WIndows11上搭建个人ai知识库(保姆级教程)
本文分享了搭建本地AI知识库的实用指南,重点基于DeepSeek和RAGFlow工具。作者从基础环境准备开始,详细介绍了下载Ollama、克隆RAGFlow源代码、安装Docker,并部署RAGFlow的步骤。文章强调了Embedding模型在RAG系统中的核心作用,如文本向量化和相似度计算(例如使用余弦相似度公式)。此外,还提供了配置本地模型或API密钥、创建知识库并添加文件的方法,使开发者能快
1,前言
写下这篇文章是为了我下一次搭建ai知识库的时候,更加方便与快捷,我认为可能对于同行也会有一些微末的作用。
我看的教学视频:【【知识科普】【纯本地化搭建】【不本地也行】DeepSeek + RAGFlow 构建个人知识库】https://www.bilibili.com/video/BV1WiP2ezE5a?vd_source=9daf68c0042e9425c5b0afbea72063a3
2,搭建基本流程
第一步:下载ollama
第二步:下载或者克隆ragflow源代码
第三步,下载docker
第四步,docker部署ragflow,
第五步,使用ragflow创建知识库,
第六步,添加内容进入知识库,调用模型或者使用本地部署的模型进行聊天
3,一些基础知识(急于正式搭建的话,可以先忽略这个)
Embedding 的概念与作用
Embedding 是一种将自然语言(如单词、句子或文档)转化为高维向量的技术。这些向量捕捉语义信息,使得机器能够通过数学方式计算文本之间的相似度。例如,单词“蟹堡王”和“比奇堡”会被映射到相近的向量空间,而“深度学习”则被映射到较远的空间,这体现了语义关联性。Embedding 的核心优势在于将非结构化的文本数据转化为结构化数值,便于机器处理。
