MySQL调优之Explain详解与索引优化实践
1、概述
Explain可以理解成MySQL提供给sql编写人员的调试工具,通过这个工具可以感知到sql在存储引擎中具体执行路径是什么,以此为依据来判断sql优化结果是否符合预期。
后文分为2部分:Explain工具介绍 和 sql调优实践示例。通过这2部分来帮助读者(当然也包括作者自己)快速熟悉使用Explain工具调优整个过程。
说明
1、本文理论知识基于存储引擎InnoDB + MySQL版本5.7。
2、Explain工具介绍
一般用法,在select 语句前面加上explain关键字,这样在查询的时候MySQL就会返回执行计划信息:
MariaDB [wang_test]> explain select * from t_user;
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | t_user | ALL | NULL | NULL | NULL | NULL | 1 | |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
这些字段每个都有自己的含义,具体在后文进一步介绍。
特别说明,当from中包含子查询时,依旧会执行该子查询并放入临时表中,当然这个子查询必须是复杂的(不然会被优化器优化掉),例如包含union、聚合等操作。
本小节后文以如下表结构为示例:
CREATE TABLE IF NOT EXISTS `t_user`(
`id` bigint(50) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_name` varchar(255) NOT NULL COMMENT '用户姓名',
`email_address` varchar(255) NOT NULL DEFAULT '' COMMENT '邮箱',
`last_modified_time` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp () COMMENT '数据库记录上一次更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 COMMENT = '用户信息表';
insert into t_user (id, user_name, email_address) values (1, '王霄一', 'wangmyyau@qq.com');
CREATE TABLE IF NOT EXISTS `t_address`(
`id` bigint(50) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`address` varchar(255) NOT NULL DEFAULT '' COMMENT '收货地址',
`last_modified_time` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp () COMMENT '数据库记录上一次更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 COMMENT = '用户收货地址表';
insert into t_address (id, address) values (8, '四川省成都市二仙桥大道');
CREATE TABLE IF NOT EXISTS `t_user2address`(
`id` bigint(50) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` bigint(50) NOT NULL COMMENT '[关联表t_user] 用户ID',
`address_id` bigint(50) NOT NULL COMMENT '[关联表t_address] 用户收货地址',
`last_modified_time` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp () COMMENT '数据库记录上一次更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 COMMENT = '用户与收货地址关联表';
insert into t_user2address (user_id, address_id) values (1, 8);
2.1、Explain工具其它关键字
在explain关键字的基础上还可以加上extended或partitions关键字使MySQL返回的执行计划更加的具体。
2.1.1、explain extended + select查询语句,可以多返回一列字段filtered,用于估算查询连接范围集大小:
MariaDB [wang_test]> explain extended select * from t_user;
+------+-------------+--------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+------+-------------+--------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t_user | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | |
+------+-------------+--------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.000 sec)
MariaDB [wang_test]> select count(*) from t_user;
+----------+
| count(*) |
+----------+
| 1 |
+----------+
1 row in set (0.000 sec)
估算值 = rows * filtered/100
实际上,当前t_user表中确实仅有1条数据。(1 * 100 / 100 = 1), 如果是联表查询,rows的取值是目标表的行数。
除了多返回一列字段filtered,再紧接着执行show warning时可以直接看到MySQL优化后的sql长啥样。(这个就很有用了):
MariaDB [wang_test]> explain extended select * from (select * from t_user) as tmp;
+------+-------------+--------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+------+-------------+--------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t_user | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | |
+------+-------------+--------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.000 sec)
MariaDB [wang_test]> show warnings;
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Note | 1003 | select `wang_test`.`t_user`.`id` AS `id`,`wang_test`.`t_user`.`user_name` AS `user_name`,`wang_test`.`t_user`.`email_address` AS `email_address`,`wang_test`.`t_user`.`last_modified_time` AS `last_modified_time` from `wang_test`.`t_user` |
+-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.000 sec)
这里就可以明显看出,把冗余的子查询给直接优化掉了。这样就直接去掉了内存临时表的额外开销。
2.1.2、explain partitions + select查询语句,可以多返回一列字段partitions
该partitions字段用于表示要访问的分区,MySQL提供自己的分区功能,但是我实际上也没用过。。。。。这里仅做了解吧。
同时生产上面分区方案,也不会直接使用MySQL直接提供的这个, 我觉得最主要的原因还是MySQL自身维护数据存储已经开销很大了,再继续维护分区的话,将直接裂开,导致性能整体下滑:
MySQL分区功能限制多、维护复杂、性能收益有限,加上现在有更好的分库分表中间件和云原生数据库方案,所以在生产环境中使用较少。对于大多数场景,通过合理的索引设计、读写分离、缓存策略等方式,能够更好地解决性能问题。
MariaDB [wang_test]> explain partitions select * from t_user;
+------+-------------+--------+------------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+------------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | t_user | NULL | ALL | NULL | NULL | NULL | NULL | 1 | |
+------+-------------+--------+------------+------+---------------+------+---------+------+------+-------+
1 row in set (0.000 sec)
2.2、Explain结果各列详细说明
explain返回的执行计划中有10列字段,一下将逐一进行说明。
MariaDB [wang_test]> explain select * from t_user;
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | t_user | ALL | NULL | NULL | NULL | NULL | 1 | |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
1 row in set (0.000 sec)
2.2.1、id
1、一个复杂查询sql中多少个select关键字,执行结果的返回值对应的就有多少行(id)。
2、该执行结果集中的id值越大,代表越先被执行。
3、该执行结果集中的id值相同,则从上往下执行。
4、该执行结果集中的id值为NULL,则最后执行。
2.2.2、select_type
顾名思义,查询的类型:
1、simple:简单查询,仅一个查询。
2、primary:主查询,复杂查询中最外层的查询。
3、subquery:子查询,但是不包含在from中。
4、derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含 义)
MariaDB [wang_test]> set session optimizer_switch='derived_merge=off'; #关闭对衍生表的合并优化
Query OK, 0 rows affected (0.000 sec)
MariaDB [wang_test]> explain select (select 1 from t_user where id = 1) from (select * from t_address where id = 8) tmp;
+------+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
| 1 | PRIMARY | <derived3> | system | NULL | NULL | NULL | NULL | 1 | |
| 3 | DERIVED | t_address | const | PRIMARY | PRIMARY | 8 | const | 1 | |
| 2 | SUBQUERY | t_user | const | PRIMARY | PRIMARY | 8 | const | 1 | Using index |
+------+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
3 rows in set (0.001 sec)
MariaDB [wang_test]> set session optimizer_switch='derived_merge=on';
Query OK, 0 rows affected (0.000 sec)
可以看到有三个select_type, 能与上述对应上。
另外select (select 1 from t_user where id = 1) from (select * from t_address where id = 8) tmp;的作用说明:
1)查询结果集每多一行, (select 1 from t_user where id = 1) 就会被执行一次。
2)这个整条sql的作用是:当存在t_address的记录id为8时,检查是否存在t_user的记录ID为1。 如果存在,则输出1,通常用于存在检查。
5、union:使用union关键字则有
MariaDB [wang_test]> explain select 1 union all select 1;
+------+-------------+-------+------+---------------+------+---------+------+------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+----------------+
| 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 2 | UNION | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+------+-------------+-------+------+---------------+------+---------+------+------+----------------+
2 rows in set (0.000 sec)
2.2.3、table
1、代表该行的执行计划访问的表(或者说本质上是数据源)。
2、当是deriven${N} 格式,表示当前执行计划行依赖执行计划结果集中 id=N 的执行结果,于是先执行 id=N 的执行计划查询,从上面的例子能看出来。
3、当有 union 时,select_type为UNION RESULT 的 table 列的值为<union1,2>,1和2表示参与 union 的 执行计划id。
+----+--------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
