【控制领域TSMC论文复现】基于时变二次规划的分布式多机器人目标围捕
本文提出了一种统一的分布式多Agent系统框架,用于解决两类复杂的时变二次规划问题(TVQP)。该框架创新性地整合了非一致时不变与一致时变两种场景:在第一种场景中,各Agent的优化目标(Hessian矩阵 Qi)和约束(Di)固定但互不相同;在第二种场景中,所有Agent的优化目标(Q(t))和约束(D(t))随时间动态变化但完全一致。通过结合预测-校正优化方法与
论文英文名称:Distributed Multiagent System for Time-Varying Quadratic Programming With Application to Target Encirclement of Multirobot System
主要内容:分布式多智能体系统、多机器人系统、目标围捕、时变二次规划。
论文英文名称:时变二次规划的分布式多智能体系统及其在多机器人系统目标围捕中的应用
一、代码及文献获取
1.仿真代码:编辑立即购买|TSMC复现:基于时变二次规划的分布式多机器人目标围捕
2.仿真效果视频:TSMC 复现:基于时变二次规划的分布式多机器人目标围捕_哔哩哔哩_bilibili
二、核心内容
本文提出了一种统一的分布式多Agent系统框架,用于解决两类复杂的时变二次规划问题(TVQP)。该框架创新性地整合了非一致时不变与一致时变两种场景:在第一种场景中,各Agent的优化目标(Hessian矩阵 Qi)和约束(Di)固定但互不相同;在第二种场景中,所有Agent的优化目标(Q(t))和约束(D(t))随时间动态变化但完全一致。通过结合预测-校正优化方法与分布式平均跟踪技术,系统仅依赖局部邻居通信(要求连通无向网络)即可协同跟踪全局最优轨迹。理论分析严格证明了系统在温和条件下(如Hessian矩阵正定、约束满秩)的指数收敛性,关键参数设计确保了鲁棒性。