为什么在 DeepSeek 和 RAGFlow 之外还需要 Embedding 模型
DeepSeek 和 RAGFlow 属于对话模型(Chat 模型),专注于生成自然语言响应。然而,它们无法直接处理文本相似度计算或外部知识检索。Embedding 模型专门用于:
- 将文本转化为向量,以支持高效相似度匹配。
- 在 RAG(Retrieval-Augmented Generation)系统中,充当“桥梁”:对话模型依赖 Embedding 模型来检索和整合外部知识,否则只能利用自身训练数据,导致响应缺乏实时性和准确性。 因此,Embedding 模型是 RAG 架构的必备组件,它弥补了对话模型在语义理解和外部数据访问上的不足。
模型的分类
在 RAG 系统中,模型主要分为两类:
- 对话模型(Chat 模型):如 DeepSeek,负责生成最终回答。它们基于输入上下文产生响应,但无法直接访问外部知识库。
- Embedding 模型:专注于文本向量化。它将自然语言映射到高维空间,便于相似度计算。例如,输入文本 $ \mathbf{t} $ 被转化为向量 $ \mathbf{v} $,其中 $ \mathbf{v} \in \mathbb{R}^d $($ d $ 表示维度)。
检索过程详解
在基于本地文件构建的 RAG 系统中,检索流程如下:
- 准备外部知识库:从本地文件(如文档)解析文本,分割为片段(如段落)。Embedding 模型处理每个片段,生成唯一向量(“指纹”)。例如,片段 $ \mathbf{s}_i $ 对应向量 $ \mathbf{v}_i $。