| 1 | PRIMARY | t_user | ref | idx_status | ... | ... | ... | 100 | 100.00 | Using where |
| 2 | UNION | t_address | ref | idx_status | ... | ... | ... | 50 | 100.00 | Using where |
| NULL| UNION RESULT | <union1,2>| ALL | NULL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------+---------------+------+---------+------+------+----------+-----------------+
2.2.4、partitions
上面有提到,是MySQL本身的分区。属于explain partitions 关键字才有的执行结果。
2.2.5、type
重要:我们优化是否达到了预期,实际上大多是看这个字段的值。也就是MySQL的执行类型,通过什么方式去查询。
1、按照类型的效率排序,主要分为:system > const > eq_ref > ref > range > index > all
2、另外有一个特殊的情况,就是NULL,是指在不执行查询表或索引时,仅在sql的优化阶段就可以确定返回值时的情况:
MariaDB [wang_test]> explain select min(id) from t_user;
+------+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+------+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
1 row in set (0.000 sec)
说明
1、优化器发现有min、max则直接检查id是否是索引,如果是,则直接访问B+树的最左子叶或者最右子叶,完全不需要经过扫描。
2、当然表自身也维护了表总大小的近似值等元数据,也不需要访问索引和表:
MariaDB [wang_test]> SELECT TABLE_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'wang_test' and TABLE_NAME = 't_user';
+------------+------------+
| TABLE_NAME | TABLE_ROWS |
+------------+------------+
| t_user | 1 |
+------------+------------+
1 row in set (0.000 sec)
2.2.5.1、system
查询源中,仅有一个常量元组(说白了就是,直接可以把sql语句中的from作为查询源拿来用):
MariaDB [wang_test]> explain select * from (select 1 as id, '王霄一' as name) as tmp;
+------+-------------+------------+--------+---------------+------+---------+------+------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+------------+--------+---------------+------+---------+------+------+----------------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+------+-------------+------------+--------+---------------+------+---------+------+------+----------------+
2 rows in set (0.000 sec)
2.2.5.2、const
常量级,也就是查找次数是确定一次就可以找到的,比如通过主键索引、唯一索引找,那么查询次数必定仅有一次:
MariaDB [wang_test]> explain select * from t_user where id = 1;
+------+-------------+--------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | t_user | const | PRIMARY | PRIMARY | 8 | const | 1 | |
+------+-------------+--------+-------+---------------+---------+---------+-------+------+-------+
1 row in set (0.000 sec)
2.2.5.3、eq_ref
2表联合查询,仅使用主键索引或唯一索引(如果这2个索引为复合索引,那么条件必须是它的所有字段)。
MariaDB [wang_test]> explain select * from t_user u1 left join t_user u2 on u1.id = u2.id;
+------+-------------+-------+--------+---------------+---------+---------+-----------------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+--------+---------------+---------+---------+-----------------+------+-------+
| 1 | SIMPLE | u1 | ALL | NULL | NULL | NULL | NULL | 1 | |
| 1 | SIMPLE | u2 | eq_ref | PRIMARY | PRIMARY | 8 | wang_test.u1.id | 1 | |
+------+-------------+-------+--------+---------------+---------+---------+-----------------+------+-------+
2 rows in set (0.000 sec)
2.2.5.4、ref
1、简单查询中用到了非唯一索引(包括非主键索引)或者唯一索引的最左前缀。-- 说白了就是仅用上了普通索引。(当然有一个前提,where的判断条件是使用等号‘=’)
MariaDB [wang_test]> alter table t_user add index idx_name (user_name) ; # 增加一个user_name普通索引
Query OK, 0 rows affected (0.017 sec)
Records: 0 Duplicates: 0 Warnings: 0
MariaDB [wang_test]> explain select * from t_user where user_name = 'xx';
+------+-------------+--------+------+---------------+----------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+------+---------------+----------+---------+-------+------+-----------------------+
| 1 | SIMPLE | t_user | ref | idx_name | idx_name | 1022 | const | 1 | Using index condition |
+------+-------------+--------+------+---------------+----------+---------+-------+------+-----------------------+
1 row in set (0.001 sec)
2、同理,在联表查询时,也仅使用普通索引(包括左前缀唯一复合索引)作为联结条件,也是一样的ref。
2.2.5.5、range
使用索引进行范围查找(包括主键索引、唯一索引)。范围查找是指(<、>、=、in、between)。 – like不算
MariaDB [wang_test]> explain select * from t_user where id in (1, 2);
+------+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | t_user | range | PRIMARY | PRIMARY | 8 | NULL | 1 | Using where |
+------+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
1 row in set (0.000 sec)
MariaDB [wang_test]>
MariaDB [wang_test]> explain select * from t_user where user_name in ('xx', 'aa'); # user_name上面示例中加了普通索引
+------+-------------+--------+-------+---------------+----------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+-------+---------------+----------+---------+------+------+-----------------------+
| 1 | SIMPLE | t_user | range | idx_name | idx_name | 1022 | NULL | 1 | Using index condition |
+------+-------------+--------+-------+---------------+----------+---------+------+------+-----------------------+
1 row in set (0.000 sec)
2.2.5.6、index_merge(8/31 补充)
where条件中包含了多个索引的情况,并且为了获取结果集还需要合并。
MariaDB [wang_test]> ALTER TABLE t_user ADD INDEX idx_user_name (user_name); -- 添加索引,模拟多索引情况
Query OK, 0 rows affected, 1 warning (0.024 sec)
Records: 0 Duplicates: 0 Warnings: 1
MariaDB [wang_test]> ALTER TABLE t_user ADD INDEX idx_email_address (email_address); -- 添加索引,模拟多索引情况
Query OK, 0 rows affected (0.014 sec)
Records: 0 Duplicates: 0 Warnings: 0
MariaDB [wang_test]> EXPLAIN SELECT * FROM t_user force INDEX (idx_user_name, idx_email_address) WHERE user_name = 'xx' OR email_address = 'xx'; -- 数据量少,如果不加force index强制走index_merge,会全表扫描,这里只是为了效果演示
+------+-------------+--------+-------------+---------------------------------+---------------------------------+-----------+------+------+-----------------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+-------------+---------------------------------+---------------------------------+-----------+------+------+-----------------------------------------------------------+
| 1 | SIMPLE | t_user | index_merge | idx_user_name,idx_email_address | idx_user_name,idx_email_address | 1022,1022 | NULL | 1 | Using union(idx_user_name,idx_email_address); Using where |
+------+-------------+--------+-------------+---------------------------------+---------------------------------+-----------+------+------+-----------------------------------------------------------+
1 row in set (0.000 sec)
MariaDB [wang_test]> ALTER TABLE t_user DROP INDEX idx_user_name; -- 还原索引
Query OK, 0 rows affected (0.011 sec)
Records: 0 Duplicates: 0 Warnings: 0
MariaDB [wang_test]> ALTER TABLE t_user DROP INDEX idx_email_address; -- 还原索引
Query OK, 0 rows affected (0.011 sec)
Records: 0 Duplicates: 0 Warnings: 0
其实本质上属于范围查询,但是最后还涉及到额外的合并开销,因此判定速度比range慢,并且有可能不回表,就也判定比index快。
2.2.5.7、index
名覆盖索引,即不从B+树根节点开始查找,而是直接查找二级索引的叶子节点就可以拿到select所需的全字段(不用回表),比扫描全表快些。
MariaDB [wang_test]> explain select id,user_name from t_user ; # user_name在上面有添加普通索引
+------+-------------+--------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+-------+---------------+----------+---------+------+------+-------------+
| 1 | SIMPLE | t_user | index | NULL | idx_name | 1022 | NULL | 1 | Using index |
