Comake D1 开发板 开源算法 VITS 语音合成算法 实战
¶vits是一个端到端的语音合成算法, 它使用预先训练好的语音编码器直接将文本转换为语音, 无需额外的中间步骤或者特征提取。https://pan.baidu.com/s/1pN-wL_5wB9gYMAr2Mh7Jvg, 密码:vits。
VITS
1 概述¶
1.1 背景介绍¶
vits是一个端到端的语音合成算法, 它使用预先训练好的语音编码器直接将文本转换为语音, 无需额外的中间步骤或者特征提取。详情可参考vits官方链接:
https://github.com/jaywalnut310/vits
由于官方提供的vits模型是基于英文训练的, 因此我们另外找了一个基于中文训练的vits仓库:
https://github.com/ywwwf/vits-mandarin-windows
模型下载链接为:
https://pan.baidu.com/s/1pN-wL_5wB9gYMAr2Mh7Jvg, 密码:vits
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/tts/vits -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/tts/vits.img
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create -n vits python==3.10 $conda activate vits $git clone https://github.com/ywwwf/vits-mandarin-windows.git $cd vits-mandarin-windows $pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple $cd monotonic_align $python setup.py build_ext --inplace $cd ..注意:这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/ywwwf/vits-mandarin-windows/blob/master/README.md -
模型测试
- 创建models文件夹并将下载好的模型放到该目录下, 然后运行模型测试脚本, 确保vits环境配置正确
$python inference.py
- 创建models文件夹并将下载好的模型放到该目录下, 然后运行模型测试脚本, 确保vits环境配置正确
-
模型修改
-
修改原始代码, 将动长输入改成定长输入
-
transforms.py文件第55行至94行-
原始代码
def unconstrained_rational_quadratic_spline(inputs, unnormalized_widths, unnormalized_heights, unnormalized_derivatives, inverse=False, tails='linear', tail_bound=1., min_bin_width=DEFAULT_MIN_BIN_WIDTH, min_bin_height=DEFAULT_MIN_BIN_HEIGHT, min_derivative=DEFAULT_MIN_DERIVATIVE): inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound) outside_interval_mask = ~inside_interval_mask outputs = torch.zeros_like(inputs) logabsdet = torch.zeros_like(inputs) if tails == 'linear': unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1)) constant = np.log(np.exp(1 - min_derivative) - 1) unnormalized_derivatives[..., 0] = constant unnormalized_derivatives[..., -1] = constant outputs[outside_interval_mask] = inputs[outside_interval_mask] logabsdet[outside_interval_mask] = 0 else: raise RuntimeError('{} tails are not implemented.'.format(tails)) outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline( inputs=inputs[inside_interval_mask], unnormalized_widths=unnormalized_widths[inside_interval_mask, :], unnormalized_heights=unnormalized_heights[inside_interval_mask, :], unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :], inverse=inverse, left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound, min_bin_width=min_bin_width, min_bin_height=min_bin_height, min_derivative=min_derivative ) return outputs, logabsdet -
修改后的代码
def unconstrained_rational_quadratic_spline(inputs, unnormalized_widths, unnormalized_heights, unnormalized_derivatives, inverse=False, tails='linear', tail_bound=1., min_bin_width=DEFAULT_MIN_BIN_WIDTH, min_bin_height=DEFAULT_MIN_BIN_HEIGHT, min_derivative=DEFAULT_MIN_DERIVATIVE): inside_interval_mask = (~(inputs < -tail_bound)) & (~(inputs > tail_bound)) outside_interval_mask = ~inside_interval_mask outputs = torch.zeros_like(inputs) logabsdet = torch.zeros_like(inputs) if tails == 'linear': unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1)) constant = np.log(np.exp(1 - min_derivative) - 1) unnormalized_derivatives[..., 0] = constant unnormalized_derivatives[..., -1] = constant outputs = inputs * outside_interval_mask else: raise RuntimeError('{} tails are not implemented.'.format(tails)) outputs, logabsdet = rational_quadratic_spline( inputs=inputs, unnormalized_widths=unnormalized_widths, unnormalized_heights=unnormalized_heights, unnormalized_derivatives=unnormalized_derivatives, inverse=inverse, left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound, min_bin_width=min_bin_width, min_bin_height=min_bin_height, min_derivative=min_derivative ) outputs = outputs * inside_interval_mask logabsdet = logabsdet * inside_interval_mask return outputs, logabsdet
-
-
models.py-
第50行:
-
原始代码
def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0): -
修改后的代码
def forward(self, x, randn, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
-
-