- 处理用户输入:用户提问时,Embedding 模型将输入转化为查询向量 $ \mathbf{q} $。
- 相似度匹配:系统计算 $ \mathbf{q} $ 与知识库中所有 $ \mathbf{v}_i $ 的相似度,常用余弦相似度度量: $$ \cos(\theta) = \frac{\mathbf{q} \cdot \mathbf{v}_i}{|\mathbf{q}| |\mathbf{v}_i|} $$ 其中 $ \cos(\theta) $ 值接近 1 表示高相似度。
- 检索与扩展上下文:系统返回相似度高的片段,将其与用户输入结合,作为增强上下文输入对话模型(如 DeepSeek),生成最终回答。
构建本地知识库的流程
为创建高效 RAG 系统:
- 知识库解析:上传本地文件后,Embedding 模型将文本分割并向量化,建立“指纹库”。
- 实时查询:用户提问时,系统通过向量相似度快速检索相关片段,确保响应基于最新外部信息。 此流程优化了知识利用,使对话模型能动态补充训练数据之外的实时内容。
4,环境准备,与正式搭建
4.1下载ollama并且拉取模型
4.1.1下载ollama
ollama是用来本地部署大模型的平台(如果对隐蔽性要求不高或者不打算本地部署可以忽略此步),可以前往官网下载:
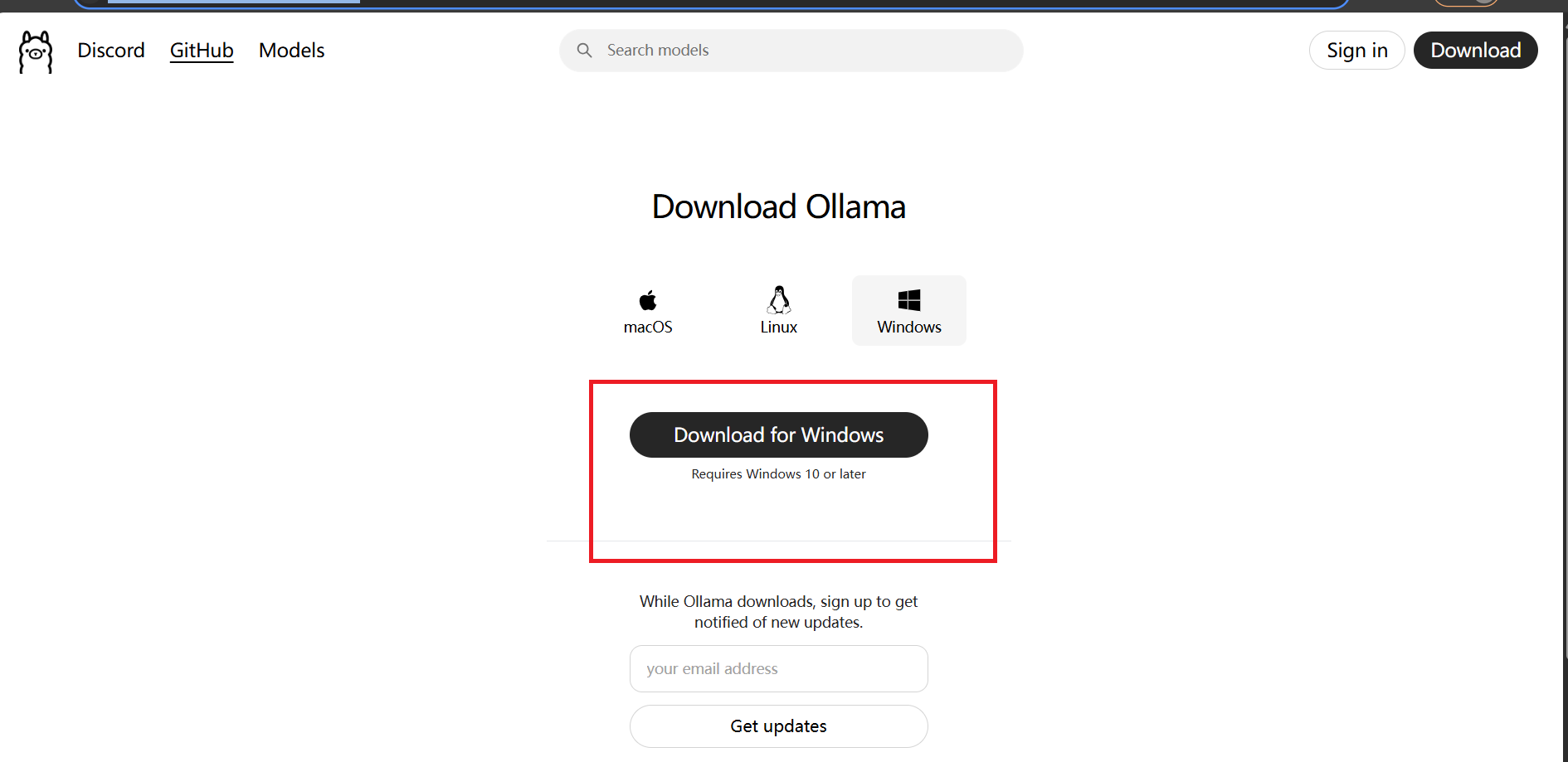
4.1.2配置环境变量
在Windows开始菜单栏输入环境变量
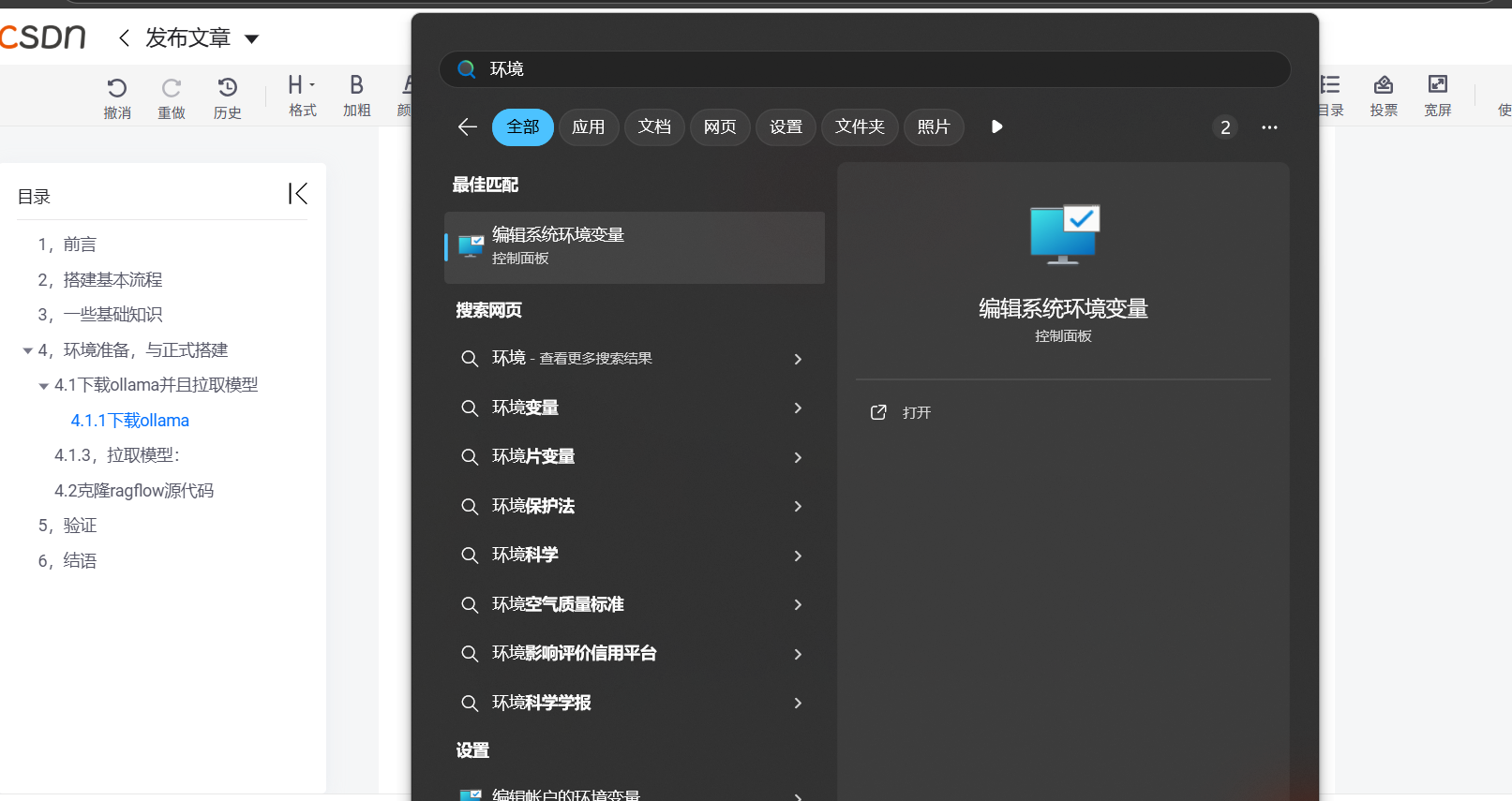
点击环境变量进行环境变量编辑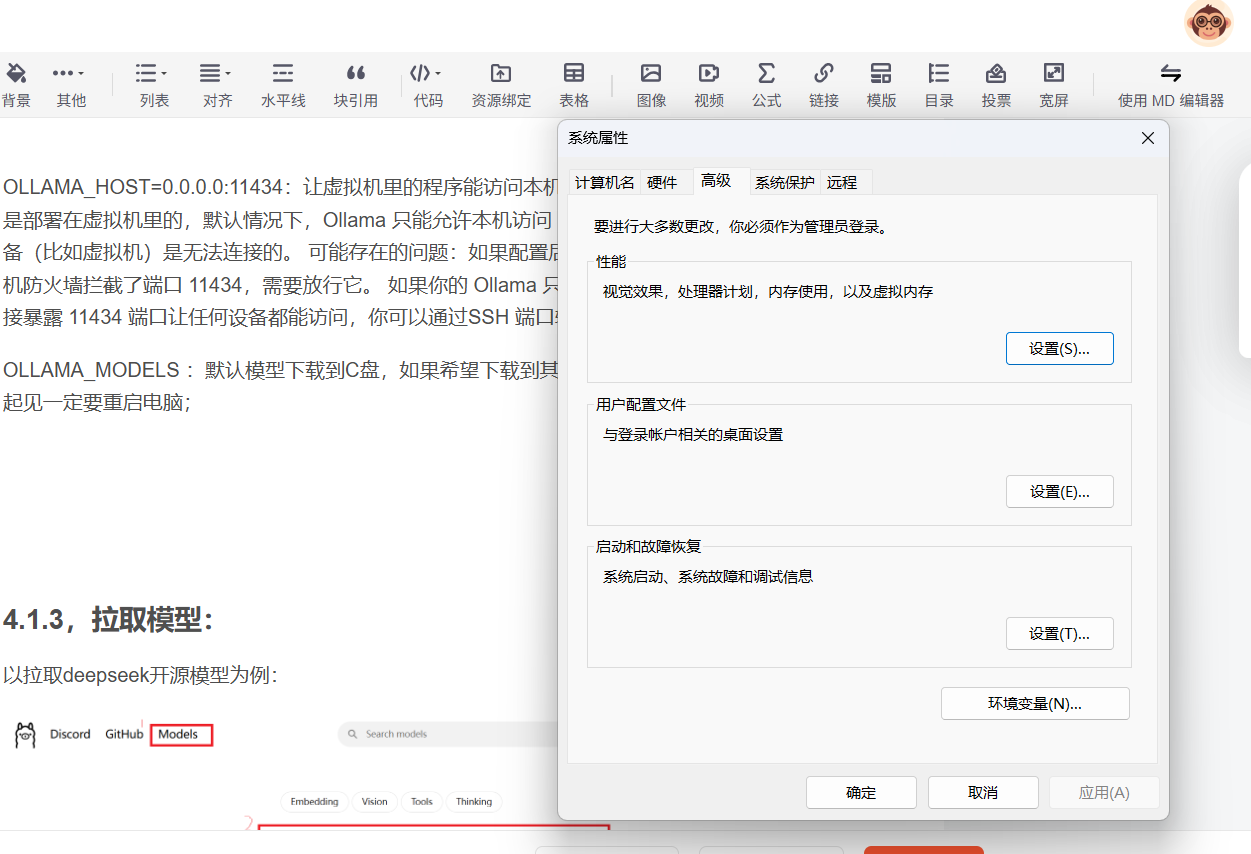
