【大模型RAG】一篇文章带你掌握RAG的典型工作流程与5种分块策略!
在构建高效的大语言模型(LLM)应用时,数据分块是至关重要的预处理步骤。通过将大型数据文件智能分割为适当大小的片段,我们能够为LLM精准提供执行特定任务所需的信息量 - 既不会因信息过载而影响性能,也不会因信息不足而降低输出质量。为了方便大家更好了解RAG的分块,将分块策略进行一些回顾和总结。
在构建高效的大语言模型(LLM)应用时,数据分块是至关重要的预处理步骤。通过将大型数据文件智能分割为适当大小的片段,我们能够为LLM精准提供执行特定任务所需的信息量 - 既不会因信息过载而影响性能,也不会因信息不足而降低输出质量。
为了方便大家更好了解RAG的分块,将分块策略进行一些回顾和总结。
一、分块的重要性
分块策略在RAG(检索增强生成)系统中扮演着核心角色,其价值主要体现在三个关键维度:
- 效率优化:显著降低计算资源消耗
- 相关性提升:增强检索结果的精准度
- 上下文保持:确保信息的连贯性和完整性
同时在选择分块策略时,需要综合评估以下关键因素:
- 数据特性:结构化数据与非结构化数据的处理差异
- 查询复杂度:简单查询与复杂多跳查询的不同需求
- 资源条件:可用计算资源与响应时间要求的平衡
- 性能目标:在响应速度、结果准确性和上下文保持之间的权衡
二、RAG的典型工作流程
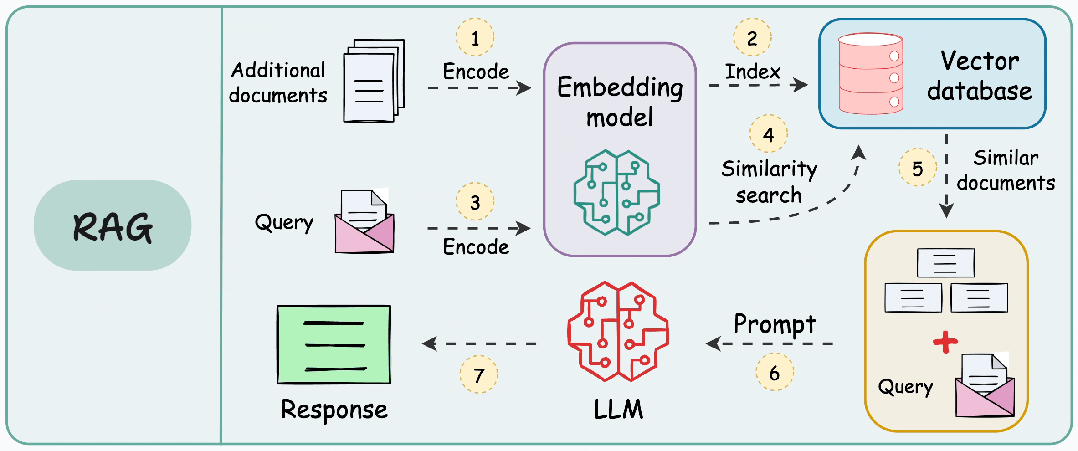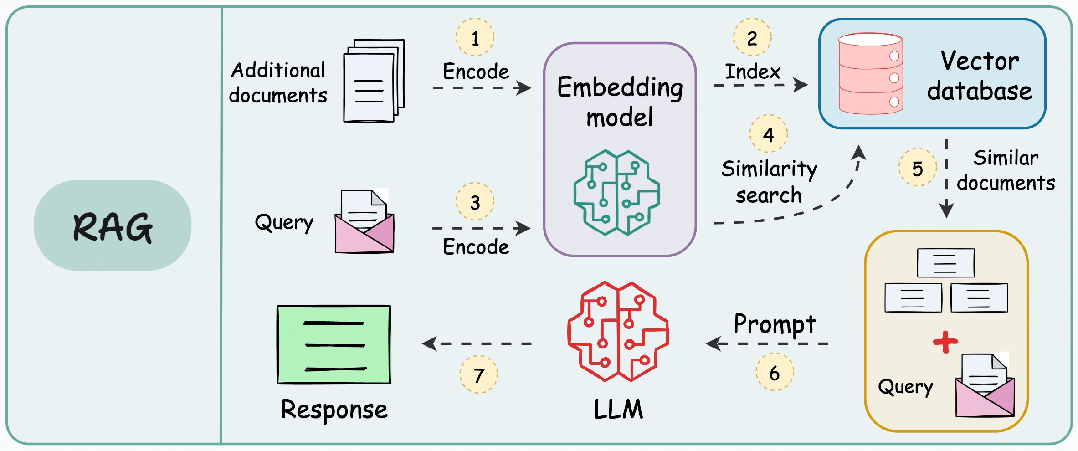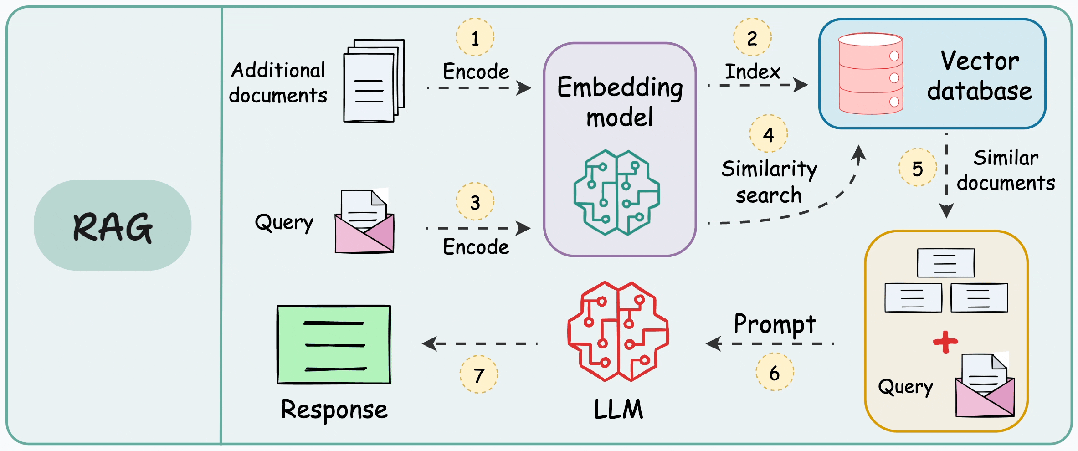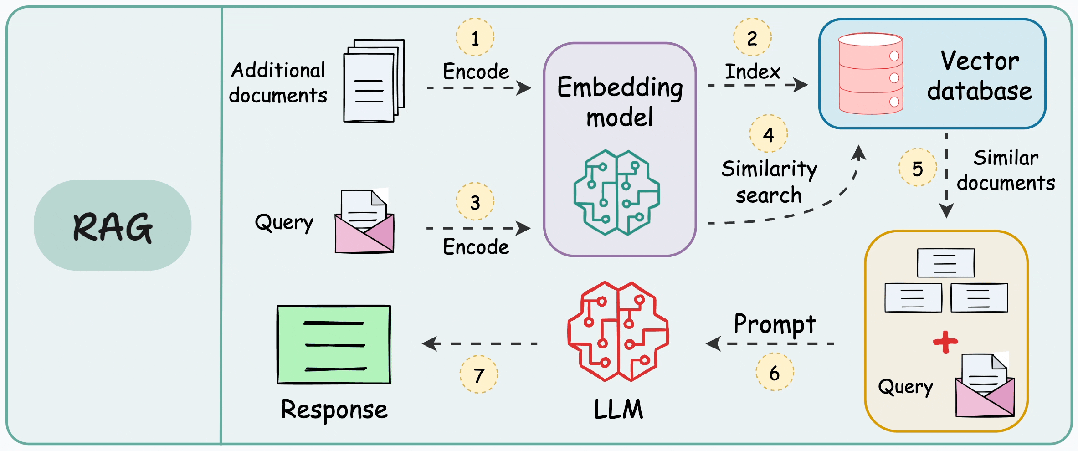
将其他信息存储为向量,将传入的查询与这些向量匹配,并将最相似的信息与查询一起提供给 LLM。
- 向量存储:将文件分块并编码,存入到向量数据库。
- 信息检索:用户输入查询,查询文本同样被编码为向量。
- 增强:将检索到的信息片段整合进发送给 LLM 的Prompt。
- 生成:LLM 基于原始问题和增强的上下文生成最终回答。
如果没有适当的分块,RAG 可能会错过关键信息或提供不完整、断章取义的响应。目标是创建在足够大以保留意义和足够小以适合模型的处理限制之间取得平衡的块。结构良好的数据块有助于确保检索系统能够准确识别文档的相关部分,然后生成模型可以使用这些部分来生成明智的响应。