第90行
-
原始代码
z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale -
修改后的代码
z = randn.to(device=x.device, dtype=x.dtype) * noise_scale
-
-
第167行至176行
-
原始代码
def forward(self, x, x_lengths): x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h] x = torch.transpose(x, 1, -1) # [b, h, t] x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) x = self.encoder(x * x_mask, x_mask) stats = self.proj(x) * x_mask m, logs = torch.split(stats, self.out_channels, dim=1) return x, m, logs, x_mask -
修改后的代码
def forward(self, x, x_mask): x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h] x = torch.transpose(x, 1, -1) # [b, h, t] # x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) x = self.encoder(x * x_mask, x_mask) stats = self.proj(x) * x_mask m, logs = torch.split(stats, self.out_channels, dim=1) return x, m, logs, x_mask
-
-
第240行
-
原始代码
z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask -
修改后的代码
z = (m + torch.exp(logs)) * x_mask
-
-
第499行至523行
-
原始代码
def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., max_len=None): x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths) if self.n_speakers > 0: g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1] else: g = None if self.use_sdp: logw = self.dp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w) else: logw = self.dp(x, x_mask, g=g) w = torch.exp(logw) * x_mask * length_scale w_ceil = torch.ceil(w) y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long() y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype) attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1) attn = commons.generate_path(w_ceil, attn_mask) m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale z = self.flow(z_p, y_mask, g=g, reverse=True) o = self.dec((z * y_mask)[:,:,:max_len], g=g) return o, attn, y_mask, (z, z_p, m_p, logs_p) -
修改后的代码
def infer(self, x, x_mask, sid=None, noise_scale=1, z_fixed=None, max_len=None): max_length=1000 x, m_p, logs_p, x_mask = self.enc_p(x, x_mask) if self.n_speakers > 0: g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1] else: g = None randn = z_fixed[:,:2,:500] if self.use_sdp: logw = self.dp(x, randn, x_mask, g=g, reverse=True, noise_scale=self.noise_scale_w) else: logw = self.dp(x, randn, x_mask, g=g) w = torch.exp(logw) * x_mask * self.length_scale # w_ceil = torch.ceil(w) w_ceil = -torch.floor(-w) y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long() # y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype) y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, max_length), 1).to(x_mask.dtype) attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1) attn = commons.generate_path(w_ceil, attn_mask) m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] z_p = m_p + z_fixed * torch.exp(logs_p) * noise_scale[0] z = self.flow(z_p, y_mask, g=g, reverse=True) o = self.dec((z * y_mask)[:,:,:max_len], g=g) # return o, attn, y_mask, (z, z_p, m_p, logs_p) return o, y_lengths
-
-
-
attention.py第165行至170行-
原始代码
if mask is not None: scores = scores.masked_fill(mask == 0, -1e4) if self.block_length is not None: assert t_s == t_t, "Local attention is only available for self-attention." block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length) scores = scores.masked_fill(block_mask == 0, -1e4) -
修改后的代码
if mask is not None: scores = scores.masked_fill(mask == 0, -1e4) scores = scores - (1-mask) * 104 if self.block_length is not None: assert t_s == t_t, "Local attention is only available for self-attention." block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length) # scores = scores.masked_fill(block_mask == 0, -103) scores = scores - (1-block_mask) * 104
-
-
-
-
模型导出
- 编写模型转换脚本