OLLAMA_HOST=0.0.0.0:11434:让虚拟机里的程序能访问本机上运行的 Ollama 模型 RAGFlow是部署在虚拟机里的,默认情况下,Ollama 只能允许本机访问(监听 localhost:11434),其他设备(比如虚拟机)是无法连接的。 可能存在的问题:如果配置后虚拟机无法访问,可能是你的本机防火墙拦截了端口 11434,需要放行它。 如果你的 Ollama 只想给自己的虚拟机使用,而不想直接暴露 11434 端口让任何设备都能访问,你可以通过SSH 端口转发来实现;
OLLAMA_MODELS :默认模型下载到C盘,如果希望下载到其他盘可以配置,最好选一个大一点的盘; 注意配置之后保险起见一定要重启电脑;
结果示例

4.1.3,拉取模型:
拉取deepseek开源模型:
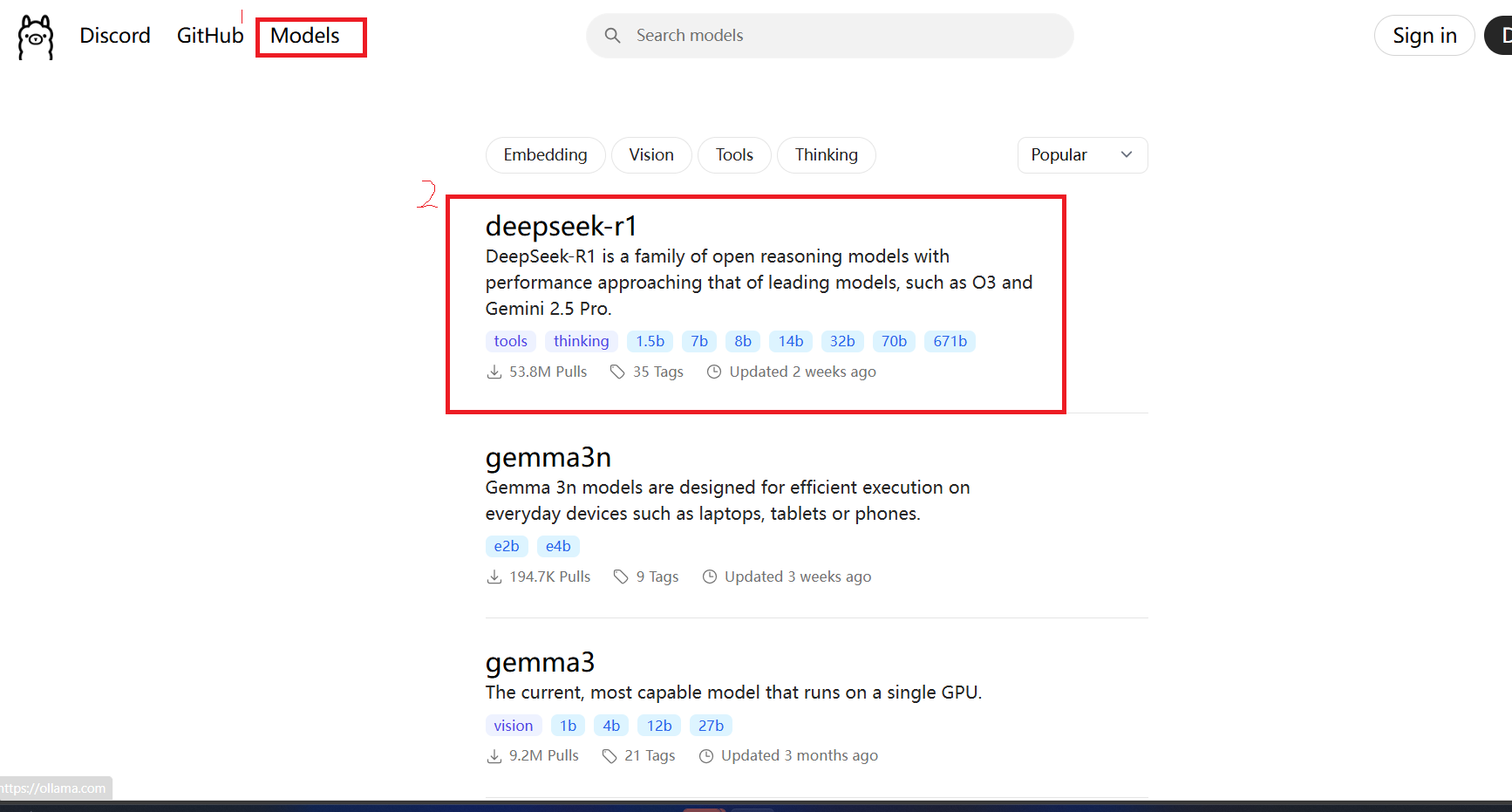
以内存最小的版本为例:
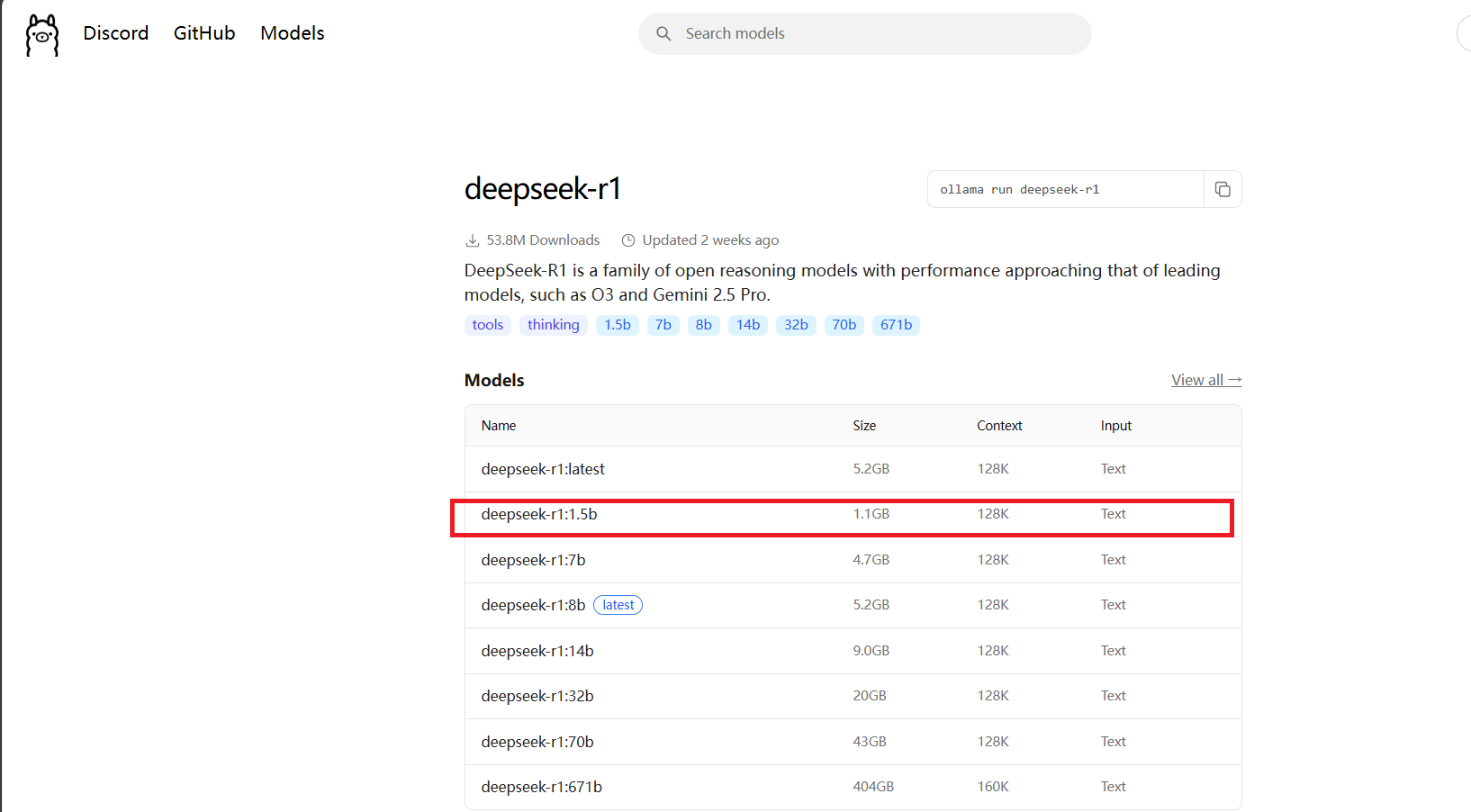 复制模型拉取命令
复制模型拉取命令
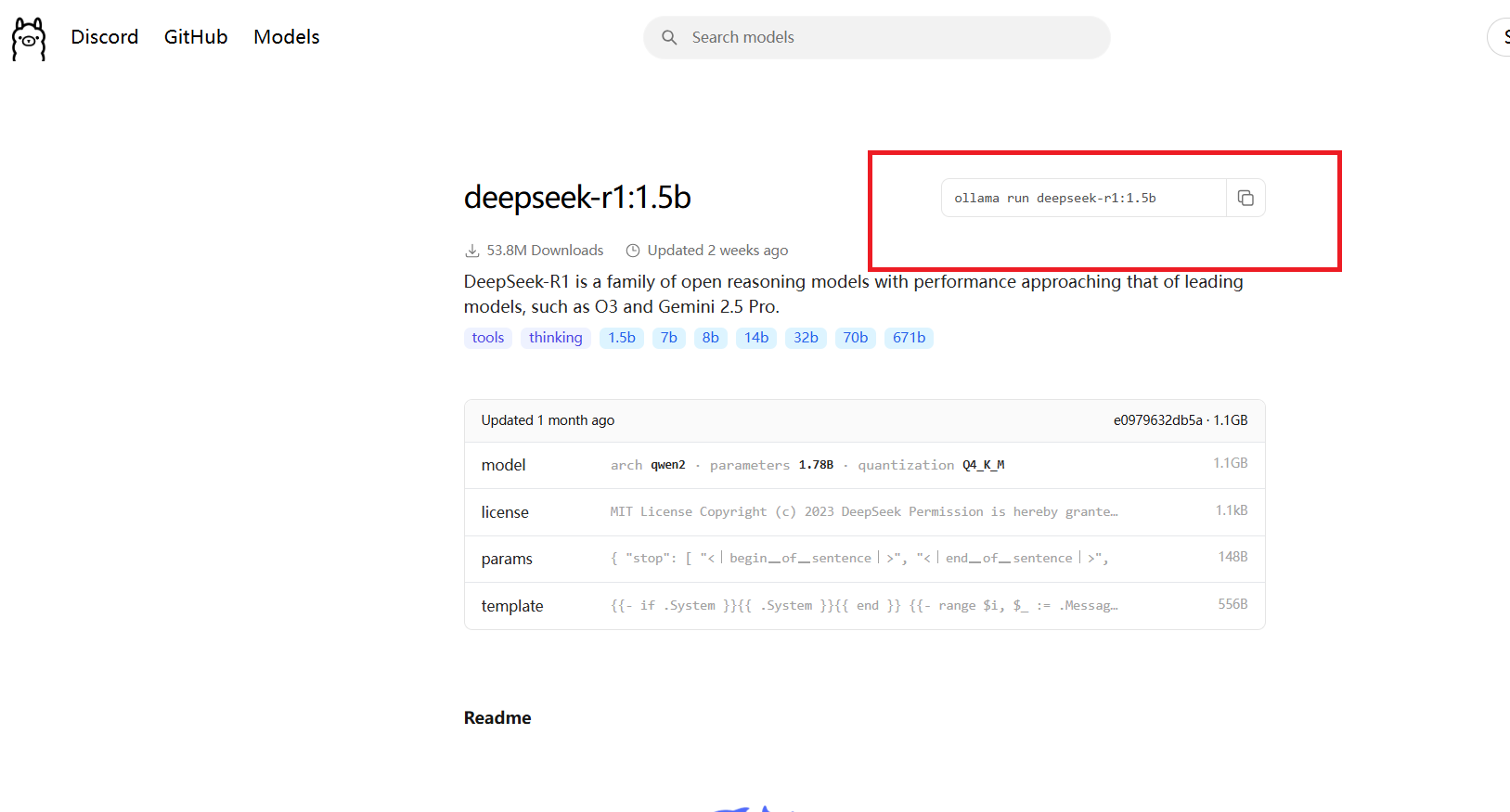
终端(win+r,然后输入cmd回车)拉取模型:
我这里由于之前以及下载好了直接就能对话,初次下载的可能要花一些时间等待模型下载
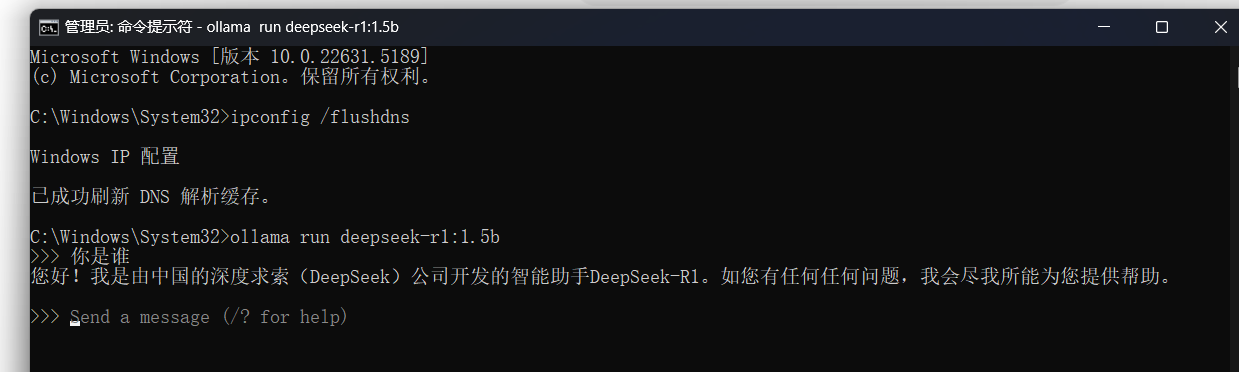
tip:初次下载的可能要等待模型下载,刚开始会有慢是正常的,不过如果非常慢,可以CTRL+c打断,然后再次输入命令继续下载。(这样并不会使我们的下载进度重新从零开始)
4.2克隆ragflow源代码
如果你会git,请看4.2.1,否则4.2.2
4.2.1使用git克隆
