大模型微调方法之QLoRA_qlora大模型训练方式
本文介绍大模型微调方法中的QLoRA。QLoRA由华盛顿大学UW NLP小组的成员于2023年提出发,旨在进一步降低微调大模型的微调成本,因为对于上百亿参数量的模型,LoRA微调的成本还是很高。模型介绍上图为QLoRA的训练过程图,QLoRA更多的是在工程上进行了量化和优化,从图中可知,主要有4个部分的改进:QLORA:是一种优化的4-bit量化数据类型,专为正态分布权重设计,通过结合低精度存储和
本文介绍大模型微调方法中的QLoRA。
QLoRA由华盛顿大学UW NLP小组的成员于2023年提出发,旨在进一步降低微调大模型的微调成本,因为对于上百亿参数量的模型,LoRA微调的成本还是很高。
模型介绍
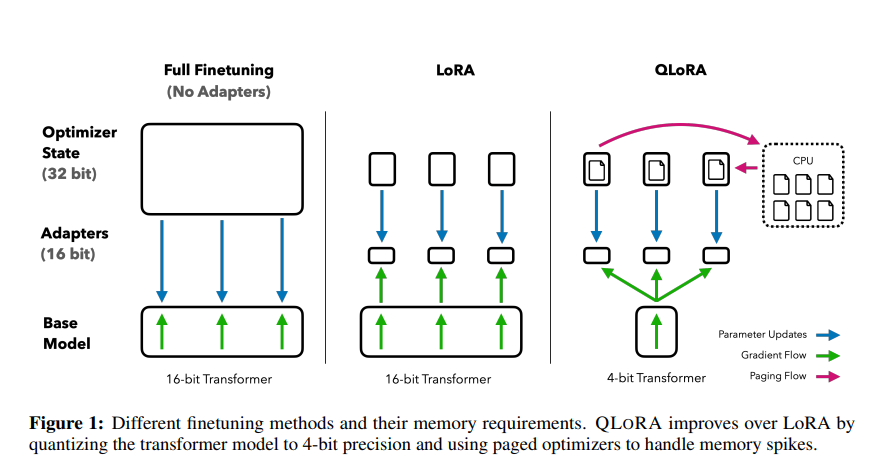
上图为QLoRA的训练过程图,QLoRA更多的是在工程上进行了量化和优化,从图中可知,主要有4个部分的改进:
-
QLORA:是一种优化的4-bit量化数据类型,专为正态分布权重设计,通过结合低精度存储和中等精度计算来提升模型性能。它使用4-bit存储权重以减少内存使用,并在计算时将权重转换为16-bit的BFloat16格式以保持准确性。这种方法适用于模型加载和训练过程,旨在平衡存储效率和计算精度。
-
Double Quantization:是一种模型量化技术,它通过对已经量化过的常量进行二次量化,进一步减少存储空间的需求。这种方法比传统的模型量化方法更能节省显存空间,每个参数平均可以节省0.37bit。例如,在65B的LLaMA模型中,这种双量化技术能够节省大约3GB的显存空间。
-
Paged Optimizers:是一种利用NVIDIA统一内存特性的优化技术,旨在解决GPU在处理过程中偶尔出现内存溢出(OOM)的问题。该技术通过自动在CPU和GPU之间进行分页到分页的数据传输,确保GPU处理过程无错误进行。其工作原理类似于CPU内存与磁盘之间的常规内存分页机制。具体来说,Paged Optimizers为优化器状态分配分页内存,当GPU内存不足时,自动将优化器状态卸载到CPU内存中;而在需要更新优化器状态时,再将其加载回GPU内存。
-
Adapter:为了弥补4-bit NormalFloat和Double Quantization带来的性能损失,作者采用了插入更多adapter的方法。在LoRA中,通常只在query和value的全连接层处插入adapter。而在QLoRA中,作者在所有全连接层处都插入了adapter,以增加训练参数并弥补由于精度降低而导致的性能损失。
Adapter实现
QLoRA的一个重要的改进和核心工作则是将量化的思想和LoRA的低秩适配器的思想结合到一起拿来对大模型进行微调,因此单独拎出来说,实现的代码如下:
if checkpoint_dir is not None:` `print("Loading adapters from checkpoint.")` `model = PeftModel.from_pretrained(model, join(checkpoint_dir, 'adapter_model'), is_trainable=True)``else:` `print(f'adding LoRA modules...')` `modules = find_all_linear_names(args, model)` `config = LoraConfig(` `r=args.lora_r,` `lora_alpha=args.lora_alpha,` `target_modules=modules,` `lora_dropout=args.lora_dropout,` `bias="none",` `task_type="CAUSAL_LM",` `)` `model = get_peft_model(model, config)
-
find_all_linear_names:找到所有的全连接层 -
get_peft_model:在所有全连接层中插入LoRA模块
如何系统学习掌握AI大模型?
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享**
一、2025最新大模型学习路线
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:AI大模型时代的华丽登场
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;通过理论原理结合多个项目实战,从提示工程基础到提示工程进阶,掌握Prompt提示工程。

L2级别:AI大模型RAG应用开发工程
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3级别:大模型Agent应用架构进阶实践
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。

L4级别:大模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

整个大模型学习路线L1主要是对大模型的理论基础、生态以及提示词他的一个学习掌握;而L3 L4更多的是通过项目实战来掌握大模型的应用开发,针对以上大模型的学习路线我们也整理了对应的学习视频教程,和配套的学习资料。
二、大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

三、大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

四、大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

五、大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献170条内容
已为社区贡献170条内容

所有评论(0)