三、5种分块策略详解
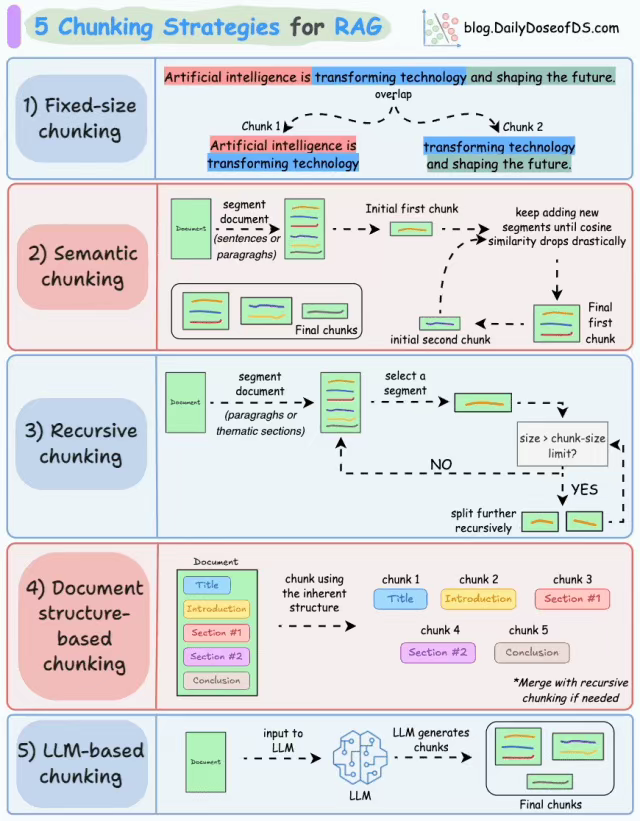
固定大小分块
生成块的最直观、最直接的方法是根据预定义的字符、单词或标记数量将文本拆分为统一的段。
优点:
- 实现简单高效,只需按字符数或Token数切分。
- 确定性结果,相同输入必然得到相同分块。
缺点:
- 语义割裂风险,暴力切割可能中断完整语义单元。
- 关键信息分散,关联内容被分配到不同块。
- 检索时可能遗漏上下文。
def fixed_size_chunk(text, max_words=100):
words = text.split()
return [' '.join(words[i:i + max_words]) for i in range(0, len(words),
max_words)]
# Applying Fixed-Size Chunking
fixed_chunks = fixed_size_chunk(sample_text)
for chunk in fixed_chunks:
print(chunk, '\n---\n')
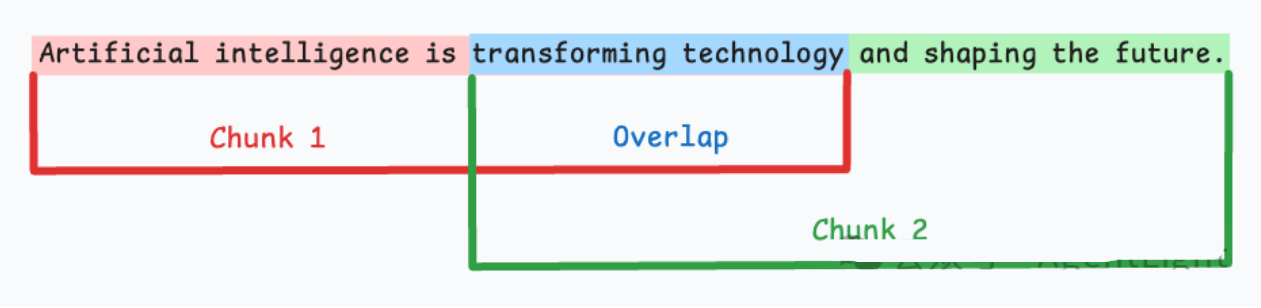
语义分块
根据有意义的单元(如句子、段落或主题部分)对文档进行分段。接下来,为每个区段创建嵌入。假设我从第一个 segment 及其嵌入开始。如果第一个段的嵌入与第二个段的嵌入具有较高的余弦相似度,则两个段将形成一个块。这种情况一直持续到余弦相似度显著下降。当它出现时,我们开始一个新的块并重复。
优点:
- 保留句子级别的含义。
- 更好的上下文保留。
缺点:
- 块大小不均匀,因为句子的长度不同。
- 当句子太长时,可能会超过模型中的标记限制。

def semantic_chunk(text, max_len=200):
doc = nlp(text)
chunks = []
current_chunk = []
for sent in doc.sents:
current_chunk.append(sent.text)
if len(' '.join(current_chunk)) > max_len:
chunks.append(' '.join(current_chunk))