+------+-------------+--------+-------+---------------+----------+---------+------+------+-------------+
1 row in set (0.000 sec)
2.2.5.8、ALL
需要扫描全表(全聚簇索引)才能拿到数据结果。(最low的)
MariaDB [wang_test]> explain select * from t_user;
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | t_user | ALL | NULL | NULL | NULL | NULL | 1 | |
+------+-------------+--------+------+---------------+------+---------+------+------+-------+
1 row in set (0.000 sec)
2.2.6、possible_keys
possible_keys列显示查询可能使用哪些索引来查找,而实际使用了哪个索引由key列决定。
explain 时可能出现 possible_keys 有值,而 key列 显示 NULL 的情况,这种情况有可能是因为表中数据不多,优化器认为索引对 此查询帮助不大,选择了全表查询。
如果possible_keys列是NULL,则代表没有where子句没有匹配上相关的索引。
2.2.7、key
1、上面提到过,用于显示当前执行计划实际会用到索引。
2、另外值得一提的是:如果想强制执行计划使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。(但是不推荐这么干,因为执行计划运行至今,已经积累了太多自己的经验,可以值得相信)
2.2.8、key_len
顾名思义,就是索引字段的长度。
示例:
有一个索引: idx_address(id, address_id), 其中id字段为bigint占8字节,address_id也占8个字节,加在一起是16字节,那么这个索引key idx_address的key_len 就是16。
这里就涉及到一些各个表字段类型占用多少字段的知识:
char(n):如果存汉字长度就是 3n 字节
tinyint:1字节 smallint:2字节 int:4字节 bigint:8字节
时间类型 date:3字节
timestamp:4字节
datetime:8字节
字符串,char(n)和varchar(n),n均代表字符数,而不是字节数,如果是utf-8,一个数字或字母占1个字节,一个汉字 占3个字节varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长度,因为varchar是变长字符串 数值类型如果字段允许为 NULL,需要1字节记录是否为 NULL索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
2.2.9、ref
具体是执行计划进行查找时所用到的字段,上面的用例中可以观察到。
说明
1、const:用到的是常量
2、t_user.id: 用到了id字段
2.2.10、rows
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
2.2.11、filtered
上面提过是估算的,与目标表连接将会扫描的预估行数。(公式 rows * filtered / 100),其中rows就是连接目标表要检测的函数,也就是执行计划结果集中的rows列。
2.2.12、Extra
扩展列,用于显示执行计划的内部细节内容:
1、Using index: 使用了覆盖索引。
2、Using where: 全表扫描(不会借助任何索引) + 条件
MariaDB [wang_test]> explain select * from t_address where address = 'xx';
+------+-------------+-----------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-----------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t_address | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
+------+-------------+-----------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.000 sec)
3、Using index condition: 使用了索引,但是没用上覆盖索引(也就是走索引 + 回表):
MariaDB [wang_test]> explain select * from t_user where user_name = 'xx'; # user_name的普通索引中没有除了id 和 user_name的其它字段
+------+-------------+--------+------+---------------+----------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+--------+------+---------------+----------+---------+-------+------+-----------------------+
| 1 | SIMPLE | t_user | ref | idx_name | idx_name | 1022 | const | 1 | Using index condition |
+------+-------------+--------+------+---------------+----------+---------+-------+------+-----------------------+
1 row in set (0.000 sec)
4、Using temporary:为了完成本条,使用了临时表,也是没有加索引的情况下:
MariaDB [wang_test]> explain select distinct address from t_address; # address没有索引,为了去重只能额外借助临时表
+------+-------------+-----------+------+---------------+------+---------+------+------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-----------+------+---------------+------+---------+------+------+-----------------+
| 1 | SIMPLE | t_address | ALL | NULL | NULL | NULL | NULL | 1 | Using temporary |
+------+-------------+-----------+------+---------------+------+---------+------+------+-----------------+
1 row in set (0.000 sec)
5、Using filesort:使用了order by排序,但是排序依据没有加索引,只能全部load出来,临时硬排序。
MariaDB [wang_test]> explain select address from t_address order by address;
+------+-------------+-----------+------+---------------+------+---------+------+------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-----------+------+---------------+------+---------+------+------+----------------+
| 1 | SIMPLE | t_address | ALL | NULL | NULL | NULL | NULL | 1 | Using filesort |
+------+-------------+-----------+------+---------------+------+---------+------+------+----------------+
1 row in set (0.000 sec)
6、Select tables optimized away:
翻译过来是:选择已优化的表
实际上就是和上文提到的type为null一样的结果,就是sql在优化阶段发现不需要去走索引和表。例如min、max。
MariaDB [wang_test]> explain select min(id) from t_user;
+------+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+------+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
1 row in set (0.000 sec)
3、SQL调优实践示例
3.1、一般场景示例
以下都使用如下表演示(其中有一个普通的复合索引idx_name_build_addr):
CREATE TABLE IF NOT EXISTS `t_house`(
`id` bigint(50) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(18) NULL COMMENT '房屋名称',
`buid_years` int(4) NULL COMMENT '已经修建年数',
`address` varchar(255) NULL COMMENT '房屋地址',
`last_modified_time` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp () COMMENT '数据库记录上一次更新时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name_build_addr`(`name`, `buid_years`, `address`) USING BTREE COMMENT '普通索引'
) ENGINE = InnoDB AUTO_INCREMENT = 1 COMMENT = '房屋表';
3.1.1、左前缀法则
当是复合索引时,只要where的条件中使用的左前缀时,尽管没有包括上复合索引的全字段,也会走该索引:
1、仅包含name:
MariaDB [wang_test]> explain select * from t_house where name = 'xx';
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | t_house | ref | idx_name_build_addr | idx_name_build_addr | 75 | const | 1 | Using index condition |
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+-----------------------+
1 row in set (0.001 sec)
2、仅包含name和buid_years
MariaDB [wang_test]> explain select * from t_house where name = 'xx' and buid_years = 8;
+------+-------------+---------+------+---------------------+---------------------+---------+-------------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+---------------------+---------+-------------+------+-----------------------+
| 1 | SIMPLE | t_house | ref | idx_name_build_addr | idx_name_build_addr | 80 | const,const | 1 | Using index condition |
+------+-------------+---------+------+---------------------+---------------------+---------+-------------+------+-----------------------+
1 row in set (0.000 sec)
3、全量匹配
MariaDB [wang_test]> explain select * from t_house where name = 'xx' and buid_years = 8 and address = 'xx';
+------+-------------+---------+------+---------------------+---------------------+---------+-------------------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+---------------------+---------+-------------------+------+-----------------------+
| 1 | SIMPLE | t_house | ref | idx_name_build_addr | idx_name_build_addr | 1103 | const,const,const | 1 | Using index condition |
+------+-------------+---------+------+---------------------+---------------------+---------+-------------------+------+-----------------------+
1 row in set (0.000 sec)
4、反例,不遵循最左前缀
1)仅用address
MariaDB [wang_test]> explain select * from t_house where address = 'xx';
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t_house | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.000 sec)
2)仅使用buid_time 和 address:
MariaDB [wang_test]> explain select * from t_house where buid_years = 8 and address = 'xx';
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t_house | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.000 sec)
3)仅使用name和address:
MariaDB [wang_test]> explain select * from t_house where name = 'xx' and address = 'xx';
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | t_house | ref | idx_name_build_addr | idx_name_build_addr | 75 | const | 1 | Using index condition |
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+-----------------------+
1 row in set (0.000 sec)
特别注意:这里仅用到了该索引里面的一个字段name,buid_time和address并没有走索引。
3.1.2、不能在索引上面左任何计算(函数)操作
反例
MariaDB [wang_test]> explain select * from t_house where left(name,3) = 'xx';
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t_house | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.000 sec)
因为经过函数之后的值,在索引B+树上面是不直接存在的,不方便继续走索引了。
3.1.3、尽量使用覆盖索引
大家应该听过过,阿里巴巴开发手册上面建议尽量不要用select *,其实大致其中一个原因就是建议尽量仅查询索引就有的字段,方便走覆盖索引。(减少回表开销)
3.1.4、不使用“不等于”操作,会导致无法走索引
前面提到,type为range时,代表用索引走范围查询,针对的是in、<、>等范围性的。
但是如果使用“不等于”操作,例如a != 1, 那么就算a加了索引,但是优化器分析下来,有大半可能走全表扫描更划算(例如表中的数据有10w+)。因此在业务场景中尽量不用“不等于”操作(!=、<>、not in等)
3.1.5、is null,is not null 一般情况下也无法使用索引
这个跟MySQL的索引结构有关,NULL值的索引一般会集中放在索引的最左端,或者最右端,有些时候,不走索引,直接走全表扫描可能会更快些。
3.1.6、like以通配符开头(‘$abc…’)mysql索引失效会变成全表扫描操作
这个很容易理解,前面如果不确定的话,肯定就没法扫描已经排序好的B+树了,跟前缀匹配一个道理。
反例
MariaDB [wang_test]> explain select * from t_house where name like '%x';
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t_house | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
+------+-------------+-----
如果非要优化这个场景的话,可以退而求其次,走覆盖索引。
实在没办法的话,只能用其他搜索引擎,例如es。
3.1.7、字符串不加单引号索引失效
类型都不同,跟上面提到的where中包含操作函数一样,会失效。
反例
MariaDB [wang_test]> explain select * from t_house where name = 9;
+------+-------------+---------+------+---------------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+------+---------+------+------+-------------+
| 1 | SIMPLE | t_house | ALL | idx_name_build_addr | NULL | NULL | NULL | 1 | Using where |
+------+-------------+---------+------+---------------------+------+---------+------+------+-------------+
1 row in set, 1 warning (0.000 sec)
3.1.8、少用or或in,用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评估 是否使用索引,详见范围查询优化
3.2、复杂场景示例
这里主要收集了一些相对更深层次的优化方向、方案和特殊情况。-- 上述“3.1、一般场景”小节只是大多数的情况,这里主要是简述MySQL经过自身优化后的一些特殊情况补充。
同样,以下都使用如下表演示(其中有一个普通的复合索引idx_name_build_addr,同时存储过程能生成10w条随机数据):
CREATE TABLE IF NOT EXISTS `t_house`(
`id` bigint(50) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(18) NULL COMMENT '房屋名称',
`buid_years` int(4) NULL COMMENT '已经修建年数',
`address` varchar(255) NULL COMMENT '房屋地址',
`last_modified_time` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp () COMMENT '数据库记录上一次更新时间',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name_build_addr`(`name`, `buid_years`, `address`) USING BTREE COMMENT '普通索引'
) ENGINE = InnoDB AUTO_INCREMENT = 1 COMMENT = '房屋表';
-- 以下是插入10万条随机数据的存储过程,下文示例有用
DELIMITER //
CREATE PROCEDURE InsertRandomHouseData()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE random_name VARCHAR(18);
DECLARE random_years INT;
DECLARE random_address VARCHAR(255);
-- 插入10万条数据
WHILE i < 100000 DO
-- 生成随机房屋名称 (5-10个字符)
SET random_name = SUBSTRING(MD5(RAND()), 1, 5 + FLOOR(RAND() * 6));
-- 生成随机修建年数 (1-100年)
SET random_years = FLOOR(1 + RAND() * 100);
-- 生成随机地址 (10-30个字符)
SET random_address = SUBSTRING(MD5(RAND()), 1, 10 + FLOOR(RAND() * 21));
-- 插入数据
INSERT INTO t_house (name, buid_years, address)
VALUES (random_name, random_years, random_address);
SET i = i + 1;
END WHILE;
end //
DELIMITER ;
CALL InsertRandomHouseData();
3.2.1、二级索引中,第一个是范围查询有可能不会走索引
不会走索引示例:
MariaDB [wang_test]> explain select * from t_house where name > '1' and buid_years = 8 and address = 'xx';
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | t_house | ALL | idx_name_build_addr | NULL | NULL | NULL | 99769 | Using where |
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
1 row in set (0.000 sec)
走索引示例:
MariaDB [wang_test]> explain select * from t_house where name > 'fffda66d' and buid_years = 8 and address = 'xx';
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+-----------------------+
| 1 | SIMPLE | t_house | range | idx_name_build_addr | idx_name_build_addr | 75 | NULL | 2 | Using index condition |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+-----------------------+
1 row in set (0.000 sec)
结果分析
1> 不走索引的示例中,实际的rows(扫描行数)是9w,说明name>"1"的数据有9w多行。确实分析下来,走全表扫描比走9w次索引更快。
MariaDB [wang_test]> select count(*) from t_house where name > '1';
+----------+
| count(*) |
+----------+
| 93754 |
+----------+
1 row in set (0.029 sec)
2> 走索引的示例中,可以反推出来,说明name>"fffda66d"的结果集不会太大,走几次索引就很快能拿到结果集,自然走索引就更快。实际上,name>"fffda66d"的结果集是2条, rows(扫描行数)也是2。
MariaDB [wang_test]> select * from t_house where name > 'fffda66d';
+-------+------------+------------+---------------------+---------------------+
| id | name | buid_years | address | last_modified_time |
+-------+------------+------------+---------------------+---------------------+
| 98034 | ffff03fcc0 | 98 | ef984a6c0b0 | 2025-08-30 23:40:05 |
| 71079 | ffff13f31 | 12 | fb00759ab739ada9851 | 2025-08-30 23:38:53 |
+-------+------------+------------+---------------------+---------------------+
2 rows in set (0.000 sec)
3> 综上所述,其实MySQL提供强制走索引的关键字force index的功能,但是我们尽量也不用去用它,因为其优化器做的执行计划比我们想象的更好。
3.2.2、索引下推
走索引示例:
MariaDB [wang_test]> explain select * from t_house where name like 'e%' and buid_years = 8 and address = 'xx';
+------+-------------+---------+-------+---------------------+---------------------+---------+------+-------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+-------+-----------------------+
| 1 | SIMPLE | t_house | range | idx_name_build_addr | idx_name_build_addr | 1103 | NULL | 12066 | Using index condition |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+-------+-----------------------+
1 row in set (0.000 sec)
不走索引示例:
MariaDB [wang_test]> explain select * from t_house where name > 'e' and buid_years = 8 and address = 'xx';
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | t_house | ALL | idx_name_build_addr | NULL | NULL | NULL | 99769 | Using where |
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
1 row in set (0.000 sec)
结果分析
1> 看似上面2个例子同样都是范围,实则不然。 第一个走索引的示例like 'xxx%'实际上用到了索引下推(MySQL 5.6+版本引入的优化)。
2> MySQL5.6之前的版本,会先用like 'xxx%'在二级索引中过滤出结果集id列表,然后回表全部记录load出来,再继续过滤buid_years = 8 and address = ‘xx’;
3> 索引下推则是直接在用like 'xxx%'在二级索引中过滤出结果集id列表的时候,同时判断buid_years = 8 and address = ‘xx’ 是否符合,如果符合才把id加入结果集,最后回表通过结果集id列表查询出所有数据,并返回。
4> 在2>和3>的比对之下,3>完全利用了buid_years、address索引字段且回表的结果集id列表更少,效率更高。
5> 那为什么>就不能像like一样使用索引下推? 分析下来,有可能是>的结果集比like相比之下更大,同时做buid_years = 8 and address = 'xx’的过滤时,次数也就越多,开销就越大,不划算了。
3.2.3、MySQL如何选择走合适的索引
上面3.2.1 3.2.1都到MySQL有一套自己的执行计划策略,那么我们如何进一步知道呢?