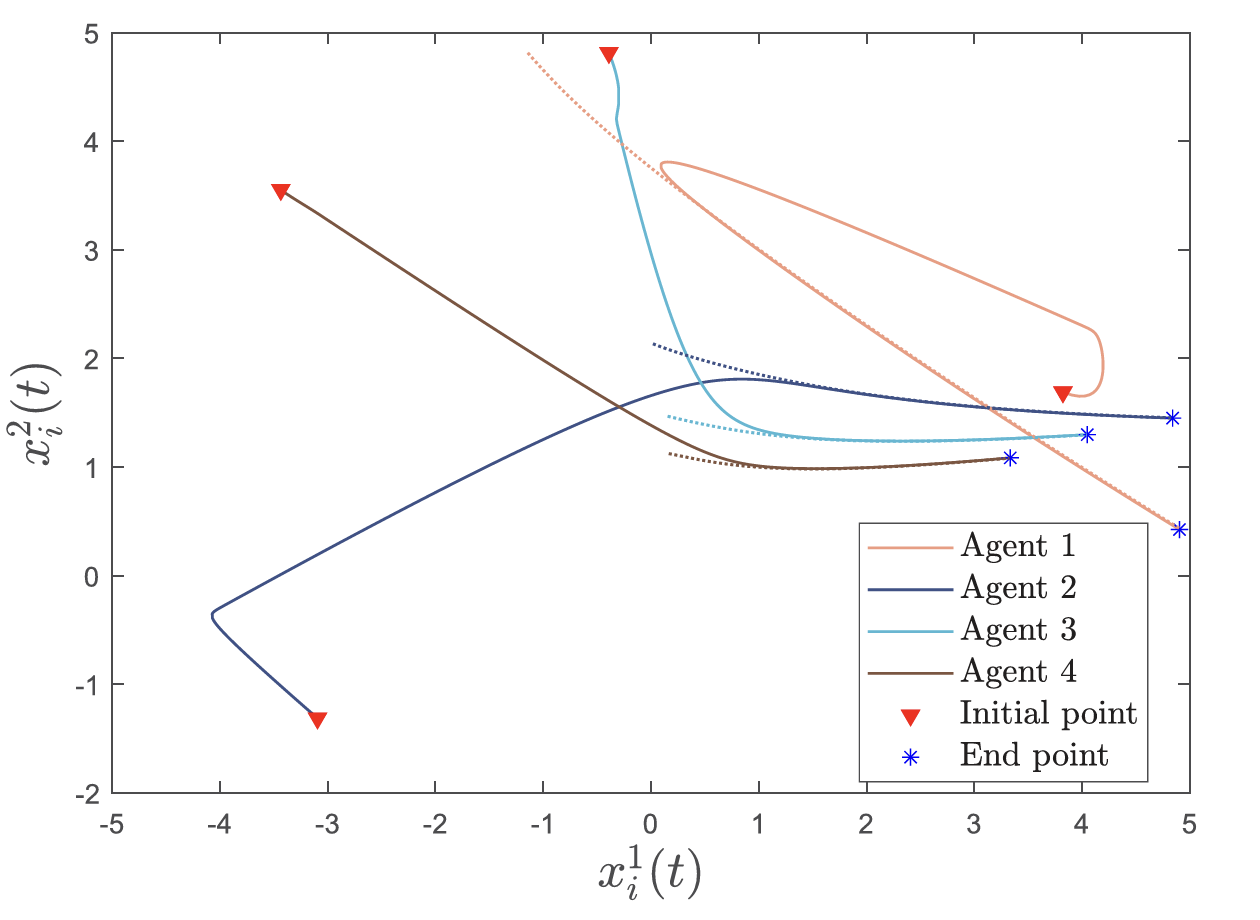
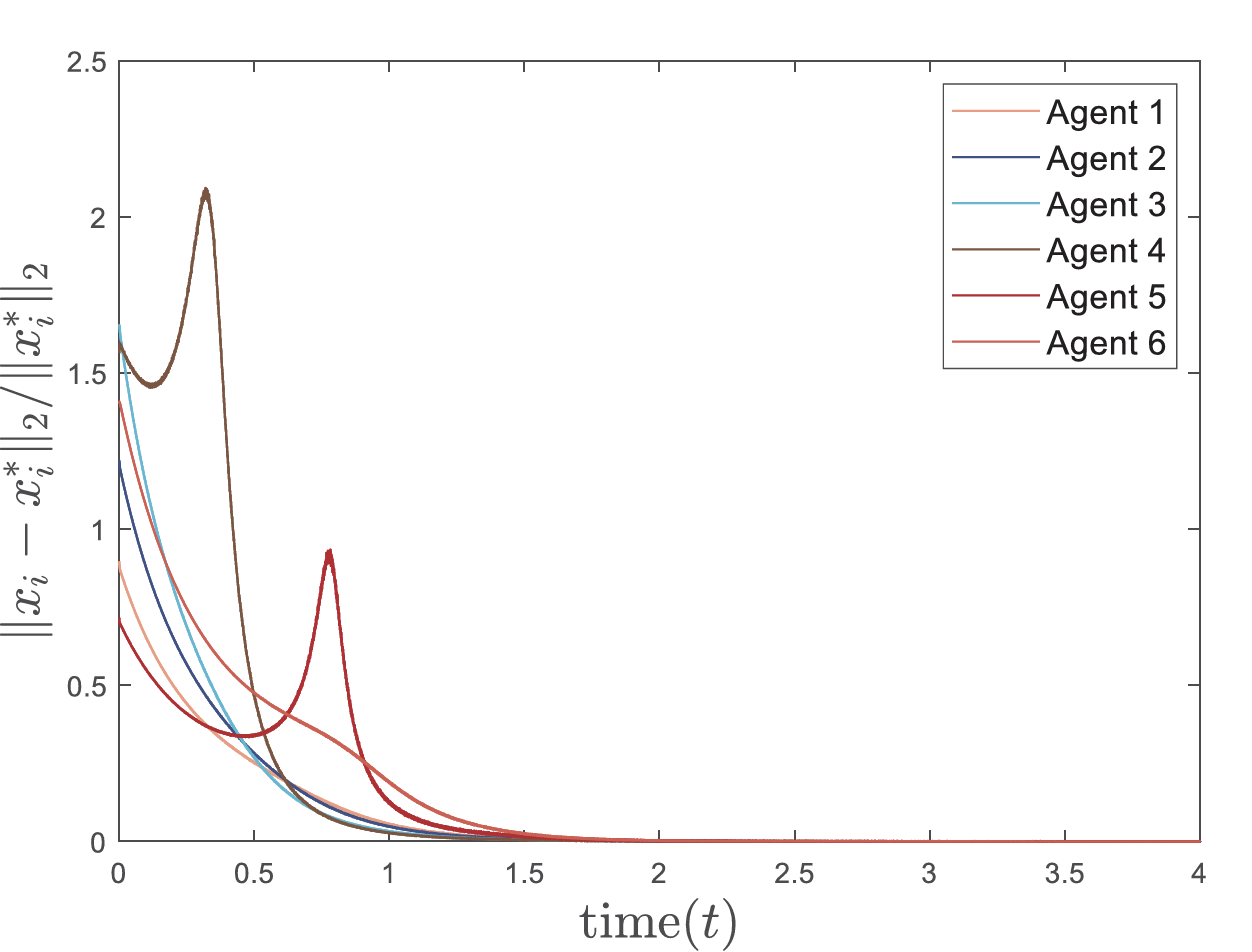
该框架成功应用于多机器人动态目标包围任务:6个机器人在分布式协作下实时包围移动目标,同时最小化检测成本并避免碰撞。仿真结果显示,机器人轨迹(下图)紧密跟踪理论最优路径,且相对误差(∥xi−xi∗∥2/∥xi∗∥2)在2秒内趋近于零(图4),验证了算法的实时性与有效性。
本文首次以分布式方式统一处理两类高维时变约束优化问题,其通用性与扩展性(支持多维场景)优于现有1-D方法(如[14]),为多机器人协同控制、能源调度等动态优化场景提供了高效解决方案。
三、部分仿真结果图
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
四、主要内容(1 小白入门版)
1. 论文要解决什么问题?
想象一群无人机(或机器人)需要实时协作完成一个动态任务,比如围捕一个移动的目标(例如逃犯或野生动物)。但面临两大挑战:
(1)任务难度随时在变:目标位置、环境障碍、无人机电量等因素随时间变化(数学上称为“时变优化问题”)。
(2)去中心化协作:每台无人机只能和附近同伴通信(无法全局掌控信息),需通过局部协商达成全局最优行动方案。
这就是论文的核心问题:设计一个分布式算法,让多机器人系统在动态环境中实时协同求解优化问题。
⚙️ 2. 论文怎么做?——统一框架解决两类场景
论文提出一个“分布式协同计算引擎”(统一多Agent系统),可处理两种常见任务:
场景1:各机器人任务不同但固定
类比:团队中有人负责追踪、有人负责拦截,角色固定但分工不同。 数学对应:每个机器人的代价函数(Hessian矩阵 Qi)和约束(Di)是固定但互异的。