进入GitHub复制网址使用git克隆
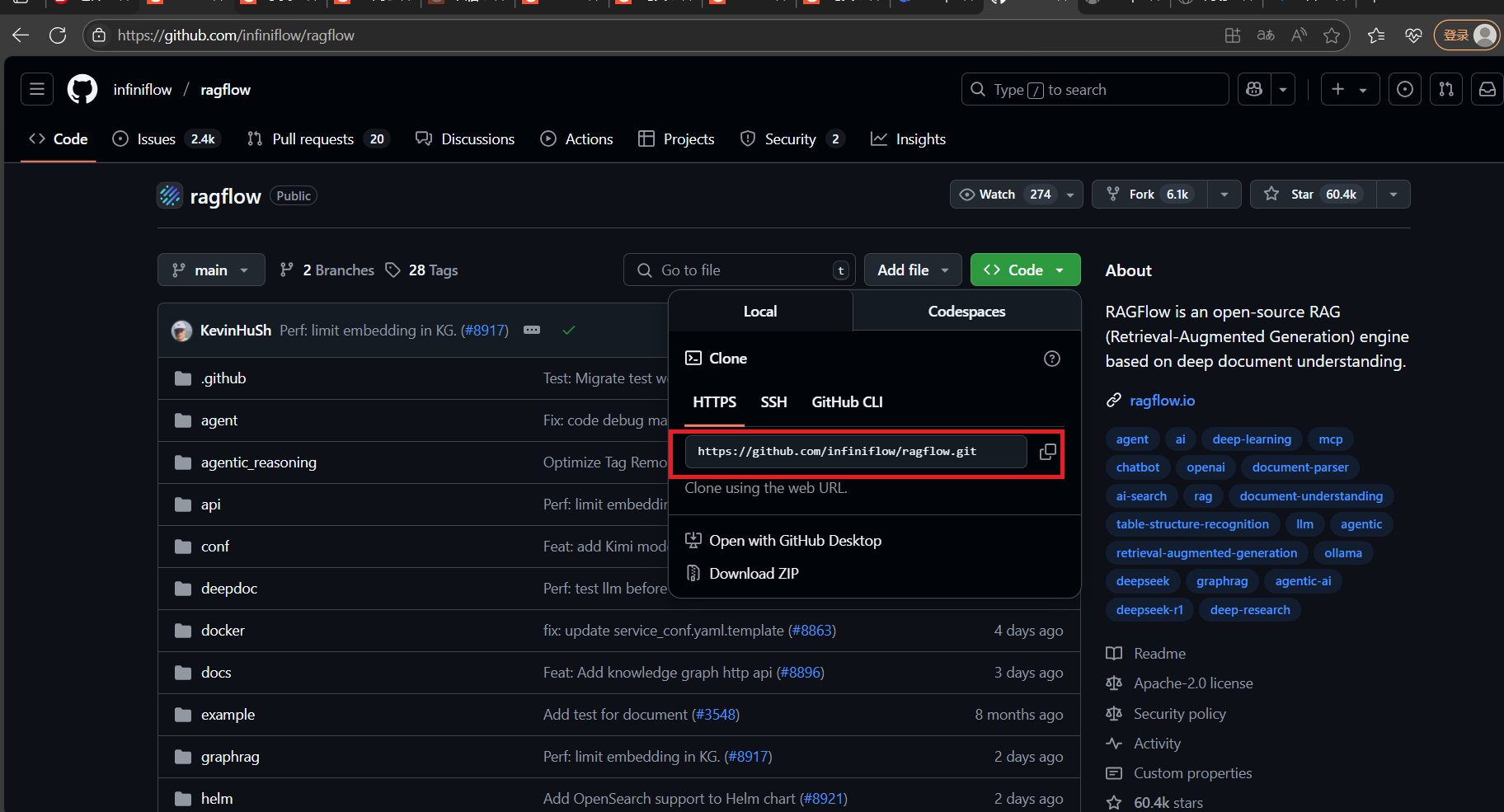
在任意一个文件夹下cmd回车,使用git克隆:
git clone https://github.com/infiniflow/ragflow.git4.2.2直接下载ragflow源代码
下载好代码将其解压到一个对应文件夹
如果无法正常打开GitHub可以下载这个网盘里的:
夸克网盘分享
4.3,下载docker:
以在windows环境下下载为例:
可以参考:
Windows安装Docker(图文解说详细版)_docker能安装在window环境下吗-CSDN博客
如果安装之后遇见wsl问题,可以参考这个视频:
【windows环境下的docker安装及配置】https://www.bilibili.com/video/BV1hPjwzjECk?vd_source=9daf68c0042e9425c5b0afbea72063a3
安装完成记得添加国内镜像仓库加速:
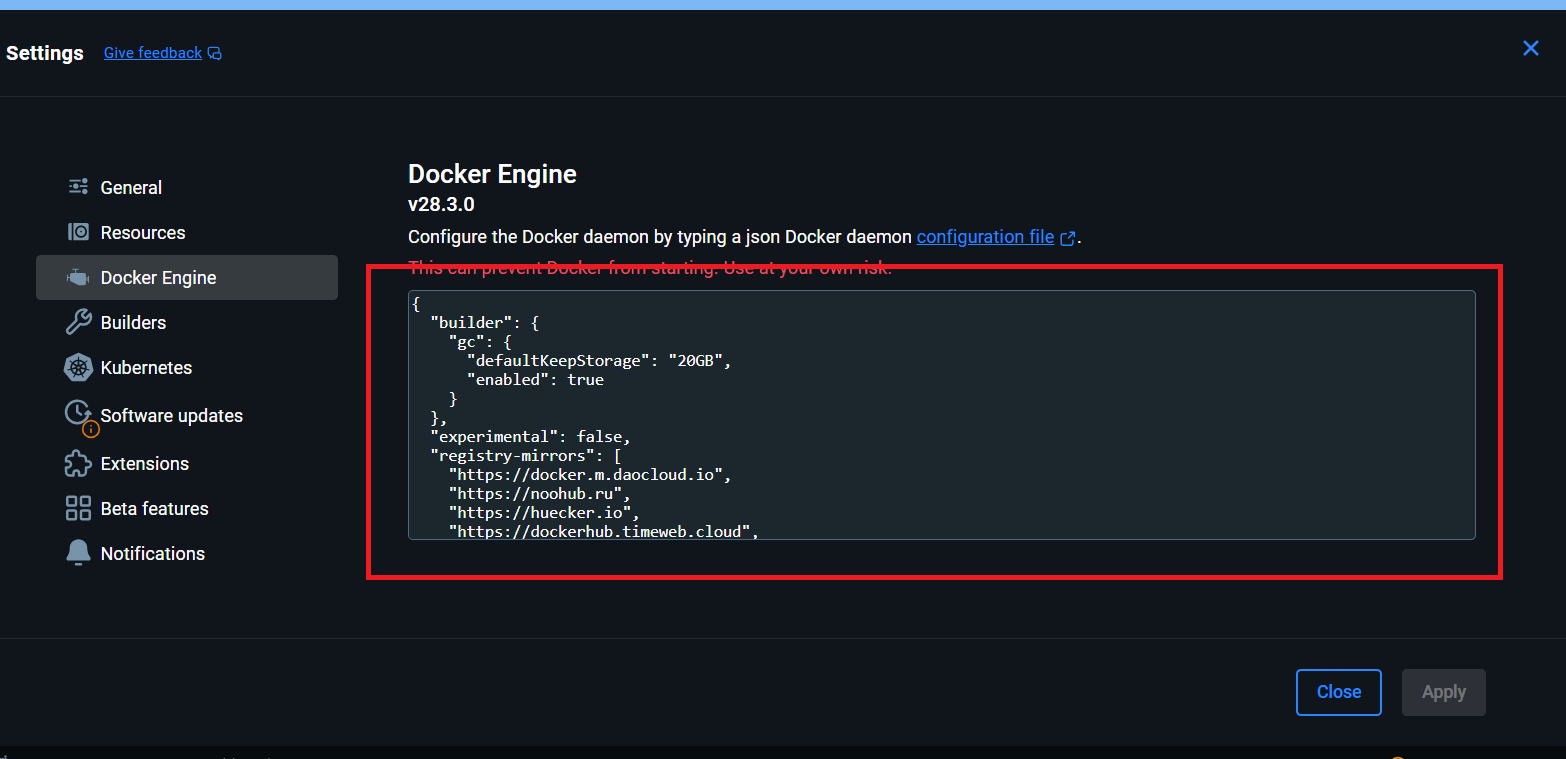
红框内容改为:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://noohub.ru",
"https://huecker.io",
"https://dockerhub.timeweb.cloud",
"https://0c105db5188026850f80c001def654a0.mirror.swr.myhuaweicloud.com",
"https://5tqw56kt.mirror.aliyuncs.com",