例如同样是>条件,但是有的会走索引,有的不会走索引。
走索引示例:
MariaDB [wang_test]> explain select * from t_house where name > 'fffda66d';
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+-----------------------+
| 1 | SIMPLE | t_house | range | idx_name_build_addr | idx_name_build_addr | 75 | NULL | 2 | Using index condition |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+-----------------------+
1 row in set (0.000 sec)
不走索引示例
MariaDB [wang_test]> explain select * from t_house where name > 'a';
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | t_house | ALL | idx_name_build_addr | NULL | NULL | NULL | 99769 | Using where |
+------+-------------+---------+------+---------------------+------+---------+------+-------+-------------+
1 row in set (0.000 sec)
结果分析
1> MySQL有一套自己的cost成本计算结果,可以使用MySQL提供的trace工具查看。
MariaDB [wang_test]> SET SESSION optimizer_trace='enabled=on'; -- 开启trace
Query OK, 0 rows affected (0.000 sec)
MariaDB [wang_test]> select * from t_house where name > 'a'; -- 执行要使用trace查看的sql
MariaDB [wang_test]> SELECT * FROM information_schema.OPTIMIZER_TRACE; -- 查看trace结果,结果内容仅太多,这里仅列关键内容
steps.join_preparation -- 第一阶段格式化sql,示例:select t_house.`id` AS `id`,t_house.`name` AS `name`,t_house.buid_years AS buid_years,t_house.address AS address,t_house.last_modified_time AS last_modified_time from t_house where t_house.`name` > 'a'
steps.join_optimization -- 第二阶段sql优化,
steps.join_optimization.condition_processing -- 条件处理:1> 去掉1=1这种无效条件 2> 分析能不能改变and顺序就可以用上联合索引 等等 通过这里就可以看出来,优化等操作尽量不要交给mysql自己来做
steps.join_optimization.rows_estimation.range_analysis.table_scan -- 预估表的访问成本(注意:这是不走索引的全表扫描成本)
steps.join_optimization.rows_estimation.range_analysis.table_scan.rows -- 扫描的行数
steps.join_optimization.rows_estimation.range_analysis.table_scan.cost -- 查询成本(依据表记录行数、回表情况等)
steps.join_optimization.rows_estimation.range_analysis.potential_range_indexes -- 查询可能使用到的索引
steps.join_optimization.rows_estimation.range_analysis.potential_range_indexes -- 查询可能使用到的索引
steps.join_optimization.rows_estimation.range_analysis.potential_range_indexes.usable -- 最终有没有用到该索引
steps.join_optimization.rows_estimation.range_analysis.potential_range_indexes.cause -- 没用上的原因
steps.join_optimization.rows_estimation.range_analysis.potential_range_indexes.key_parts -- 用到的索引字段部分
steps.join_optimization.rows_estimation.analyzing_range_alternatives.range_scan_alternatives -- 分析每个索引的成本
steps.join_optimization.rows_estimation.analyzing_range_alternatives.range_scan_alternatives.index -- 索引名称
steps.join_optimization.rows_estimation.analyzing_range_alternatives.range_scan_alternatives.rows -- 走该索引的扫描行数
steps.join_optimization.rows_estimation.analyzing_range_alternatives.range_scan_alternatives.cost -- 走该索引的查询开销
steps.join_optimization.rows_estimation.analyzing_range_alternatives.range_scan_alternatives.chosen -- 最终有没有选择这个索引
steps.join_optimization.rows_estimation.analyzing_range_alternatives.range_scan_alternatives.cause -- 最终没有选择这个索引的原因
steps.join_optimization.steps.considered_execution_plans.get_costs_for_tables.best_access_path -- 最优选择路径结果
MariaDB [wang_test]> SET SESSION optimizer_trace='enabled=off'; -- 最后关闭trace,因为打开会耗性能
Query OK, 0 rows affected (0.000 sec)
2> 结合trace工具的结果就可以看出来为何全表扫描更优: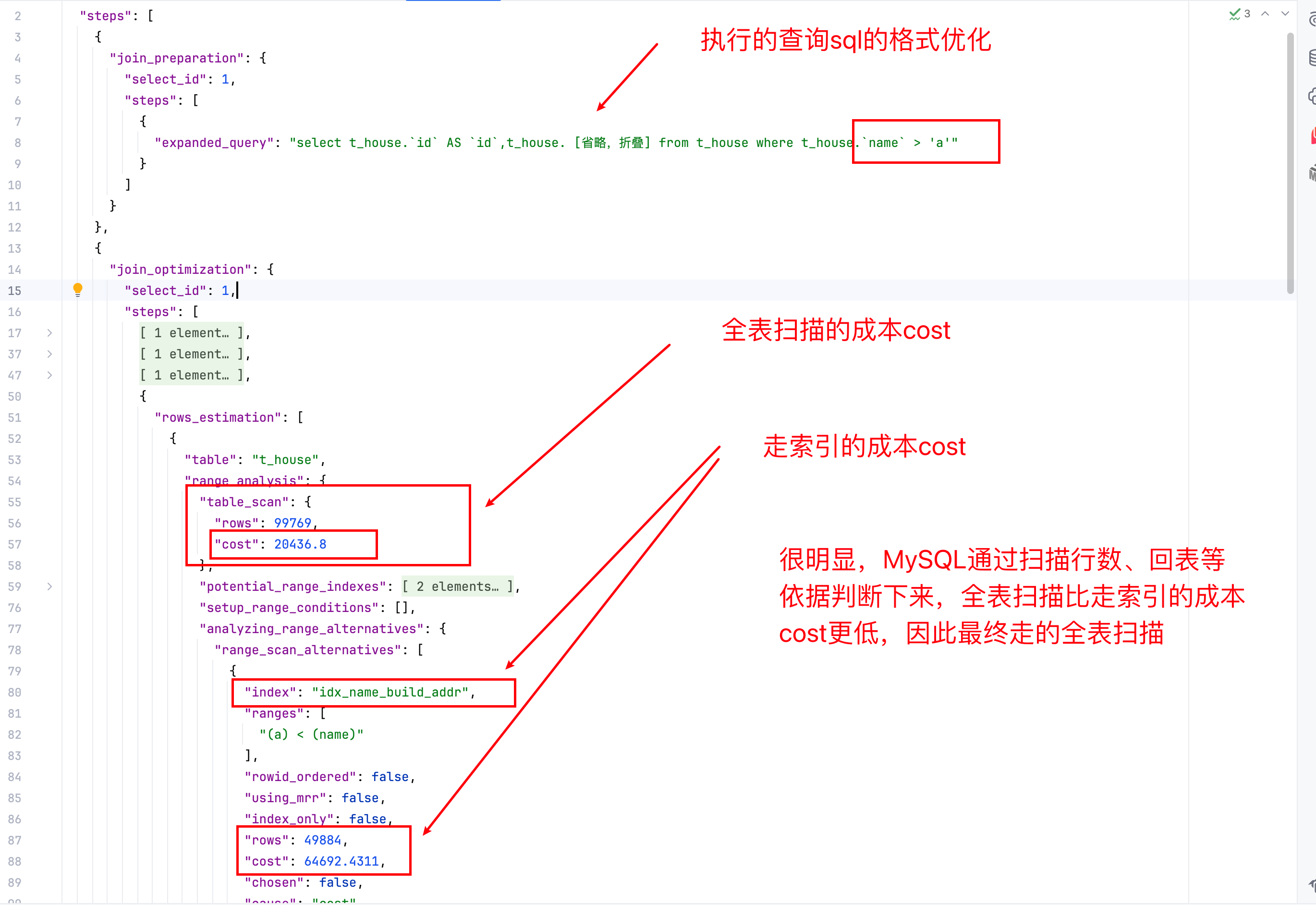
3> 特别说明,cost 与 rows的值只是一个相对的预估值,非真实的物理行数。
3.2.4、order by场景下特殊示例
以下内容以如下索引为依据,进行展开
INDEX idx_name_build_addr(name, buid_years, address) USING BTREE COMMENT ‘普通索引’
1> order by 下的复合索引字段排序规则不一样时不会走索引
MariaDB [wang_test]> explain select * from t_house where name = 'fffbadc453' order by buid_years desc, address asc;
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+----------------------------------------------------+
| 1 | SIMPLE | t_house | ref | idx_name_build_addr | idx_name_build_addr | 75 | const | 1 | Using index condition; Using where; Using filesort |
+------+-------------+---------+------+---------------------+---------------------+---------+-------+------+----------------------------------------------------+
1 row in set (0.000 sec)
特别说明:MySQL8.0支持这种倒序索引
2> in 不会走索引
MariaDB [wang_test]> explain select * from t_house where name in ('fffbadc453', 'xx') order by buid_years, address;