场景2:全体机器人任务相同且时变
类比:全体需同步完成动态动作(如同时收紧包围圈)。 数学对应:所有机器人的代价函数(Q(t))和约束(D(t))相同但随时间变化。
创新点:
(1)一套算法兼容两类场景:无需为不同场景单独设计,节省部署成本。
(2)分布式设计:每个机器人仅通过邻居通信(如图形网络),用预测-校正+平均跟踪技术估计全局信息(避免中央控制)。
🤖 3. 具体应用:多机器人包围移动目标
论文以6个机器人包围一个移动目标为例(Section V-A):
任务目标:
(1)机器人需保持包围圈(圆心始终匹配目标位置)。
(2)每个机器人尽量靠近自己的监视点(避免碰撞)。
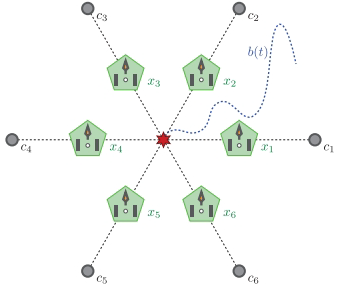
六个机器人组成的多智能体系统的目标围捕目标示意图
-
算法效果: 机器人从随机位置出发,快速形成动态包围圈并跟踪目标移动。下图显示轨迹(虚线为理论最优路径,实线为实际路径):
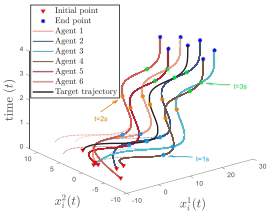
添加图片注释,不超过 140 字(可选)
误差在2秒内趋近于零(Fig.4),证明实时性。
✅ 4. 为什么重要?——优势与价值
理论价值: (1)首次统一处理两类分布式时变优化问题(非一致时不变 vs. 一致时变)。
(2)严格证明:只要机器人网络连通,算法就能收敛。
工程价值: (1)扩展性强:支持高维问题(如3D机器人编队),而此前方法[14]仅限一维。
(2)抗动态干扰:适应目标突变、环境扰动等场景(如目标轨迹 b(t)=(t,icos(0.5it)) 含复杂运动)。
(3)节省资源:分布式计算减少通信负载,适合无人集群等低带宽场景
💡 一句话总结:论文像给多机器人系统装了“智能协作大脑”,让它们在动态场景中自主高效完成任务!