export_onnx.py:import os import time import random import numpy as np import torch from scipy.io.wavfile import write import soundfile as sf import commons import utils from models import SynthesizerTrn from text import create_symbols_manager, text_to_sequence, cleaned_text_to_sequence, _clean_text import argparse import onnx from onnxsim import simplify import onnxruntime from thop import profile from torchsummary import summary class AudioGenerator(): def __init__(self, hparams, device): self.hparams = hparams self._device = device if 'language' in hparams.data: symbols_manager = create_symbols_manager(hparams.data.language) else: symbols_manager = create_symbols_manager('default') self.symbol_to_id = symbols_manager._symbol_to_id self.net_g = create_network(hparams, symbols_manager.symbols, device) def load(self, path): load_checkpoint(self.net_g, path) def inference(self, text, phoneme_mode=False): return do_inference(self.net_g, self.hparams, self.symbol_to_id, text, phoneme_mode, self._device) def get_text(text, hparams, symbol_to_id, phoneme_mode=False): if not phoneme_mode: print("1: ", _clean_text(text, hparams.data.text_cleaners)) text_norm = text_to_sequence(text, hparams.data.text_cleaners, symbol_to_id) else: print("2: ", text) text_norm = cleaned_text_to_sequence(text, symbol_to_id) if hparams.data.add_blank: text_norm = commons.intersperse(text_norm, 0) text_norm = torch.LongTensor(text_norm) return text_norm def create_network(hparams, symbols, device): net_g = SynthesizerTrn( len(symbols), hparams.data.filter_length // 2 + 1, hparams.train.segment_size // hparams.data.hop_length, **hparams.model).to(device) _ = net_g.eval() return net_g def load_checkpoint(network, path): _ = utils.load_checkpoint(path, network, None) # Assume the network has loaded weights and are ready to do inference def do_inference(generator, hparams, symbol_to_id, text, phoneme_mode=False, device=torch.device('cpu')): stn_tst = get_text(text, hparams, symbol_to_id, phoneme_mode) with torch.no_grad(): x_tst = stn_tst.to(device).unsqueeze(0).int() x_tst = torch.cat([x_tst, torch.zeros(1, 500 - x_tst.size(1))],dim=1).int() x_tst_lengths = torch.tensor([stn_tst.size(0)])# 1x500 x_mask = torch.unsqueeze(commons.sequence_mask(x_tst_lengths, x_tst.size(1)), 1).float() # noise_scale = 0.667 # noise_scale_w = 0.8 noise_scale = torch.tensor([random.uniform(0, 1)]) noise_scale_w = torch.tensor([random.uniform(0, 1)]) print(f"The noise ncale is {noise_scale}") print(f"The noise scale_w is {noise_scale_w}") max_length=1000 input_tensor = torch.randn(1, hparams.model.hidden_channels, max_length, device="cuda", dtype=torch.float32) z_fixed = torch.randn_like(input_tensor).to(x_tst.device) #audio_pt = generator.infer(x_tst.int(), x_mask, None, noise_scale_w, z_fixed) dummy_input = (x_tst.int(), x_mask, None, noise_scale_w, z_fixed) generator.forward = generator.infer torch.onnx.export( model=generator, args=dummy_input, f='./models/vits.onnx', input_names=["input", "mask", "noise_scale", "z_fixed"], output_names=["z", "y_lengths"], opset_version=13, export_params=True, verbose=False ) model = onnx.load('./models/vits.onnx') model_simp, check = simplify(model) export_name = './models/vits_sim.onnx' onnx.save(model_simp, export_name) # exit(1) # import pdb # pdb.set_trace() np.save("./npy_data/x_tst_0.npy", x_tst) np.save("./npy_data/x_mask_0.npy", x_mask) np.save("./npy_data/noise_scale_w_0.npy", noise_scale_w) np.save("./npy_data/z_fixed_0.npy", z_fixed) onnx_session_static = onnxruntime.InferenceSession('./models/vits_sim.onnx', providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']) input_names_static = [input.name for input in onnx_session_static.get_inputs()] output_names_static = [output.name for output in onnx_session_static.get_outputs()] data_static = {input_names_static[0]: np.array(x_tst, dtype=np.int32), input_names_static[1]: np.array(x_mask, dtype=np.float32), input_names_static[2]: np.array(noise_scale_w, dtype=np.float32), input_names_static[3]: np.array(z_fixed, dtype=np.float32),} data_out_static = onnx_session_static.run(output_names_static, data_static) audio=data_out_static[0][0][0] y_length = data_out_static[1] return audio,y_length def save_to_wav(data, sampling_rate, path): sf.write(path, data, 22050, 'PCM_16') if __name__ == "__main__": config_path = "./config/bb_v100.json" hps = utils.get_hparams_from_file(config_path) audio_generator = AudioGenerator(hps, "cpu") checkpoint_path = "./models/G_bb_v100_820000.pth" audio_generator.load(checkpoint_path) phoneme_mode = False do_noise_reduction = True text = "他的到来是一件好事, 我很欢迎他, 大家好, 我是御坂美琴的儿子。" start = time.perf_counter() audio,y_length = audio_generator.inference(text, phoneme_mode) print(f"The inference takes {time.perf_counter() - start} seconds") print(audio.dtype) if do_noise_reduction: import noisereduce as nr # perform noise reduction audio = nr.reduce_noise(y=audio, sr=hps.data.sampling_rate) output_dir = './output/' # python program to check if a path exists # if it doesn’t exist we create one if not os.path.exists(output_dir): os.makedirs(output_dir) filename = 'output.wav' file_path = os.path.join(output_dir, filename) save_to_wav(audio, hps.data.sampling_rate, file_path)
- 编写模型转换脚本
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
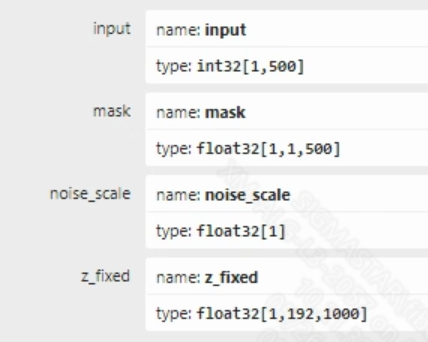
vits模型的输入信息如下图所示, 该模型有四个输入。其中, input为输入的token_id, mask为用于记录token_id有效值的位置, noise_sclae和z_fixed为随机值, 用于丰富模型输出多样性。 以中文为例, 一段输入文本转为模型的输入, 需要经过以下几个步骤:
1)用pypinyin包将中文转为拼音 2)对拼音进行切分, 通过字典查找每个音素对应的索引值, 将音素转为token 3)每个token前后补0, 表示停顿最终转为token_id。
-
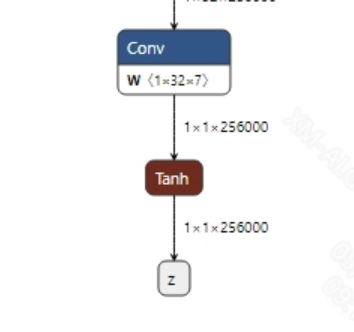
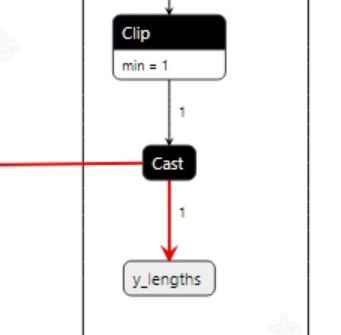
后处理
vits没有后处理, 输出的tensor直接通过wav工具将输出转为音频。模型输出信息如下:
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp models/vits_sim.onnx OpenDLAModel/tts/vits/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a tts/vits -c config/tts_vits.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/vits.img output/${chip}_${时间}/vits_fixed.sim output/${chip}_${时间}/vits_float.sim
2.2.3 关键脚本参数解析¶
- input_config.ini
[INPUT_CONFIG]
inputs=speech,mask,noise_scale,z_fixed; #onnx 输入节点名称, 如果有多个需以“,”隔开;
input_formats=RAWDATA_S16_NHWC,RAWDATA_F32_NHWC,RAWDATA_F32_NHWC,RAWDATA_F32_NHWC; #板端输入格式, 可以根据onnx的输入格式选择, 例如float:RAWDATA_F32_NHWC, int32:RAWDATA_S16_NHWC;
quantizations=TRUE,TRUE,TRUE,TRUE; #打开输入量化, 不需要修改;
[OUTPUT_CONFIG]
outputs=z,y_lengths; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations=TRUE,TRUE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
- tts_vits.cfg
[VITS]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=vits_sim #输入onnx模型名称
INPUT_SIZE_LIST=0 #模型输入分辨率
INPUT_INI_LIST=input_config.ini #配置文件
CLASS_NUM_LIST=0 #填0即可
SAVE_NAME_LIST=vits.img #输出模型名称
QUANT_DATA_PATH=image_lists.txt #量化数据路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a tts/vits -c config/tts_vits.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到tts/vits/log/output路径下的txt文件中。此外, 在tts/vits/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 在
vits-mandarin-windows/export_onnx.py文件中打印第351行的结果:print(audio)获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端vits示例。
$cd sdk/verify/opendla $make clean && make source/tts/vits -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_tts_vits
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_tts_vits
- vits.img
- zh_tn_tagger.fst
- zh_tn_verbalizer.fst
3.3 运行说明¶
-
Usage:
./prog_tts_vits txt model zh_tn_tagger.fst zh_tn_verbalizer.fst(执行文件使用命令) -
Required Input:
- txt: 输入文本路径
- model:需要测试的offline模型路径
- zh_tn_tagger.fst:文本前处理所依赖的第三方资源,用于中文正则化
- zh_tn_verbalizer.fst:文本前处理所依赖的第三方资源,用于中文正则化
-
输入文本示例:input_word.txt
美国是中国的贸易伙伴之一,中美现有贸易格局的形成是供需对接、市场配置的结果。 文艺是时代前进的号角,文艺工作者是灵魂的工程师。 -
Typical Output:
./prog_tts_vits resource/input_word.txt models/vits.img resource/wetext/zh_tn_tagger.fst resour ce/wetext/zh_tn_verbalizer.fst input text: 美国是中国的贸易伙伴之一,中美现有贸易格局的形成是供需对接、市场配置的结果。 model invoke time: 2659.814000 ms Generated: 220416 samples of audio 0.000000 -0.000093 0.000521 -0.000707 0.000558 -0.000391 WAV file 'output_0.wav' has been written input text: 文艺是时代前进的号角,文艺工作者是灵魂的工程师。 model invoke time: 2659.969000 ms Generated: 106496 samples of audio 0.000000 -0.000093 0.000521 -0.000707 0.000521 -0.000391 WAV file 'output_1.wav' has been written
4 立即开始
加入Comake开发者社区
主页地址: CoMake开发者社区
SDK下载: CoMake开发者社区
文档中心: CoMake开发者社区
马上购买 : 首页-Comake开发者社区商店

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)