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+---------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+---------------------------------------+
| 1 | SIMPLE | t_house | range | idx_name_build_addr | idx_name_build_addr | 75 | NULL | 2 | Using index condition; Using filesort |
+------+-------------+---------+-------+---------------------+---------------------+---------+------+------+---------------------------------------+
1 row in set (0.000 sec)
3.2.5、group by说明
1> group by操作本质上是先order by,然后再收集,因此也和order by类型,遵循索引最左前缀法。
2> where 的优先级比 having高,因此尽量条件都放到where中,提前过滤掉。
3.2.6、Using filesort浅析
本质上是不借助已经排好序的索引,而是自己单独开辟一块内存来自己实时的现排。是不是感觉听起来就很耗时。
根据需要排序数据量的大小,内部提供了2个方式:
1> 单路排序:数据量小的情况下,一次性取出符合条件的聚簇索引所有字段,load到内存,一次性排序完。
2> 双路排序(又叫回表排序):数据量大的情况下,在有限的内存下面,仅现取出需要参与排序的字段和能回表的id到内存中进行排序。先得到的结果是排好序之后的id集合,最后还需要一步回表,才能拿到所有排好序的记录并返回。(trace工具中能看到sort_mode: <sortkey, rowid>相关内容,证实)
3> 数据量大小的判断依据:MySQL有一个阈值变量,默认是1MB,如果参与排序的所有字段加起来超过这个阈值,就会使用双路排序。
4> 特殊说明:如果参与排序的字段实在太大了sort_buffer(默认1MB)放不下,会使用磁盘上面创建临时文件排序!
3.2.7、索引设计原则小总结
1> 代码先行,索引后上
因为一开始并不知道一共会建多少个索引,索引建立得越多,MySQL维护起来就越吃力。因此在业务代码起来,大概确定之后,再按照实际出发,设计索引,这样才能尽量的确保每个索引都用在刀刃上。
2> 联合索引尽量覆盖更多的业务查询条件
原因同第一点一样,索引建立得越少越好。具体实施的话可以参考上文的最左前缀原则,索引覆盖原则, 排序原则、范围查询优化、结合业务分析,大多数场景优先、范围查询索引字段靠最后、考虑业务sql能不能换种写法来满足本次修改后的新覆盖索引、考虑业务当前的存储形式是否能换,例如日期范围查找,能不能换成是否7天内、14天内、14天外
3> 阿里规约之不要想着通过代码维护唯一性,创建表的唯一索引更可靠。
4> 不要在基数小的字段上面建立索引
例如一个基数小的字段的值,只有2到3个,例如性别。实际上不如全表扫描来得快,有点浪费索引个数了。
5> 长字符串字段不要拿来做索引字段
1) 长字段例如varchar(255),太占空间,且检索比对吃力。
2)如果非要对长字段建立索引,可以考虑优化成前缀20个字符来做前缀索引。(理论上,前20个已经足够来区分大多数的不同了) – 有个弊端,不能在索引上使用order by 与 group by了
3)生产级长字符串解决方案,建议使用专业的文本检索中间件,例如es,不要再依赖MySQL了。
6> 复合索引设计中where 与 order by冲突时,优先选择满足where
因为可以先通过where走索引将要排序的字段筛选出来,范围缩小之后,再针对这个小集合全量排序带来的利弊权衡更好些。
7> 慢sql查询优化技巧
MySQL可以开启慢SQL日志,并指定慢sql的输出日志文件,例如mysql-slow.log。 拿到慢sql之后再针对性的分析,进行优化。(因为第一点,所以很多情况下,慢sql都是后发现的)
另外的话,还有一个参数可以设置多少时间算超时,例如可以设置超过10s的才记录到慢sql日志中。
3.2.8、分页查询优化
如下这条sql是想取从10000行开始的10条记录,但是实际的执行计划是读取了10010条记录,然后把前10000条数据丢弃了。 – 查询性能很差
MariaDB [wang_test]> select * from t_house limit 10000,10;
+-------+------------+------------+------------------------------+---------------------+
| id | name | buid_years | address | last_modified_time |
+-------+------------+------------+------------------------------+---------------------+
| 10001 | 7c050bd | 81 | 185ce507250a952695 | 2025-08-30 23:36:17 |
| 10002 | d93bcca3fc | 13 | f98e6c5b4c7ec89270 | 2025-08-30 23:36:17 |
| 10003 | 9499fcbf | 50 | 9a1b51c41e419339c3021f403564 | 2025-08-30 23:36:17 |
| 10004 | 19cc4d80 | 81 | aedc0d5a8a2 | 2025-08-30 23:36:17 |
| 10005 | bdb8720 | 39 | 696bf00f36fdfa3 | 2025-08-30 23:36:17 |
| 10006 | b15fe815d1 | 24 | efc8a17e215e99c7a2021690 | 2025-08-30 23:36:17 |
| 10007 | dca289c06 | 88 | 4b7914e2912 | 2025-08-30 23:36:17 |
| 10008 | a43bea7c | 33 | 4524a01e5d85c0e7d6 | 2025-08-30 23:36:17 |
| 10009 | 2dc9cf0 | 25 | 64575b8215b7e6ecf889 | 2025-08-30 23:36:17 |
| 10010 | 285ef | 14 | bf81a39732c1b60d414cc1d9171 | 2025-08-30 23:36:17 |
+-------+------------+------------+------------------------------+---------------------+
10 rows in set (0.003 sec)
3.2.8.1、根据连续自增的主键优化
前提:表的主键ID字段是自增且连续的。
MariaDB [wang_test]> select * from t_house where id > 10000 limit 10;
+-------+------------+------------+------------------------------+---------------------+
| id | name | buid_years | address | last_modified_time |
+-------+------------+------------+------------------------------+---------------------+
| 10001 | 7c050bd | 81 | 185ce507250a952695 | 2025-08-30 23:36:17 |
| 10002 | d93bcca3fc | 13 | f98e6c5b4c7ec89270 | 2025-08-30 23:36:17 |
| 10003 | 9499fcbf | 50 | 9a1b51c41e419339c3021f403564 | 2025-08-30 23:36:17 |
| 10004 | 19cc4d80 | 81 | aedc0d5a8a2 | 2025-08-30 23:36:17 |
| 10005 | bdb8720 | 39 | 696bf00f36fdfa3 | 2025-08-30 23:36:17 |
| 10006 | b15fe815d1 | 24 | efc8a17e215e99c7a2021690 | 2025-08-30 23:36:17 |
| 10007 | dca289c06 | 88 | 4b7914e2912 | 2025-08-30 23:36:17 |
| 10008 | a43bea7c | 33 | 4524a01e5d85c0e7d6 | 2025-08-30 23:36:17 |
| 10009 | 2dc9cf0 | 25 | 64575b8215b7e6ecf889 | 2025-08-30 23:36:17 |
| 10010 | 285ef | 14 | bf81a39732c1b60d414cc1d9171 | 2025-08-30 23:36:17 |
+-------+------------+------------+------------------------------+---------------------+
10 rows in set (0.000 sec)