五、主要内容(2 进阶版)
1. 摘要与核心贡献 论文针对时变二次优化问题,提出了一种统一的分布式多agent系统框架。该问题涉及在时间变耦合等式约束下最小化二次函数,并推广了现有文献中的模型。主要贡献包括:
(1)统一框架:系统可处理两种TVQP案例:(1)Hessian矩阵和约束矩阵非一致且时不变;(2)Hessian矩阵和约束矩阵一致但时变。这扩展了现有工作(如[14]),后者需单独处理这些案例。
(2)分布式设计:结合分布式平均跟踪方法(如Lemma 1和Lemma 2),估计全局信息,避免了集中式计算。
(3)收敛保证:在通信图连通无向的条件下,系统状态能指数收敛到最优轨迹(需满足温和条件如Hessian矩阵正定)。
(4)实际应用:成功应用于多机器人系统的动态目标围捕问题,仿真验证了有效性。
论文的创新点在于将两种TVQP案例整合为一个框架,并处理了更一般的约束(如时变资源向量),而[14]仅限于标量或1-D问题。
2. 问题定义:时间变二次规划(TVQP) 论文将TVQP问题建模为:目标函数和全局等式约束
-
•两个案例:
-
•Case 1:非一致时不变(Nonidentical Time-Invariant):Qi(t)=Qi, Di(t)=Di(常数矩阵)。
-
•Case 2:一致时变(Identical Time-Varying):Qi(t)=Q(t), Di(t)=D(t)(所有agent共享相同但时变的矩阵)。
3. 方法:统一分布式多agent系统 论文提出一个连续时间多agent系统,基于预测-校正方法(Prediction-Correction)和分布式平均跟踪(Distributed Average Tracking)。系统设计如下:
集中式算法基础(Section III):使用Lagrange乘子法(μ(t))将约束优化转化为无约束问题。预测-校正动态(式(7))确保状态指数收敛到最优轨迹。
分布式实现(式(15)):每个agent维护状态估计和乘子 ,用于估计全局矩阵 。