"https://docker.1panel.live",
"http://mirrors.ustc.edu.cn/",
"http://mirror.azure.cn/",
"https://hub.rat.dev/",
"https://docker.ckyl.me/",
"https://docker.chenby.cn",
"https://docker.hpcloud.cloud"
]
}4.3,docker部署ragflow:
tips:这个镜像还是使用有点儿大的可能会占用30g,如果不想c盘爆满,建议修改默认镜像存储位置。修改方式可参考下文:windows下Docker安装路径、存储路径修改_window 修改docker的资源路径-CSDN博客
4.3.1,准备工作
进入布置好的ragflow文件下的docker文件夹,修改一下.env文件,
将这一行:
RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1-slim
进行注释(在前面加一个#)修改完记过如下:

另一行
#RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1
取消注释
![]()
4.3.2,部署ragflow:
tip:优先确保docker已经开启。
进入ragflow文件夹下的docker文件夹 cmd回车
然后输入以下命令回车:
ci
docker compose -f docker-compose.yml up -d等待镜像下载完成就部署好ragflowl了
验证,ragflow默认使用80端口(可以修改默认端口,这里就不做赘述了),随便一个浏览器输入以下命令:
如果进入界面: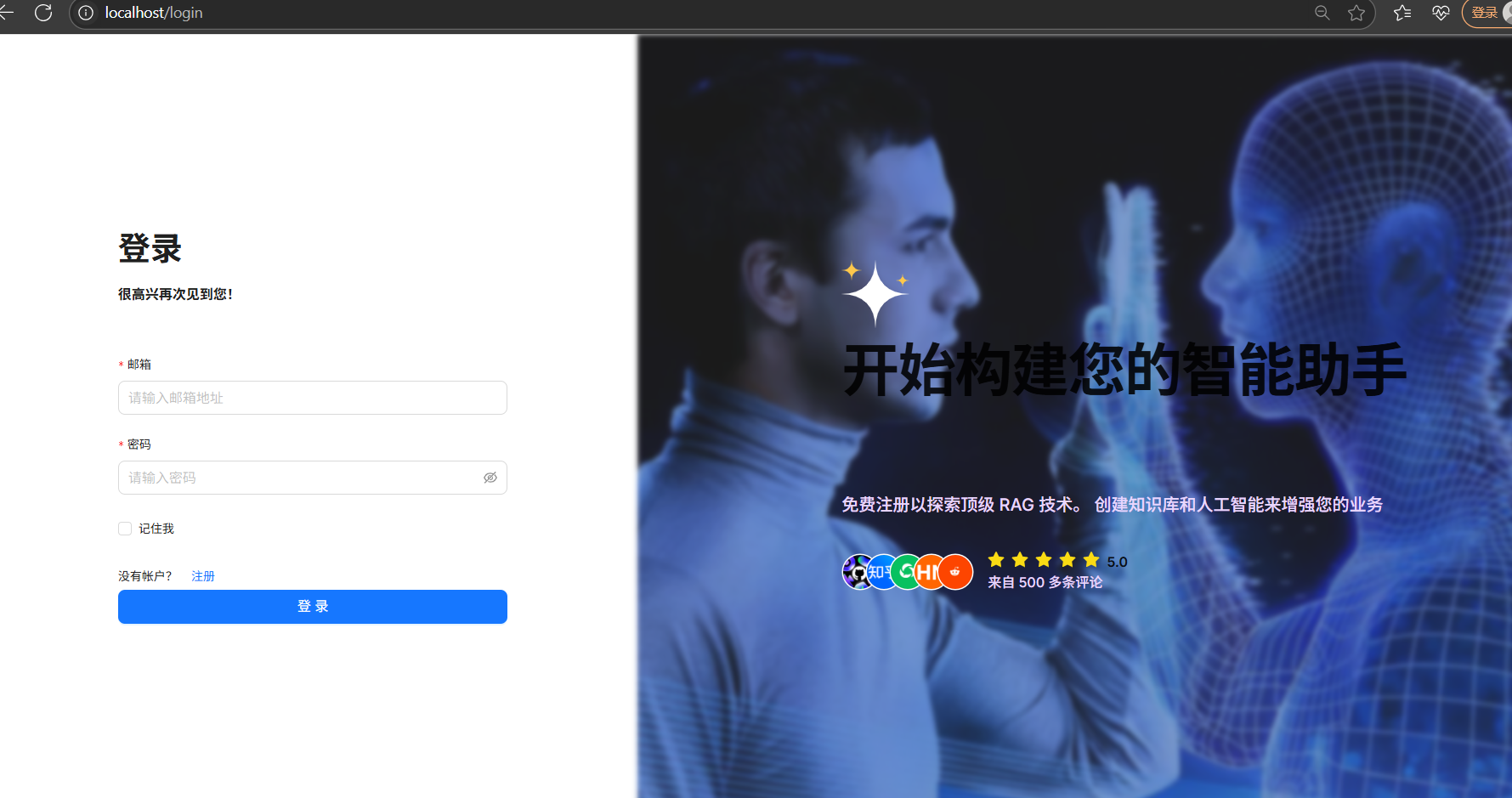
则代表部署成功
接下来你只需要注册号账号登录进去就可以开始创建自己的ai知识库
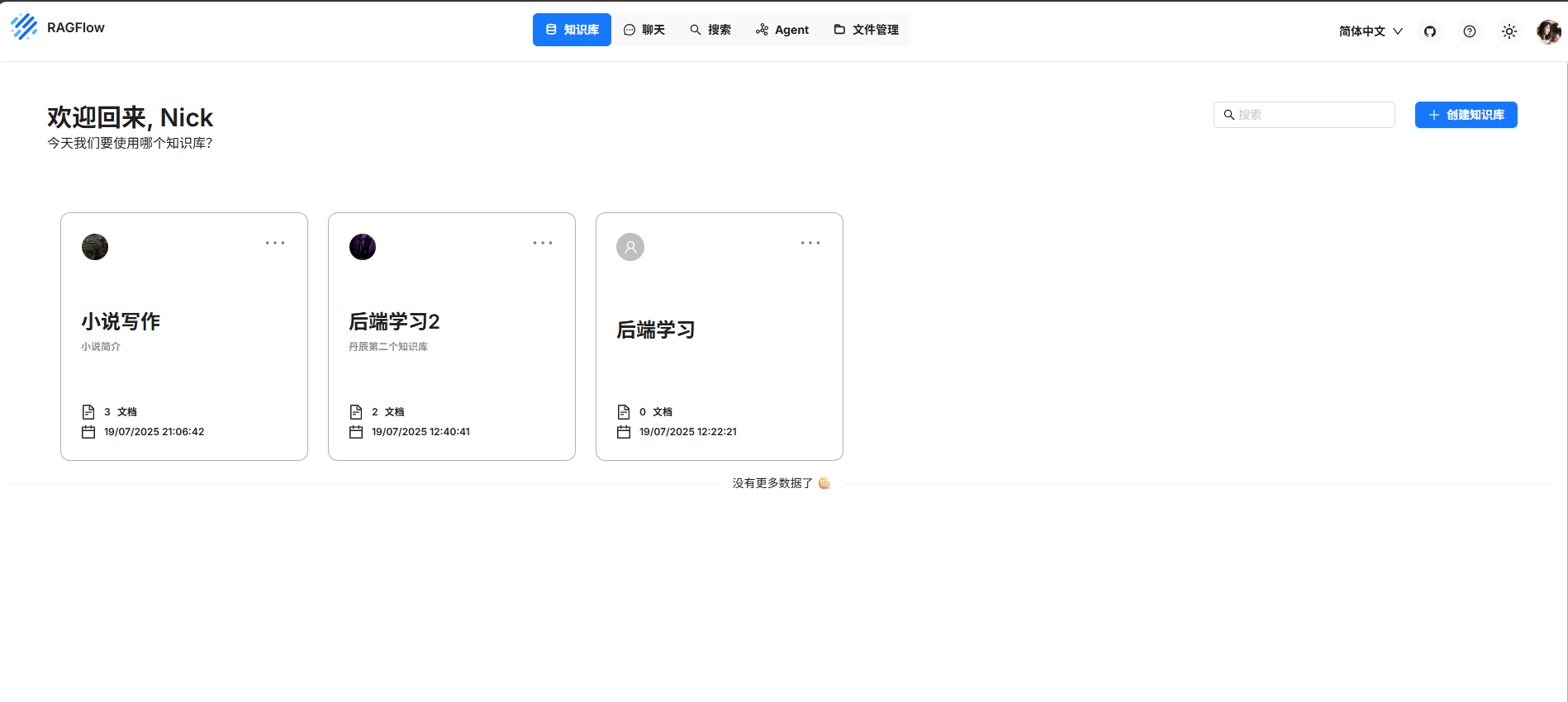 4.3.3创建ai知识库:
4.3.3创建ai知识库:
4.3.3.1创建前的准备(二选一)
a, 使用本地模型(适合本地运行)
- 点击用户头像,进入“模型提供商” → “待添加模型”。
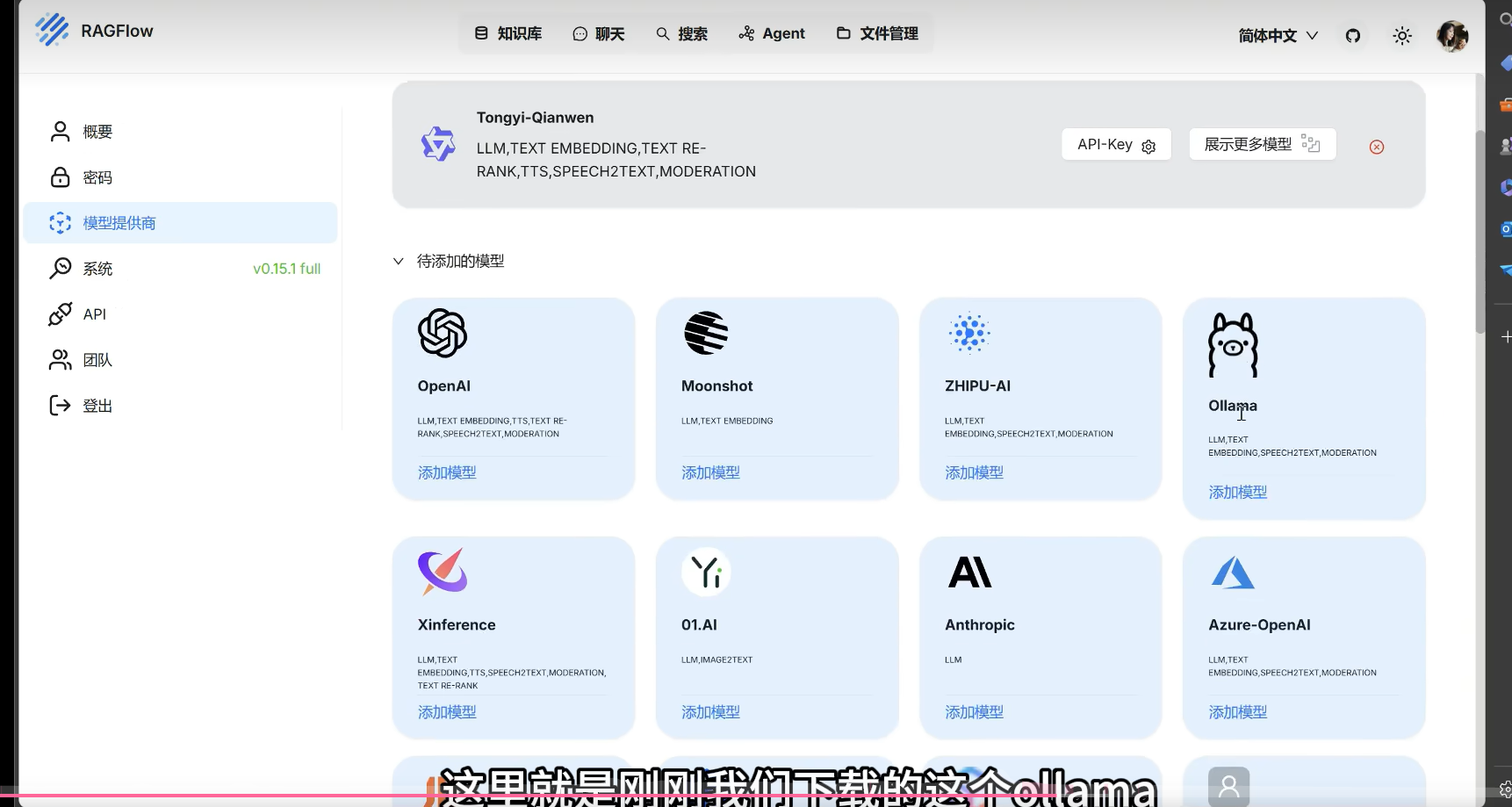
- 选择“添加模型”,类型为Ollama。
- 选择Chat模型,并严格复制已部署的本地模型名称(在终端输入
ollama list查看并复制名称)。 - 在模型名称框中填入复制的名称。
- 设置基础URL:
- 在终端执行
ipconfig。 - 在输出中找到IPv4地址(例如:192.168.x.x)。

- 复制地址(不包括冒号前的部分)。
- 在基础URL框中输入
http://{复制的IPv4地址}:11434。
- 在终端执行
- 设置最大token数(建议值大于600)。
- 点击“确定”。
- 设置默认模型:
- 进入“设置”菜单。
- 在“嵌入聊天模型”下拉栏中,选择之前添加的模型。
- 嵌入模型使用现有即可。
- 点击“确定”完成配置。
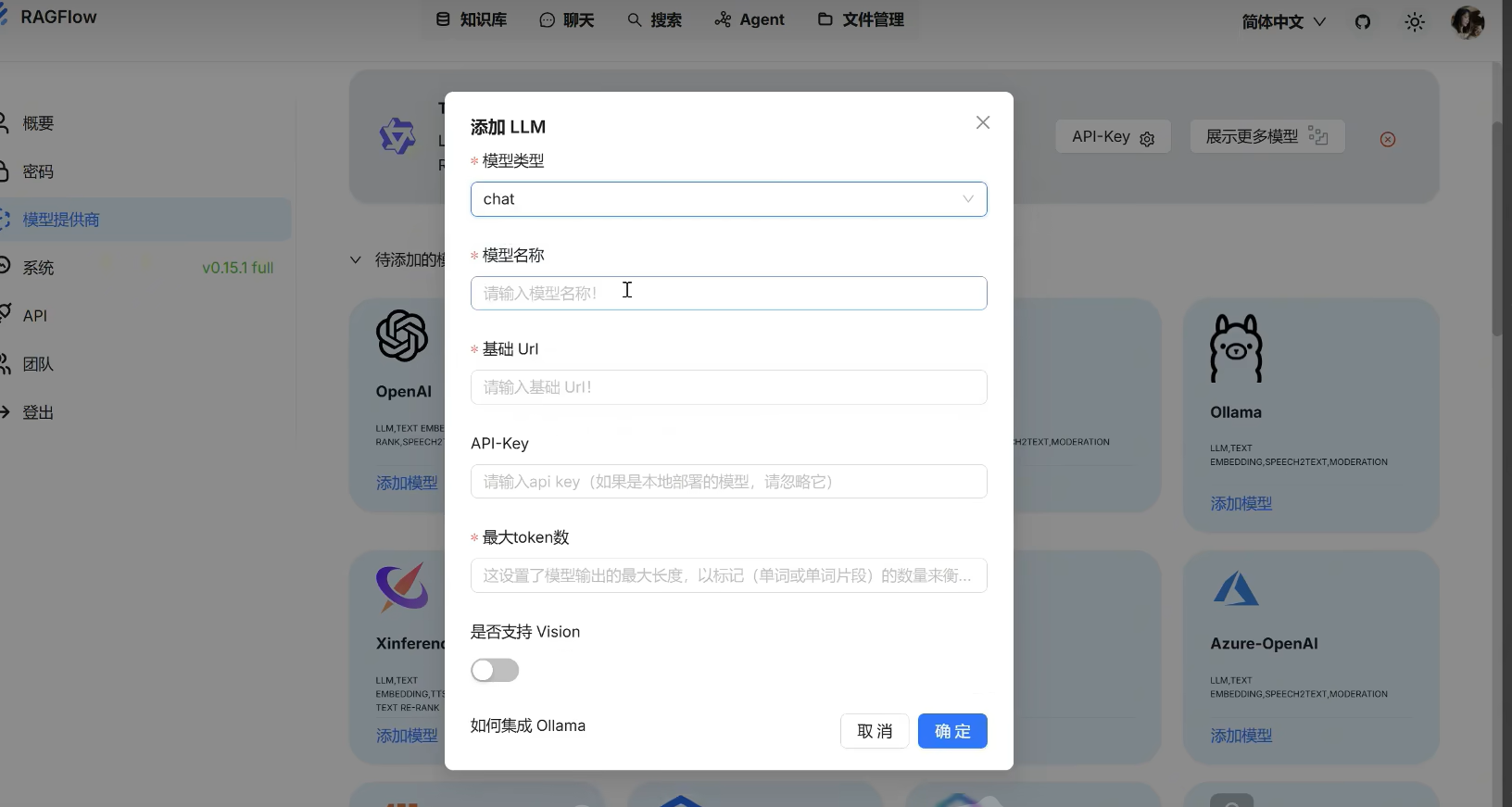
在以下栏寻找到ipv4地址然后复制冒号之后地址即可
在基础url添加http://{刚刚复制的ipv4地址}:11434
最大token数自行设置,(一般设置大于600)点击确定