这个前提很难满足,大多数场景下用不上这个方法优化。
3.2.8.2、覆盖索引优化
前提: 使用索引(本质上是缩小回表范围),本例以已经建立了如下索引为例:
INDEX idx_name_build_addr(name, buid_years, address) USING BTREE COMMENT ‘普通索引’
MariaDB [wang_test]> select * from t_house a inner join (select id from t_house order by name limit 10000,10) b on a.id = b.id;
+-------+------------+------------+----------------------------+---------------------+-------+
| id | name | buid_years | address | last_modified_time | id |
+-------+------------+------------+----------------------------+---------------------+-------+
| 60657 | 198933d | 13 | 6ce8217aa9ff1e52 | 2025-08-30 23:38:25 | 60657 |
| 33789 | 198a3d | 19 | c65a8c6e6ac703c56739 | 2025-08-30 23:37:16 | 33789 |
| 92954 | 198c72b | 72 | eaf991a00a48400df2d5645bfc | 2025-08-30 23:39:51 | 92954 |
| 76338 | 198e319fed | 83 | c655b1428e558 | 2025-08-30 23:39:07 | 76338 |
| 59643 | 198e8 | 23 | da233446f1f70065d17a9 | 2025-08-30 23:38:22 | 59643 |
| 91225 | 198f6792e | 67 | 56781dd498505e1 | 2025-08-30 23:39:47 | 91225 |
| 62522 | 198fe | 74 | c14394cddf8da01 | 2025-08-30 23:38:30 | 62522 |
| 62266 | 19906be9 | 6 | a2bfc146a962c0 | 2025-08-30 23:38:30 | 62266 |
| 45994 | 1990d0 | 76 | 510ecd06ff9a223f88852cb4 | 2025-08-30 23:37:47 | 45994 |
| 95719 | 1990d69ecf | 16 | bc7bcaa459 | 2025-08-30 23:39:58 | 95719 |
+-------+------------+------------+----------------------------+---------------------+-------+
10 rows in set (0.003 sec)
这样确实是最优的解法。(tips:如果是分库分表场景,还是有文本中间件比较好,比如es)
3.2.9、join关联优化
数据准备(一个用户users可以创建多个标签tags, 用户数据100条,标签数据10w条,且都有一个用于2表连接的普通索引)
-- 创建用户表 users (小表,100条记录)
CREATE TABLE users (
user_id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(8) NOT NULL,
registration_date DATE,
INDEX idx_username (username)
) ENGINE=InnoDB;
-- 创建标签表 tags (大表,10万条记录)
CREATE TABLE tags (
tag_id INT PRIMARY KEY AUTO_INCREMENT,
tag_name VARCHAR(50) NOT NULL,
category VARCHAR(30),
created_by VARCHAR(8) NOT NULL,
INDEX idx_created_by (created_by)
) ENGINE=InnoDB;
-- 生成 users 表的100条随机记录
DELIMITER //
CREATE PROCEDURE GenerateUsersData()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE random_username VARCHAR(50);
WHILE i < 100 DO
SET random_username = CONCAT('user_', LPAD(i+1, 3, '0'));
INSERT INTO users (username, registration_date)
VALUES (random_username, DATE_ADD('2020-01-01', INTERVAL FLOOR(RAND() * 1000) DAY));
SET i = i + 1;
END WHILE;
end //
DELIMITER ;
-- 生成 tags 表的10万条随机记录
DELIMITER //
CREATE PROCEDURE GenerateTagsData()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE random_tag_name VARCHAR(50);
DECLARE random_category VARCHAR(30);
DECLARE random_creator VARCHAR(50);
WHILE i < 100000 DO
SET random_tag_name = CONCAT('tag_', LPAD(i+1, 6, '0'));
-- 随机选择分类
CASE FLOOR(RAND() * 5)
WHEN 0 THEN SET random_category = '技术';
WHEN 1 THEN SET random_category = '生活';
WHEN 2 THEN SET random_category = '娱乐';
WHEN 3 THEN SET random_category = '学习';
ELSE SET random_category = '其他';
END CASE;
-- 随机选择创建者(从100个用户中选择)
SET random_creator = CONCAT('user_', LPAD(FLOOR(1 + RAND() * 100), 3, '0'));
INSERT INTO tags (tag_name, category, created_by)
VALUES (random_tag_name, random_category, random_creator);
SET i = i + 1;
END WHILE;
end //
DELIMITER ;
CALL GenerateUsersData(); -- 生成100条用户记录
CALL GenerateTagsData(); -- 生成10万条标签记录
3.2.9.1、嵌套循环连接 Nested-Loop Join(NLJ) 算法
前提: 被驱动表的连接字段建立了索引
MariaDB [wang_test]> explain select * from users u inner join tags t on u.username = created_by;
+------+-------------+-------+------+----------------+----------------+---------+----------------------+-------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+----------------+----------------+---------+----------------------+-------+-------+
| 1 | SIMPLE | u | ALL | idx_username | NULL | NULL | NULL | 100 | |
| 1 | SIMPLE | t | ref | idx_created_by | idx_created_by | 34 | wang_test.u.username | 26759 | |
+------+-------------+-------+------+----------------+----------------+---------+----------------------+-------+-------+
2 rows in set (0.000 sec)
从这里就可以看出来,是先全表扫描的小表users,然后去和大表tags进行使用索引联合查询,典型的大表驱动小表
MySQL会优化成这样,跟join的前后顺序无关。
扫描行数分析: 小表走聚簇索引,也就是扫描全表的磁盘地址,就是100行。 大表走的是索引,能根据小表的一行直接定位到磁盘地址,因此扫描行数总共也是100行。 那么扫描的总行数就是200行。
反之,如果是大表驱动小表,那么就是100000 + 100 = 100100行扫描!