关键机制:分布式平均跟踪(式(14))估计 Λ(t),结合符号函数(signum function)处理通信噪声,确保有限时间共识(Lemma 1)。
系统优势在于统一性:同一框架适应两种案例,无需案例特定调整。
4. 理论分析:收敛性证明 论文通过Lyapunov分析和Lemma 2–6证明了系统的收敛性: 理论贡献在于处理了高维时变矩阵的复杂性,而[14]仅分析1-D案例。
5. 应用:多机器人目标包围(Target Encirclement) 论文将TVQP应用于多机器人系统的动态目标包围问题(Section V-A):
Case 1仿真(时不变非一致Hessian): 设置:4个agent,n=2,l=2,环形通信图,Qi 和 Di 时不变非一致。
结果:Agent状态收敛到最优轨迹(Fig. 5),相对误差在4秒内趋近零(Fig. 6)。
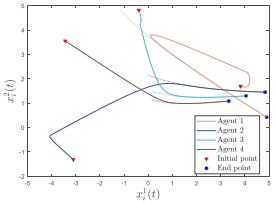
添加图片注释,不超过 140 字(可选)
-
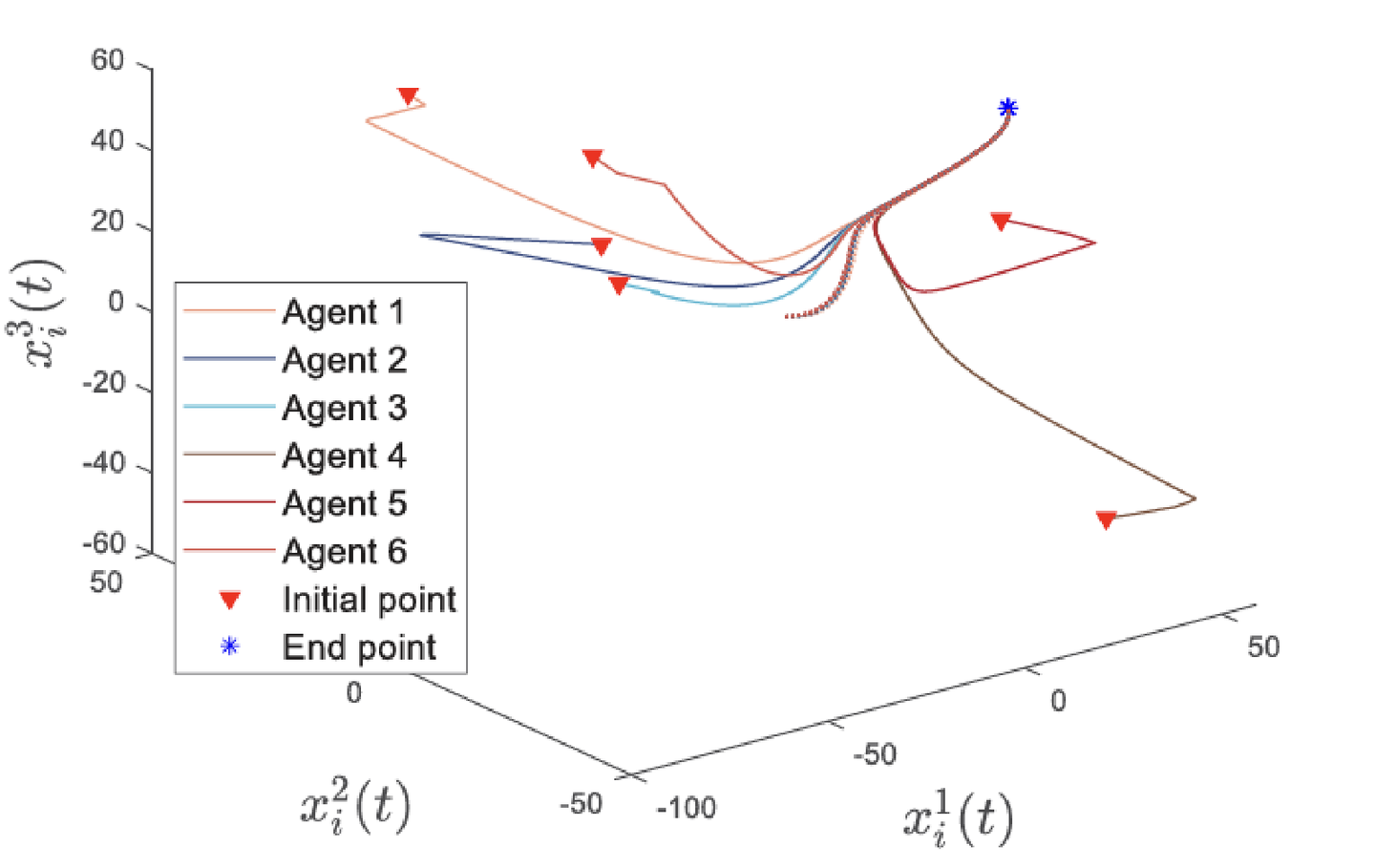
Case 2仿真(时变一致Hessian): 设置:6个agent,n=3,l=2,Q(t) 和 D(t) 时变一致。
-
结果:类似收敛行为(Fig. 7),误差在3秒内衰减(Fig. 8)。
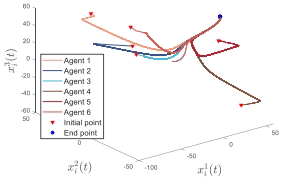
添加图片注释,不超过 140 字(可选)
6. 结论与意义
结论(Section VI):论文提出了一个统一分布式框架,解决两类TVQP问题,并严格证明了收敛性。应用表明其在多机器人协同任务中的实用性。
意义:
理论:扩展了分布式优化领域,处理高维时变约束,为后续研究(如固定时间收敛)提供基础。
应用:适用于机器人编队、能源管理([36]–[37])等实时优化问题。
局限:假设通信图无向;未来工作可探索有向图或噪声环境。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)