化
- 优化检索算法,提高准确率
- 支持增量索引,新增文件时无需重建整个索引
- 加入缓存机制,提高响应速度
RAG技术的未来
从我们的实战项目中可以看出,RAG技术正在改变我们与知识交互的方式。它不仅解决了LLM的局限性,更重要的是让我们的个人知识资产变得真正可检索、可利用。
在企业级应用中,RAG正在被广泛应用于:
- 客服系统:基于产品文档和FAQ自动回答客户问题
- 内部知识管理:帮助员工快速找到公司内部文档和流程
- 法律咨询:基于法律条文和案例提供专业建议
- 医疗辅助:结合医学文献为医生提供诊断参考
虽然我们从零开始实现了一个完整的RAG系统,但在实际开发中,你可能会发现手写代码的复杂性。每个环节都需要仔细处理,代码量大,维护成本高。这就像早期的Java Web开发,需要手动配置各种XML文件。
幸运的是,就像Spring Boot简化了Java开发一样,现在有很多优秀的RAG框架可以大大简化开发过程。LangChain就是其中的佼佼者,它将我们手动实现的各个环节封装成了简洁的组件,让RAG应用开发变得更加高效。
在下一篇文章中,我们将探索如何使用LangChain来构建更强大、更优雅的RAG应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)