这种连接的方式叫嵌套循环连接(NLJ)算法
3.2.9.2、基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
前提: 被驱动表的连接字段没有建立索引
因此该例,就需要把上面的索引去掉
MariaDB [wang_test]> ALTER TABLE users DROP INDEX idx_username; -- 去掉 users 表的 idx_username 索引
Query OK, 0 rows affected (0.013 sec)
Records: 0 Duplicates: 0 Warnings: 0
MariaDB [wang_test]> ALTER TABLE tags DROP INDEX idx_created_by; -- 去掉 tags 表的 idx_created_by 索引
Query OK, 0 rows affected (0.011 sec)
Records: 0 Duplicates: 0 Warnings: 0
这是的执行计划就是这样:
MariaDB [wang_test]> explain select * from users u inner join tags t on u.username = created_by;
+------+-------------+-------+------+---------------+------+---------+------+------+-------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------------------------------------------+
| 1 | SIMPLE | t | ALL | NULL | NULL | NULL | NULL | 1 | |
| 1 | SIMPLE | u | ALL | NULL | NULL | NULL | NULL | 2 | Using where; Using join buffer (flat, BNL join) |
+------+-------------+-------+------+---------------+------+---------+------+------+-------------------------------------------------+
2 rows in set (0.001 sec)
执行流程:
1)先把tags表的数据放到join_buffer(默认值256KB)中
2)逐一从users表中取出行和join_buufer做比对
3)返回结果内容
特别说明
1> join_buffer的存储内容是无序的,比较次数也多。
2> join_buffer的内存是有限的,如果一次性放不完,会分批次放。这就导致批次越多,users表被全表扫描层重复次数就越多。
3> 实际分析下来,扫描总行数假设join_buffer能一次性放完的情况下,是100000 + 100 = 100100扫描行数。同时比对次数也是100000 * 100 = 1000w次!
4> 这样做有什么好处呢?
如果不走join_buffer,那么磁盘扫描行数将是100000 * 100 = 1000w次!join_buffer的最大作用就是减少比较时的磁盘扫描行数!
3.2.9.3、总结
综上所述,连接的优化技巧就是尽量加索引,走NLJ方式 和 尽量小表驱动大表(有关键字强制指定驱动表,但是不需要这么干,MySQL的优化比想象中的更好)。
小表定义:是指过滤后,结果集更小的表,而不是表总行数
3.2.10、in和exists优化
核心思想:小表驱动大表。
原因(重复说明):
1> 被驱动表没加索引的情况下,谁驱动谁其实区别不大。
2> 如果被驱动表加了索引,就能保证被驱动表走索引先知道磁盘地址,最终被驱动表读取一次磁盘就可以拿到数据。这样的话,仅需要驱动表的行数越少,磁盘的扫描次数就会越少,因此强调行数少的表作为驱动表。
3> 这里有一个核心支撑点:innoDB的Buffer pool 是将非叶子节点基本缓存在内存的,因此索引的读取基本在内存,几乎不算磁盘扫描开销。
3.2.10.1、in
select * from A where id in (select id from B)
#等价于:
for(select id from B) {
select * from A where A.id = B.id
}
每次select * from A where A.id = B.id 是需要读取磁盘的,因此需要保证(select id from B)是最小的。
3.2.10.2、exists
select * from A where exists (select 1 from B where B.id = A.id)
#等价于:
for(select * from A){
select * from B where B.id = A.id
}
每次select * from B where B.id = A.id是需要读取磁盘的,因此需要保证select * from A是最小的。
3.2.11、count
一般count有如下几种写法
一下执行计划是在有索引的基础上:INDEX idx_name_build_addr(name, buid_years, address) USING BTREE COMMENT ‘普通索引’
MariaDB [wang_test]> explain select count(1) from t_house;
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| 1 | SIMPLE | t_house | index | NULL | idx_name_build_addr | 1103 | NULL | 99769 | Using index |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
1 row in set (0.000 sec)
MariaDB [wang_test]> explain select count(id) from t_house;
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| 1 | SIMPLE | t_house | index | NULL | idx_name_build_addr | 1103 | NULL | 99769 | Using index |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
1 row in set (0.000 sec)
MariaDB [wang_test]> explain select count(name) from t_house;
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| 1 | SIMPLE | t_house | index | NULL | idx_name_build_addr | 1103 | NULL | 99769 | Using index |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
1 row in set (0.000 sec)
MariaDB [wang_test]> explain select count(*) from t_house;
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
| 1 | SIMPLE | t_house | index | NULL | idx_name_build_addr | 1103 | NULL | 99769 | Using index |
+------+-------------+---------+-------+---------------+---------------------+---------+------+-------+-------------+
1 row in set (0.000 sec)
MariaDB [wang_test]> explain select count(last_modified_time) from t_house;
+------+-------------+---------+------+---------------+------+---------+------+-------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+---------+------+---------------+------+---------+------+-------+-------+
| 1 | SIMPLE | t_house | ALL | NULL | NULL | NULL | NULL | 99769 | |
+------+-------------+---------+------+---------------+------+---------+------+-------+-------+
1 row in set (0.000 sec)
结论:
1> 除了不走索引的统计效率最低,其余的都走的覆盖索引,效率差不多。
2> 进一步仔细分析:
1) 有索引的情况下count(name) > count(主键) 因为主键索引存储的字段比二级索引存储的字段多。-- 其实上面执行计划也看出来了, 即使count(id),也是走的二级覆盖索引。
2) 没索引的情况下count(name) < count(主键), 这个毫无疑问,没索引的话,就要磁盘开销了。
3) count(1), 是代表直接用字段1作为依据,比上面的都快,因为count(name)和count(id)还需要取出对应字段的值。
4) count(*) ,MySQL做过优化,比1更直接,直接按行累加,连1都没有了。
5) 因此 count(*) ≈ count(1) > count(name) > count(id) 有索引的情况下
6) count(name)不会统计值为NULL的行。
3> 在数据量大的情况下,count还是会很慢
1) 如果是MyISAM存储引擎,因为其锁的最小粒度是表锁,因此维护了表的总记录数的元数据,能直接count(*)拿到,很快。但是innoDB就不行了,因为支持更小粒度的行数与MVCC。
2)InnoDB存储引擎只能拿到一个表总行数的近似值这个元数据,如果需要精确的总行数的话,只能借助第三方了,例如redis计数(如果需要100%一致的话,就不推荐redis了,一致性代价高)。如果需要100%准确的话,只有单独开个MySQL表来记录次数,且事务和业务表处于同一个事务中。当然,这里指的是无条件的count
4、表字段类型选择注意事项
1、浮点数,尽量选择适用Decimal,而不是float、double。因为后面2个有可能丢失精度。
2、日期类型:datetime和date的上限是9999年,但是timestamp的上限是2038年。
3、字符类型char:固定长度,不足时会补空格占位,但是select会自动去掉空格。
4、文本类型:大文本类型,例如text建议单独拆子表存,因为太大会影响聚簇索引性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)