current_chunk = []
if current_chunk:
chunks.append(' '.join(current_chunk))
return chunks
# Applying Semantic-Based Chunking
semantic_chunks = semantic_chunk(sample_text)
for chunk in semantic_chunks:
print(chunk, '\n---\n')
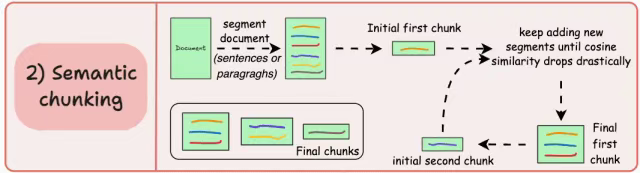
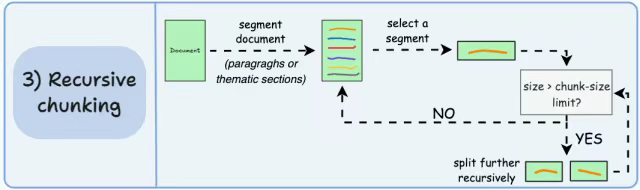
递归分块
首先,基于固有分隔符(如段落或节)进行 chunk。
接下来,如果大小超过预定义的数据块大小限制,则将每个数据块拆分为较小的数据块。但是,如果 chunk 符合 chunk-size 限制,则不会进行进一步的拆分。
优点:
- 语义完整性高,优先在自然边界(如段落结尾)分块,保持上下文连贯。
- 更好的上下文保留。
缺点:
- 实现比固定大小分块更复杂一些。
- 参数敏感,分隔符顺序和重叠量需精细调优。

def recursive_chunk(
text: str,
separators: List[str] = ["\n\n", "\n", "。", "?", "!", ". ", "? ", "! "],
chunk_size: int = 500,
chunk_overlap: int = 50,
) -> List[str]:
"""
递归分块核心算法
:param text: 输入文本
:param separators: 优先级递减的分隔符列表
:param chunk_size: 目标块大小(字符数)
:param chunk_overlap: 块间重叠量
:return: 分块结果列表
"""
chunks = []
# 终止条件:文本已小于目标块大小
if len(text) <= chunk_size:
return [text]
# 按优先级尝试每个分隔符
for sep in separators:
parts = re.split(f"({sep})", text) # 保留分隔符
parts = [p for p in parts if p.strip()] # 移除空片段