之后点击设置默认模型:
在嵌入聊天模型处下滑栏选择我们之前添加的模型即可
嵌入模型使用已经有的即可,点击确定
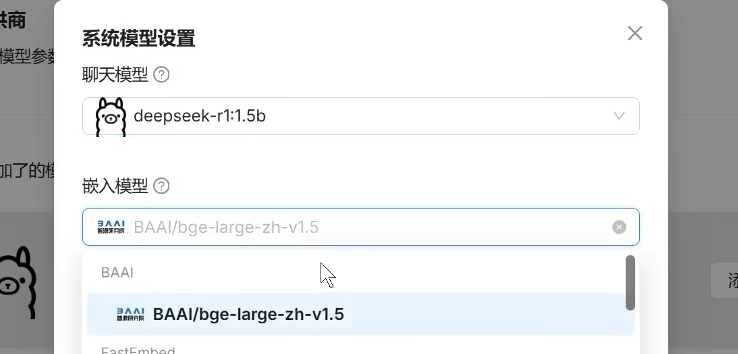
这样默认模型就配置成功了。
b,使用非本地部署模型(往往效果好一些,因为不是所有电脑都能跑满血大模型)

在对应模型官网的api开放平台获取apikey,在上面的空白框输入即可,其余操作与本地部署的大模型一致
4.3.3.2正式创建ai知识库
点击黑框区域,为知识库命名 。如:“小说写作”
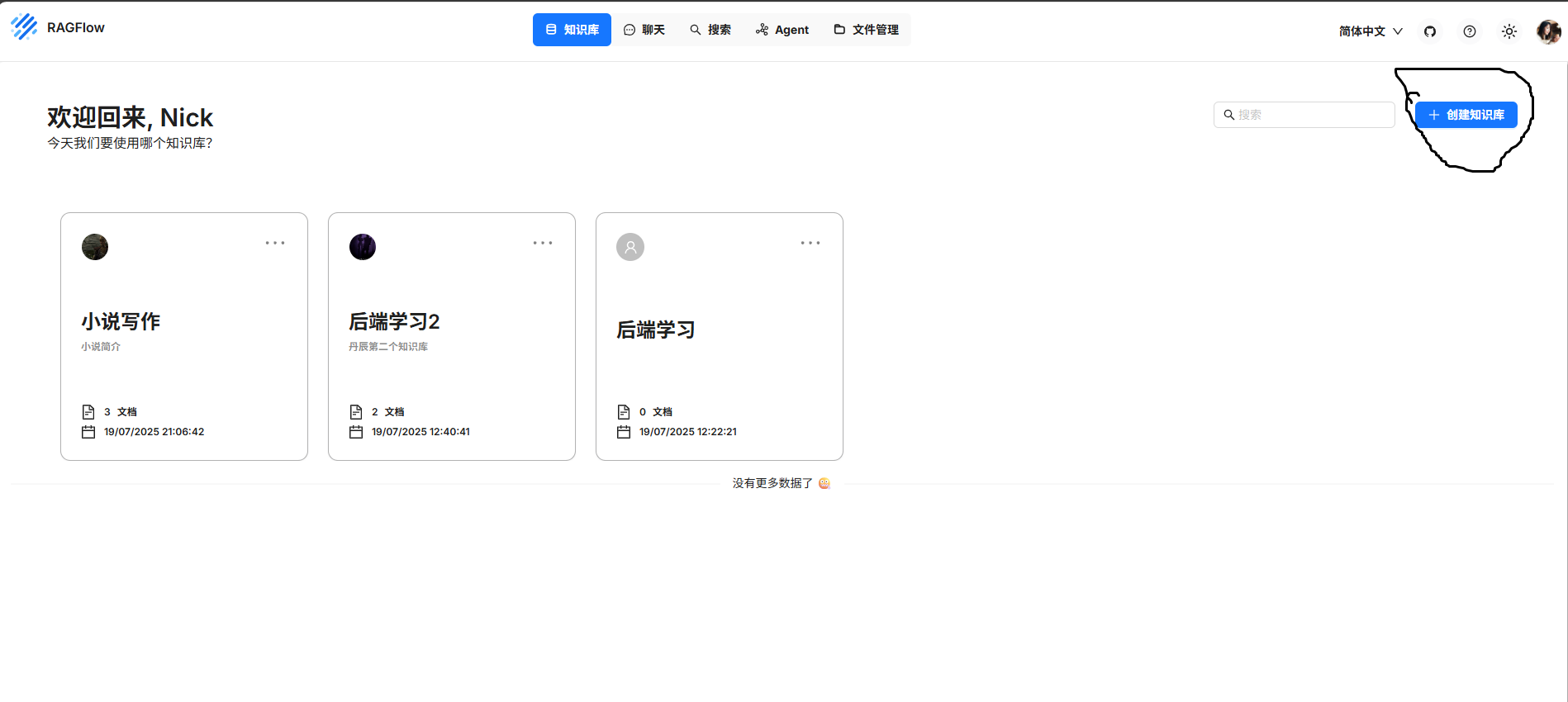
等待知识库加载,进入知识库进行配置,
可以选择使用默认的嵌入模型和默认配置
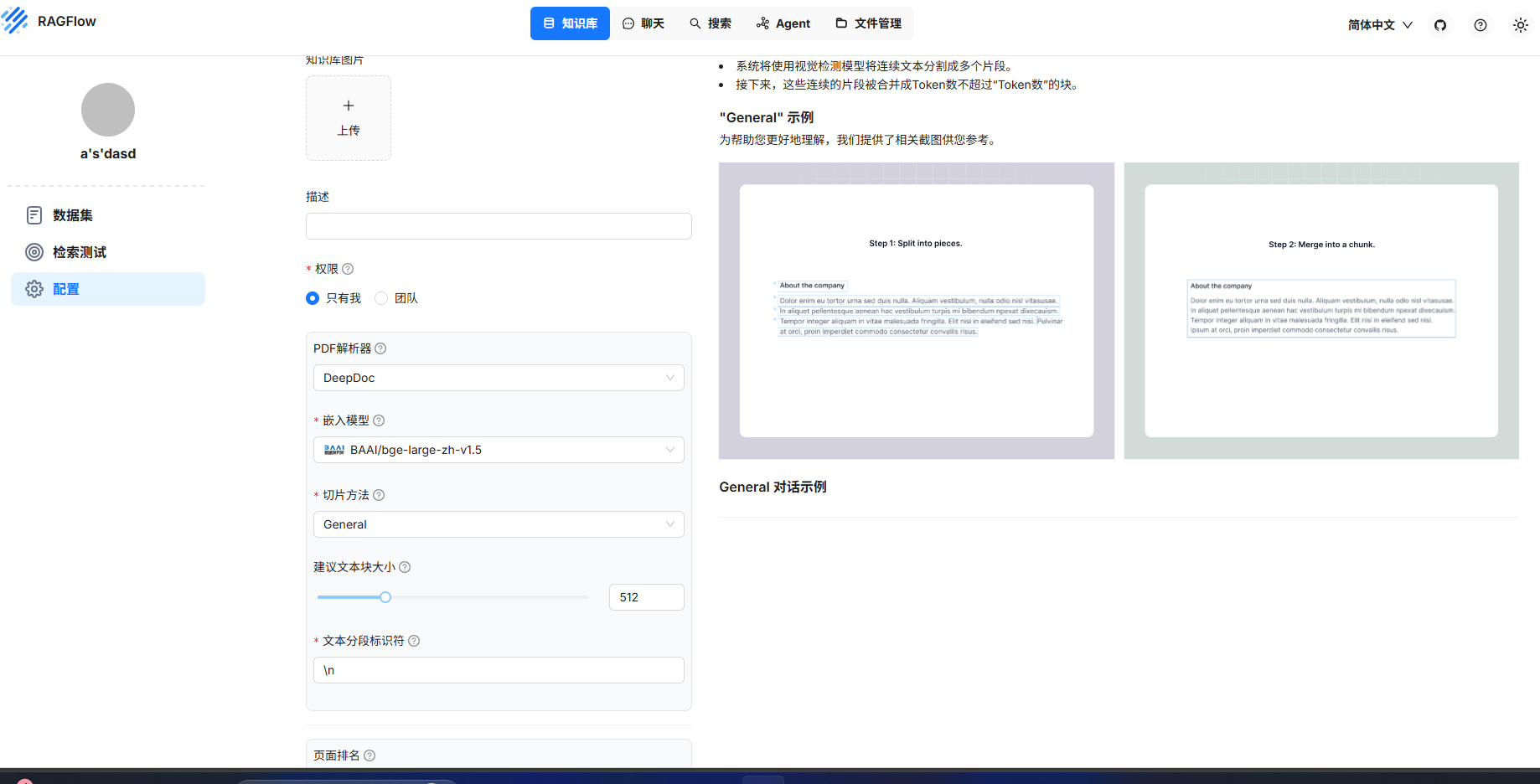
然后在数据集栏-----新增文件
添加你希望ai知道的内容文件保存配置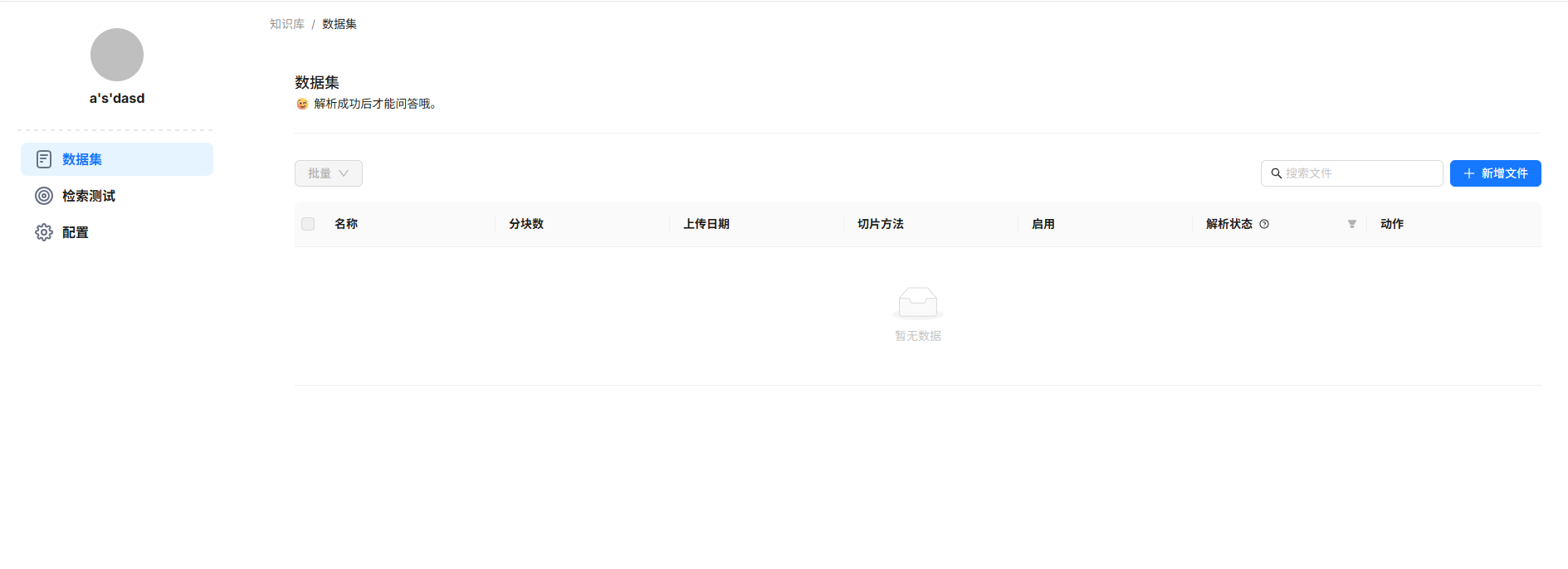
添加完成之后要点击解析,否则ai无法识别。(解析速度过慢可选择不同的嵌入模型以提高速度)
等待解析完成之后可以在“聊天--新建助理”
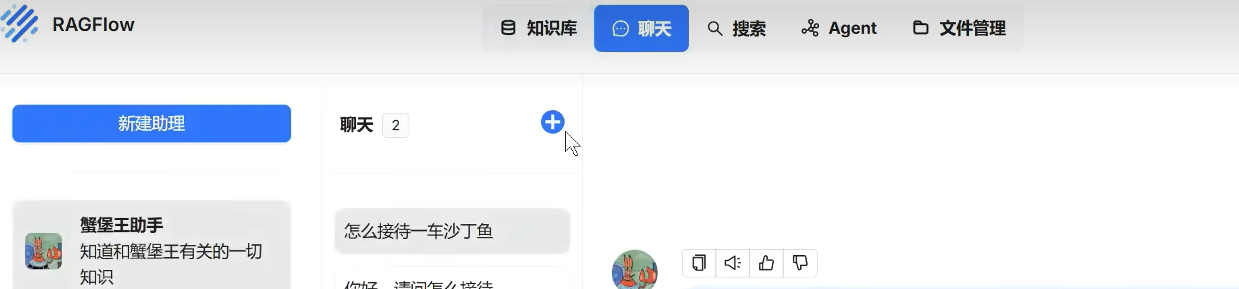 完成助理配置,点击加号选择你需要ai知道的知识库,
完成助理配置,点击加号选择你需要ai知道的知识库,
然后就可以和你部署的模型聊天,ai会根据你的知识库进行解答。
6,结语
这是我写的第一篇博客,可能有不足,还望海涵。
特别感谢b站up 堂吉诃德拉曼查的英豪 的授权支持

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)