AI基础学习周报十一
本周深入研究了Transformer架构的核心组件:注意力机制与前馈神经网络。系统解析了自注意力机制的计算流程,包括查询-键-值矩阵的生成、缩放点积注意力计算及softmax归一化过程;详细探讨了多头注意力机制的多视角特征提取能力与线性变换实现方式;完整分析了前馈神经网络的两层全连接结构与ReLU激活函数的非线性变换作用。
摘要
本周深入研究了Transformer架构的核心组件:注意力机制与前馈神经网络。系统解析了自注意力机制的计算流程,包括查询-键-值矩阵的生成、缩放点积注意力计算及softmax归一化过程;详细探讨了多头注意力机制的多视角特征提取能力与线性变换实现方式;完整分析了前馈神经网络的两层全连接结构与ReLU激活函数的非线性变换作用。
Abstract
This week delved into the core components of Transformer architecture: attention mechanisms and feed-forward neural networks. Systematically analyzed the computational workflow of self-attention, including query-key-value matrix generation, scaled dot-product attention calculation, and softmax normalization. Detailed the multi-perspective feature extraction capability of multi-head attention and its linear transformation implementation. Comprehensively examined the two-layer fully connected structure and nonlinear transformation role of ReLU activation in feed-forward networks.
1、注意力机制
1.1 自注意力机制
注意力机制(Self Attention)是Transformer的核心组件,允许模型在处理某个Token时,关注到别的Token,提高长距离依赖的捕捉能力,从而捕捉全局关系。具体结构如下: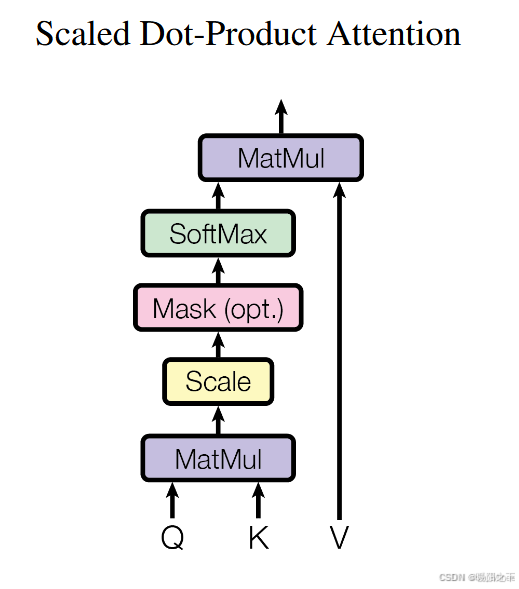
自注意力计算涉及三个关键矩阵:
- 查询(Query, Q):用于寻找相关信息。
- 键(Key, K):用于匹配 Query。
- 值(Value, V):用于生成最终的注意力加权结果。
ps:Q, K, V是根据序列长度和模型维度随机生成,然后根据算法学习和损失不断训练得到。(个人理解,如有误请纠正)
步骤 1:计算 Query, Key, Value
每个 Token(单词)通过可训练的权重矩阵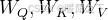
变换得到: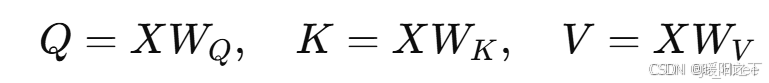
其中:
X是输入的 Token Embedding,形状为 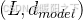
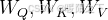
是可训练的参数矩阵,形状为 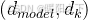
步骤 2:计算注意力分数
使用 Scaled Dot-Product Attention 计算注意力:
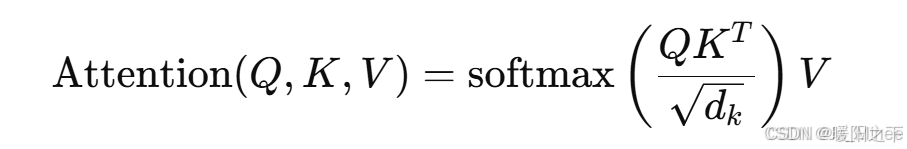
QKTQK^TQKT 计算每个 Token 与其他 Token 的相似度(点积计算)。
通过 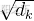 进行缩放,防止梯度爆炸。
进行缩放,防止梯度爆炸。
经过 softmax 归一化,得到注意力权重。
最后,乘以 V 计算加权结果。
步骤 3:计算最终输出
最终得到一个形状 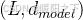 的输出矩阵,其中每一行代表该 Token 经过自注意力计算后的表示。
的输出矩阵,其中每一行代表该 Token 经过自注意力计算后的表示。
以下为自注意力部分代码实现:
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V, mask=None):
d_k = Q.shape[-1] # 维度
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5) # 计算 QK^T / sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9) # 应用 mask(用于解码时防止看未来)
attn_weights = F.softmax(scores, dim=-1) # 计算 softmax 注意力分数
return torch.matmul(attn_weights, V) # 计算加权和
# 示例:
d_model = 512
seq_len = 10
Q = torch.rand(seq_len, d_model)
K = torch.rand(seq_len, d_model)
V = torch.rand(seq_len, d_model)
attention_output = scaled_dot_product_attention(Q, K, V)
print(attention_output.shape) # 输出: torch.Size([10, 512])