# 合并片段直到达到chunk_size
current_chunk = ""
for part in parts:
if len(current_chunk) + len(part) <= chunk_size:
current_chunk += part
else:
if current_chunk:
chunks.append(current_chunk)
current_chunk = part[-chunk_overlap:] + part if chunk_overlap > 0 else part
if current_chunk:
chunks.append(current_chunk)
# 如果成功分块则退出循环
if len(chunks) > 1:
break
# 如果没有找到合适分隔符,强制分割
if len(chunks) <= 1:
chunks = [text[i:i+chunk_size] for i in range(0, len(text), chunk_size - chunk_overlap)]
return chunks
文档基础结构分块
它利用文档的固有结构(如标题、部分或段落)来定义块边界。
这样,它通过与文档的逻辑部分保持一致来保持结构完整性。
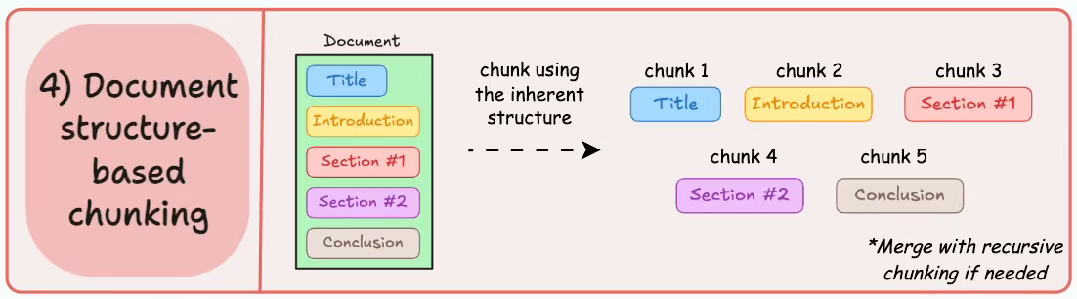
优点:
- 精准的文档保持,保留文档逻辑单元(如完整表格、代码块、章节)。
- 划分方式自然,符合人类的阅读和理解习惯。
缺点:
- 格式依赖。纯文本文件无法获取结构信息,不同格式需要不同解析器(PDF/EPUB/PPT等)。
- 生成的块大小可能差异巨大,某些块可能非常长,超出 LLM 的处理限制。

基于LLM分块
利用大型语言模型 (LLM) 自身的理解能力来判断文本的最佳分割点。

优点:
- 可识别隐含语义边界(如科研论文中的"假设-论证-结论"逻辑结构)。
- 多维度上下文感知。
缺点:
- 资源消耗问题,由于通过LLM在进行分块,计算成本高,速度慢。
- Prompt的设计复杂,并且上下文有限制。
以上就是基于RAG的5种分块策略。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献170条内容
已为社区贡献170条内容

所有评论(0)