1.2 多头注意力机制
多头注意力机制(Multi-Head Attention)是对自注意力机制的扩展,能够让模型学习不同的表示方式,让模型关注不同的信息,提高表达能力。具体结构如下: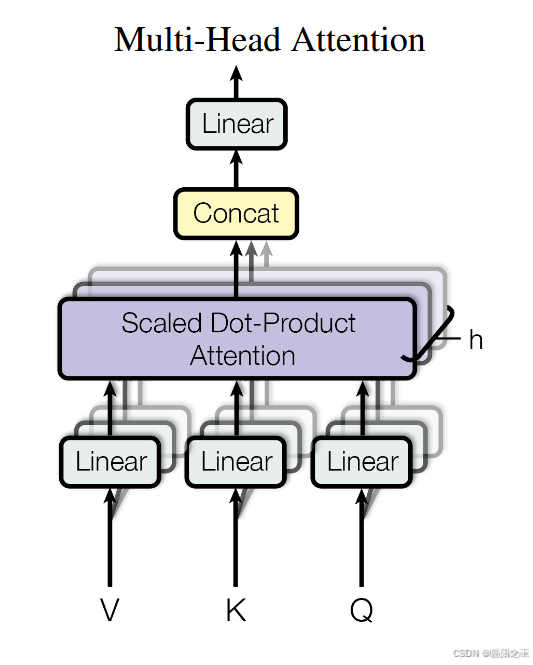
计算过程
步骤 1:线性变换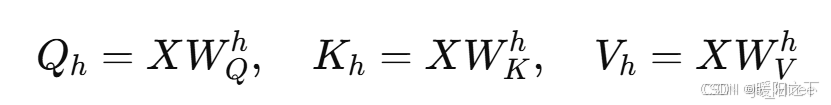
- 对输入 X进行不同的线性变换,得到 多个 Q、K、V。
- 这里h 表示第 h 个注意力头。
步骤 2:计算多个注意力头
每个头独立计算自注意力: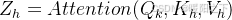
步骤 3:拼接多个头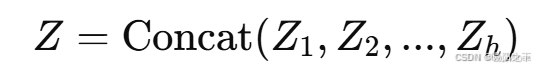
- 将所有注意力头的输出拼接(Concat),然后进行 线性变换:
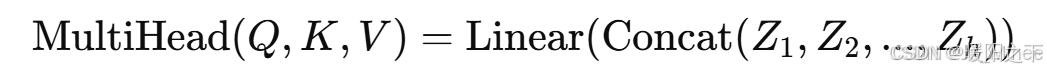
以下为多头注意力机制代码实现:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0 # 确保可均分
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头的维度
# 线性变换矩阵
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model) # 输出线性变换
def forward(self, Q, K, V):
batch_size = Q.shape[0]
# 线性变换 + 拆分多头
Q = self.W_Q(Q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_K(K).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_V(V).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 计算多头注意力
attn_output = scaled_dot_product_attention(Q, K, V) # (batch, num_heads, seq_len, d_k)
# 拼接多头输出
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.W_O(attn_output) # 线性变换回原始维度
# 示例:
d_model = 512
num_heads = 8
multihead_attn = MultiHeadAttention(d_model, num_heads)
input_tensor = torch.rand(2, 10, d_model) # batch_size=2, seq_len=10
output = multihead_attn(input_tensor, input_tensor, input_tensor)
print(output.shape) # 输出: torch.Size([2, 10, 512])
2、前馈神经网络
前馈神经网络(Feed Forward Neural Network, FFN):在Transformer中的Encoder和Decoder中,每层都有一个前馈神经网络,用于对注意力计算后的数据进行进一步的非线性变换,以增强模型的表达能力。
计算公式:
前馈神经网络通常由两个全连接层(Linear)和一个非线性激活函数(ReLU)组成: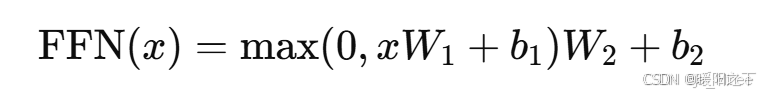
其中:
-
x 是输入 Token 的隐藏表示,形状为
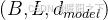
-
W_1和 W_2 是可训练的权重矩阵。
-
b_1 和b_2是偏置项。
-
ReLU 是激活函数,用于增加非线性。
以下是前馈神经网络部分的代码实现:
import torch
import torch.nn as nn
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model=512, d_ff=2048):
super(FeedForwardNetwork, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff) # W1: (512 -> 2048)
self.relu = nn.ReLU() # ReLU 激活函数
self.fc2 = nn.Linear(d_ff, d_model) # W2: (2048 -> 512)
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
# 示例
ffn = FeedForwardNetwork()
x = torch.rand(2, 10, 512) # batch_size=2, seq_len=10, d_model=512
output = ffn(x)
print(output.shape) # 输出: torch.Size([2, 10, 512])
总结
本周通过理论推导与代码实践相结合的方式,深度剖析了Transformer的核心计算模块:在注意力机制方面,完整掌握了自注意力的数学实现流程;在多头注意力扩展中,理解了通过多组线性变换并行计算注意力并拼接输出的架构设计;在前馈神经网络部分,明确了其作为编码器层中第二个子层的定位,通过两级线性变换与ReLU激活函数为模型注入非线性表达能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)